프로듀서의 기본 개념
프로듀서는 Kafka 토픽과 파티션에 데이터를 전송하는 역할을 한다. 중요한 점은 프로듀서가 메시지를 어떤 파티션에 기록할지 미리 결정한다는 것이다. 많은 사람들이 Kafka 서버가 이 결정을 한다고 오해하지만, 실제로는 프로듀서가 이 결정을 담당한다.
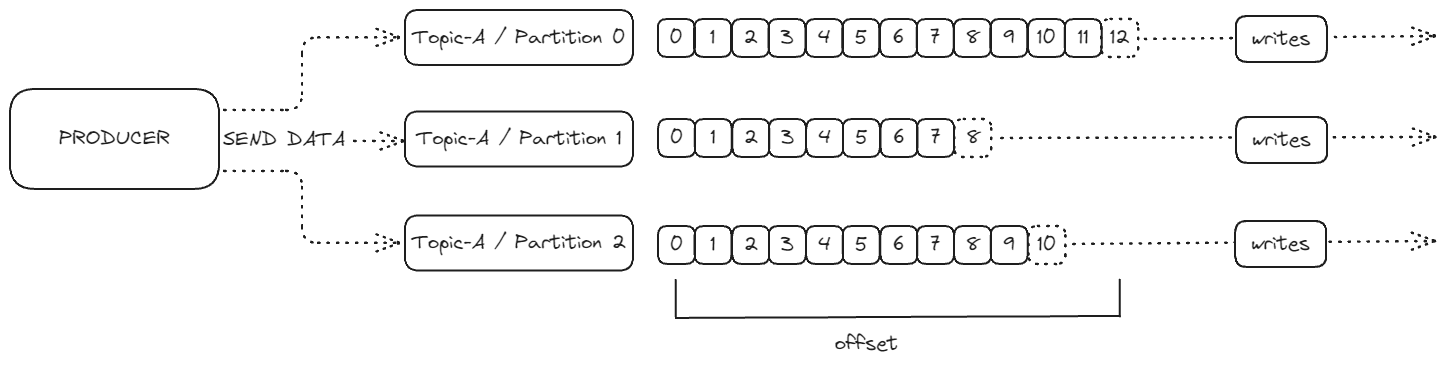
예를 들어, Topic-A라는 토픽에 파티션 0, 1, 2가 있다면, 프로듀서는 각 메시지가 어떤 파티션으로 갈지 결정하고 데이터를 전송한다. 또한 프로듀서는 특정 파티션에 장애가 발생했을 때 어떻게 복구할지도 알고 있다.
로드 밸런싱과 스케일링
Kafka의 강점 중 하나는 로드 밸런싱 메커니즘을 통해 모든 파티션에 걸쳐 데이터를 분산시킨다는 점이다. 토픽 내에 여러 파티션을 두고, 각 파티션이 하나 또는 여러 프로듀서로부터 메시지를 받을 수 있기 때문에 Kafka는 효과적으로 스케일링된다.
메시지 키와 파티션 할당(Default 파티셔너의 작동 원리)
프로듀서가 보내는 메시지에는 메시지 키를 포함할 수 있다. 이 키는 선택사항이며, 문자열, 숫자, 바이너리 등 다양한 형태가 될 수 있다.
메시지 키에 따라 파티션 할당이 달라진다:
1. 키가 null인 경우:
키가 null인 경우, Kafka 버전에 따라 다른 전략이 적용된다:
- Kafka 2.3 이전: 라운드 로빈(Round Robin) 방식
- Kafka 2.4 이상: 스티키 파티셔너(Sticky Partitioner) 방식
라운드 로빈(Round Robin) 방식
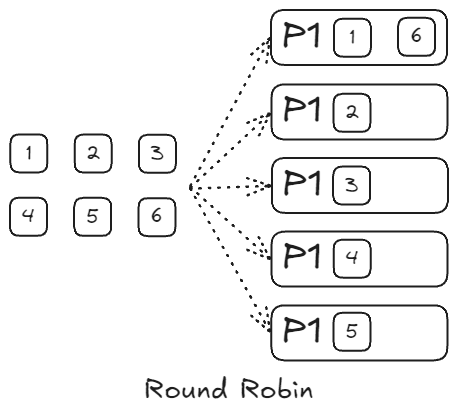
라운드 로빈은 프로세스나 데이터를 순차적으로 돌아가며 균등하게 분배하는 알고리즘이다.
주요 특징:
- 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 자원을 할당한다.
- 보통 시간 단위는 10ms ~ 100ms 정도다.
- 할당된 시간이 끝나면 해당 프로세스는 대기열의 맨 뒤로 이동한다.
- 모든 대상에게 요청을 차례대로 전달하는 방식으로 동작한다.
장점:
- 구현이 간단하고 효율적
- 모든 프로세스가 CPU를 독점하지 않고 공평하게 이용할 수 있음
- 대화형 시스템에 유용함
단점:
- 시간 할당량이 너무 크면 FCFS(First-Come, First-Served) 스케줄링과 유사해짐
- 시간 할당량이 너무 작으면 문맥 교환(Context Switching)에 따른 오버헤드가 크게 증가
- 대상의 상태나 부하를 고려하지 않고 균등하게 분산하므로, 성능이 다른 대상들 사이에서는 비효율적일 수 있음
스티키 파티셔너(Sticky Partitioner) 방식
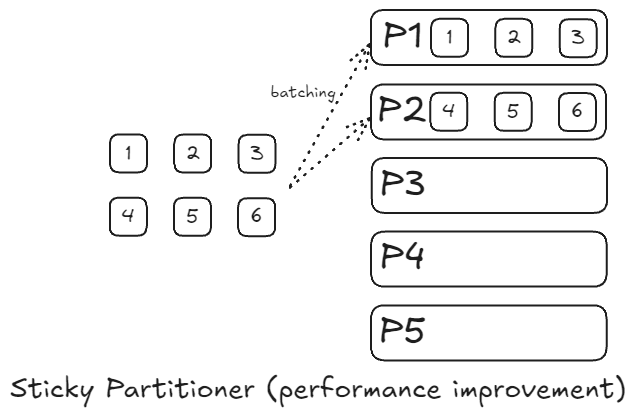
스티키 파티셔너는 카프카 2.4 버전부터 도입된 파티셔닝 알고리즘으로, 기존 라운드 로빈 방식의 단점을 개선하기 위해 설계되었다.
주요 특징:
- 배치(batch)로 묶어서 메시지를 처리한다.
- 배치가 가득차거나 linger.ms가 경과할 때까지 파티션을 "고정"한다.
- 배치를 전송한 후 고정된 파티션을 변경한다.
- 레코드가 할당된 파티션 수가 적어지며, 배치에 할당된 레코드의 수가 많아진다.
장점:
- 라운드 로빈에 비해 성능이 향상됨(테스트 결과 최대 1.5배~5배 성능 차이)
- 배치 처리를 통해 네트워크 요청 수를 줄이고 처리량을 증가시킴
- CPU 사용량도 줄어듬
단점:
- 특정 브로커의 latency가 느리면 불균형이 발생할 수 있음
- "느린 브로커"가 담당하는 파티션은 브로커의 느린 응답을 기다리면서 배치에 레코드가 쌓이는 시간이 길어짐
두 방식의 비교
라운드 로빈은 모든 파티션에 균등하게 메시지를 분배하는 반면, 스티키 파티셔너는 배치 처리를 통해 효율성을 높인다. 라운드 로빈은 메시지 전송 요청이 들어오는 대로 파티션을 순회하면서 전송하지만, 스티키 파티셔너는 배치로 레코드를 묶어서 한 번에 전송한다.
파티션 수가 많아질수록 두 방식의 성능 차이는 더욱 커지며, 스티키 파티셔너가 더 나은 성능을 보인다. 카프카 3.4 버전부터는 파티션 불균형 문제를 해결하기 위해 Strictly Uniform Sticky Partitioner가 도입되었다.
결론적으로, 처리량과 효율성이 중요한 시스템에서는 스티키 파티셔너가 더 적합하며, 균등한 분배가 중요한 시스템에서는 라운드 로빈이 더 적합할 수 있다.
성능 비교
Confluent의 성능 테스트에 따르면, 스티키 파티셔너는 다음과 같은 성능 향상을 보여준다:
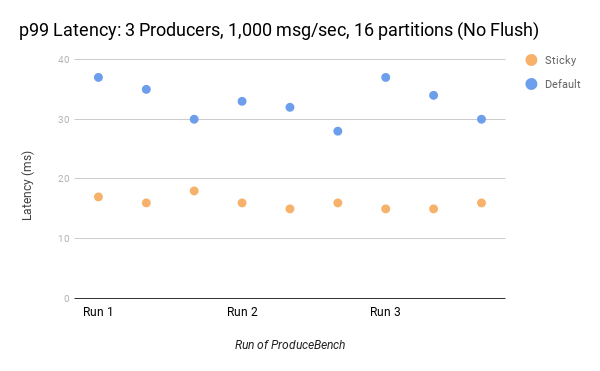
- 3개 프로듀서, 16개 파티션, 초당 1,000 메시지 환경에서 P99 지연 시간이 약 50% 감소
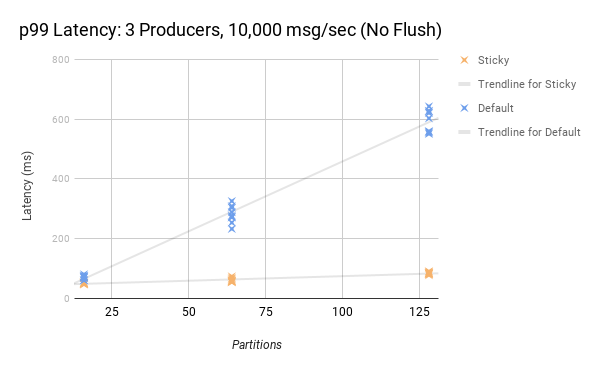
- 파티션 수가 증가할수록 성능 차이가 더 커짐
- 128개 파티션 환경에서는 기존 방식보다 지연 시간이 현저히 낮음
- CPU 사용량도 감소
특히 linger.ms 값이 설정된 경우(예: 1,000ms), 스티키 파티셔너는 기존 방식보다 최대 5배 낮은 지연 시간을 보여준다.
2. 키가 있는 경우:
Kafka의 Default 파티셔너는 키가 null이 아닌 경우 다음과 같은 방식으로 파티션을 결정한다:

targetPartition = Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions이 과정을 "키 해싱(Key Hashing)"이라고 하며, 다음과 같은 특징이 있다:
- 결정적(Deterministic): murmur2 알고리즘은 예측 가능한 해시 함수로, 동일한 키는 항상 동일한 파티션에 할당된다.
- 파티션 수에 의존: 계산식에
numPartitions가 포함되어 있어, 토픽의 파티션 수가 변경되면 키-파티션 매핑이 바뀐다.
중요: 토픽에 파티션을 추가하면 기존 키-파티션 매핑이 변경될 수 있으므로, 키 순서가 중요한 경우 파티션을 추가하는 대신 새 토픽을 생성하는 것이 좋다.
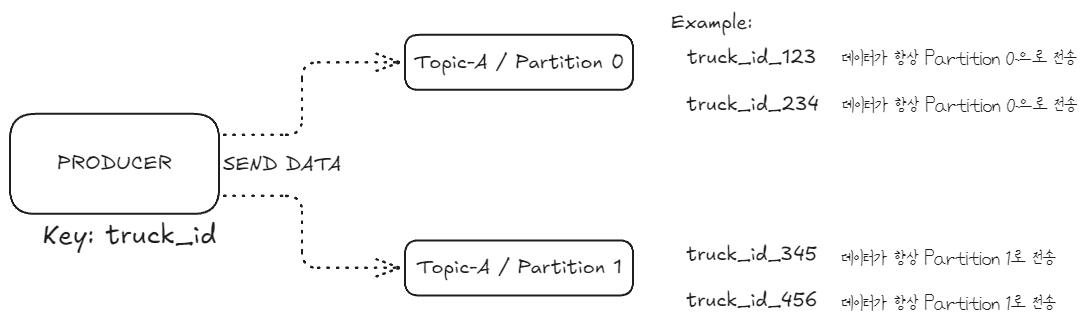
예를 들어, 트럭의 위치 데이터를 추적하는 시스템에서 truck_id를 키로 사용한다면, truck_id_123의 모든 메시지는 항상 같은 파티션(예: 파티션 0)으로 전송된다. 이렇게 하면 특정 트럭의 데이터를 순서대로 읽을 수 있다.
Kafka 메시지의 구조
Kafka 메시지는 다음과 같은 구성 요소를 가진다:
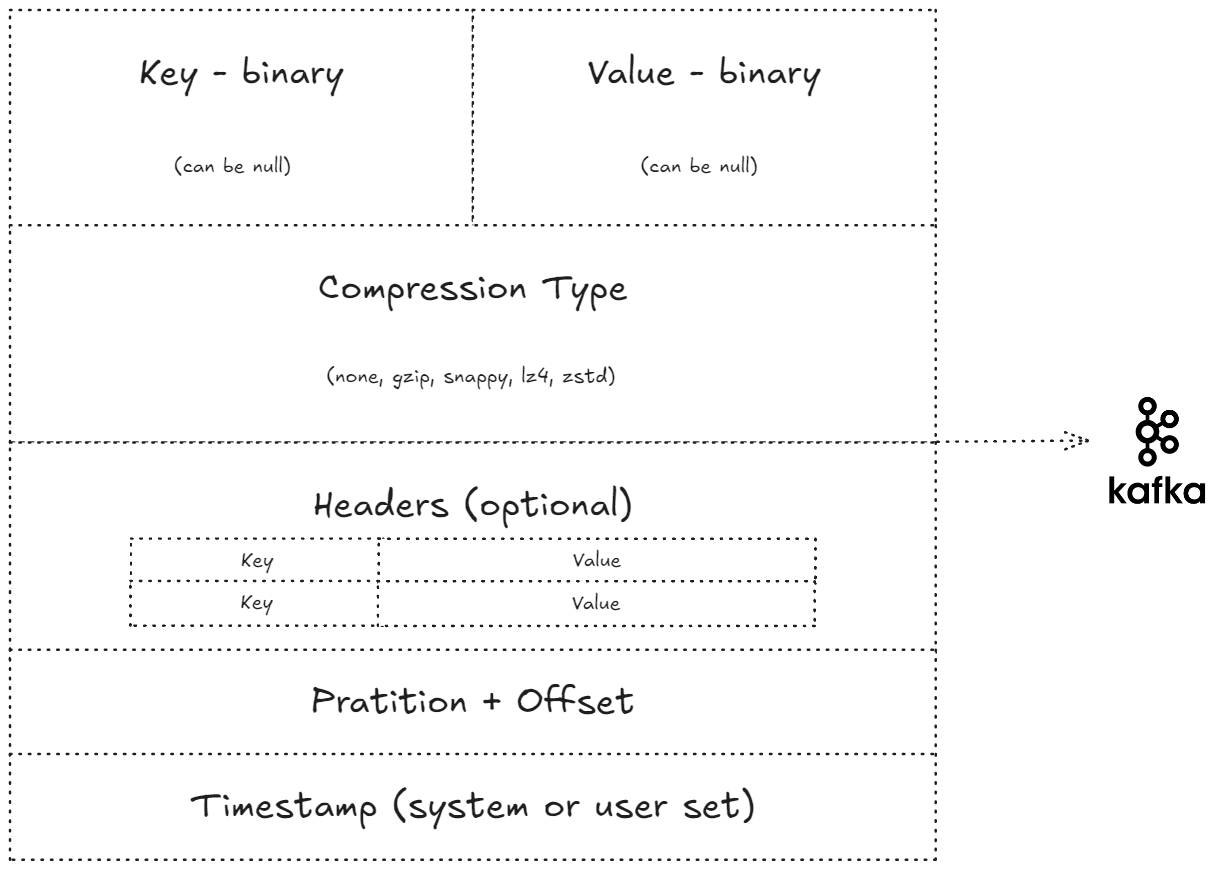
- 키(Key): 바이너리 형식, null일 수 있음
- 값(Value): 메시지의 실제 내용, 바이너리 형식
- 압축 타입: 선택적으로 gzip, snappy, lz4, zstd 등의 압축 메커니즘 지정 가능
- 헤더: 선택적인 키-값 쌍 리스트
- 파티션과 오프셋: 메시지가 전송될 대상
- 타임스탬프: 시스템 또는 사용자가 설정
메시지 직렬화(Serialization)
Kafka는 바이트 형태로만 데이터를 주고받는다. 따라서 프로듀서는 객체나 데이터를 바이트로 변환하는 직렬화 과정이 필요하다.
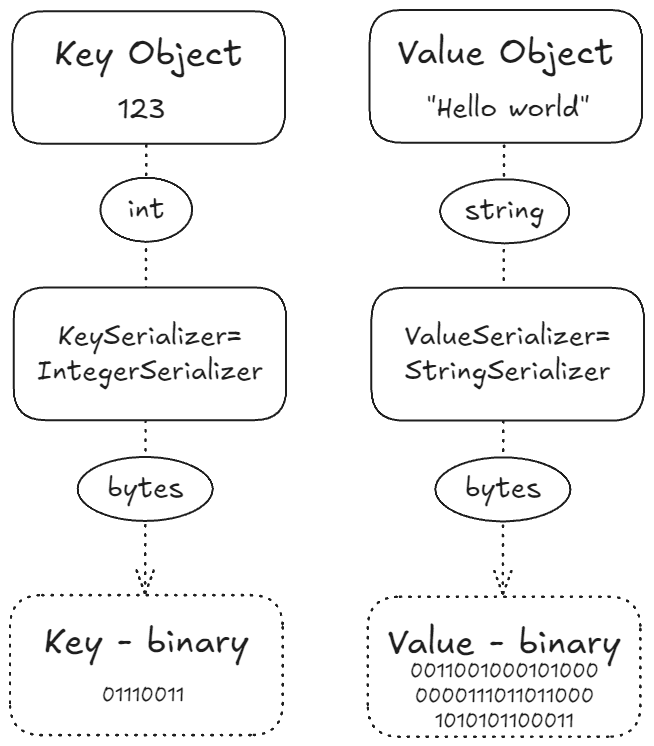
예를 들어:
- 키 객체가 트럭 ID인 123이고
- 값이 "hello world"라는 문자열이라면
이를 Kafka로 전송하기 위해 직렬화가 필요하다:
1. KeySerializer를 IntegerSerializer로 지정하여 123을 바이너리로 변환
2. ValueSerializer를 StringSerializer로 지정하여 "hello world"를 바이너리로 변환
Kafka는 다양한 기본 Serializer를 제공한다:
- String (JSON 포함)
- Int, Float
- Avro, Protobuf 등
고급 내용: 키 해싱과 파티션 할당
Kafka는 파티셔너라는 코드 로직을 사용하여 메시지가 어떤 파티션으로 갈지 결정한다. 프로듀서가 send()를 호출하면, 파티셔너가 레코드를 확인하고 적절한 파티션을 지정한다.

기본 Kafka 파티셔너는 murmur2 알고리즘을 사용하여 키를 해싱한다. 이 알고리즘은 키의 바이트를 분석하여 어떤 파티션으로 메시지를 전송할지 결정한다.

이 내용은 고급 주제이므로 완전히 이해하지 못해도 걱정하지 말자 중요한 점은 프로듀서가 키를 기반으로 메시지의 목적지 파티션을 결정한다는 것이다.
Kafka 프로듀서에 대한 이해는 효과적인 메시징 시스템을 구축하는 데 중요한 기초가 된다.
