Advantage 함수
Advantage 함수 도입 의도
task의 action value function Q는 어떤 action을 취하든 받게 되는 할인 총 보상이 상태 s에 의해서만 결정되는 면이 있다.
Ex) 상태 s가 거의 쓰러지기 직전이면, action이 왼쪽이든 오른쪽이든 pole은 넘어질 것이고 그에 따라 reward의 합계도 매우 적을 것이다. 즉 Q 함수가 갖는 정보를 상태 s만으로 결정되는 부분과 acton에 따라 결정되는 부분으로 나누어 볼 수 있다.
- Q 함수를 상태 s만으로 결정되는 가치 함수 의 weight는 action과 상관없이 매 step마다 학습할 수 있다.
- action에 따라 결정되는 Advantage인 로 나눠서 학습하여 마지막 output에서 로 Q 함수를 계산한다.
DQN과 비교했을 때 장점
의 weight는 action과 상관없이 매 step마다 학습가능. 그 덕분에 DQN에 비해 적은 수의 episode 만으로 학습을 마칠 수 있음. 특히 action 수가 늘어날수록 이득.
``
Dueling Network 구현 고드
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, n_in, n_mid, n_out):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_in, n_mid)
self.fc2 = nn.Linear(n_mid, n_mid)
# Dueling Network
self.fc3_adv = nn.Linear(n_mid, n_out) # Advantage 함수
self.fc3_V = nn.Linear(n_mid, 1) # Value 함수
def forward(self, x):
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
adv = self.fc3_adv(h2) # 이 출력은 ReLU를 거치지 않음
val = self.fc3_V(h2).expand(-1, adv.size(1)) # 이출력은 ReLU를 거치지 않음
# self.fc3_V_(h2)는 [minibatch * 1] 크기
# .expand(-1, adv.size(1))은 [minibatch * n_out] 크기로 확장
output = val + adv - adv.mean(1, keepdim=True).expand(-1, adv.size(1))
# val + (adv - adv.mean())
# axis=1 방향으로 keepdim=True 구함
# keepdim을 사용하지 않으면 [minibatch*1]이 되지 않고, [minibatch]가 됨.
# expand로 크기를 [minibatch*2]로 늘림
return outputadv - mean.adv하는 이유
action 수에 따라 서로 다른 bias가 적용된 채로 학습이 진행돼서 학습이 잘 안될 수 있음.
Ex). Advantage에서 오른쪽 action에 해당하는 값이 b0 라고 할 때, 이 state에서 을 제대로 계산하려면 바이어스 b0를 상쇄시키기 위해 에 바이어스 -v0을 적용해야 한다. 즉 와 에서 서로 바이어스를 상쇄시킬 수 있으므로 어떤 바이어스 값이 되더라도 학습이 잘됨.
한편 왼쪽에 해당하는 바이어스가 이라고 할 때, state에 대응하는 부분에 바비어스 을 적용해야 한다. 행동의 종류에 따라 서로 다른 바이어스 와 이 V(s)에 적용되는데, 같은 부호를 가지게 되면 잘 구분하지 못하기 때문에.
오른쪽, 왼쪽 action에 대한 값을 양과 음의 부호로 확실히 구분지어 학습이 되게끔하기 위해 평균 값을 뺀다.
이렇게 오른쪽을 계산하는 식에 왼쪽의 action도 값도 같이 update되기 때문에 가 왼쪽, 오른쪽 따로 계산되는 일도 방지할 수 있다.
하나의 action에 대해 Q(s,a) 출력값에서 역전파되어 학습될 때 모든 action들이 같이 한번에 Adv(s,a)가 update되므로 action마다 다른 bias가 적용되는 현상을 줄이게 되는 것이다.
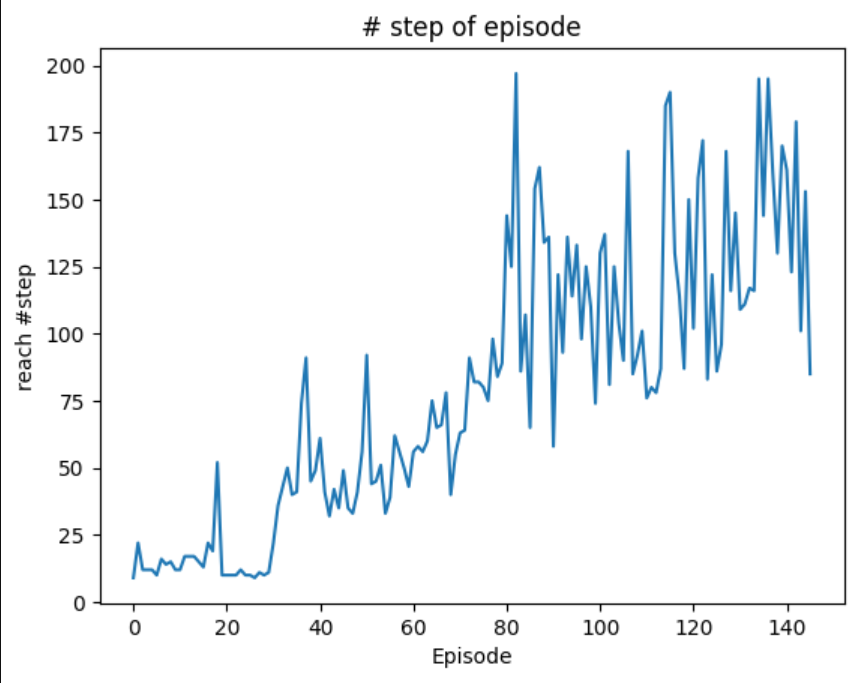
결과