Dimensionality Reduction & Unsupervised Learning(수정중)
Dimentionality Reduction (Curse of Dimensionality)
- Projection -> PCA & Kernel PCA | Subspace
- Manifold Learning | Hyperplane, Manifold
Clustering
- K-Means
- DBSCAN (Density Based Spatial Clustering of Application with Noise)
GMM (Gaussian Mixture Model)
Dimensionality Reduction 차원축소
Why
- Speed up training
변수 또는 피쳐가 많으면 training 하는데 많은 시간이 소요되기 때문에 차원축소를 해야함 - Filtering out noises
noise = rare 가 많은 경우 그 이벤트는 여기에 들어오지 못함 - Condensed data visualization
How
차원축소가 하는 일: 큰 차원을 작은 차원으로 어떻게 바꿀 것인가
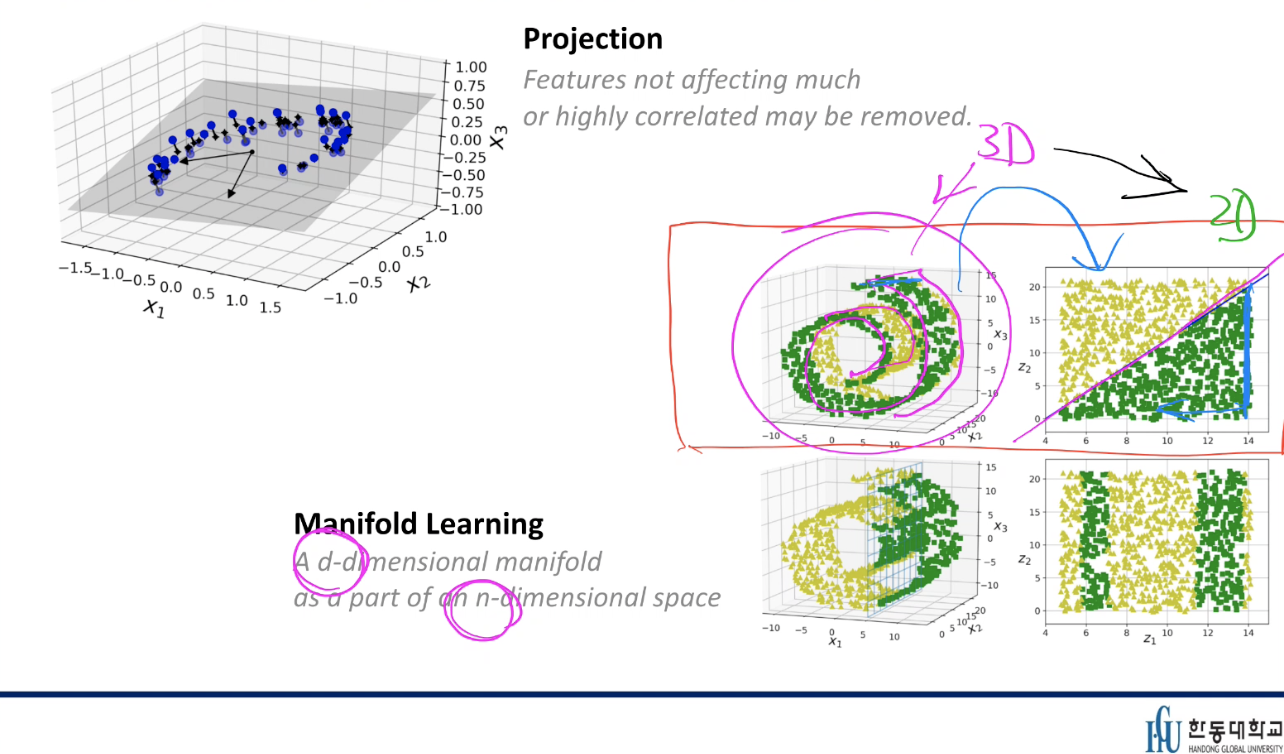
Projection
Features not affecting much or highly correlated may be removed
Manifold Learning
A d-dimensional manifold as a part of an n-dimensioal space
PCA
original variance ~~ Reduced dimension variance
Randomized PCA - 속도를 줄이는
Incremenral PCA(IPCA)
Singular Vector Decomposition(SVD)
Unsupervised Learning
- 원하는 형태의 레이블링이 안 되어 있는 경우
- 레이블링이 되어 있으나 신뢰도가 낮은 경우
- 일부만 레이블링이 되어 있거나
적절하게 미리 그루핑을 할 수 있으면 효과적인 머신러닝 가능
Classification
- labeling 이 되어있음 (~는 setosa이고 ~는 versicolor이고 ~는virginica)
Clustering
- labeling 안 되어있음 (어느놈이 뭐인지 몰름, 몇 개의 iris's로 -> clustering하는게 가장 좋을까요?)
예) 100개의 엔진 사운드를 주고 어떤 것이 고장난/비정상적인 엔진 사운드인지 알아내라
- 디지털로 만들어야 함
- 데이터를 clustering
- 2차원이라고 하면 몰려있는 것들(normal) 외 bound에서 벗어난 것들(abnormal)
K-Means
a simple algorithm capable of clustering dataset, very quickly and efficiently Hard Clustering vs. Soft Clustering
distance base 적절하게 스케일링이 되어있지 않으면 normalize 큰 bias 될 수 읶음
K-Means
Guaranteed to converge without oscillation
May not converge to the right solution for unlucky random centroid initialization
초기에 centroid를 정해야함 -> 초기에 이걸 어디다 두느냐에 따라 답이 다름 -> 판단기준이 있어야 함(performance measure)어떤 놈이 좋은 놈인지 알아야 함
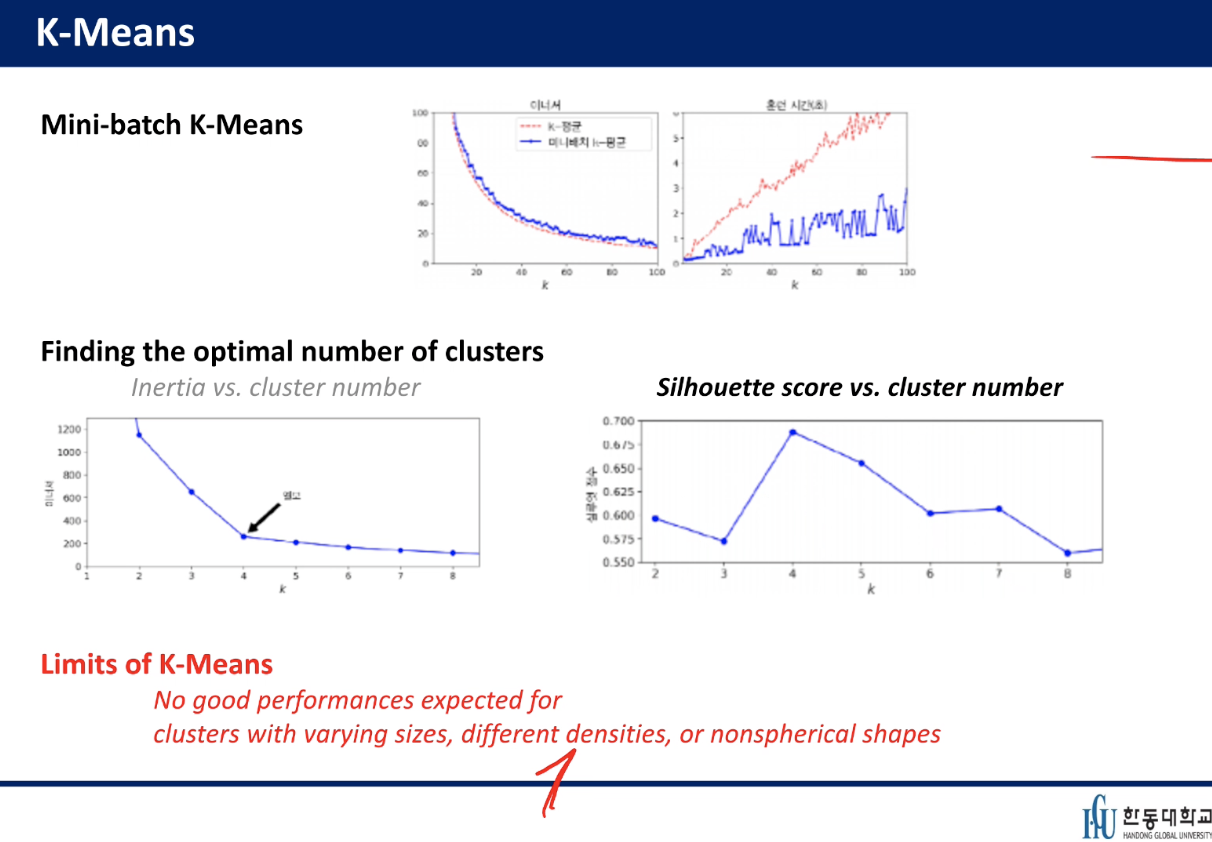
Inertia가 작은 cluster 가 좋음
각각 데이터 포인트 하나당 가까운 센트로이드 거리의 제곱의 합 - balance가 잘 되어진
Mini-batch K-means - 모든 데이터를 쓰지 않음
DBSCAN(Density Based Spatial Clustering of Application with Noise)
defines clusters as continuous regions of high density
dense 한 것을 따라감
connection 이 중요함

DBSCAN은 prediction하는 모델이 아님
- clustering 먼저 하고
- kNeighborsClassifier 하면 prediction
Gaussian Mixture Model (GMM)
임의의 distribution을 보았을 때 Gaussian function들의 합을 보게되는 것임
세 개의 parameter가 있음
1. Mean point
2. Standard deviation이 얼마나 되는지
3. 얼마나 많은 population을 갖는지
