Abstract
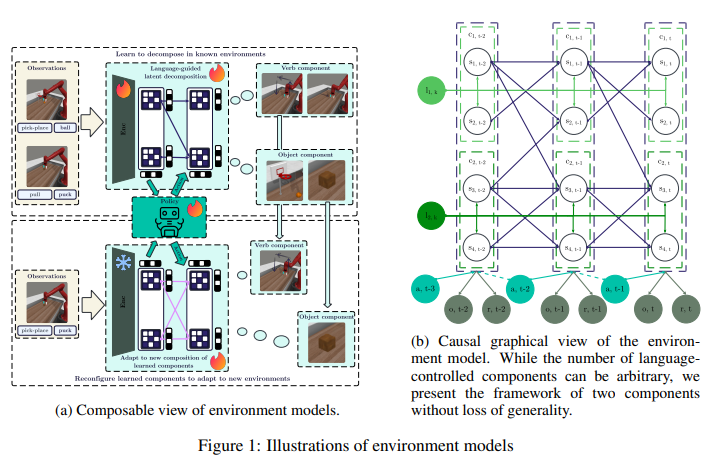
RL에서 일반화는 중요한 도전 과제이다. 에이전트가 이전에 보지 못한 동역학 가진 새로운 환경을 마주할 때 그러함. 이미 알고 있는 구성 요쇼들을 재조합하여 새로운 상황을 다루는 능력에서 영감 받아서 World Modeling with Compositional Causal Components, WM3C 제안함.
구성적 인과 구성요소(compositional causal components)를 학습하고 활용하여 강화학습 일반화 성능 향상. 기존 invariant representation learning이나 meta-learning에 초점을 둔 접근법과 달리, 조합 가능한 요소들 간의 인과적 동역학을 식별하고 활용하여 강건한 적응 가능하게 함.
언어를 compositional modality로 통합하여 latent space(잠재공간)을 의미 있는 구성요소들로 분해하여, 완화된 가정하에서 이 구성요소들이 고유하게 식별될 수 있다는 이론적 보장도 제공함.
실제 구현에서는 상호 정보 제약(mutual information costraint)과 적응적 희소성 정규화(adaptive sparsity regularization)를 결합한 마스크드 오토인코더(masked autoencoder)를 사용하여 고수준의 의미적 정보를 포착하고 전이 동역학을 효과적으로 분리함.
수치 시뮬과 실물 로봇 조작결과 기존 방법들이 비해 잠재적 과정(latent process)의 식별, 정책 학습(policy learning), 보지 못한 과제에 대한 일반화 측면에서 우수함
-> 기존 강화학습은 환경 전체를 한 덩어리로 배우려다 보니 새로운 환경에서는 일반화 어려움.
WM3C는 언어를 compositional cue로 활용해 요소로 나누고 각 구성요소가 어떻게 상호작용하는지를 학습함.
1. Introduction
DRL, DQN, SAC, PPO 등은 다양한 형태의 강화학습 과제들을 해결해 옴. DRL에서 가장 시급한 문제는 학습된 정책을 새로운, 보지 못한 환경으로 일반화하는 것
Ex): 공을 밀어서 A위치에 두는 작업 -> 공을 밀어서 B위치에 두는 작업 - 매우 안좋은 성능.
이는 특정 학습 환경에 대한 overfitting 때문. 특히 에이전트가 partially obserable env(부분관측 환경)에서 시각적 입력만을 받을 수 있는 경우, 새로운 환경에서의 관측 함수와 보상 함수의 변화를 포착하기는 더욱 어려움. -> 보지 못한 환경에서 변화가 발생한 지점을 찾아내고, 학습된 지식을 적응시켜, 그 변화를 수용하는 것은 일반화 가능한 에이전트를 만들기 위해 매우 중요함.
기존 연구들은 다양한 접근법 제시. 데이터 증강(data augmentation), 시각 인코더(visual encoder) 학습 도메인 내에서 가능한 시각적 변화를 포함시키는 방식으로 관측 함수의 변동에 대한 강건성 높이려고 함. -> 효과적인 증강을 위해 광범위한 도메인 지식에 의존하며, 학습 중 예상되지 않았던 state space와 dynamical structure의 변화에는 취약함.
불변 표현 학습(invariant representation learning)과 메타 강화학습(meta-RL) 은 여러 학습 과제들에 걸쳐 안정적인 과제-비특이적(task-agnostic)정보를 학습함으로써 새로운 관측으로의 일반화 시도함.
전자는 일관되고 전이 가능한 정보를 활용해 새로운 환경에서도 에이전트 성능 향상 -> 근본적으로 다른 동역학 구조 가진 환경에서는 한계
후잘는 새로운 과제에서 빠른 적응과 효율적인 학습을 가능하게 하는 메타 파라메터(meta-parameters)를 최적화하지만, 계산 비용이 높고, 환경의 다양성이 큰 경우 빠른 수렴을 보장하기 어려움.
*메타 학습
여러개의 과제를 경험하면서, 새 과제를 빠르게 학습하는 방법 자체를 학습하는 강화학습.
- 하나의 환경이 아니라 비슷하지만 서로 다른 많은 환경들을 준비 (마미로 구조가 매번 다르지만 출구 찾기라는 공통 구조 가진 여러 미로)
- 에이전트에게 이 다양한 task를 겪게 하면서 환경 규칙을 빨리 눈치채고 적은 경험으로 좋은 정책을 만드는 방식을 내부에 학습시키는 것.
- 새로운 task가 오면, 처음 보는 환경이어도 적은 step/episode만으로 성능 좋게 하기
RNN기반 메타 RL(RNN, LSTM 의 hidden state가 환경을 추론함), MAML 스타일 메타 RL(조금만 gradient 업데이트 해도 성능이 좋아지는 초기 파라메터를 학습)
모델 기반 강화학습은 다양한 환경에서 하이퍼파라메터에 대한 강건성을 보여줌. 데이터 효율성 면에서 우수하지만 world model이 실제 데이터 생성 과정의 모든 측면을 정확히 포착하지 못할 경우, 비최적의 planning과 새로운 상황에 대한 일반화 실패로 이어질 수 있음.
-> 일반화 가능한 세계 모델을 학습하기 위해 필요한 것은 무엇인가?
인간은 익숙한 구조로부터 알려지지 않은 상황으로 일반화 할 때, 구성적 방식으로 사고함. "push ball to place A"라는 과제를 push, ball, place A라는 구성 가능한 요소듥솨 그들 간의 관계로 학습함.
즉, 이러한 구성요소들과 동역학을 학습함으로써, 새로운 과제나 환경에 효율적으로 적응 가능. 이러한 compositional generalization을 실현하기 위해 causal struture를 이해하는 것. modularity(모듈성)와 sparsity(희소성)으로 특징지어지며 본질적으로 구성적 일반화 가능하게 한다. - 이는 각 구성요소가 독립적으로 학습될 수 있으며, 새로운 과제를 다룰 때 최소한의 수정만으로 재조합 될 수 있음
push와 ball 객체 사이 인과 관계 -> push와 puck 관계로 재사용 가능
World Modeling with Compositional Causal Components(WM3C) 에이전트가 구성 가능한 요소들을 식별하고, 그들 간의 인과적 동역학을 학습하며, 이를 효율적인 학습과 적응에 활용할 수 있도록 함.
기존 연구들(Huang et al., 2021; Liu et al., 2023; Feng & Magliacane, 2024)도 인과 표현 학습을 강화학습에 통합하려는 시도를 했지만, 구성 가능한 인과 요소를 학습하고 그 동역학을 이해함으로써 일반화를 향상시키는 접근은 없었음
구성적 모달리티인 '언어'를 활용. 또한 완화된 조건하에서(composed mild assumptions) 이러한 구성요소들과 그 동역학이 유일하게 식별될 수 있음(uniquely identifiable)을 이론적으로 증명함.
마지막으로 이러한 구성요소 통합하는 세계 모델 학습 알고리즘 제시하고, 이 접근법이 unseen tasks로 일반화되는 방식을 보여줌
Introduction 정리
기존 접근법
- 표현학습/데이터 증강: 시각적 변화에는 대응하지만, 새로운 동역학 구조나 상태공간 변화에는 약함.
- Meta-RL: 여러 과제에서 공통 패턴을 배워 빠른 적응 시도하지만 과제가 많아질수록 연산량 증가, 환경 다양성이 커질수록 일반화 성능 저하 -> 결국 새로운 환경에 완전히 적응하기는 어려움
WM3C의 핵심 아이디어
- 언어를 구성적 단서로 사용해서 'push', 'ball', 'place A'처럼 구성요소로 분해. 각 구성요소 간의 인과적 관계를 학습
- 이렇게 학습된 인과 구성요소들을 재조합해서 unseen env에 쉽게 적응 가능
2. World Model With Compositional Causal Components
formulation에서 motivation과 intuition 제시. 그 후, 올바른 식별을 보장하는 식별 이론 제시. 또한 환경모델과 식별 결과에 기반하여 구성된 world model 학습 프레임워크 보여줌
2.1 Motivation And Intuitions
인간
이미 알고 있는 과제들로부터 composable concepts를 추상화하고 이를 새로운 상황에서 재사용하는 compositional generalization를 수행함. 이 과정에서 언어가 핵심적인 역할을 함.
pick-place ball -> 동사: pick-place, 명사: puck 처럼 두 개의 잠재 구성요소를 가짐
이 과정은 인과적 시스템의 핵심 원리인 희소성(sparsity)과 모듈성(modularity)을 그대로 반영함.
- 희소성: 전체 중에서 실제로 영향을 주는 원인은 매우 일부에 불과하다. -> 분포변화가 발생해도 시스템 전체가 크게 변하지 않고 일부 구성요소만 최소한으로 변경되도록 보장한다.
- 모듈성: 인과 구성요소들을 독립적으로 식별하고 새로운 방식으로 재조합 할 수 있게 해주며, 이를 다른 시스템으로의 적응을 용이하게 한다.
이러한 인과적 관점에서 composable env model을 모델링하고자 한다. 이를 위해 Partially Obserable Markov Decision Process, POMDP를 확장된 그래프(augmented graph) 형태로 표현하여 환경 모델을 기술한다.
*c_i,t와 c_i는 같음
- 관측 시퀀스는
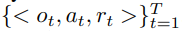
여기서 ot는 이미지, at는 action, rt는 reward 의미. - 잠재변수는
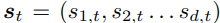
로 정의함. - 또한 N개의 언어 구성요소를 {l_1, ..., l_m}으로 둠
각 st가 m개의 언어 제어 구성요소 (c_1,t, ..., c_m,t)으로 유일하게 분해(unique partition) 될 수 있다고 가정함.
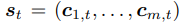
Proposition 1
환경 모델의 그래프 표현이 Markov 성질과 신실성(faithfulness: 삼단 논법 같은거)을 만족한다고 가정할 때, c_i,t는 언어 구성요소 l_i에 의해 직접 제어되는 상태 차원의 최소 부분집합이며 다음 조건을 만족한다. 즉, 특정 상태 변수 s_j,t가 c_i,t에 포함되는 조건은 다음과 같다. (s_j,t 시점 t에서 상태벡터 s_t 안의 여러 차원 중 하나) (c_i,t는 그 중에서 언어 l_i가 담당하는 부분 component)
ex): l_i='puck'이면 puck의 위치 속도 같은 상태축들이 c_i,t에 포함됨
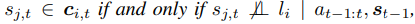
(즉 s_j,t는 언어 구성요소 l_i와 조건부 독립이 아님)
-> 이전 상태와 액션들을 알고 있어도 s_j,t와 언어 l_i 사이에 인과적 관계가 있다면 l_i에 의해 직접적으로 영향을 받음
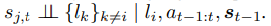
(즉 s_j,t는 다른 언어 구성요소들과는 조건부 독립임)
상태축 s_j,t가가 l_i에 의해 설명되면, 나머지 언어토큰들은 더 이상 아무 설명력을 추가하지 못한다.
-> 즉, l_i에 해당하는 s를 하나씩 매핑하겠다는 뜻
*조건부 독립
X⟂⟂Y: X와 Y는 독립이다.
X⟂⟂Y | Z: Z를 알고 있다는 조건하에서 X와 Y는 서로 독립이 아니다
직관적으로 말하자면, 언어제어구성요소(language-controlled components)란 각 언어 구성요소 l_i에 의해 직접적으로 제어되는 상태 차원들의 집합. 이 구조를 통해 모듈식이고 해석 가능한 환경 모델을 식별할 수 있다. 이로써 언어 구성요소의 지도를 바탕으로 잠재공간 내에서 구성정 일반화를 달성할 수 있다.
특히 보지 못한 테스트 도메인에서도 조건을 완화하여 개별 구성요소가 바로 이전 상태뿐만 아니라 모든 이전 상태에 영향을 받을 수 있도록 확장한다.
구성 가능한 구성요소(composable components)에 기반한 데이터 생성 과정은 아래와 같이 수식화 됨.
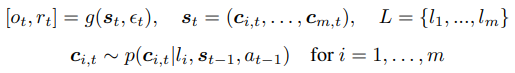
(식 1, 2)
-> 1번식:
관측(o_t)과 보상(r_t)는 잠재상태(s_t)와 노이즈(e_t)에 의해 생성된다
전체 상태 s_t(시점 t에서의 전체 상태)는 언어 구성요소들이 제어하는 여러 작은 부분들의 묶음
-> 2번식: "확률적으로 어떻게 다음 상태가 만들어 지는가?" -> 이전 상태와 직전 행동에 의해 결정된다.
*POMDP

현재 상태는 오직 이전 상태와 행동에 의존함
-> WM3C에서는 이 구조를 조금 확장해서 언어(l_i)를 추가함
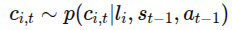
i번째 구성요소 c_i,t는 바로 직전의 상태(state)와 행동(action), 그리고 언어(l_i)에 의해 결정된다.
2.2 Identifiability Theory
일반화 할 수 있는 결고한 모델을 위해서 composable components와 causal dynamics(인과적 동역학)을 정확하게 식별하는 것이 중요함. 그러나 이 작업은 데이터 생성 과정의 불확실성과 복잡성 떄문에 매우 어려움
기존방식
비선형 ICA(Independent Component Analysis)관련 연구들은 노이즈 항의 독립성이나 특정 함수 형태에 대한 사전 가정과 같은 강한 가정을 사용해 차원별로 식별하는 방법을 제안함.
-> 상호 의존적인 잠재 구조를 가진 복잡한 시스템에서는 잘 작동하지 않음
-> 기존 비선형 ICA 방식은 x = f(x) 형태에서 관측된 데이터 x로부터 숨은 요인 s를 찾을 때, 함수 f나 노이즈 구조를 정해진 형태(가우시안 같은거)로 고정해놓고 뒤집어서 함
강한 constraint 때문에 식별 가능성이 보장되지만 실제로는 모델이 너무 제한적이고 계산 복잡&수렴 어려움
또한 확장성 안좋음 - static 해서
단일 보조 변수(single auxiliary variable)와 모수적 가정(parametric assumptions - 모델이 미리 정해진 형태의 수학식으로 가정되어 있고, 그 안에 있는 소수의 파라미터 값만 학습한다.,), 단순한 그래프 모델에 의존하기 때문에 확장성이 떨어진다. 또한 최적화 절차가 복잡하여 실제 환경에 적용하기 어렵다.
제안 방법
차원별(dimension-wise) 식별가능성 대신 블록별(block-wise) 식별가능성에 집중함으로써 확장성(scalability)과 추정 정확도(estimation accuracy) 사이의 균형을 더 잘 달성하고자 함.
이 접근은 각 언어구성요소가 그에 대응하는 잠재변수를 독립적으로 제어할 수 있도록 함. 기존의 단일 보조변수 기반 시계열 접근과 다름
모수적 가정 없이 언어가 제어하는 조합 가능한 구성 요소를 식별함으로써, 이론적 보장을 유지하면서도 훨씬 적은 수의 언어 구성요소 값으로도 식별이 가능함을 보여줌. - 언어에 국한 된 것이 아니라 제어신호에서도 적용 가능
-> 이 연구가 일반적인 비선형 상황에서 서로 다른 간헐적 제어 신호에 의해 독립적으로 제어되는 분리된 구성요소의 식별가능성을 처음으로 증명했다고 주장함.
Definition 1 (Block-wise Identifiability)
변화하는 변수 c_i의 실제 구성요소가 다음 조건을 만족할 때, 그 구성요소는 블록별로 식별가능하다고 한다.
추정된 변수 c^_i에 대해 각 구성요소 c_i에 대해 다음을 만족하는 가역함수(invertible function-뒤집을 수 있는 함수, 손실 없이 변환 가능한 함수) h_i가 존재한다면,
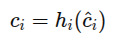
-> c^으로 h로 c를 얻을 수 있으면 블록이 식별가능하다
블록이 (위치x, 위치y) 같이 변수 묶음
- 식별가능하다: 각 잠재변수가 완전히 독립된 차원별로 식별되는 것
Theorem 1
데이터 생성 과정이 식 1,2를 따르고 아래 가정이 충족된다면, 언어로 제어되는 구성요소 c_i는 블록별로 식별가능하다.
-
혼합 함수 [ot,rt]=g(st,ϵt)는 가역적(invertible)이고 매끄럽다(smooth).
-> 관측으로부터 잠재 상태를 복원 가능해야 함 -
{si∈S ∣ p(si)=0}의 집합의 measure는 0이다.
-> 말이 안되는 특이 케이스는 제외(확률 0인거 제외) -
조건부 확률밀도는 p(si,t∣li,st−1,at−1)는 충분히 매끄러워야 하며, 최소한 1차 미분가능해야한다.
-> 분포가 너무 들쭉날쭉하면 안됨 -
언어구성요소 l_i, 이전상태, 액션이 주어졌을 때, 모든 잠재변수 s_j,t는 서로 조건부 독립이어야 한다.
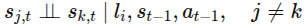
-> 언어 + 이전 상태, 액션 고정하면 잠재 변수끼리는 독립 -
각 c_i ∈ C_i에 대해, n_ci + 1 개의 l_i값이 존재하며, 그때 다음 행렬이 가역적이어야 한다.
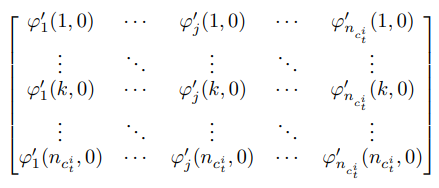
여기서
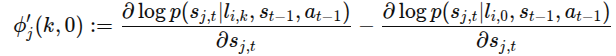
는 언어구성요소 l_i의 k번째 값과 0번째 값에 대한 로그밀도의 1차 미분 차이를 의미한다.
-> 언어 구성요소 l_i를 여러 값으로 바꿔봤을 때, 그 효과를 충분히 구분 할 수 있어야 함. : 이 언어 구성요소는 이 잠재 블록에 대응하구나 역추적 가능
이 가정들은 인과표현학습 분야에서 일반적으로 사용되는 것들이다.
이 가정들은 퇴화한 경우(degenerate case)를 방지하고, 모델의 조합 가능한 구성요소들이 일반적인 조건을 만족하도록 하여 인과구조 복구(causal structure recovery)가 가능하도록 돕는다.
위의 정리는 완화된 형태의 식별가능성을 제시한다. 즉, 각 언어로 제어되는 조합 가능한 구성요소 c_i에 대해 주어진 언어 구성요소에서 n_ci + 1개의 서로 다른 값이 존재한다면 각 실제 변수는 모든 추정된 변수의 함수로 표현될 수 있다.
모든 m개의 언어제어 구성요소를 식별하기 위해 테스크 수는 아래와 같다.
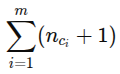
-> 환경 속 잠재 변수들의 서로 다른 부분을 독립적으로 조종한다면, 각 블록을 수학적으로 구분하고 해석할 수 있음. 블록 단위로 처리해서 현실 적용성 높임.
2.3 Learning Composable World Models
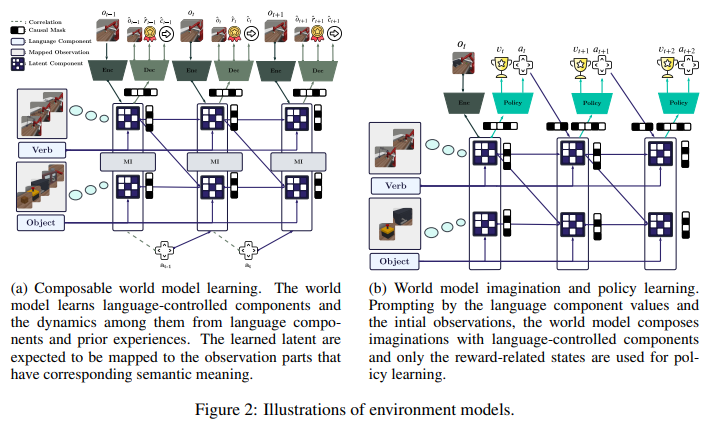
World Model은 agent의 상호작용 통해 composable components 식별하고 결합하는 composition rules을 학습함. 식별 가능성 결과에 기반. 학습 프레임워크는 모델 비종속적(agnostic)으로 구조에 의존 안함. 최신 모델 기반 강화학습 알고리즘인 DreamerV3에 사용함. 식별가능성 이론에서 도출된 통찰은 학습 과정의 지침으로 적용함.
Approximating invertible mixing function(가역적인 혼합 함수 근사)
invertible mixing function의 가역성을 충족하기 위해 기존의 인코더-디코더 구조를 사용함. 또한 정책 학습을 위한 continuation signal(연속 신호) 예측도 함께 학습함.
각 task u를 테스크 임베딩 z로 인코딩하는 학습 가능한 임베딩 함수를 도입하여, 디코딩 함수들이 도메인 간 변화를 더 잘 포착하도록 한다.
두가지 WM3C(World Model with Modular, Multimodal, and Compositional structure) 변형을 제시.
- 기본 구조를 CNN으로 사용하는 관측 인코더/디코더 모델
- Masked Auto-encoder(MAE) 기반 모델
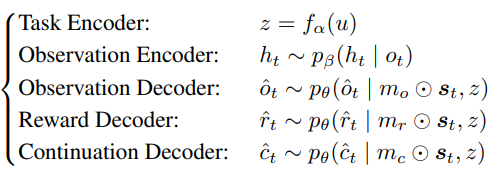
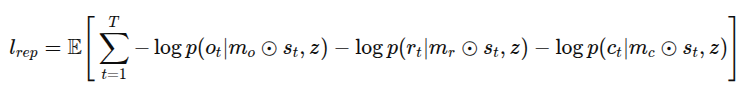
-> World Model의 인코더-디코더 구조를 어떻게 설계했나
관측, 보상, 연속 신호를 복원하는 인코더-디코더 구조를 만들고, 태스크 임베딩으로 도메인 차이를 흡수함.
Facilitating modular dynamics(모듈형 동역학 촉진)
환경 모델의 인과적 구조를 따르기 위해 전이 모델(transition model)과 표현 모델(representation model) 모두를 분리된 모듈(블록)로 분해한다. KL 정규화도 구성요소별 KL 발산으로 분리되어 구성요소 간의 독립성을 부드럽게 유도하는 제약으로 작용함.
언어 구성요소 l_i는 토큰 임베딩으로 인코딩되어 모델의 유연성을 높임

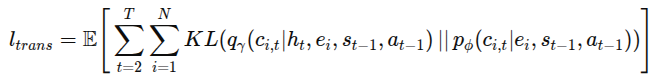
-> 환경의 각 언어로 제어되는 부분을 독립 모듈로 나누고, 서로 영향을 덜 받게 disentangled 하게 학습됨
Enhancing causal structure(인과 구조 강화)
식별 이론에 따르면 각 구성요소마다 충분한 값이 주어지면 추가 제약 없이도 그 구성요소를 식별할 수 있음. 그러나 실제에서는 언어 신호의 효과가 작을 때 학습이 어려워짐.
이를 해결하기 위해 상호정보량 제약(Mutual Information, MI)을 추가하여 환경 모델에 기술된 조건부 독립성(conditional independence)을 강화한다.
즉, 각 언어-제어 구성요소에 대해
- 해당 언어 구성요소와 그에 대응하는 구성요소 간의 MI를 최대화하고
- 다른 언어 구성요소들과의 MI는 최소화 한다.
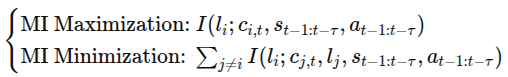
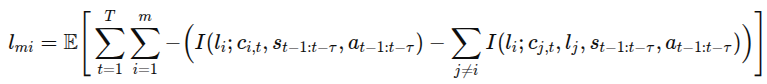
-> 언어-잠재 구성요소 간 연결을 명확히 하기 위해 MI 제약 추가. 각 언어 구성요소 l_i와 그에 해당하는 잠재 블록 c_i 사이의 MI는 최대화. 반대는 최소화
Enforcing sparse interactions(희소적 상호작용 적용)
현실의 인과 시스템은 대부분 sparse으로 대부분의 변수는 서로 직접적인 영향을 주지 않는다. 이를 반영하고 학습과 식별을 돕기 위해, 학습 가능한 mask를 세계 모델에 통합한다.
즉, 관측 디코딩, 보상 디코딩, 연속 신호 디코딩은 각각 일부 잠재변수 subset 만을 사용하며, 그 부분은 이진 마스크 m_0, m_r, m_c로 표현된다. adaptive L1 loss를 적용하여 희소성을 동적으로 제어함.
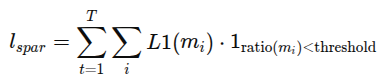
-> 진짜 필요한 변수만 쓰게 만들어서 인과 구조를 단순하고 해석 가능하게 유지함
총 학습 목적 함수
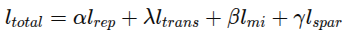
Policy learning
DreamerV3의 Soft Actor-Critic 구조 사용
태스크 임벧딩 z를 Actor와 Critic에 입력 -> 멀티태스크 대응
전체 잠재 상태 대신, 보상과 관련된 잠재 상태만 입력 - reward mask 사용
Quick Adaptation to New Compositions
테스트 중 같은 동사여도 다른 의미로 사용될 경우 - 동역학 관련 부분만 fine-tuning 하면 충분함
