Introduction
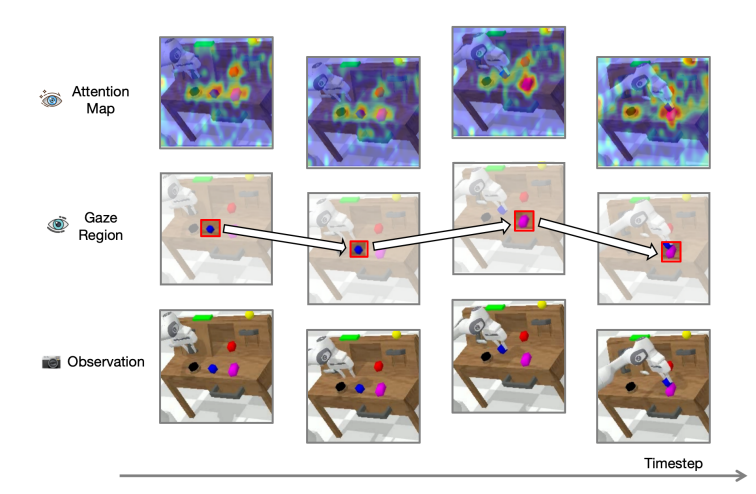
기존 VLA에서 시각입력 attention-map을 시각화 한 것. 집중해야하는 영역과 반대로 분산되는 경향을 보임 -> 실패한다.
따라서 어떻게 VLM의 grounding 능력을 향상시킬 수 있냐?
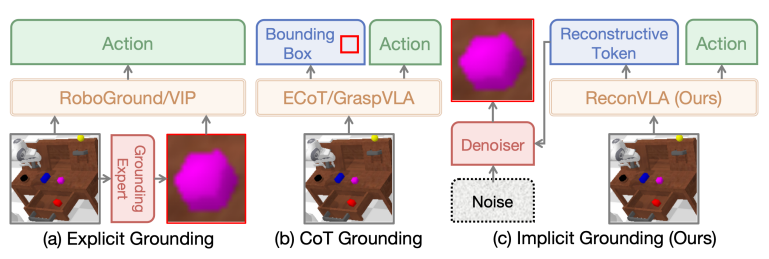
기존 VLA의 시각적 그라운딩 방법
1. 그라운딩된 이미지를 명시적 입력으로 사용
2. CoT 방식으로 바운딩 박스 출력
-> 이런 방식들은 목표 영역에 대한 인식 강화하고 공간적 인식 향상시키지만 어텐션 할당 자체를 근본적으로 정교화 불가능
recontructive visual instruction tunning에 영감받아 lightweight diffusion transformer에 기반 보조 시각 재구성 모듈 도입 - VLA 모델이 region-specific 정보 포함한 미세 표현 학습하도록 유도. -> 시각적 어텐션이 올바른영역에 집중하도록 함 : gaze region
기존 VLA 모델들은 시각적 생성 능력이 결여됨. - 10만개 이상의 트래젝터리 200만 개의 데이터 샘플 포함하는 사전학습 데이터셋 구축 - 여러 오픈소스 로봇 데이터 셋 + Grounding DINO 활용해서 데이터 처리 파이프라인 설계해서 전체 이미지와 조작 대상 영역 이미지의 쌍 생성
ReconVLA 개발. 현재 이미지, 언어 지시문, proprioception 입력으로 사용.
학습 과정에서 입력 이미지의 gaze region은 frozen 된 비주얼 토크나이저 통해 latent token으로 변환 - 이 token은 잠재토큰 복원하는 diffusion 트랜스포머 학습 - 이러한 diffusion기반 디노이징 과정은 조건부 분포 효과적으로 모델링
long-horizon 작업에서는 제안한 암묵적(implicit)그라운딩이 다른 그라운딩보다 더 효과적. ablation에서도 검증
ReconVLA directive(지향성) 시각적 어텐션 보임
Contribution
1. implicit 그라운딩 패러다임 갖는 ReconVLA 제안 - 정밀한 시각적 어텐션 할당과 미세한 표현 학습 가능하게
2. 데이터셋 구축 - 이걸로 학습시킬 시 시각 재구성 일반화 능력 향상
3. 시뮬레이션과 실제 환경 실험 통해 그라운딩 우수성, unseen 대상 대해 정밀 조작 및 일반화 입증
Method는 기존과 비슷한 듯.
loss는 action단이랑 recon 단 같이 들어감
학습 방법
기존 로봇 시뮬레이션 데이터셋에서 더해 grounding DINO로 instruction이랑 gaze region 상호 작용
flow matching에서 DiT를 학습시킬 때 Vector field 학습 관점과 유사 - gaze region latent로 가는 복원 방향을 학습해서 어디를 봐야 하는가를 implicit하게 규정 - supervised 느낌이 아님.
Experiments
실험이 중요해 보임
1. implicit 그라운딩 접근법이 다른 그라운딩 접근법보다 성능이 우수한가? - 4.2
2. gazing 메커니즘은 시각적 그라운딩에 기여하여 더 나아가 정밀 조작에 유용한가? - 4.3
3. 제안한 사전학습 단계는 시각적 생성의 일반화를 향상시키는가? 그리고 ReconVLA에서 제안된 핵심 설계 - 4.4
4. ReconVLA는 다른 경쟁 방법들과 비교했을 때 long-horizon 작업을 효과적으로 수행할 수 있는가? - 4.5
5. unseen에 대해 일반화된 조작 수행 가능한가? - 4.6
4.2 Paradigm Comparison
Explicit Grounding (EG): YOLOv11 검출, crop, resize -> 입력
Chain-of-Thought Grounding (CG): 출력 형식을 Bbox + action sequence -> VLA가 목표 객체 그라운딩과 행동 출력 학습
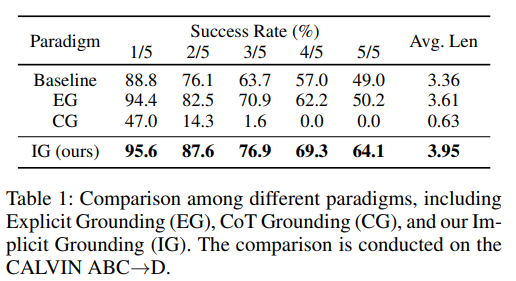
EG가 성능 좋음 but 원본이랑 크롭 이미지 같이 넣어서 시각 정보 중복, 모델 성능 제한
CG는 성능 오히려 안좋음 - VLA 모델에게 학습 어려움 야기
Implicit 그라운딩 방식이 가장 높은 SR - 추가적인 입출력 필요로 하지 않음
4.3 In-depth Analysis
Attention Visualization: attention이 목표 객체에 해당하는 영역과 밀접하게 정렬되도록 보여줌 - 뭐 잘 됨
Precise Manipulation: stack block 과제에서 제일 좋은 성는 보여줌 - 하나 블록에서 다른 블록 위에 정확히 쌓아야 하기 때문에
4.4 Ablation Study
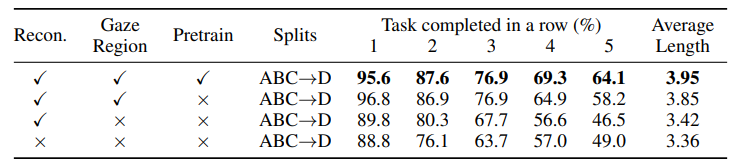
ablation이 잘 됨
4.5 Comparison with Sate-of-the-arts
뭐 제안한 방법이 제일 좋았다.
4.6 Multi-task Experiments in the Real Worlds
OpenVLA와 PD-VLA 능가.
여기서는 instruction이랑 사진이랑 비교해서 gaze 가져오기 때문에 VAE로 복원하는거는 목표 객체
