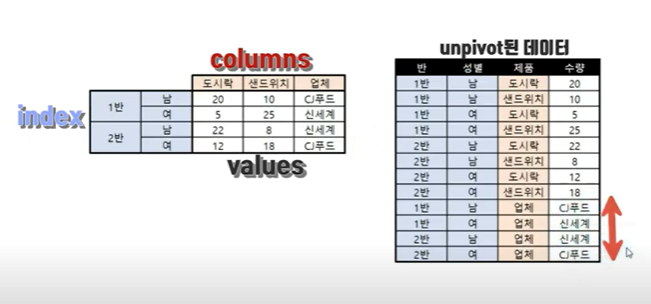
unpivot이란?
말그대로 피벗의 반대말로 피벗된 자료의 value를 한 열로 길게 재구성하는 것.
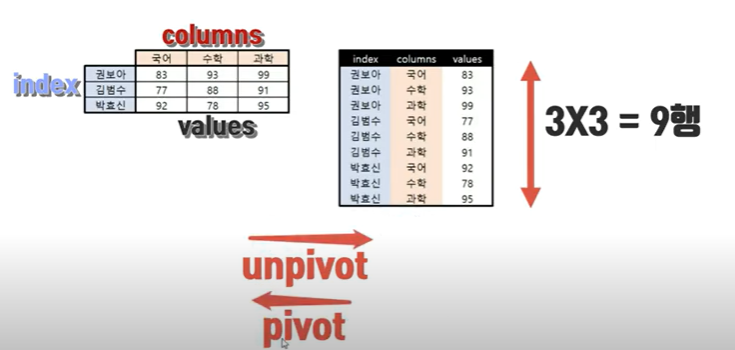
언피벗의 필요성
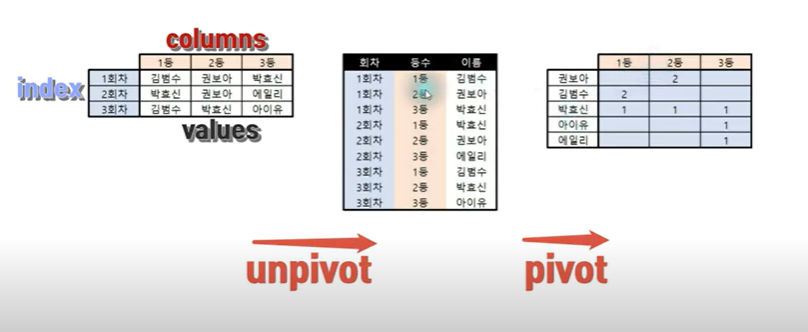
- 언피벗을 왜 하는걸까? 일단 피벗을 하는 이유는 원하는 데이터를 한눈에 보기 위함 이며 학생들의 가목당 성적이 한눈에 들어옴을 알수 있다. 하지만 다른 방향의 데이터를 만들고 싶을땐 쉽게 전환시키기 어렵다는 한계가 있다. 그래서 피벗된 테이블을 언피벗 시키면 다른 정보를 쉽게 알아 볼 수 있는 새로운 표 데이터를 다시 피벗을 할수 있게 된다.
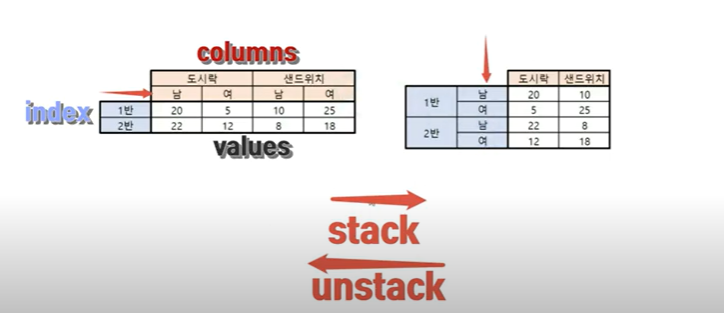
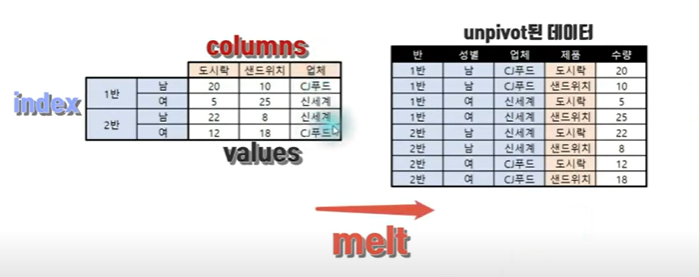
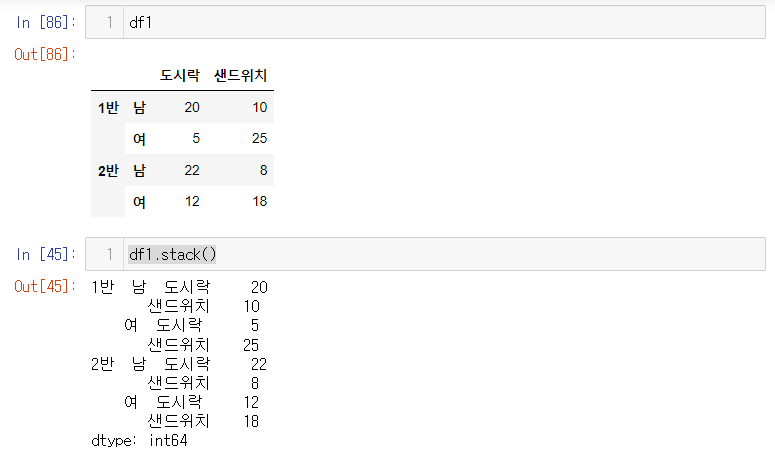
unpivot=stack()+reset_index()
- stack()
컬럼의 한줄을 빼서 인덱스화 시켜 시리즈로 만들어줌
남,여의 성별은 인덱스로 변경되고 해당 컬럼은 사라지게됨
- reset_index() = 스택으로 전부 컬럼>인덱스로 바꿔버렸기 떄문에 컬럼이 없으므로 컬럼을 재설정 시켜준다(이때,임의로 정해지기 때문에 컬럼 이름 변경을 원하면 따로 해주어야 함)
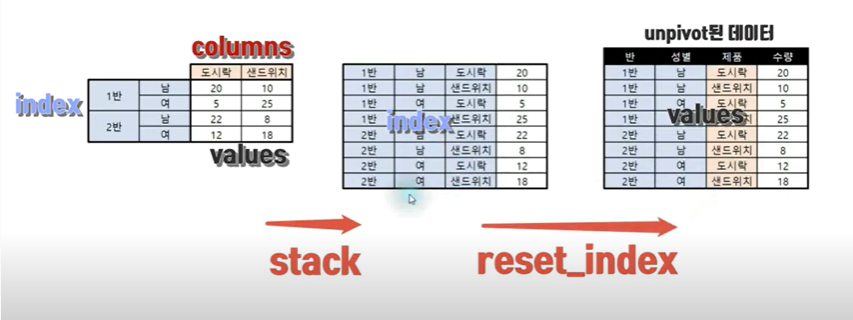
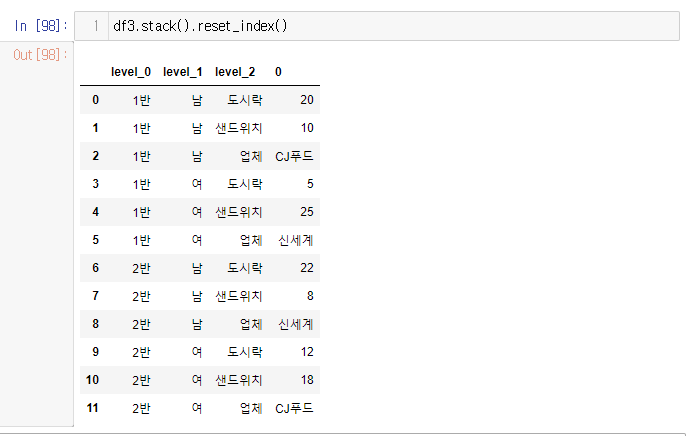
stack을 사용하여 컬럼즈가 없고 인덱스에 몰빵된 시리즈를 만들고, 그 시리즈를 reset_index() 하여 데이터 프레임을 만들어 주면 언피벗이 된다.
melt() 함수 사용하기
- 언피벗되어 value값으로 나오면 안될 데이터들이 종종 등장한다. 업체는 포함되지 않았으면 하는 상황이다
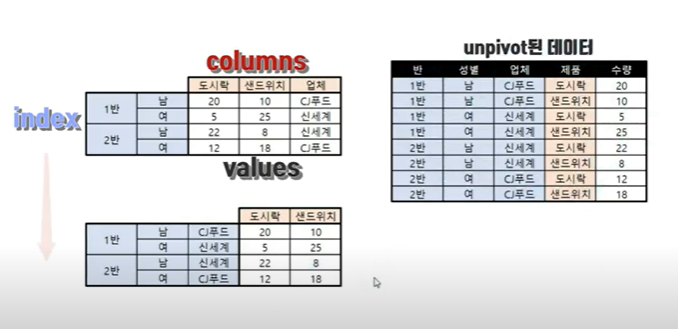
그래서 stack 하기 전에 업체를 인덱스로 바꾸어 주고 stack를 하면(도시락과 샌드위치만 원하는 정보의 표를 구할수 있다. set_index(append로 업체명을 추가) > stack > reset_index
이럴때는 일부 열이 언피벗되지 않게 하기 위해서 melt() 함수를 쓴다
오늘의 목표
- stack으로 언피벗 하기
- melt로 언피벗 하기
1. 판다스 가져오고 데이터 살펴보기

2. stack()+reset_index =unpivot
- 리셋 인덱스 후 컬럼을 재설정+이름 재설정
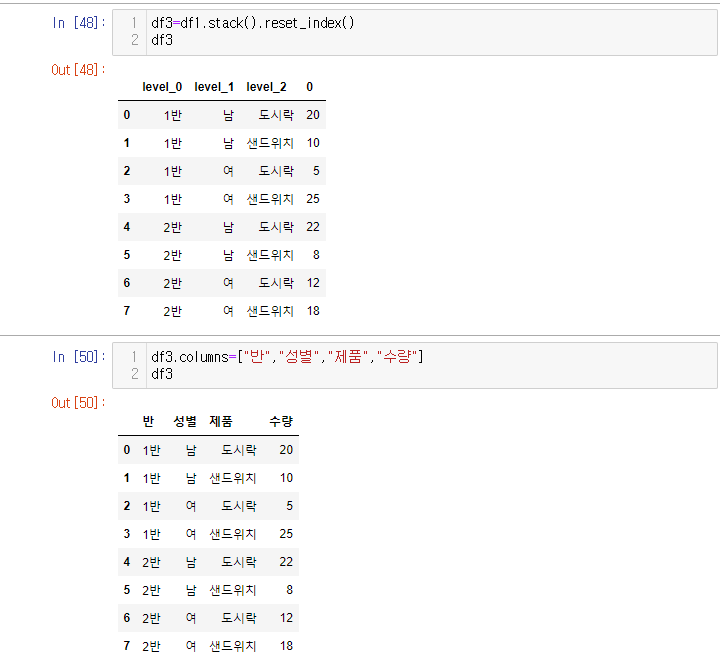

- 멀티 인덱스인 경우에도 똑같이 해주면 된다
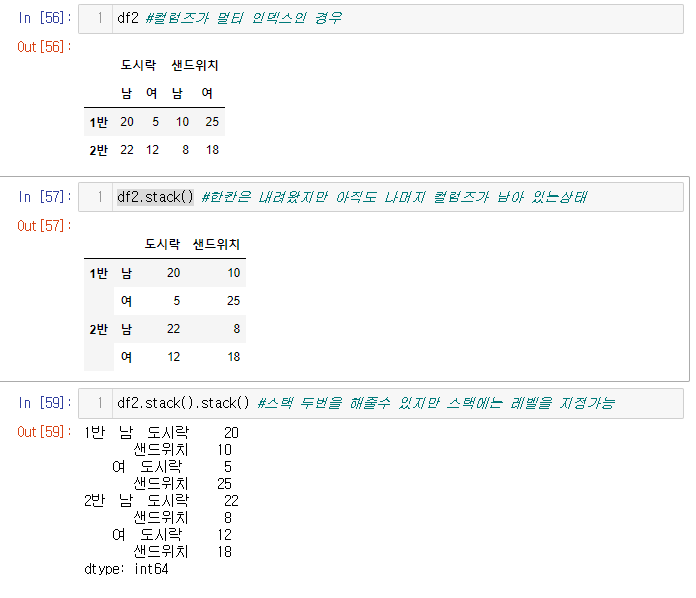
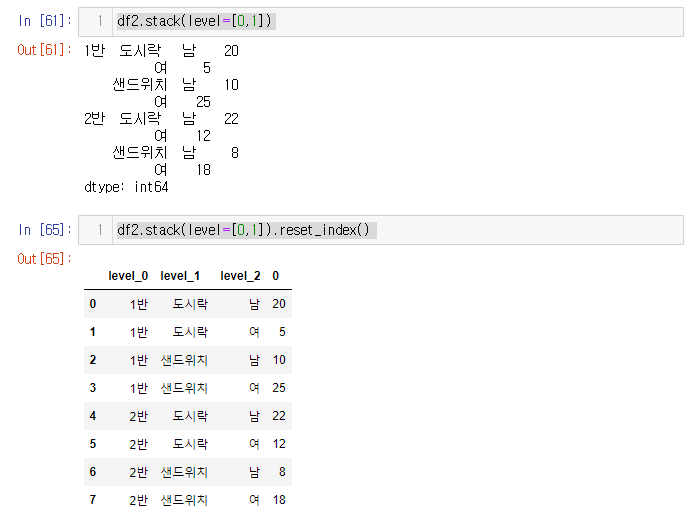
- 컬럼이 멀티 인덱스인 경우는 단순히 stack를 중복해서 써주면 되긴 하지만, level parameter를 사용하여 손쉽게 모두 인덱스로 바꿔줄수 있다.

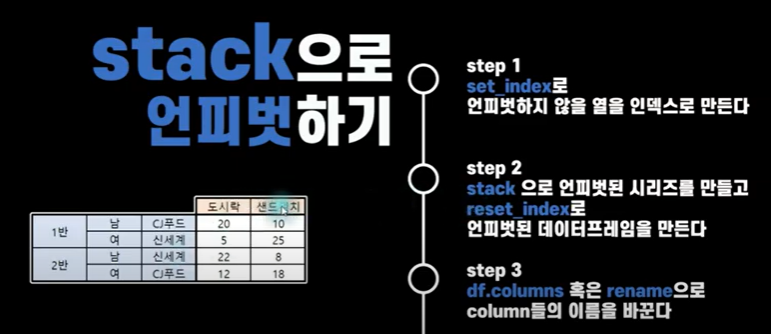
3. 인덱스로 지정후 stack 만들기


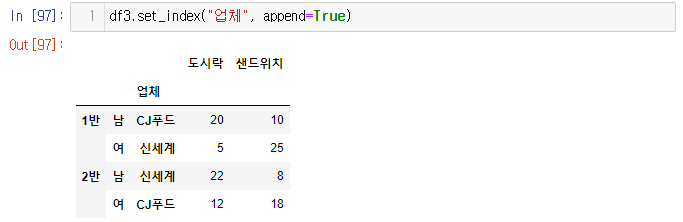
- 지금 있는 인덱스 뒤에 이어붙이겠습니까? true
4. 3번이 복잡하고 귀찮다 싶으면 melt 함수 사용하기

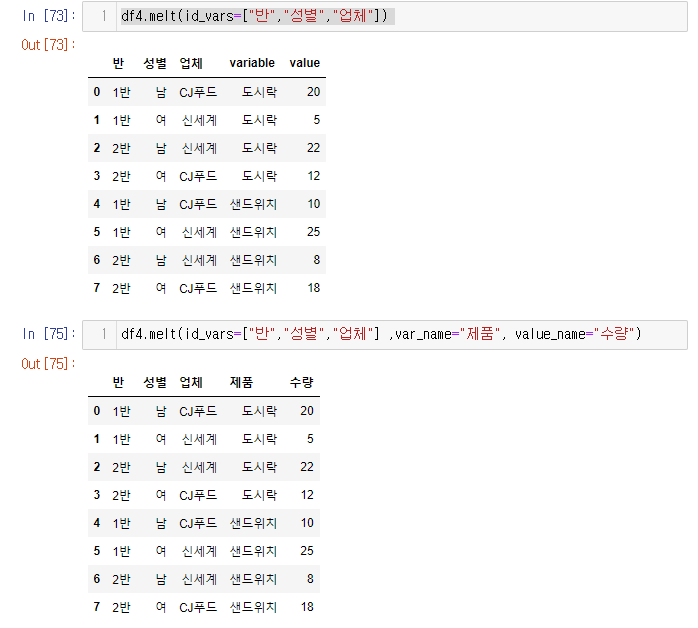
- 파라미터를 사용하여 이름도 melt 함수 내에서 바로 변경가능하다

질문 없는 성장은 없다. 3년차 데이터 분석가