Kafka 컨슈머 그룹이 장시간 실행될 때 안정적으로 작동하기 위해서는 내부 메커니즘과 주요 설정을 이해하는 것이 중요하다.
컨슈머 그룹의 핵심 메커니즘
Kafka 컨슈머 그룹은 두 가지 중요한 메커니즘을 통해 상태를 유지한다:
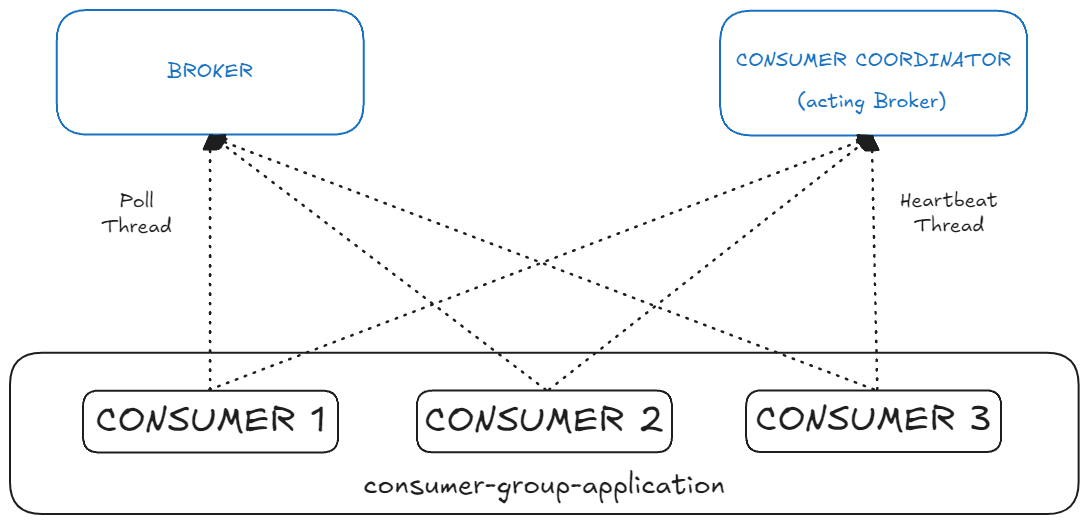
- 허트비트 스레드(Heartbeat Thread): 컨슈머가 활성 상태임을 브로커에 주기적으로 알리는 메커니즘
- 폴 스레드(Poll Thread): 실제로 데이터를 요청하고 처리하는 메커니즘
이 두 메커니즘은 컨슈머의 상태를 모니터링하고, 문제가 발생했을 때 적절한 리밸런싱을 트리거하는 데 중요한 역할을 한다.
허트비트 메커니즘
허트비트는 컨슈머가 그룹 코디네이터(Group Coordinator)에게 주기적으로 보내는 신호로, 컨슈머가 여전히 활성 상태임을 알린다.
주요 설정:
-
heartbeat.interval.ms: 허트비트 신호를 보내는 주기 (기본값: 3초)
- 일반적으로 session.timeout.ms의 1/3로 설정하는 것이 권장됨
-
session.timeout.ms: 컨슈머가 허트비트를 보내지 않을 때 실패로 간주하는 시간 (기본값: Kafka 3.0 이전 10초, 이후 45초)
- 빠른 리밸런싱을 원한다면 낮게 설정 (예: 4초)
- 네트워크 지연이 있는 환경에서는 높게 설정 (예: 30초 이상)
허트비트 메커니즘은 컨슈머 프로세스 자체가 살아있는지 확인하는 데 초점을 맞춘다. 컨슈머 애플리케이션이 충돌하거나 종료되면 허트비트가 중단되고, 그룹 코디네이터는 session.timeout.ms 이후에 해당 컨슈머를 그룹에서 제거한다.
폴(Poll) 메커니즘
폴 메커니즘은 컨슈머가 실제로 데이터를 처리하는 능력을 모니터링한다. 컨슈머는 poll() 메서드를 호출하여 데이터를 요청하고 처리한다.
주요 설정:
-
max.poll.interval.ms: 두 번의 poll() 호출 사이의 최대 허용 시간 (기본값: 5분)
- 데이터 처리가 빠른 애플리케이션: 20초 정도로 설정
- 처리 시간이 긴 애플리케이션: 필요에 따라 증가 (예: 3시간)
-
max.poll.records: 한 번의 poll() 호출에서 반환되는 최대 레코드 수 (기본값: 500)
- 메시지 크기가 작을 경우: 값을 높여 처리량 증가
- 메시지 크기가 크거나 처리가 복잡할 경우: 값을 낮춰 처리 시간 단축
폴 메커니즘은 컨슈머가 데이터를 처리하는 능력을 모니터링한다. 만약 컨슈머가 max.poll.interval.ms 내에 다음 poll()을 호출하지 않으면, 그룹 코디네이터는 해당 컨슈머가 처리 능력을 상실했다고 판단하고 리밸런싱을 트리거한다.
데이터 가져오기(Fetch) 관련 설정
컨슈머의 데이터 가져오기 동작을 최적화하기 위한 설정들이다:
기본 가져오기 설정
-
fetch.min.bytes: 요청당 가져올 최소 데이터 양 (기본값: 1바이트)
- 값을 높이면 처리량은 증가하지만 레이턴시도 증가
- 예: 1MB로 설정하면 최소 1MB의 데이터가 모일 때까지 대기
-
fetch.max.wait.ms: fetch.min.bytes를 충족하지 못할 때 최대 대기 시간 (기본값: 500ms)
- 예: fetch.min.bytes가 1MB이고 fetch.max.wait.ms가 5000ms일 때, 5초 동안 1MB가 모이지 않으면 그대로 반환
고급 가져오기 설정
-
max.partition.fetch.bytes: 파티션당 가져올 최대 데이터 양 (기본값: 1MB)
- 많은 파티션을 구독할 경우 메모리 사용량에 주의
- 예: 100개 파티션 구독 시 최소 100MB RAM 필요
-
fetch.max.bytes: 요청당 가져올 전체 데이터의 최대 양 (기본값: 50MB)
- 브로커 설정인 fetch.max.bytes(기본값 55MB)보다 클 수 없음
- 메모리가 충분하다면 값을 높여 처리량 증가 가능
최적화 전략 및 권장사항
-
빠른 실패 감지가 필요한 경우:
- heartbeat.interval.ms: 1초
- session.timeout.ms: 4초
- 장점: 컨슈머 장애 시 빠른 리밸런싱
- 단점: 네트워크 지연 시 불필요한 리밸런싱 발생 가능
-
처리 시간이 긴 작업을 수행하는 경우:
- max.poll.interval.ms: 처리 시간보다 충분히 길게 설정
- max.poll.records: 처리 시간을 고려하여 적절히 조정
- 예: 처리에 1시간 걸리는 작업의 경우 max.poll.interval.ms를 2-3시간으로 설정
-
높은 처리량이 필요한 경우:
- fetch.min.bytes: 높게 설정 (예: 1MB)
- max.partition.fetch.bytes: 메모리 허용 범위 내에서 높게 설정
- fetch.max.bytes: 메모리 허용 범위 내에서 높게 설정
-
낮은 레이턴시가 필요한 경우:
- fetch.min.bytes: 낮게 유지 (기본값)
- fetch.max.wait.ms: 낮게 설정 (예: 100ms)
결론
Kafka 컨슈머의 허트비트와 폴 메커니즘은 컨슈머 그룹의 안정성과 효율성을 보장하는 핵심 요소다. 대부분의 경우 기본 설정으로도 충분하지만, 특정 요구사항이나 성능 문제가 있을 때 이러한 설정을 조정하여 최적화할 수 있다.
일반적으로 데이터를 빠르게 처리하고 자주 폴하는 것이 좋으며, 설정을 변경할 때는 한 번에 하나씩 변경하고 그 영향을 모니터링하는 것이 중요하다. 특히 대규모 시스템에서는 이러한 설정이 전체 시스템 성능에 큰 영향을 미칠 수 있으므로 신중하게 접근해야 한다.
