Kafka 2.4 버전부터 도입된 '가장 가까운 레플리카 읽기(Closest Replica Fetching)' 기능은 멀티 데이터센터 환경에서 Kafka를 운영할 때 레이턴시와 네트워크 비용을 크게 줄일 수 있는 중요한 기능이다.
기존 Kafka 컨슈머의 동작 방식

Kafka 2.4 이전 버전에서는 컨슈머가 항상 파티션의 리더 레플리카에서만 데이터를 읽어왔다. 이러한 구조에서는 다음과 같은 문제가 발생할 수 있다:
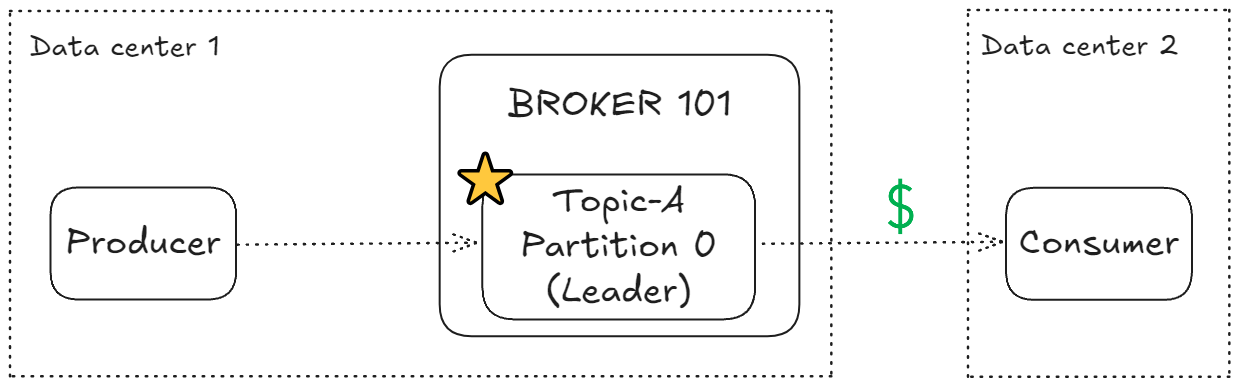
- 높은 레이턴시: 컨슈머가 리더 레플리카와 다른 데이터센터에 위치할 경우 네트워크 지연이 발생
- 추가 네트워크 비용: 특히 클라우드 환경(예: AWS)에서 가용 영역(AZ) 간 데이터 전송 시 추가 비용 발생
가장 가까운 레플리카 읽기의 장점
Kafka 2.4부터 도입된 가장 가까운 레플리카 읽기 기능을 사용하면 다음과 같은 이점이 있다:
- 레이턴시 감소: 컨슈머가 물리적으로 가장 가까운 레플리카에서 데이터를 읽어 응답 시간 단축
- 네트워크 비용 절감: AWS와 같은 클라우드 환경에서 가용 영역 간 데이터 전송 비용 감소
- 리더 부하 분산: 모든 읽기 요청이 리더에 집중되지 않아 리더의 부하 감소
AWS MSK를 사용하는 경우, 가장 가까운 레플리카 읽기를 통해 가용 영역 간 트래픽 비용을 최대 2/3까지 절감할 수 있다.
작동 원리
가장 가까운 레플리카 읽기 기능은 다음과 같이 작동한다:
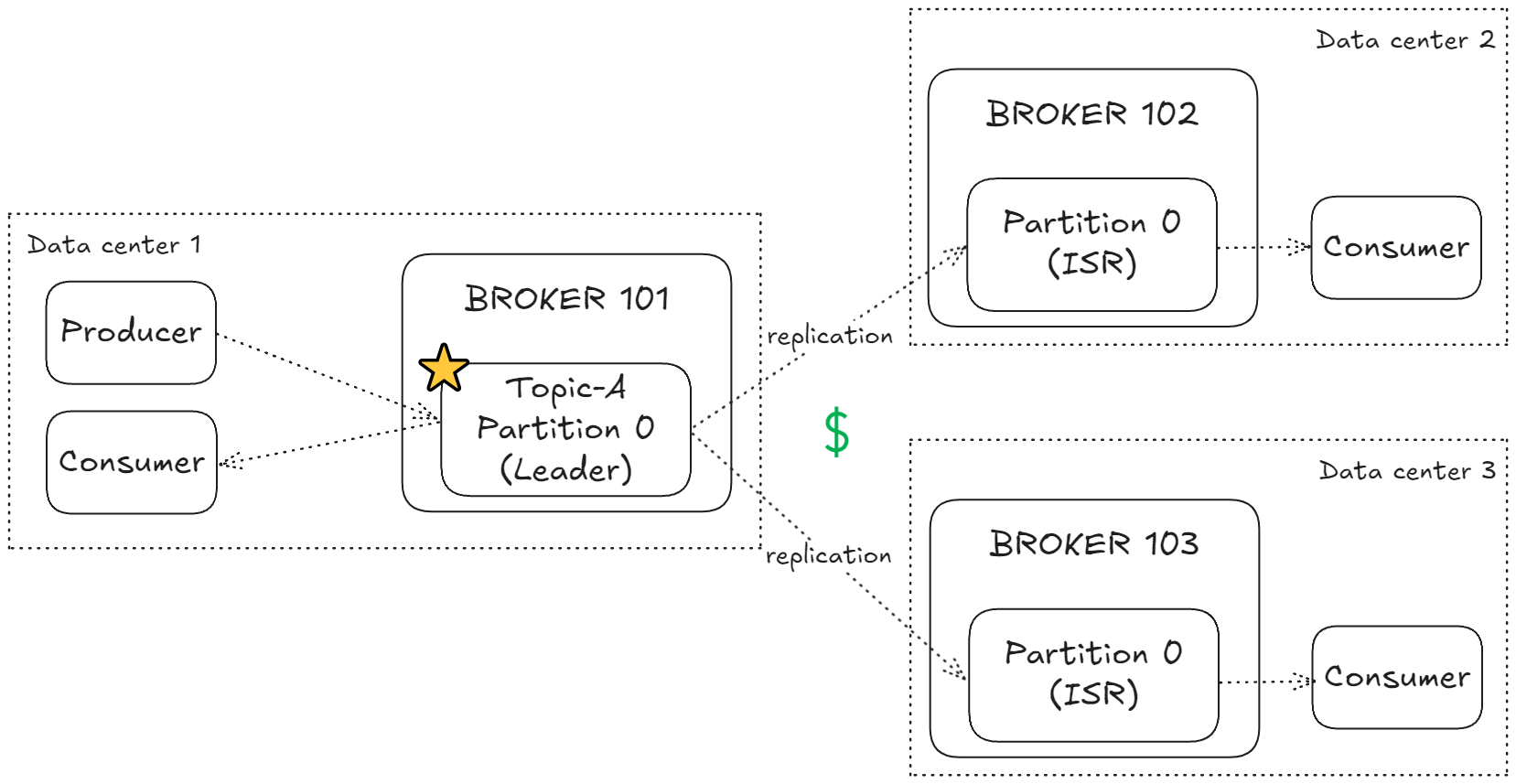
- 각 브로커와 컨슈머에 '랙 ID(Rack ID)'를 할당한다. 이 ID는 보통 데이터센터나 가용 영역을 식별한다.
- 컨슈머가 데이터를 요청할 때, Kafka는 컨슈머의 랙 ID와 동일한 랙 ID를 가진 레플리카를 찾는다.
- 동일한 랙 ID를 가진 레플리카가 있으면, 컨슈머는 리더 대신 해당 레플리카에서 데이터를 읽는다.
- 동일한 랙 ID를 가진 레플리카가 여러 개 있는 경우, 가장 최신 상태의 레플리카가 선택된다.
- 동일한 랙 ID를 가진 레플리카가 없으면, 기본적으로 리더 레플리카에서 데이터를 읽는다.
설정 방법
브로커 측 설정
- Kafka 버전 확인: Kafka 2.4 이상 버전이 필요하다.
- broker.rack 설정: 각 브로커의 물리적 위치를 나타내는 랙 ID 설정
broker.rack=usw2-az1 # AWS의 경우 가용 영역 ID 사용 - replica.selector.class 설정: 랙 인식 레플리카 선택기 활성화
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
컨슈머 측 설정
컨슈머 구성에 client.rack 속성을 추가하여 컨슈머가 위치한 랙 ID를 지정한다:
client.rack=usw2-az1 # 컨슈머가 실행 중인 데이터센터/가용 영역 ID멀티 레벨 랙 인식 설정 (고급)
더 복잡한 인프라 구조를 가진 환경에서는 멀티 레벨 랙 인식을 구성할 수 있다:
- 멀티 레벨 랙 ID는 절대 경로 형식을 사용한다 (예:
/DC1/Rack1). - 컨슈머의 랙 ID가 브로커의 랙 ID와 부분적으로만 일치해도 가장 가까운 레플리카를 찾을 수 있다.
예를 들어:
- 브로커 레플리카 위치:
/DC1/R1과/DC2/R3 client.rack=/DC1→/DC1/R1레플리카 선택client.rack=/DC2/R5→/DC2/R3레플리카 선택client.rack=/DC3→ 리더 레플리카 선택 (일치하는 DC가 없음)
설정 확인 방법
설정이 제대로 적용되었는지 확인하려면 컨슈머 로깅 레벨을 DEBUG로 설정한다:
log4j.logger.org.apache.kafka.clients.consumer.internals.Fetcher=DEBUG로그에서 다음과 같은 내용을 확인할 수 있다:
DEBUG [Consumer clientId=consumer-1, groupId=console-consumer-12345] Sending READ_UNCOMMITTED fetch for partitions [order-0] to node b-3.mskcluster.jcojml.c23.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az1) (org.apache.kafka.clients.consumer.internals.Fetcher)이 로그는 컨슈머가 use1-az1 랙에 있는 브로커에서 데이터를 가져오고 있음을 보여준다.
결론
Kafka의 가장 가까운 레플리카 읽기 기능은 멀티 데이터센터 환경에서 레이턴시를 줄이고 네트워크 비용을 절감할 수 있는 강력한 도구다. 특히 클라우드 환경에서 Kafka를 운영할 때 이 기능을 활용하면 상당한 비용 절감 효과를 얻을 수 있다.
Kafka 2.4 이상 버전을 사용하고 있다면, 랙 인식 기능을 설정하여 컨슈머가 가장 가까운 레플리카에서 데이터를 읽도록 구성해보자 특히 대규모 분산 시스템에서 성능과 비용 효율성을 크게 향상시킬 수 있다.
