논문
1.Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop (CoRL 2025, Justin Kerr Kush Hari Ethan Weber Chung Min Kim Brent Yi Tyler Bonnen Ken Goldberg Angjoo Kanazawa)

Link: https://www.eyerobot.net/사람은 수동적으로 보지 않는다. 이에 영감을 받아 EyeRobot시스템을 제안.주변을 관찰할 수 있는 eyeball을 고안 - RL에 gaze policy 사용함. 이건 360도 teleoperated 데
2.BeBOP - Combining Reactive Planning and Bayesian Optimization to Solve Robotic Manipulation Tasks (Jonathan Styrud et.al ICRA 2024)
논문주소: https://arxiv.org/abs/2310.00971?utm_source=chatgpt.com 깃허브 레포: https://github.com/jstyrud/BeBOP Abstract 새로운 작업에 대해 손쉽게 구성될 수 있어야 함 Behavior-b
3.RoboDexVLM: Visual Language Model-Enabled Task Planning and Motion Control for Dexterous Robot Manipulation(IROS 2025)
로봇 작업 계획 및 그립 감지 프레임워크 RoboDexVLM 소개.기존 방법들은 단순화되고 제한된 조작작업에 초점을 맞추어, 다양항 형태의 물체를 장기 시퀀스로 조작하는 데 필요한 복잡성을 간과함.이에 반해 다양한 형태의 크기의 물체를 파지할 수 있는 hand를 활용하
4.MODELING UNSEEN ENVIRONMENTS WITH LANGUAGE-GUIDED COMPOSABLE CAUSAL COM-PONENTS IN REINFORCEMENT LEARNING(ICLR 2025)_강화학습 수업 발표용 정리

Abstract RL에서 일반화는 중요한 도전 과제이다. 에이전트가 이전에 보지 못한 동역학 가진 새로운 환경을 마주할 때 그러함. 이미 알고 있는 구성 요쇼들을 재조합하여 새로운 상황을 다루는 능력에서 영감 받아서 World Modeling with Compositi
5.Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders
Abstract 시선 예측위해 appearance랑 scene content 추론 필요함. 기존 연구들은 head, scene encoder 필요. 그리고 depth나 pose 추정 보조 모델들 feature 결합하는 파이프라인 필요함. 이 논문에서는 DINOv2 en
6.SAGE: A SYNCHRONIZED ACTION AND GAZE ESTIMATION FRAMEWORK FOR COMPREHENSIVE HUMAN BEHAVIOR ANALYSIS
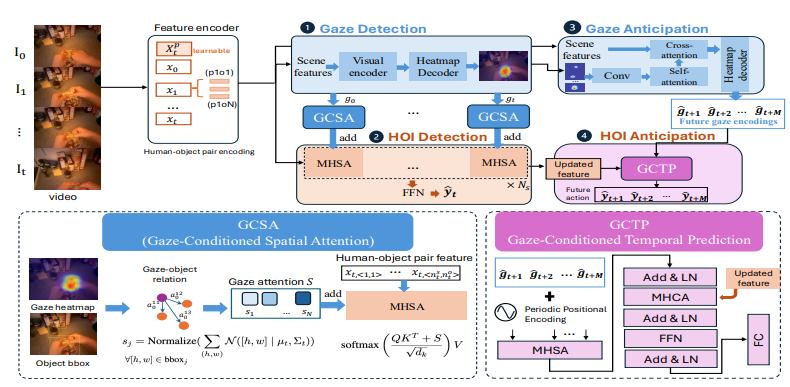
Abstract 사람의 객체 상호작용, 시선 패턴, 그리고 그에 대한 예측은 긴말하게 연결되어 있음. 하지만 대부분의 기존 모델들은 gaze와 action을 분리해서 다뤄서 상호의존성뿐만 아니라 통합 이점 놓침 -> SAGE(Synchronized Action and
7.HD-EPIC: A Highly-Detailed Egocentric Video Dataset
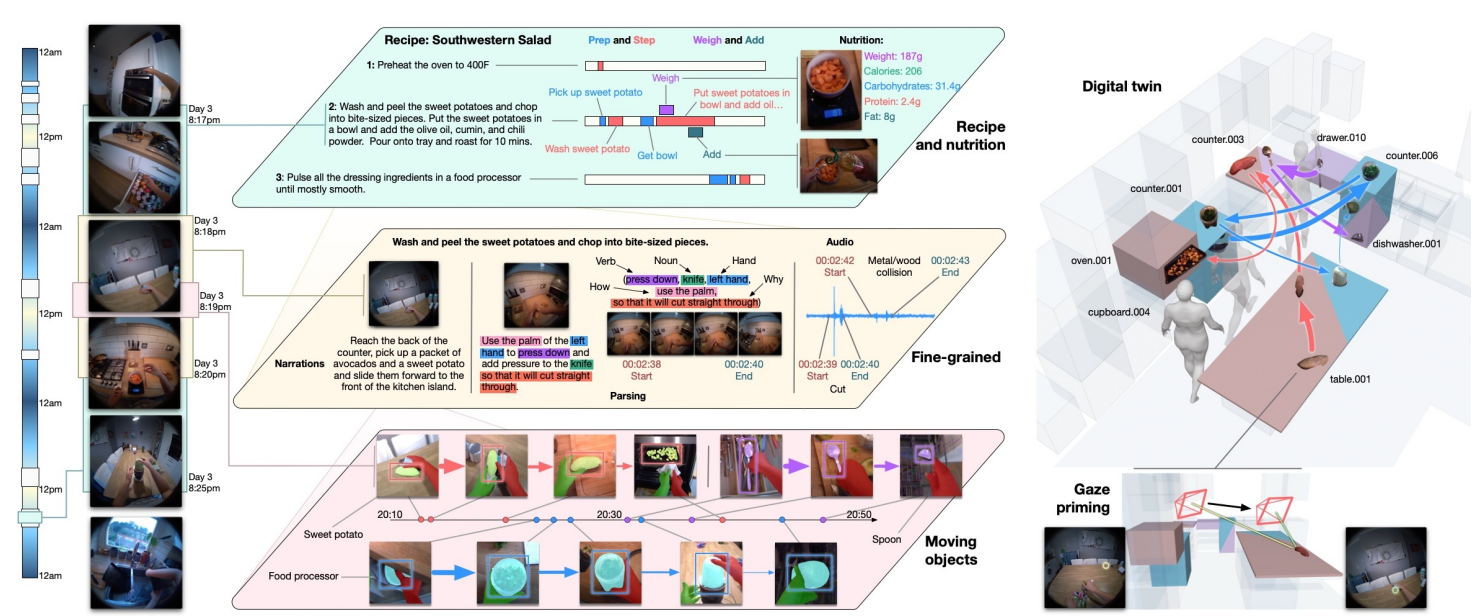
HD-EPIC egocentric 비디오 데이터 셋41시간 영상, 9개 주방69개 레시피59K 행동, 51K 오디오 이벤트20K 객체 이동, 37K 3D 객체 마스크분당 평균 annotation -> 현존 egocentric 데이터셋 중 최고 밀도\*\*레시피, 행동,
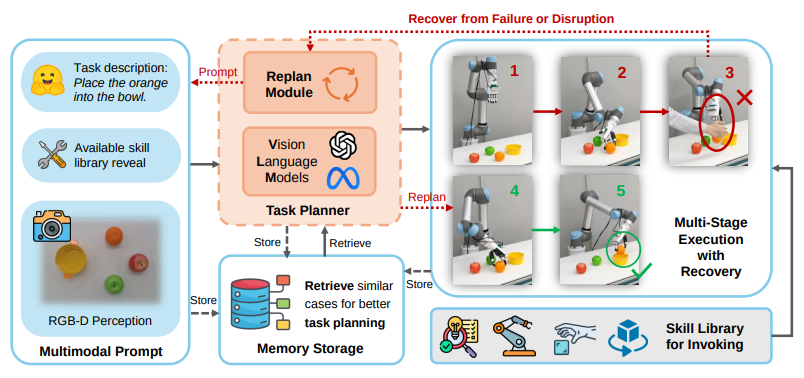
8.Towards Long-Horizon Vision-Language-Action System: Reasoning, Acting and Memory
Abstract VLA는 단일 task에선 큰 발전 이루었지만 long-horizon 한계로 실제 적용 제한 - hierarchical VLA system MindExplore 제안 핵심은 task planning과 action execution의 지식 영역을 반복
9. VIMA: General Robot Manipulation with Multimodal Prompts
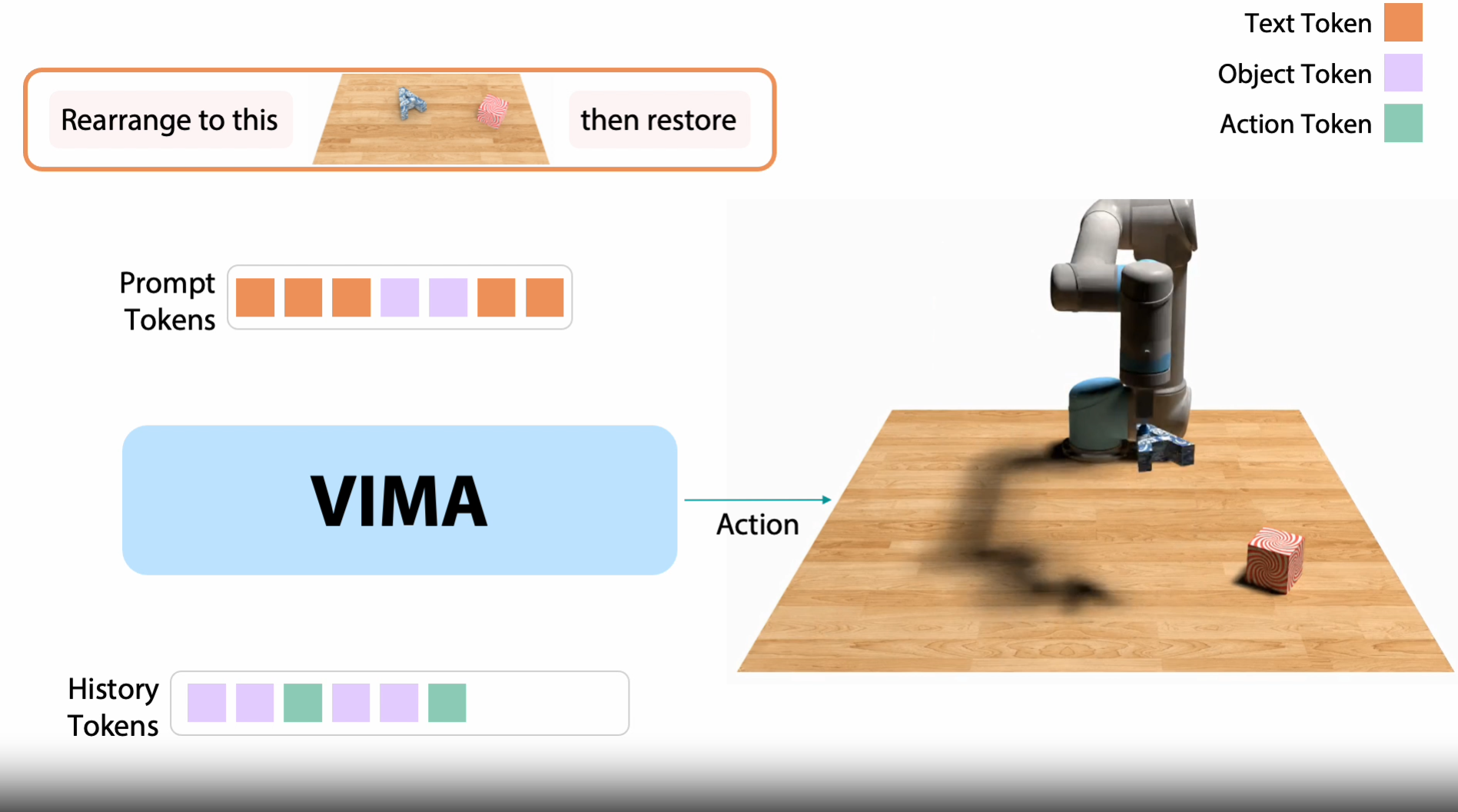
광범위한 로봇 조작 작업들이 텍스트 & 시각 토큰이 교차(interleaving)된 멀티모달 프롬프트로 표현될 수 있음을 보임.수천 개의 preocedurally-generated tebletop task, 멀티모달 프롬프트, IL 위한 60만개 이상의 expert t
10.GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
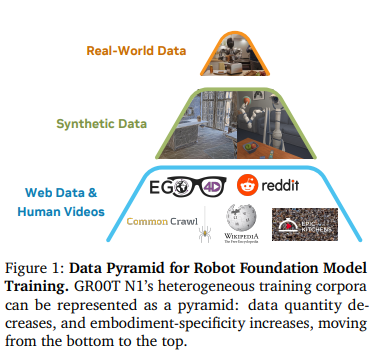
휴머노이드 로봇 위한 오픈 파운데이션 모델.GROOT N1은 이중 시스템 아키텍처를 갖는 VLA 모델. vision-language module(system2)는 시각 정보와 언어 지시를 통해 환경 해석. diffusion transformer module(system
11.VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers
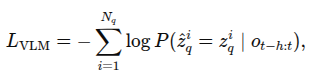
Abstract 대규모 행동 궤적 데이터셋 기반 VQ-action tokenizer 제안. 기존 접근들보다 100배 이상 많은 데이터 활용 -> 시공간적 동역학 학습 가능 한번 학습한 토크나이저는 별도 추가 학습 없이 다양한 작업에 zero-shot 가능 본 연구
12.LAPA: LATENT ACTION PRETRAINING FROM VIDEOS
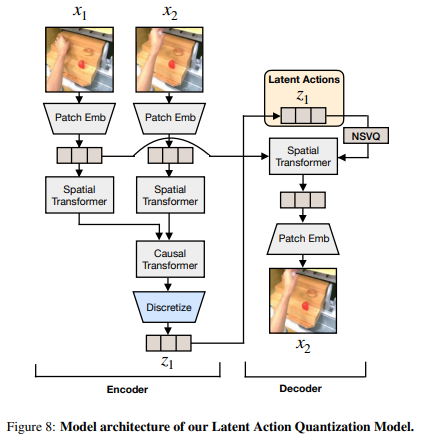
Abstract 로봇 action label 없는 인터넷 규모 비디오 데이터로부터 학습할 수 있는 방법 제안 VQ-VAE 기반 이미지 프레임 사이의 discrete latent action 학습하는 action quantization model -> observati
13.PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
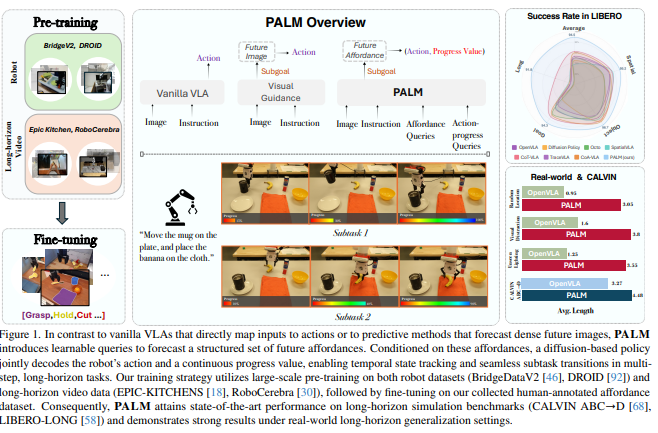
long horizon, multi-step 문제. 작업과 관련된 상호작용 단서 식별하거나 subtask 내에서의 진행 상황 추적하는 내부 추론 메커니즘이 부족. interaction-centric의 afforance 추론과 subtask 진행 신호를 중심으로 poli
14.ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
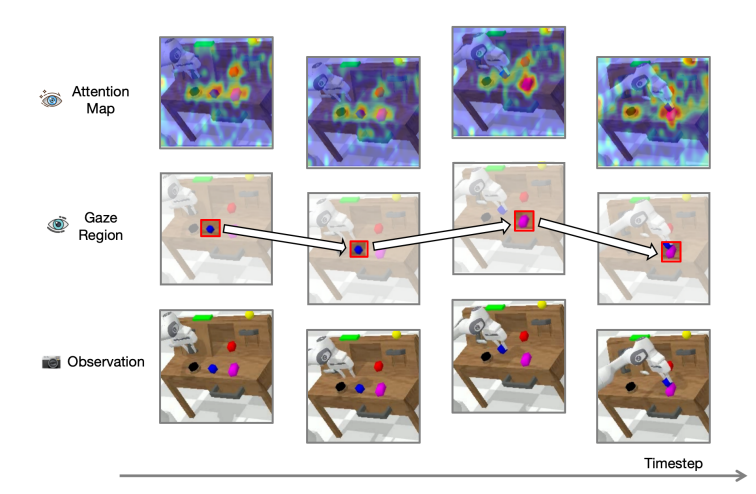
기존 VLA에서 시각입력 attention-map을 시각화 한 것. 집중해야하는 영역과 반대로 분산되는 경향을 보임 -> 실패한다.따라서 어떻게 VLM의 grounding 능력을 향상시킬 수 있냐?기존 VLA의 시각적 그라운딩 방법1\. 그라운딩된 이미지를 명시적 입력
15.Scaling Manipulation Learning with Visual Kinematic Chain Prediction
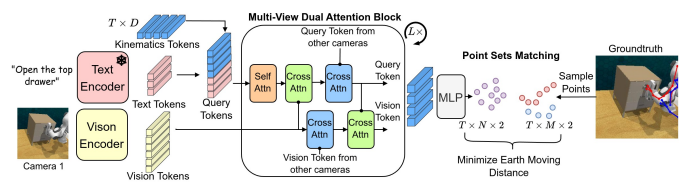
2024 CoRL기존 멀티테스크 학습 방법들이 일반적으로 단일 로봇과 단일 작업공간에 제한되는 경우가 많음. RT-X 같은 연구는 서로 다른 환경 액션 공간 정규화 요구.이 논문에서는 다양한 환경에서의 로봇 학습을 위한 visual kinematics chain 제안.