2024 CoRL
Abstract
기존 멀티테스크 학습 방법들이 일반적으로 단일 로봇과 단일 작업공간에 제한되는 경우가 많음. RT-X 같은 연구는 서로 다른 환경 액션 공간 정규화 요구.
이 논문에서는 다양한 환경에서의 로봇 학습을 위한 visual kinematics chain 제안. 로봇 모델과 카메라 파라메터 통해서 수동 조정 필요 없음
BCT 대비 우수한 성능 보임
1. Introduction
범용 모델 - 서로 다른 액션 공간 사이 차이를 위해 액션 정규화 필요 -> 모델 일반화 성능과 해석 가능성 영향 줌.
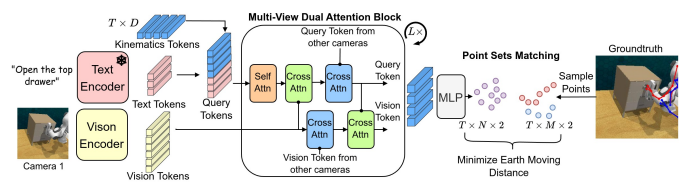
다양한 로봇에 대해 보편적 액션 표현 어떻게 찾을 수 있을까? -> VKC: 로봇의 고차원 운동학 구조를 이미지 평면 상의 픽셀로 투영화 한 것 - 이미지 평명 상에서 로봇 운동학 체인 움직임 학습하고 시각적으로 예측하는 방식 제안.
다양한 로봇 운동학 구조 예측 위해 링크 따라 포인트 샘플링 & 운동학 체인을 포인트셋으로 렌더링, 예측된 포인트셋과 실제 운동학 구조 사이의 Earth Moving Distance 최소화 위해 최적 매칭 수행
VKT는 어떠한 저수준 로봇 액션도 보지 않고 최적 포인트셋 매칭 통해 운동학 구조 예측하는 단일 목적 함수로 학습 - 특정 환경에 배치할 때는 백본 고정하고 작은 헤드만 학습
contributions
1. 다양한 로봇에 대해 학습위해 visual kinematic chain 제안
2. 임의의 카메라 시점 지원하여 최적 포인트셋 매칭 통해 운동학 구조 예측하는 단일 목적 함수로 학습
3. VKT 성능 실험적 분석
2. 패스
3. Visual Kinematic Chain Forecasting
Fitting any Structure with Point-Set Matching
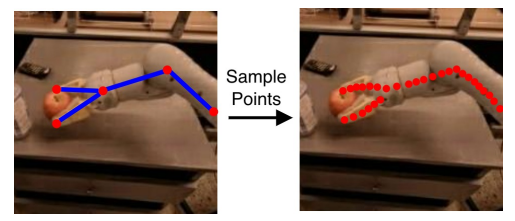
먼저 URDF같은 로봇 모델에 조인트 값을 이용해서 FK한 한 후, 카메라 파라메터를 통해 기하학적 투영으로 링크 투영
그림같이 링크 따라 균일하게 포인트 샘플링해서 렌더링
