Abstract
로봇 작업 계획 및 그립 감지 프레임워크 RoboDexVLM 소개.
기존 방법들은 단순화되고 제한된 조작작업에 초점을 맞추어, 다양항 형태의 물체를 장기 시퀀스로 조작하는 데 필요한 복잡성을 간과함.
이에 반해 다양한 형태의 크기의 물체를 파지할 수 있는 hand를 활용하여 자연어 명령 기반으로 작업 수행
1. VLM 활용하여 task-level recovery mechanism을 포함한 robust task planner를 설계 -> open-vocabulary 명령 해석하고 long sequence task를 실행 가능
2. robot kinematics와 formal methods에 기반하여 설계된 language-guided dextrous grasp perception 알고지름 제안 -> 다양한 물체와 명령에 대해 zero-shot으로 정교한 조작을 수행 할 수 있도록 설계됨
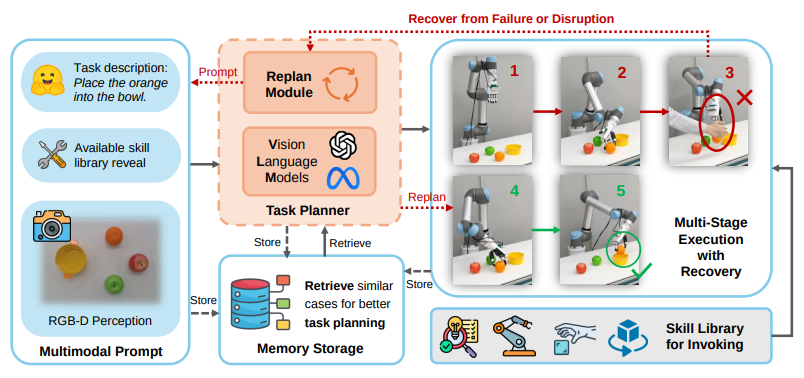
1. Introduction
RoboDexVLM은 시각 정보와 자연어 명령을 통합하여 로봇이 intent를 해석하고 skill library를 기반으로 task hierachy을 추론하며 상황에 따라 동적으로 planning 해줌. 특히 손과 결합될 때, context-aware조작을 실현하여 real-world 환경에서 seamlessly 동작 기반 마련.
주요 Contribution
- RoboDexVLM 프레임워크 제안
- VLM 기반 자동작업 계획 파이프라인과 modular skill library를 통합하여 long-horizon 다관절 조작 -> 고수준 계획과 저수준 제약을 효과적으로 연결
- VLM 기반 작업 분해 및 복구 매커니즘 통합
- open-vocabulary commands로부터 primitive(원시 행동 단위) 기반의 작업 분해 및 실행 가능
- robust task planner는 user intent를 해석하고 grasp pose를 최적화하며, reflection 기능을 활용한 failure recovery 메커니즘을 통해 장기 정응성을 확보
- 실험적 검증
- real-world에서의 실험 많이함
- 복잡한 환경에서의 stable dexterous grasping, 새로운 물체에 대한 적응성 등등 확인
2. Language-Ground Manipulation with Canonical Primitives
A. Task Planning with Manipulation Primitives
RoboDexVLM 프레임워크는 high-level task planning과 low-level execution 사이의 간극을 스킬 라이브러리를 통해 매끄럽게 연결함으로써 로봇 조작에서 진전 이뤄냄. 스킬 라이브러리는 제로샷 조작을 가능하게 하는 핵심임.
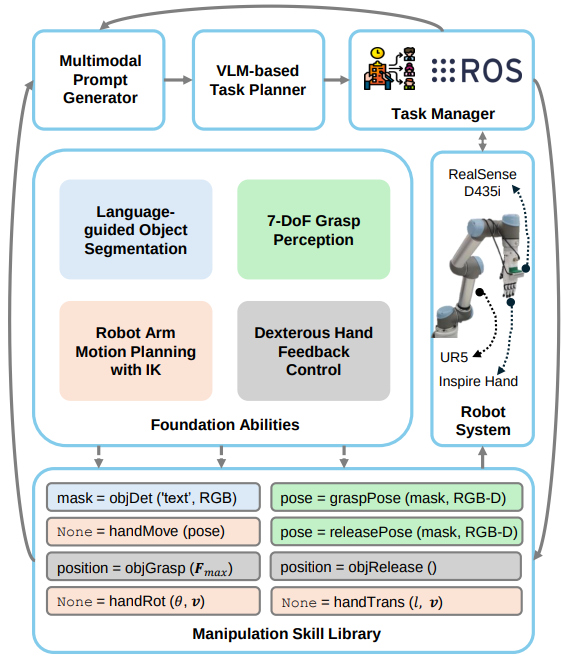
스킬 라이브러리
스킬 라이브러리 S={F1(X1),F2(X2),⋯,Fn(Xn)} 는 manipulation primitive를 formalize하면서 language input에 의해 유연하게 조정될 수 있도록 설계됨
- 각 스킬 단위 F_i는 특정 동작을 활성화하기 위한 input I_i를 가짐.
- i에 해당하는 8개의 기본 스킬로 구성되어 있으며, detecting, grasping, moving, placing 등 기본 조작 행위 포괄함 - 각 스킬은 위 그림에 나옴
서로 독립적으로 동작할 수 있고 유기적으로 결합됨
VLM 기반 스킬 시퀀스 생성
RoboDexVLM은 VLM활용하여 스킬 순서와 필요한 파라미터를 자동으로 생성함.
다음의 prompt-reasoning 과정으로 정의됨
{Rτ,Oτ,Iτ}=T(K(S,Mτ,Lτ))
- K(): 컨택스트 생성기
- 입력요소
- S: 시스템 메시지, CoT 추록 템플릿 포함
- Mτ: 메모리 메시지 - 이전 작업의 상태 정보
- Lτ: 인산의 명령 - 시간단계 τ에서의 작업 설명
- T: VLM 추론 과정을 나타내는 함수
- 출력요소
- Rτ: CoT 기반 추론 텍스트 - VLM이 어떤 근거로 스킬 순서를 설계했는지
- Oτ: {O1, O2, ... Om} - 호출된 스킬의 순서. 각 O는 스킬 라이브러리의 스킬 중 하나
- I = {I1, I2, ... , Im - 각 스킬의 입력 파라미터, 해당 스킬 Fi의 동작을 활성화 하는 데 필요한 인자
B. Interaction Primitives for Skill Execution
각 스킬에 대해 표준화된 입출력 인터페이스(Fi(Xi)) 갖춤. VLM이 주어진 언어명령의 구체적인 요구 사항에 따라 스킬들을 동적으로 연결 할 수 있게 함.
아래와 같이 형식화된 dynamic variable storage 유지함.
D={Elang,PRGB,PDepth,Bimg,G,Fmax,A}
- Elang: 이미지 분할을 위한 언어 지침
- PRGB, PDepth: 각각 RGB-D 이미지의 pixeel matrics를 표현
- Blang: Elang에 대한 semantic segmentation의 binary result가 저장됨
- G: 물체 파지를 위한 필수적인 geometric values 포함함
- Fmax: 물체와의 최대 접촉력
- A = {d,θ,r}: 로봇 동작을 위한 기하 벡터
각 스킬함수 F는 D를 조회(query)하여 실시간 조작에 필요한 갱신된 데이터를 가져올 수 있음
3. Skill Execution with Dexterous Manipulation
A. Perception-Action Paradigm
Robust한 동작을 위해 closed loop 실행 시스템으로 설계됨.
-
언어 기반 영상 분할
- 언어 임베딩 Elang과 실시간 시각 PRGB를 통합하여 semantic-level의 object mask를 생성함. DINO + SAM 사용하여 semantic mask(Bimg)로 정제함
-
파지 인식 및 자세 추론
RGB-D 데이터(PRGB, PDepth)와 분할 마스크 Bimg를 정렬하여 목표 객체 필터링 함. 그 다음 AnyGrasp 이용하여 파지자세 추론
이때 각 파지 자세 Gj에 대해 geometric-geometric alignment를 통해 pairwise correspondance score 계산함.
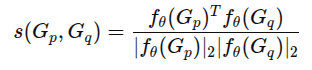
- fθ(): 학습된 네트워크 θ를 통해 파지 자세를 특징 벡터로 인코딩
- 모든 후보 간 유사도를 모아 Spq로 구성
- 후보 j의 신뢰도는 행 단위 합으로 계산됨
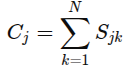
- 최적 파지는 아래 식으로 선택됨
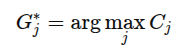
이는 PDepth에서 추론된 local geometry constraint내에서 공간적 일관성을 최대화 하는 자세
-> 후보들 중 가장 일관성 높은 자세 선택
- 동작 실행 및 궤적 계획
동작 실행 단계에서는 로봇 팔의 궤적을 Denavit-Hartenberg 운동학을 사용하여 계산함. 보간된 경유점은 엔드이펙터의 자세 제약을 유지하도록 최적화되며 부드럽고 안정적인 움직임을 보장함
B. Dexterous Manipulation Pose Generation
파지 제안
G={t,R,w}
t: 파지 중심
R: 회전 행렬
w: 그리퍼 폭
-> 그리퍼를 손 형태로 바꾸는 거. 내가 안쓸거라서 정리 안할겨
C. Recovery Strategy from Failures During Manipulation
Robust한 동작을 위해 dual-layer recovery mechanism을 적용함. 각 skill이 실행된 후에는 깊이 기반 변화 감지와 손 관절 피드백해서 성공 검증함.
실패하면 reflection prompt 생성함
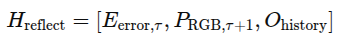
- Eerror,τ: 탐지된 오류 정보
- PRGB,τ+1: 실패 이후 시점의 현재 장면 상태 (RGB 이미지 입력)
- Ohistory ⊂ Oτ: 이전 스킬 실행의 history
이 프롬프트가 VLM으로 입력되어 reasoning 거침
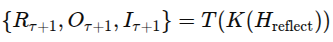
-> 이 입력 기반으로 adjusted skill sequence 제안함
무한 루프 방지하기 위해 마지막으로 성공한 스킬 이후부터 작업을 재ㅑ개함.
Experiment 는 그냥 표만 봐도 알 듯 -> 그리퍼 포지를 손으로 바꾼거 없으면 그닥 컨트리 뷰션이...
