pandas
1.판다스 기초

해당 판다스 기초 강의는 엑셀투파이썬 유트브를 기본으로 정리하였음https://www.youtube.com/watch?v=SVjKsvvhWlQ&list=PLrpXwtuxGqcIIf_SpCWg04MoHf1yJUCvi&index=1dataframe은 index와
2.판다스 기초 1. 인덱싱과 슬라이싱
우리가 데이터를 수집하다 보면 우리가 원하는 데이터만 딱 골라와서 사용할 수 없다. 방대한 자료 속에서 우리가 원하는 자료를 삭제하거나 재조립해야 하는 경우가 훨씬 더 많다. 이런 불필요한 자료를 원하는 자료의 형태로 만들기 위해서 데이터를 재조립하는 기능이 인덱싱과
3.판다스 기초 2. 정렬
sort_values() 라는 함수를 사용해서 컬럼(확률변수)을 기준으로 오름차순, 내림차순을 할 수 있다.1개의 열을 기준으로 오름차순 해보기1개의 열을 기준으로 내림차순 해보기2개 이상의 열을 기준으로 정렬2개 이상의 열기준 오름차순, 내림차순 섞어서 정렬데이터 살
4.판다스 기초 3. broadcasting과 연산
numpy의 연산(3X3) X (3X3) 의 연산이며 같은 자리에서 연산이 되는것을 볼 수 있다(3X3) X (3X1) 의 연산도 위의 값과 같다. 왜일까?브로드 캐스팅은 똑같은 배열이 늘어나서 연산을 진행 시키는 역할을 한다판다스는 넘파이와 다르게 라벨링(인덱스 &
5.판다스 기초 4. boolean indexing
df의 열 가져오기=df"열이름"df.loc 사용하여 행, 열, 슬라이싱하기=df.loc"행이름","열이름" >>문자열로 가져오기df.iloc 사용하여 행, 열, 슬라이싱하기=df.iloc행,열>> 숫자로 가져오기drop 함수 사용하기=df.droptrue or fal
6.판다스 기초 5. Index 수정하기
이때까지 행의 이름을 index, 열의 이름을 columns라고 배웠는데 엄밀히 말하면행의 index는 index, 열의 index를 columns이라고 부르는 것. 즉 둘다 데이터 프레임은 인덱스로 이루어진 표이다. 다만 헷갈리기 쉬워서 네이밍을 인덱스, 컬럼으로 나
7.판다스 기초 6. 피벗, 피벗테이블
pivot피벗이란 중요한 부분을 그대로 두고, 단지 방향만을 전환해서 새로운 것을 만들어 내는것이다.예를들어 스타트업에서는 피벗전략이라는 말을 쓰는데 세계 최대의 동영상 공유 플랫폼인 유트브도 원래는 자기소개 동영상을 올리면 메이트를 연결해주는 데이팅 기반 서비스를 기
8.판다스 기초 7. unpivot
말그대로 피벗의 반대말로 피벗된 자료의 value를 한 열로 길게 재구성하는 것.언피벗을 왜 하는걸까? 일단 피벗을 하는 이유는 원하는 데이터를 한눈에 보기 위함 이며 학생들의 가목당 성적이 한눈에 들어옴을 알수 있다. 하지만 다른 방향의 데이터를 만들고 싶을땐 쉽게
9.판다스 기초 8. concat
=두 테이터 표를 합치고 싶을때 쓰는 함수행을 기준으로 붙이기pd.concat(df1,df2) axis=0 은 행을 뜻하고 행을 기준으로 붙인다는 말이다. 디폴트 값이므로 굳이 적어주지 않아도 된다.열을 기준으로 붙이기pd.concat(df1,df2 , axis=1)
10.판다스 기초 09. value_counts
= 말그대로 값부분을 카운트 해주며 시리즈로 반환한다사용법은 직관적이라 어렵지 않으며, 함수는 value만 치고 탭쳐주면 알아서 완성됨1개의 열 값을 카운트 한다 df.value_counts("열이름")복수의 열의 값들을 카운트 한다 df.value_counts("열
11.판다스 기초 10. 중복값 처리
df.dulplicate() 함수를 써서 중복값이 있는지(True) 없는지(False) 확인하며, 처음 나온 값을 중복값이라고 여기지 않고 2번째 나오는 값들부터 중복값이라고 여긴다. 그리고 삭제할때도 첫번쨰 값은 두고 두번째 이상부터 삭제한다(복수여도 상관없음. 첫번
12.판다스 기초 11. merge
merge 함수는 뜻 그대로 합치다 라는 뜻인데, concat 함수와는 차이가 있다. concat 함수는 행과 열, 즉 index 기준으로 합치는것이고, merge는 엑셀의 vlookup처럼 같은 값는 열을 기준으로 열로 붙게 된다. 여기서 편한점은 엑셀의 vlooku
13.판다스 기초 13. column /열수정, 열생성, 행추가, 행수정
"반" 이라는 열을 만들고 싶음df"반" = 1 작성하면 위의 그림처럼 df의 맨 오른쪽에 반이라는 열이 생성되며 값으로 1이 생성되게 된다열을 만드는 방법 기본 공식df"열이름" = 값 (숫자, 문자, 배열)해당 열이 데이터 프레임에 없는 경우에는 열을 생성한다 (가
14.데이터 타입 변경
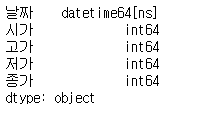
참고 티스토리 : https://seong6496.tistory.com/134데이터 프레임 = dfdf.dtypes()모든 컬럼을 바꾸고 싶지 않고, 일부의 컬럼의 타입을 바꾸려면df = df.astype({'col' : 'datatype' , ..})ex)
15.데이터 프레임 값 바꾸기
판다스에서 value값이 이상한것이 들어가 있거나, 변경하고 싶은 값이 있다면 수정하거나 대체 할 수 있다. df.loc인덱스명,컬럼명 = 바꿀 값예를 들어, A열의 2번째 인덱스에 들어있는 3의 값을 3000으로 변경하고 싶으면df.loc2:'A' = 3000특정 컬
16.데이터 프레임 결측치
참고 티스토리 : https://computer-science-student.tistory.com/306 1. 판다스 결측값 확인 및 처리 결측값은 탐색적 데이터 분석에도, 그 후 나아가 머신 러닝 알고리즘을 통해 분석을 할때에도 성능에 영향을 줄 수 있는 값이다.
17.Dataframe을 리스트로 변경하기
참고 티스토리 : https://ddolcat.tistory.com/729 판다스의 데이터 프레임을 리스트로 변환하는 방법에 대해 알아보자. 데이터 프레임의 값을 리스트로 변환하려면, tolist() 메소드를 사용하면 된다. 1. 데이터 프레임의 values를 리스
18.데이터 프레임 조건 걸고 특정 열 뽑아보기
데이터 프레임의 특정 열의 조건을 걸어두고, 그에 해당하는 다른 열을 보고 싶을때영화 데이터 프레임에서 매출액이 100억이 넘는 영화명을 리스트에 담고 싶음