인덱스와 슬라이싱을 사용하는 이유
우리가 데이터를 수집하다 보면 우리가 원하는 데이터만 딱 골라와서 사용할 수 없다. 방대한 자료 속에서 우리가 원하는 자료를 삭제하거나 재조립해야 하는 경우가 훨씬 더 많다. 이런 불필요한 자료를 원하는 자료의 형태로 만들기 위해서 데이터를 재조립하는 기능이 인덱싱과 슬라이싱 이다.
오늘의 목표
- df의 열 가져오기=df["열이름"]
- df.loc 사용하여 행, 열, 슬라이싱하기=df.loc["행이름","열이름"]
- df.iloc 사용하여 행, 열, 슬라이싱하기=df.iloc[행,열]
- drop 함수 사용하기=df.drop
- 2,3번은 같은 기능을 한다. 2번은 문자열을 통해 가져오는 방법이고, 3번은 숫자를 통해 가져오는 방법이다. 상황에 따라 숫자로 가져오는게 편할지, 문자로 가져오는게 편할지 모르므로 두루 익혀 두자
1차원 vs 2차원 인덱스와 슬라이싱 비교하기
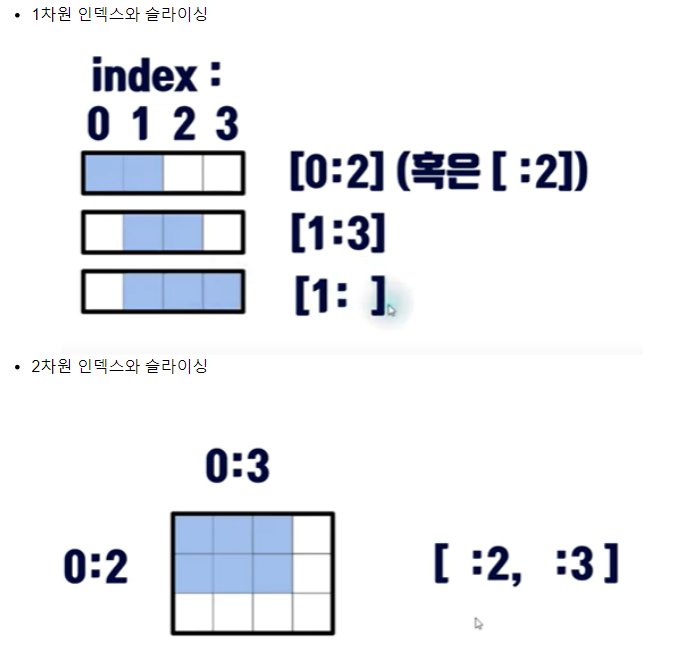
- 파이썬에서 배운 개념과 동일하므로 그렇게 어렵지 않게 이해할 수 있다
파이썬 만세 - 항상 주의해야 할 점은 인덱스는 0에서 부터 시작하는 것과, 슬라이싱의 끝 범위는 끝을 포함 하지 않는다 라는 점이다. [1:3] 는 인덱스 1,2 만 가져오고 3은 포함하지 않는다. range와 같다
1. 판다스와 넘파이 라이브러리 불러오기
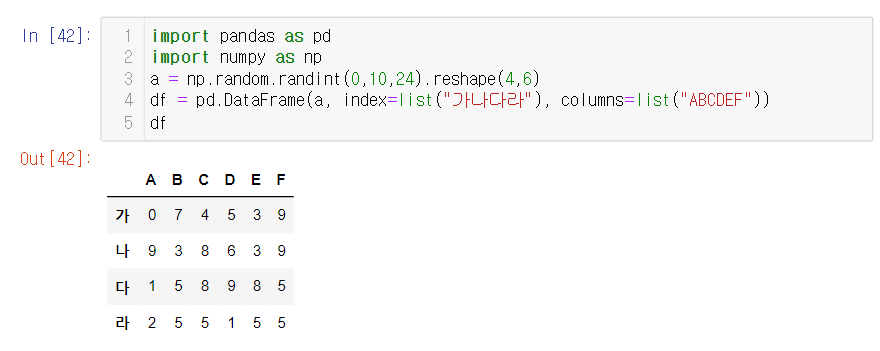
- DataFrame 쉽게 만드는 방법, a값에는 리스트로 변경될 랜덤값 부여, 컬럼과 인덱스는 리스트 화 될 문자열 가로안에 써주기! 꿀팁... 이제야 알려주네
2. 첫번째 함수 df["열"] 컬럼값만 불러오고 싶을때 쓴다
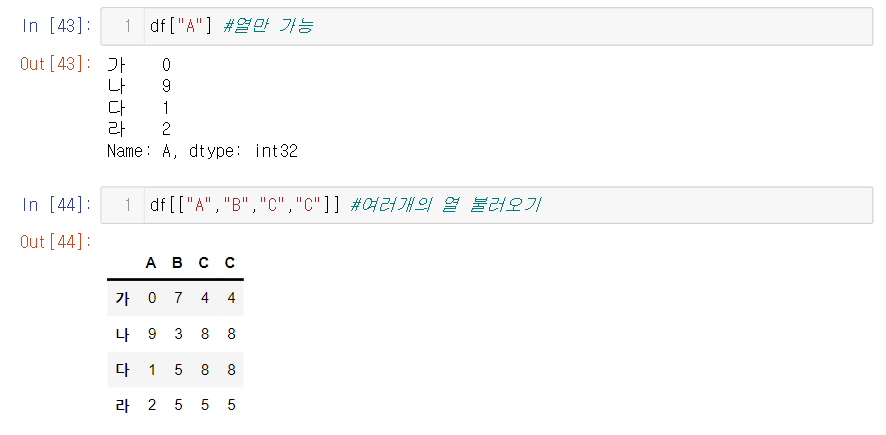
- 2개 이상의 열을 (중복포함) 불러올수도 있다. 해당함수는 아쉽게도 열을 가져오고 싶을때만 사용가능하다. 행은 불러올 수 없다
3. 두번째, 세번째 함수 df.loc, df,iloc 사용하기
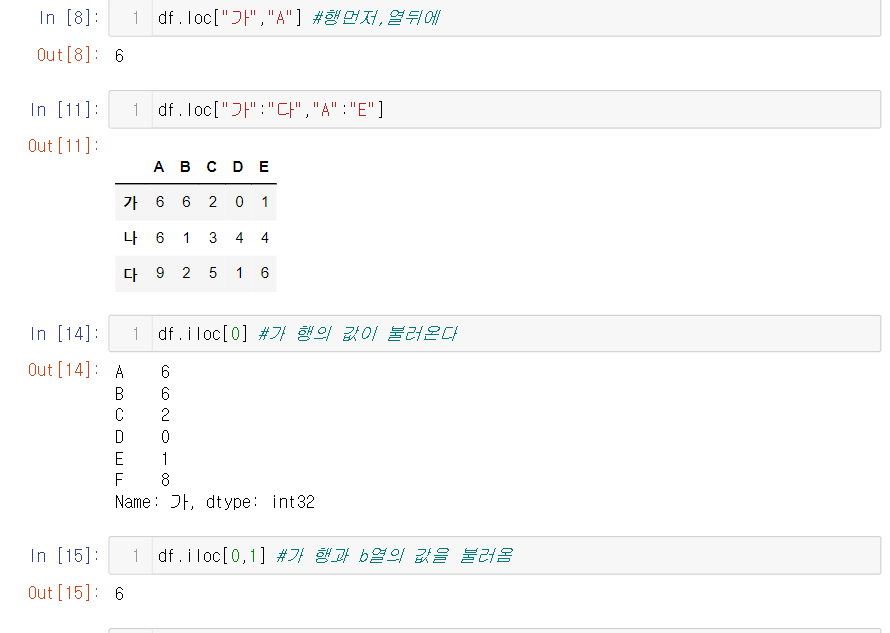
- df.loc는 직관적으로 값을 가져올수 있다는 장점이 있지만 문자열을 하나씩 쳐야한다는 수고스러움과 오타시 에러가 발생한다는 단점이 있다.
- df.iloc는 인덱스를 사용해서 값을 가져오기 대문에 빠르게 작동하지만 조금 헷갈릴순 있다
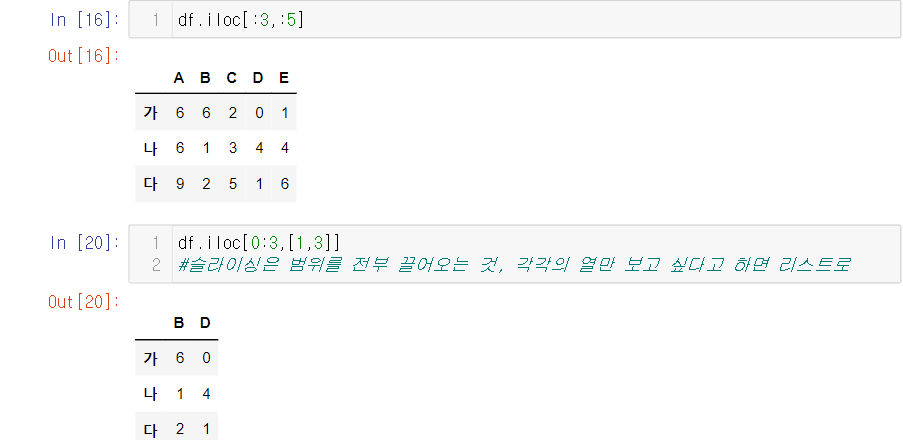
- 슬라이싱과 리스트를 같이 사용할 수 있다.
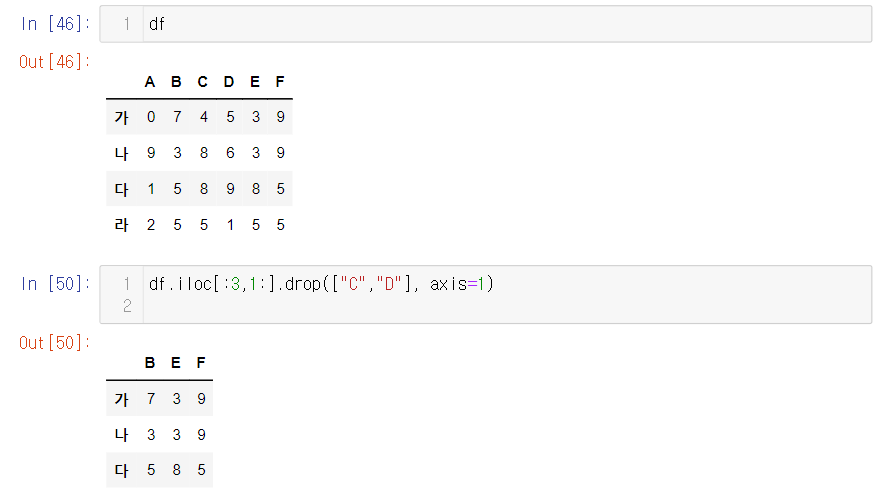
4. 행, 열중 특정 값을 배제하고 싶을때 drop 함수 사용하기

- "D" 열을 삭제하고 싶을때는 df.drop("D", axis=1)을 사용해서 제거한다
- axis=0 (행, 기본값이므로 행을 삭제할때 굳이 적어주지 않아도 된다), axis=1 (열)
Quiz
- B,D,E,F열과 가나다행의 자료를 추출하라
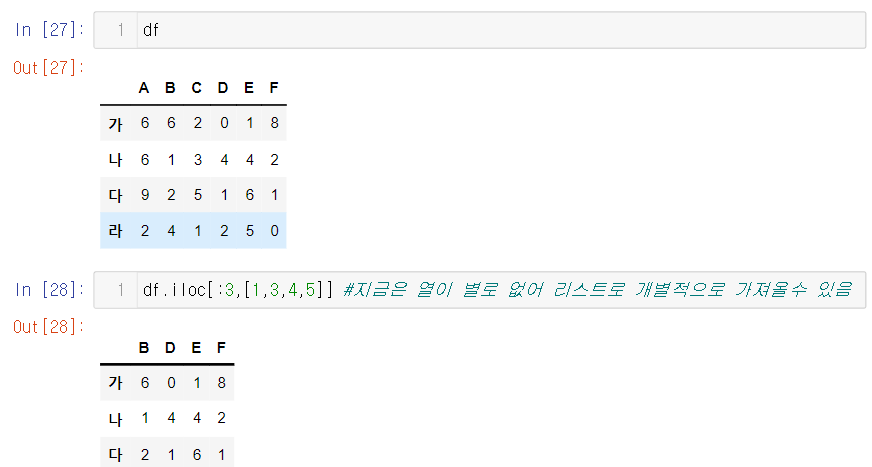
- 행은 슬라이싱, 열은 리스트로 가져올 수 있다. 하지만 열이 이어진 값이지만 한두개만 빠진 상황이라면 일단 슬라이싱을 한 후에 drop 함수로 빼주는 방법이 유용한 상황일 수도 있다.

+) 빼고 싶은 값이 2개 이상일 경우에는 리스트로 묶어주면 된다

질문 없는 성장은 없다. 3년차 데이터 분석가