개요
- train_data와 test_data 나누기
- 모델 학습 해보기
- 혼돈 행렬
어제 부족한 부분 추가
- 데이터 정제
- 일행이 몇명 탔는지에 대한 데이터 추가
- Dtype가 int, float가 아닌 데이터들 int, float형으로 변환
# 일행 데이터 추가 +1은 자기 자신 포함
train['FamilySize'] = train['SibSp'] + train['Parch'] + 1
test['FamilySize'] = test['SibSp'] + test['Parch'] + 1
embarked_mapping = {"S": 0, "C": 1, "Q": 2}
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].map(embarked_mapping)
print(train['Embarked'].value_counts())
# 일행 데이터 추가로 인한 데이터 drop
train.drop('SibSp', axis=1, inplace = True )
test.drop('SibSp', axis=1, inplace = True )
train.drop('Parch', axis=1, inplace = True )
test.drop('Parch', axis=1, inplace = True )- 결측치 해결 및 데이터 정제 완료 데이터 정보
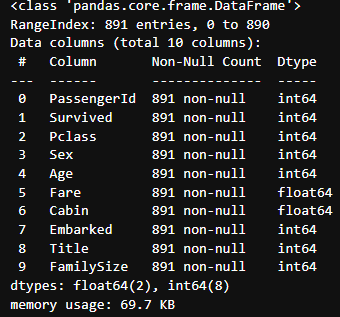
데이터 학습을 위한 데이터 분류
- train의 데이터 항목에만 있는 Survived가 target
- 훈련, 테스트 데이터에서 PassengerId 부분 삭제
- train_data에서 target인 Survived drop
train = train.drop(['PassengerId'], axis = 1) # 훈련에서 passengerID 삭제
train_data = train.drop('Survived', axis = 1)
target = train['Survived']
test_data = test.drop('PassengerId', axis = 1)
#
dicaprio = [ [3., 0., 1., 0., 0., 1., 0, 0] ] #남자주인공
winslet = [ [1., 2., 2., 2., 1., 1., 1, 1] ] #여쟈주인공
df = pd.DataFrame(winslet , columns= ['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Title', 'FamilySize'])다양한 모델로 학습해보기
- SVC
kfold= KFold(n_splits=10, shuffle=True, random_state=0)
modelSVC = SVC()
score = cross_val_score(modelSVC, train_data, target, cv=kfold, scoring='accuracy')
print('SVC훈련 검증 결과 =', round(np.mean(score)*100,2))검증결과

modelSVC.fit(train_data, target)
def isSurvived_SUV(PassengerInfo):
test_data = pd.DataFrame(PassengerInfo, columns=['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Title', 'FamilySize'])
prediction = modelSVC.predict(test_data)
if prediction[0]==1:
print(PassengerInfo)
print('Result = not survived')
else:
print(PassengerInfo)
print('Result = Survived')
isSurvived_SUV(dicaprio)
isSurvived_SUV(winslet)결과
dicaprio
[[3.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0, 0]]
Result = Survivedwinslet
[[1.0, 2.0, 2.0, 2.0, 1.0, 1.0, 1, 1]]
Result = Survived
2.DecisionTreeClassifier
modelDT = DecisionTreeClassifier()
score2 = cross_val_score(modelDT, train_data, target, cv=kfold, scoring='accuracy')
print('modelDT 검증 결과 =', round(np.mean(score2)*100,2))검증 결과

def isSurvived_DT(PassengerInfo):
test_data = pd.DataFrame(PassengerInfo, columns=['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Title', 'FamilySize'])
prediction = modelDT.predict(test_data)
if prediction[0]==1:
print(PassengerInfo)
print('Result = not survived')
else:
print(PassengerInfo)
print('Result = Survived')
isSurvived_DT(dicaprio)
isSurvived_DT(winslet)결과
dicaprio
[[3.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0, 0]]
Result = Survivedwinslet
[[1.0, 2.0, 2.0, 2.0, 1.0, 1.0, 1, 1]]
Result = Survived
- LogisticRegression
lr = LogisticRegression()
score3 = cross_val_score(modelDT, train_data, target, cv=kfold, scoring='accuracy')
print('lr 검증 결과 =', round(np.mean(score3)*100,2))검증 결과

def isSurvived_lr(PassengerInfo):
test_data = pd.DataFrame(PassengerInfo, columns=['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Title', 'FamilySize'])
prediction = lr.predict(test_data)
if prediction[0]==1:
print(PassengerInfo)
print('Result = not survived')
else:
print(PassengerInfo)
print('Result = Survived')
isSurvived_lr(dicaprio)
isSurvived_lr(winslet)결과
dicaprio
[[3.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0, 0]]
Result = Survivedwinslet
[[1.0, 2.0, 2.0, 2.0, 1.0, 1.0, 1, 1]]
Result = not survived

안녕하세요. 도야입니다