0. Abstract
새로운 형태의 깊은 문맥화된(deep contextual-ized) 단어 표현을 소개하며, 이 표현이 두 가지 주요 문제를 해결한다고 설명한다:
-
단어 사용의 복잡한 특성 모델링: 여기에는 구문적(syntax) 및 의미적(semantics) 특성이 포함된다. ELMo 단어가 문맥에 따라 어떻게 다르게 사용되는지(다의성, polysemy)를 반영할 수 있는 모델을 제안한다.
-
문맥에 따른 의미 변화 반영: 단어가 문장 내에서 다르게 사용될 때, 이를 모델링하는 것이 핵심 목표다. 이를 위해 ELMo는 양방향 언어 모델(bidrectional Language Model, biLM)의 내부 상태를 학습하여 각 단어의 벡터를 문맥 의존적으로 변형시킨다.
ELMo의 큰 장점은 사전 학습된 양방향 언어 모델을 기반으로 하기 때문에 기존 NLP 모델에 쉽게 통합될 수 있으며, 텍스트 추론, 질문 응답, 감정 분석 등 여러 NLP 문제에서 최신 성능을 기록하는 데 기여할 수 있다는 점이다.
이 논문은 6개의 주요 NLP 작업에서 ELMo가 어떻게 성능을 향상시키는지 실험을 통해 보여주며, 기존 접근 방식보다 더 나은 결과를 달성한다. 특히, 사전 학습된 모델의 내부 상태를 드러내는 것이 중요하며, 이를 통해 후속 모델들이 다양한 준지도 학습 신호를 혼합해 사용할 수 있음을 강조한다.
*Corpus: NLP에서 대규모 텍스트 데이터를 의미.
1. Introduction
ELMo(Embeddings from Language Models)라는 새로운 형태의 깊은 문맥적 단어 표현을 소개하며, 이는 기존의 사전 훈련된 단어 임베딩(예: Word2Vec, GloVe)이 가진 몇 가지 한계를 해결하려는 목적을 가지고 있다.
기존 단어 임베딩의 한계:
- 기존 임베딩은 주어진 단어의 고정된 표현을 사용하기 때문에 단어의 의미가 문맥에 따라 변화하는 다의어 문제를 잘 다루지 못했다.
ELMo의 차별점:
- 깊은 문맥적 임베딩: ELMo는 문맥에 따라 단어의 의미를 동적으로 변환할 수 있도록 각 단어가 입력된 문장의 전체 문맥에 기반하여 임베딩을 생성한다.
- biLSTM 사용: ELMo는 bidirectional LSTM(biLSTM)을 기반으로 하며, 큰 텍스트 코퍼스에서 언어 모델(LM) 목표로 학습된다.
- 모든 내부 레이어 활용: 단어 임베딩은 단순히 biLSTM의 마지막 레이어에서 추출되는 것이 아니라, 모든 내부 레이어의 선형 결합을 통해 만들어진다. 이는 단순히 마지막 레이어만 사용하는 것보다 훨씬 더 풍부한 정보를 제공한다.
문맥 정보의 활용:
- ELMo의 고차원 레이어는 단어의 문맥적 의미를 잘 반영하여, 단어 의미 구분(WSD)과 같은 태스크에서 유용하게 사용될 수 있다.
- 낮은 차원의 레이어는 구문적 정보(예: 품사 태깅)와 같은 문법적 요소를 캡처한다.
결과:
- 다양한 NLP 태스크에서 ELMo를 적용한 결과, 기존 방법에 비해 성능이 크게 향상되었다. 특히 텍스트 추론, 질문 응답, 감정 분석과 같은 복잡한 문제에서 성과를 보였으며, 때로는 20%에 달하는 상대적 오류 감소를 기록했다.
2. Related work
언어 모델에서 사전 훈련된 단어 벡터와 문맥을 반영한 표현을 학습하는 다양한 기존 연구를 설명하며, 새로운 ELMo(Embeddings from Language Models) 모델이 이들 연구와 어떻게 다른지 다룬다.
-
사전 훈련된 단어 벡터의 중요성과 한계를 언급한다. 단어 벡터는 많은 NLP 모델에서 중요한 구성 요소이며, 다양한 태스크에서 유용하지만, 이 벡터들은 각 단어에 대해 문맥에 독립적인 고정된 표현만을 제공한다. 이를 보완하기 위해 최근에는 단어의 다양한 의미를 포착하는 방법들이 연구되었다. 예를 들어, 서브워드 정보(단어의 부분 정보)를 활용하거나 단어의 의미별로 서로 다른 벡터를 학습하는 방식들이 제안되었다.
-
문맥을 고려한 단어 표현을 학습하는 방식들도 제안되었다. context2vec이나 CoVe와 같은 모델들은 단어 주변의 문맥 정보를 고려한 단어 표현을 생성한다. CoVe는 기계 번역 시스템을 사용한 반면, ELMo는 큰 규모의 모노링구얼 데이터(한 언어로만 구성된 데이터)를 사용하여 학습되며, 이로 인해 더 풍부한 표현을 제공한다. 특히, ELMo는 깊이 있는 문맥화된 표현을 학습하고, 이를 통해 다양한 NLP 태스크에서 뛰어난 성능을 발휘한다.
-
이전 연구들은 심층 양방향 RNN(biRNN)의 다른 레이어가 서로 다른 유형의 정보를 인코딩한다는 점을 강조한다. ELMo 역시 이러한 구조를 통해 다양한 정보를 효율적으로 인코딩하며, 이를 다운스트림 태스크에 활용할 때 매우 유용하다는 것을 보여준다.
3. ELMo: Embeddings from Language Models
3-1. 양방향 언어 모델(Bidirectional language models)
이 부분은 ELMo의 핵심 구성 요소 중 하나인 Bidrectional Language Model (양방향 언어 모델, biLM)을 설명하고 있다. 양방향 언어 모델은 주어진 시퀀스에서 단어의 앞뒤 문맥을 모두 고려하여 단어 임베딩을 생성하는 방법이다.
1. 순방향 언어 모델 (Forward Language Model)
순방향 언어 모델은 주어진 시퀀스에서 앞에서부터 뒤로 단어를 예측한다. 시퀀스가 (t_1, t_2, …, t_N)일 때, 각 단어 t_k는 그 이전 단어들 의 문맥에 따라 예측된다.
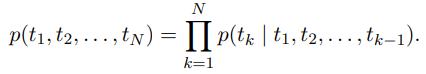
즉, t1부터 t_N까지의 시퀀스 전체의 확률은 각 단어 t_k가 그 이전 단어들 (t_1, …, t{k-1})에 기반해 예측되는 조건부 확률들의 곱이다. 예를 들어, 문장을 순서대로 처리하며, t_k는 그 이전의 모든 단어들로부터 추론된다.
2. 역방향 언어 모델 (Backward Language Model)
역방향 언어 모델은 순방향과 비슷하지만, 시퀀스를 반대로 처리한다는 점이 다르다. 즉, 단어의 다음 문맥을 기반으로 그 이전 단어를 예측하는 방식이다. 주어진 시퀀스 (t1, t_2, …, t_N)에서 각 단어 t_k는 그 이후에 나올 단어들 (t{k+1}, t_{k+2}, …, t_N)을 기반으로 예측된다.
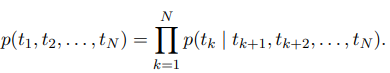
이 역방향 모델도 LSTM 구조를 따르며, 시퀀스를 역순으로 처리해 각 단어에 대해 다음 문맥을 사용해 문맥 의존적인 표현을 생성한다.
3. 양방향 언어 모델 (Bidrectional Language Model, biLM)
양방향 언어 모델(BiLM)은 순방향 언어 모델과 역방향 언어 모델을 결합한 구조이다. BiLM은 단어의 앞뒤 문맥을 모두 고려하여 단어의 의미를 더 잘 반영할 수 있다.
- BiLM의 손실 함수: BiLM은 순방향 모델과 역방향 모델의 로그 가능도(log-likelihood)를 함께 최적화한다. 순방향 모델은 이전 문맥을 기반으로, 역방향 모델은 이후 문맥을 기반으로 각각의 단어를 예측하며, 이를 동시에 학습한다.
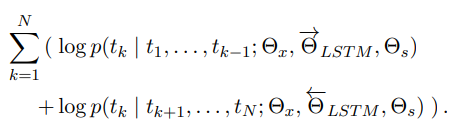
- 파라미터 공유: 순방향과 역방향 LSTM에서 토큰 표현 파라미터와 Softmax 레이어 파라미터는 공유하지만, 순방향과 역방향 LSTM의 파라미터는 서로 독립적이다. 이로써 양방향 모델에서 동일한 입력 토큰에 대해 일관된 토큰 표현을 사용할 수 있지만, 문맥을 처리하는 방식은 독립적으로 학습된다.
이 구조 덕분에 ELMo는 문맥을 반영한 동적 단어 임베딩을 생성하며, 다양한 NLP 테스크에서 성능을 향상시킬 수 있다.
3-2. ELMo
ELMo가 biLM(Bidrectional Language Model)에서 생성된 여러 계층의 중간 표현들을 결합해 특정 작업에 맞는 단어 임베딩을 만드는 방법을 설명한다. ELMo는 단어마다 여러 층의 표현을 가중합해 사용하므로, 각 작업에 맞게 임베딩을 조정할 수 있다.
1. biLM이 만드는 표현 (Intermediate Layer Representations)
biLM은 양방향 LSTM으로 구성된 언어 모델로, 각 토큰 t_k에 대해 여러 계층의 문맥 의존적 표현을 생성한다. biLM은 L층의 양방향 LSTM으로 이루어져 있으며, 이 모델을 통해 각 단어는 총 2L + 1 개의 표현을 얻을 수 있다. 여기서 표현들은 다음과 같은 것들로 구성된다:
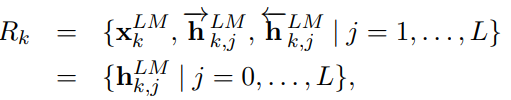
- 입력 임베딩
- 순방향 LSTM의 j번째 층에서의 출력
- 역방향 LSTM의 j번째 층에서의 출력
이들을 모두 합치면 다음과 같은 표현 벡터가 생성된다:
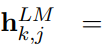
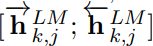
j-번째 층에서 양방향 LSTM의 출력을 합친 벡터이다.
2. ELMo 표현을 하나의 벡터로 결합 (Collapsing Layers into a Single Vector)
ELMo는 biLM에서 생성된 여러 층의 표현들을 결합해 하나의 벡터를 만든다. 가장 간단한 경우에는 biLM의 최상위 계층의 출력을 선택하는 방식이다. 예를 들어:
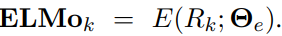
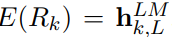
이 방식은 Peters et al. (2017)과 McCann et al. (2017)의 TagLM 및 CoVe 모델에서 사용된 방식과 유사하다. 최상위 계층만을 사용하는 방식이지만, 모든 층의 표현을 가중합해 사용할 수 있다.
3. 작업별 가중합 (Task-Specific Weighted Sum of Layers)
ELMo의 핵심 장점은 단순히 최상위 층의 출력을 사용하는 것이 아니라, 각 층의 출력을 가중합하여 특정 작업(task)에 맞게 조정할 수 있다는 것이다. 이를 수식으로 표현하면 다음과 같다:
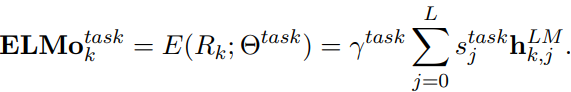
- s_j^{task}: 각 층 j의 표현에 할당된 가중치로, softmax로 정규화된 값이다. 이 가중치들은 학습을 통해 각 작업에 맞는 최적의 값을 찾는다.
- r_{k, j}^{LM}: 전체 ELMo 벡터의 크기를 조정하기 위한 스칼라 파라미터이다. 이 값은 각 작업에 맞춰 학습되며, 최적화 과정에서 중요한 역할을 한다.
이 과정에서 각 층의 가중치는 작업(task)에 맞게 자동으로 학습되므로, 특정 작업에 더 적합한 표현이 강화된다.
4. 레이어 정규화 (Layer Normalization)
각 층에서 나온 출력 값들은 분포가 서로 다를 수 있다. 따라서 가중합을 하기 전에 Layer Normalization을 적용하는 경우가 있다. 레이어 정규화는 각 층의 출력을 정규화하여, 값들의 분포 차이를 줄이고 더 안정적인 학습을 가능하게 한다.
Ba et al. (2016)의 레이어 정규화 기법은 층마다 평균과 분산을 조정하여 각 층의 출력을 정규화한다. 이를 통해 가중합 과정이 더 효과적으로 이루어지며, 이는 특히 층 간 분포가 큰 차이를 보일 때 도움이 된다.
요약
- biLM 출력: 각 토큰 tkt_ktk에 대해 biLM은 토큰 임베딩과 여러 층의 양방향 LSTM 출력을 포함해 총 2L+12L+12L+1개의 표현을 만든다.
- ELMo 표현 결합: ELMo는 각 층의 출력을 결합해 단일 벡터로 만들며, 이는 특정 작업에 맞게 조정됩니다. 단순한 경우 최상위 층을 사용할 수 있지만, 더 일반적으로는 각 층의 출력을 가중합하여 사용한다.
- 작업별 가중합: 각 층의 가중치는 softmax로 정규화된 값이며, 작업별로 최적화됩니다. 또한, 벡터 크기를 조정하는 스칼라 파라미터도 함께 학습된다.
- 레이어 정규화: 층 간의 출력 분포 차이를 줄이기 위해 가중합 전에 레이어 정규화를 적용할 수 있다.
이를 통해 ELMo는 다양한 NLP 작업에서 문맥에 맞는 동적인 단어 임베딩을 제공하며, 작업에 따라 단어 표현을 최적화할 수 있는 유연성을 제공한다.
4. Evaluation
ELMo(Embeddings from Language Models)를 다양한 NLP 태스크에서 사용했을 때의 성능 향상을 평가한 결과를 제시한다. ELMo를 기존 모델에 추가하는 것만으로도 모든 실험에서 성능이 개선되었으며, 태스크에 따라 6%에서 20%까지의 오류 감소를 확인할 수 있다.
[Table 1]
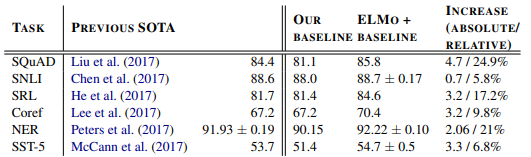
- Previous SOTA: SQuAD 태스크에 대해 보고된 이전의 최고 성능 점수
- Our Baseline: ELMo를 사용하지 않은 모델의 성능. 즉, ELMo를 적용하기 전의 성능
- ELMo + Baseline: ELMo를 적용한 후의 모델이 SQuAD 태스크에서 달성한 성능
- Increase (Absolute/Relative):
- Absolute Increase: ‘ELMo + Baseline’ - ‘Our Baseline’
- Relative Increase: (Absolute Increase / Our Baseline) * 100
ELMo의 성능은 텍스트 이해와 관련된 다양한 NLP 작업에서 평가되었다.
질문 응답(SQuAD), 텍스트 추론(SNLI), 의미역 분석(SRL), 개체명 인식(NER), 감정 분석(SST-5), 그리고 공지 참조 해결(Coreference Resolution) 등의 과제에서 ELMo를 사용해 성능을 평가했다.
실험 결과, ELMo는 모든 태스크에서 최신 성능을 기록하며, 기존 모델 대비 상당한 성능 향상을 보였다. 예를 들어, SQuAD 데이터셋에서 ELMo를 추가한 모델은 F1 점수가 81.1%에서 85.8%로 4.7% 상승했으며, 이는 상대적으로 24.9%의 오류 감소에 해당한다. 마찬가지로 NER 작업에서도 F1 점수가 90.15%에서 92.22%로 2.06% 상승했으며, 이는 21%의 상대적 오류 감소를 의미한다.
5. Analysis
Table 1
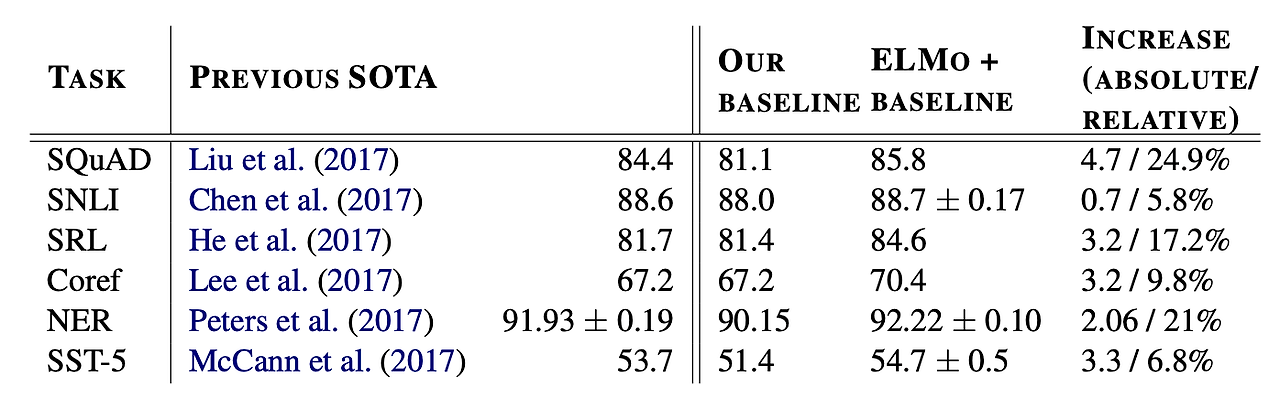
여섯 개의 NLP benchmark task에 ELMo를 적용한 결과를 보여준다.
각각의 task는 차례대로 QA task, Textual entailment, Sementic role labeling, Coreference resolution, Named entity extraction, Sentiment analysis의 benchmark task 이다.
Table 2
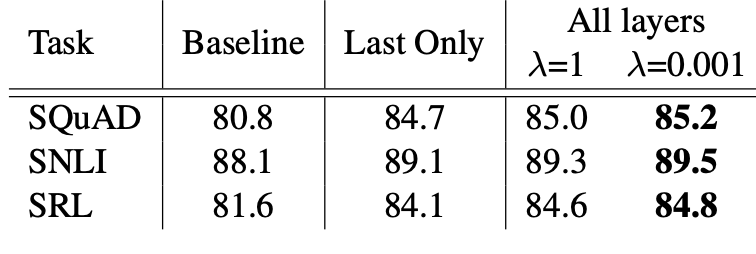
regularization parameter λ에 따른 성능 비교이다.
모든 biLM layer를 사용하여 ELMo를 표현하고 적절한 λ를 적용하였을 때 가장 좋은 성능을 보였다.
Table 3

ELMo representation이 추가되는 위치에 따른 성능 비교이다.
단순히 input의 위치에서만 ELMo를 추가하는 것이 아닌, 입,출력 동시에 추가했을 경우, 출력에만 추가했을 경우를 비교했다.
세 가지 Task의 결과가 일치되지는 않았지만 대체로 입,출력에 모두 ELMo를 적용한 모델 성능이 좋았다. 하지만 이를 통해, Task 별로 ELMo representation이 필요한 위치가 다름을 알 수 있다.
Table 4

play 라는 단어에 대한 GloVe와 biLM의 representation vector를 통하여 유사한 단어들을 확인해본 결과이다.
GloVe의 결과는 스포츠와 관련된 단어들이 주를 이뤘다. 그리고 GloVe는 하나의 단어에 대해 하나의 벡터 표현만을 갖고 있기 때문에 같은 play를 유사한 단어로 추천하지 않았다.반면에, biLM의 play는 각각 다른 문맥에서 주어진 play와 의미가 일치하는 play를 각각 유사한 단어로 추천한 결과를 확인할 수 있다.
Table 5,6
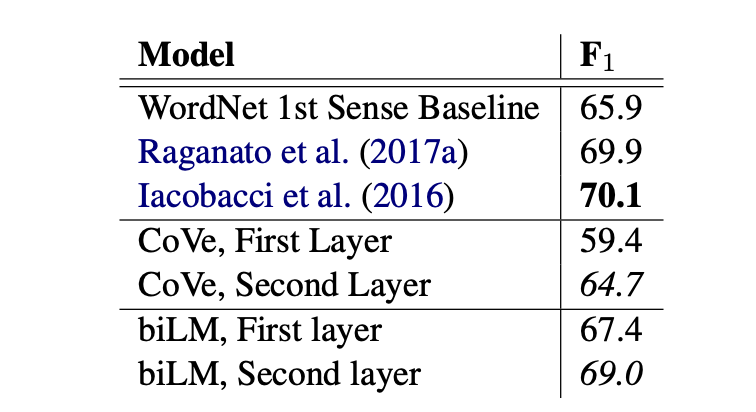
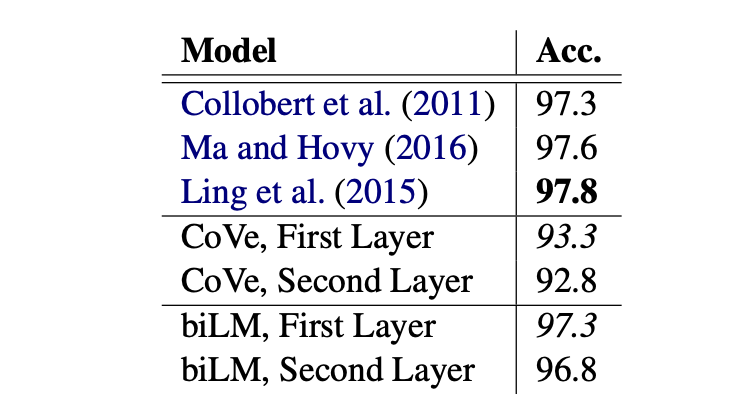
Table 5는 Context 능력이 중요한 Word sense disambiguation(WSD, 단어 의미 중의성해소) task의 결과이며, Table 6는 Syntax 능력이 중요한 Pos tagging task의 결과이다.
우선, 두 실험에서 모두 biLM이 준수한 성능을 보였음을 확인할 수 있다.
본 실험을 통해 알 수 있는 중요한 정보가 있다.
WSD의 경우, First layer를 이용한 것 보다 Second layer를 이용한 성능이 좋았기 때문에 higer-layer가 context 파악에 있어 더 중요한 정보를 제공 한다는 것을 확인할 수 있었다.
또한, POS-tagging에 있어서는 First layer를 사용한 성능이 더 좋았다는 점에서 lower-layer가 Syntax를 파악에 있어 더 중요한 정보를 제공한다는 것을 확인할 수 있었다.
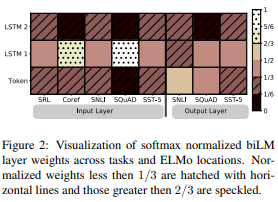
Figure 1
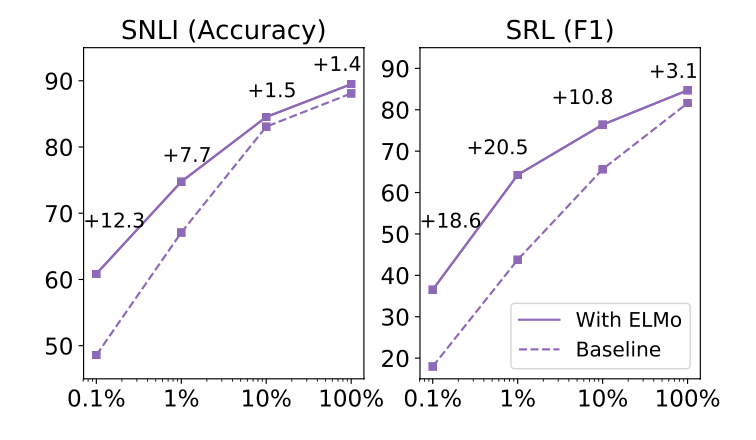
Train set의 크기에 따른 성능 비교이다.
학습데이터가 작을수록 ELMo를 사용하면 더 효율적인 학습이 가능함을 확인할 수 있다.
Figure 2
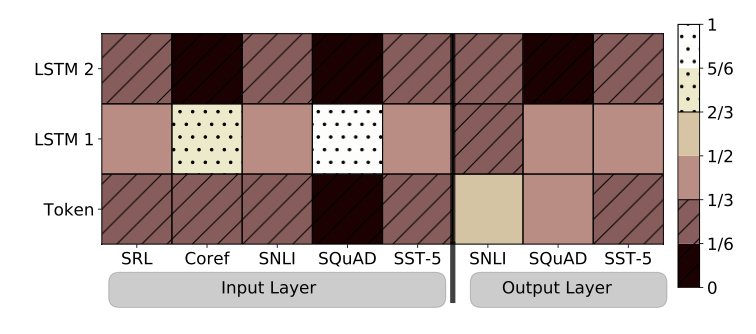
task의 Input Layer와 Output Layer가 더 높은 가중치를 두는 biLM layer를 확인하기 위한 시각화 결과이다.
Input Layer는 상대적으로 첫번째 layer에 높은 가중치를 두었으며, Output Layer는 상대적으로 모든 layer에 대해 균형잡힌 가중치를 두고 있음을 확인할 수 있다.
6. Conclusion
ELMo는 기존의 단어 임베딩 기법과 달리, 단어의 문맥적 의미를 반영하는 깊은 문맥화된 단어 표현을 제공한다. 이 논문은 ELMo가 단순한 고정된 단어 벡터를 사용하는 기존의 임베딩 기법보다 훨씬 더 풍부하고 정교한 표현을 제공함을 입증했다. 특히, 양방향 언어 모델(biLM)을 사용하여 각 단어의 앞뒤 문맥을 모두 고려한 벡터를 생성하며, 이는 문법적 정보와 의미적 정보를 모두 포함하는 다층적 표현을 가능하게 한다.
ELMo는 다양한 NLP 과제에서 최신 성능을 기록하며, 기존 모델에 쉽게 추가할 수 있는 장점이 있다. 또한, ELMo는 모든 층의 정보를 결합하여 단일 층에서 파생된 벡터를 사용하는 기존 방식보다 더 풍부한 문맥 정보를 제공하며, 다의어 문제나 문맥 변화에 따른 의미 변화를 효과적으로 처리할 수 있다. 저자들은 ELMo가 앞으로도 많은 NLP 문제에서 중요한 역할을 할 것으로 기대하며, 특히 적은 양의 데이터로도 높은 성능을 발휘할 수 있는 강력한 모델임을 강조한다. 결론적으로, ELMo는 향후 다양한 NLP 작업에서 문맥화된 단어 표현의 표준이 될 가능성이 크다고 본다.
