컨슈머의 기본 개념
Kafka 컨슈머는 풀(pull) 모델을 구현한다. 이는 컨슈머가 Kafka 브로커(서버)에 직접 데이터를 요청하고, 그에 대한 응답을 받는 방식이다. 중요한 점은 Kafka 브로커가 데이터를 컨슈머에게 푸시하는 것이 아니라, 컨슈머가 필요할 때 데이터를 요청한다는 것이다.
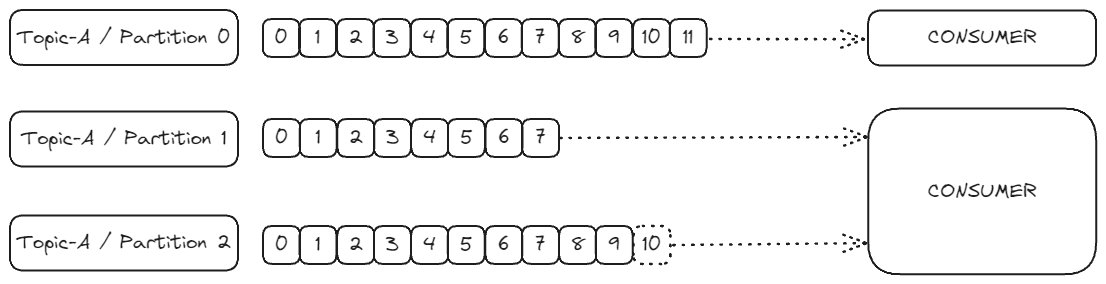
예를 들어:
- 하나의 컨슈머가 토픽-A의 파티션 0에서 데이터를 읽을 수 있다.
- 다른 컨슈머는 여러 파티션(예: 파티션 1과 파티션 2)에서 동시에 데이터를 읽을 수 있다.
컨슈머는 자동으로 어떤 브로커에서 데이터를 읽어야 하는지 알고 있으며, 브로커에 장애가 발생했을 때도 스마트하게 복구 방법을 찾아낸다.
데이터 읽기 순서
파티션에서 읽히는 데이터는 항상 순서대로 처리된다. 즉, 낮은 오프셋부터 높은 오프셋 순으로 데이터가 읽히게 된다(0, 1, 2, 3...).
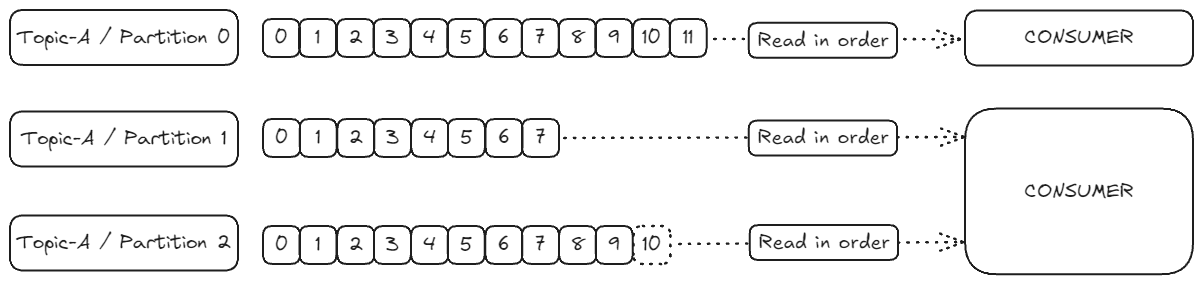
예를 들어:
- 첫 번째 컨슈머는 토픽-A 파티션 0에서 오프셋 0부터 오프셋 11까지 순서대로 데이터를 읽는다.
- 두 번째 컨슈머도 파티션 1과 파티션 2에서 각각 순서대로 데이터를 읽는다.
그러나 서로 다른 파티션 간의 읽기 순서는 보장되지 않는다. 즉, 파티션 1의 데이터를 먼저 읽을지, 파티션 2의 데이터를 먼저 읽을지는 정해져 있지 않다. 순서 보장은 각 파티션 내부에서만 적용된다.
역직렬화(Deserialization) 과정
컨슈머는 Kafka로부터 받은 바이너리 데이터를 프로그래밍 언어가 이해할 수 있는 객체나 데이터로 변환해야 한다. 이 과정을 역직렬화(Deserialization)라고 한다.
컨슈머는 메시지의 형식을 미리 알고 있어야 한다:
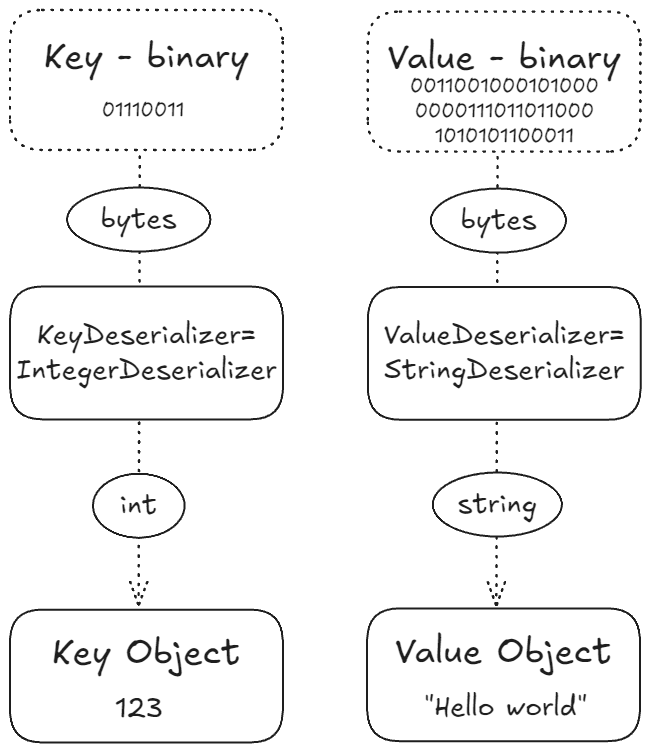
1. 키 역직렬화:
- 예를 들어, 키가 정수라면
IntegerDeserializer를 사용하여 바이너리 데이터를 정수(1, 2, 3 등)로 변환한다.
2. 값 역직렬화:
- 값이 문자열이라면
StringDeserializer를 사용하여 바이너리 데이터를 문자열("hello world" 등)로 변환한다.
Apache Kafka는 다양한 기본 Deserializer를 제공한다:
- String
- Int, Float
- Avro, Protobuf 등
중요한 주의사항: 데이터 타입 변경
토픽이 생성된 후에는 프로듀서가 전송하는 데이터 타입을 변경하지 않는 것이 중요하다. 컨슈머는 특정 타입의 데이터를 예상하고 있기 때문에, 타입이 변경되면 컨슈머가 제대로 작동하지 않을 수 있다.
예를 들어:
- 컨슈머가 정수나 문자열을 예상하고 있는데
- 프로듀서가 갑자기 소수나 Avro 형식으로 데이터를 보내기 시작하면
- 컨슈머는 데이터를 제대로 처리할 수 없게 된다.
만약 데이터 타입을 변경해야 한다면, 새로운 토픽을 생성하고 그 토픽에서 원하는 형식을 사용하는 것이 좋다. 그리고 컨슈머도 새로운 형식에 맞게 재프로그래밍해야 한다.
요약
Kafka 컨슈머는 토픽에서 데이터를 읽어오는 중요한 구성 요소다. 풀 모델을 사용하여 데이터를 요청하고, 각 파티션 내에서 순서대로 데이터를 처리한다. 또한 역직렬화 과정을 통해 바이너리 데이터를 유용한 객체로 변환한다.
프로듀서는 Serializer를 사용하여 객체를 바이트로 변환하고, 컨슈머는 Deserializer를 사용하여 바이트를 다시 객체로 변환한다. 이 과정에서 데이터 타입의 일관성을 유지하는 것이 매우 중요하다.
