FCN : Fully Convolutional Networks for Semantic Segmentation
오늘 review해 볼 논문은 2015년도에 나온 Fully Convolutional Networks for Semantic Segmentation입니다!
논문 제목 : Fuuly Convolutional Netwokrs for Semanctic Segmentation
저자 : jonathan Long et al.
학회 : CVPR2015
게재 년도 : 2015년
인용수 : 52,590회
0.필수 개념
먼저 필수 개념에 대해서 알아보고 시작하겠습니다~
Fully Conovlutional Networks는 Semantic Segmentation을 위한 Networks인데요,
여기서 Semantic Segmentation이 뭔지 알아보고 가겠습니다!
Image Segmentation이란?
정의 : 이미지 내에 있는 각 물체(object)들을 의미 있는(semantic) 단위로 분할(segmentation)하는 작업을 의미합니다
->각 pixel마다 클래스(class)를 할당하는 작업입니다
- 일반적인 분류(classification)에서는 단일 이미지를 하나의 클래스로 분류합니다
- 분할(segmentation)에서는 각 픽셀마다 하나의 클래스로 분류합니다
Semantic segmentation을 진행하면, 이미지가 주어졌을 때 (높이 X 너비 X 1) 크기를 가지는 한 장의 분할 맵(segmentation map)이 생성됩니다
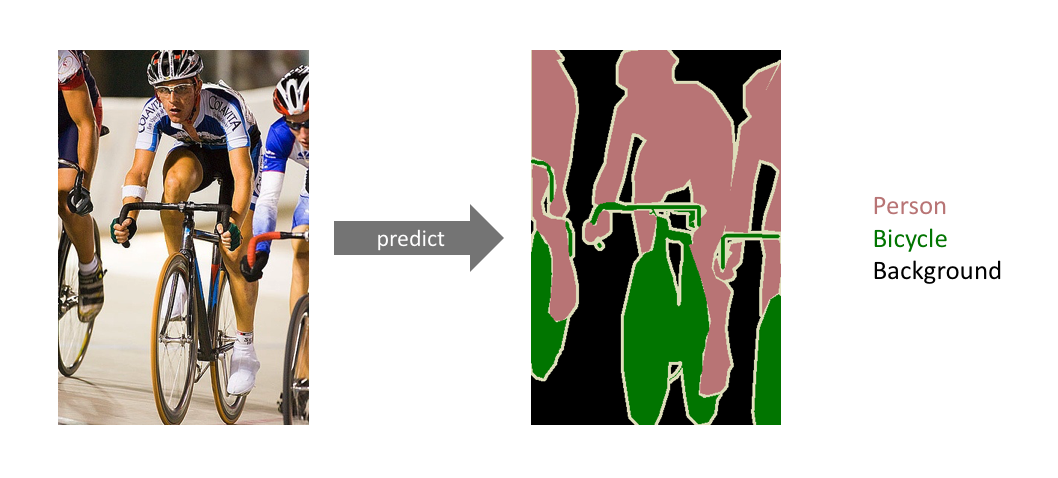
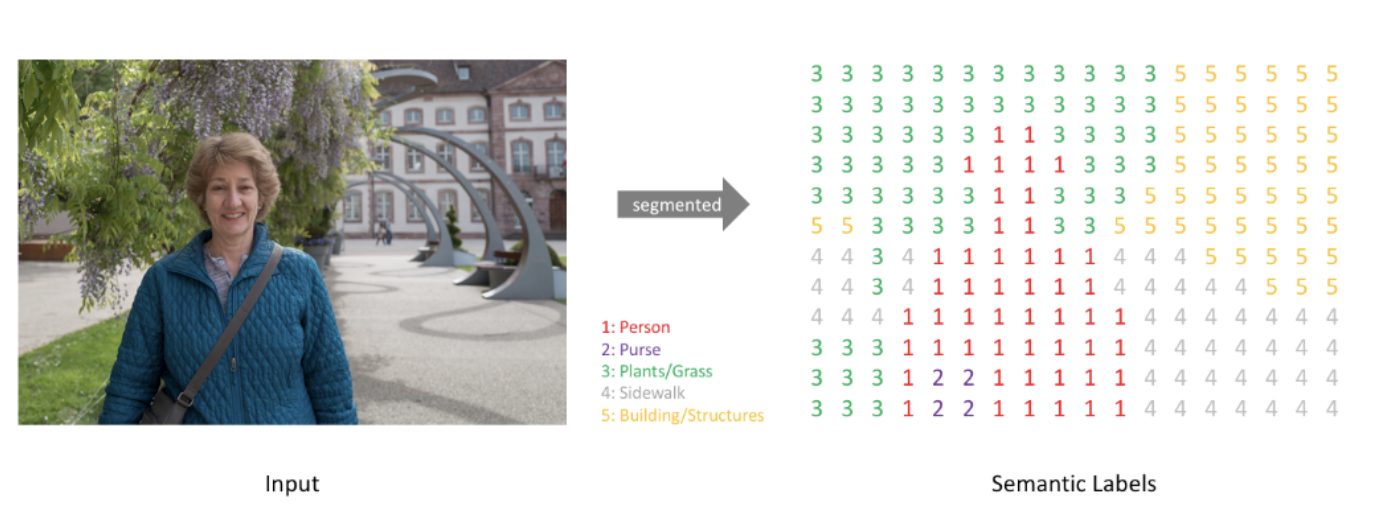
Semantic Segmentation이란?
정의 : 이미지에서 각 pixel의 의미(class)를 예측하는 컴퓨터 비전 기술
->예를 들어, 도로 장면에서 각 pixel을 하늘, 도로, 차량, 보행자와 같은 class로 분류하여 이미지를 pixel 단위로 분할합니다
-> 이미지의 각 pixel을 특정 class에 할당하는 작업으로, 이미지에서 어떤 객체가 어디에 있는지를 파악하는데 유용합니다.
- 이미지의 모든 pixel을 특정 class에 할당합니다
-> 예를 들어, 고양이 이미지에서는 모든 고양이 pxiel을 하나의 class로, 배경 pixel은 다른 class로 분류합니다.- semantic segmentation은 같은 class의 객체들을 하나의 그룹으로 묶으며, 객체의 개별적 경계를 구분하지 않습니다
-> 예를 들어, 여러 명의 사람이 있을 때 모든 사람을 같은 '사람' class로 지정하고 개별 사람을 구분하지 않습니다.
CNN
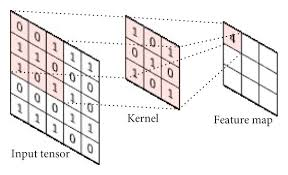
CNN에서는 filter 또는 kernel이라고 부르는 것을 사용합니다
- 각 filter는 입력에서 특정한 특징(feature)를 잡아내어 특징맵(feature map)을 생성합니다
- 하나의 filter는 sliding 하면서 convolution 연산을 통해 feature map을 계산합니다
- 일반적으로 CNN 분류 모델에서 깊은 layer로 갈수록 채널의 수가 증가하고, 너비와 높이는 감소합니다
- convolution layer의 서로 다른 fitler들은 각각 적절한 특징(feture) 값을 추출하도록 학습됩니다
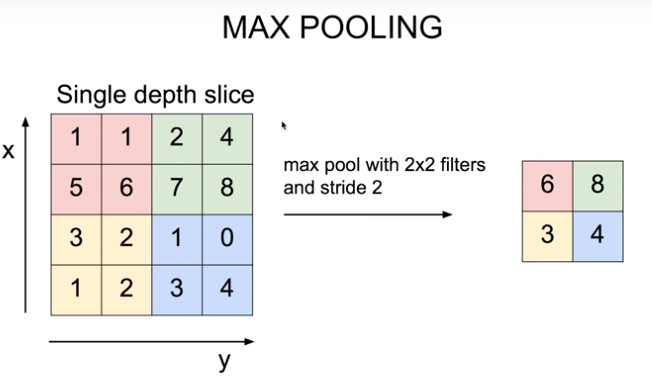
Max Pooling
CNN 분류 모델에서 중요한 정보는 유지한 상태로 해상도(너비와 높이)를 감소시키는 방법 중 하나입니다
- 가장 큰값을 가지는 원소(element)만 남깁니다
Down-Sampling & Up-Sampling
Down-Sampling : 너비와 높이 감소를 도와줍니다(해상도 감소)
Up-Sampling : 너비와 높이 증가를 도와줍니다(해상도 증가)
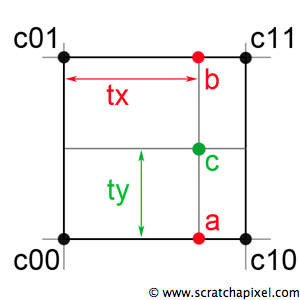
Bilinear Interpolation
2차원 공간에서 값을 추정하는 방법으로, 주로 이미지 처리에서 픽셀 값을 스무딩하거나 크기를 변경할 때 사용됩니다.
-> 이는 네 개의 주변 픽셀 값을 이용해 중간 위치의 값을 계산하는 방식입니다
지금까지 간단한 필수 개념에 대해서 알아보았습니다
이제 본격적으로 논문 review를 시작해보겠습니다!
1. 논문의 Contribution
본 논문인 Fully Convolutional Networks에서는 Semantic Segmentation 문제에 대해 Convolutional Neural Network(CNN)를 기반으로 한 새로운 접근법을 제시했는데요!
크게 3가지로 논문의 Contribution을 얘기할 수 있습니다!
1. End-to-End Learning을 위한 Fully Convolutional Architecture
- 기존의 CNN 구조에서는 Fully Connected(FC) layer를 통해 classification을 수행했습니다.
- 하지만 FC layer는 spatial 정보를 소실시키고, pixel 단위의 예측을 어렵게 만듭니다.
- 본 논문에서는 모든 layer를 convolution으로 대체하여 end-to-end 학습이 가능한 구조를 제안했습니다.
2. Skip Connection을 통한 Multi-Scale Feature Fusion
- 다중 해상도의 feature map을 결합하는 skip connection을 통해 더욱 세밀하고 정확한 segmenation 결과를 얻는 방법을 제안했습니다.
3. 다양한 모델 버전 제시
- FCN-32s, FCN-16s, FCN-8s 모델을 통해 coarse-to-fine 구조로 segmentation 성능을 점진적으로 개선하며 skip connection의 중요성을 입증했습니다.
2. 기존 방법 설명 & 한계점
1. 기존 방법
- Patch-Based Classification
- 초기의 semantic segmentation 방법들을 이미지에서 작은 patch를 추출한 후, 각 patch에 대해 객체를 분류하는 방식을 사용했습니다.
- patch 단위로 분류된 결과를 조합하여 전체 이미지의 segmenation을 수행했습니다.
- CNN-Based Approches
- CNN을 이용한 segmentation 방법은 patch 기반 접근 방식을 따랐습니다.
- 이 방식은 patch별로 분류와 위치 정보를 결합하여 segmentation 결과를 얻었지만, 이미지 전체를 한번에 처리할 수는 없었습니다.
2. 한계점
- 공간적 정보 손실
- FC layer는 spatial 정보를 소실시키고 이미지 전체의 정보를 평균화해 버리는 특성이 있어 정확한 위치 정보를 반영하기 어렵습니다.
- 비효율성
- patch 단위로 분류 작업은 계산량이 많아 느리고, 모델의 효율성이 떨어지며 실제 응용에 적용하기 어렵습니다.
- 객체 경계 식별 한계
- patch 단위로 segmentation을 수행할 경우 객체의 경계나 작은 세부 요소를 정확히 구분하는 데 한계가 있습니다.
3. Network Architecture
Network Architecture를 한 장으로 간단하게 설명해 놓은 그림입니다.
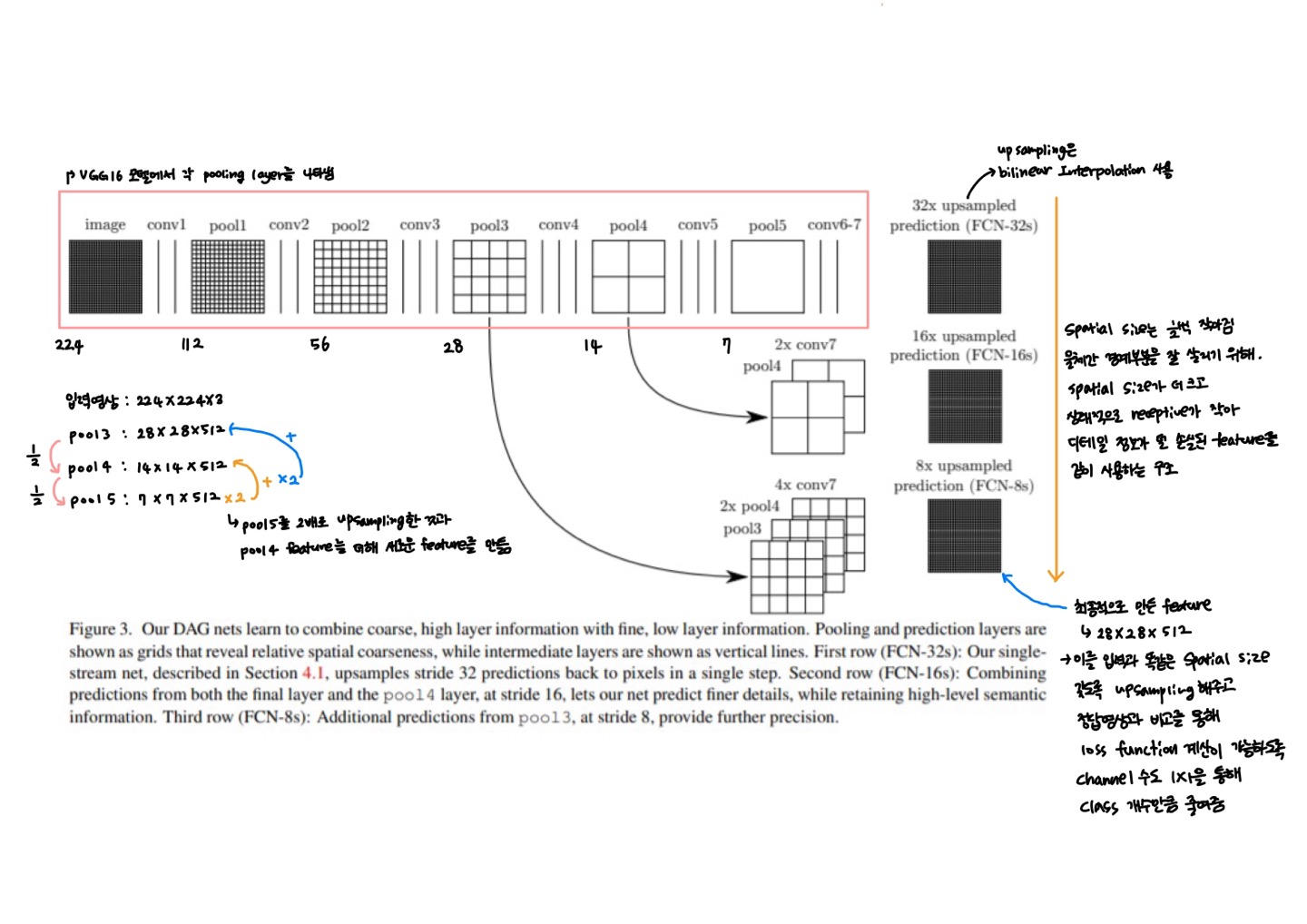
FCN-32s
- pool5에서 생성된 가장 coarse한 feature map을 32배로 upsampling하여 segmentation map을 생성합니다.
- 가장 높은 수준의 semantic 정보를 가지고 있지만, 세부적인 경계나 작은 객체의 예측이 어려울 수 있습니다.
FCN-16s
- pool5의 feature map을 2배로 upsampling하여 pool4와 결합한 후, 16배로 upsampling하여 segmentation map을 생성합니다.
- FCN-32s에 비해 더 세밀한 예측을 제공하며, pool4의 상대적으로 fine한 정보가 추가되면서 경계 구분이 향상됩니다.
FCN-8s
- pool4의 feature map을 pool3과 결합하여 8배로 upsampling하여 최종 segmentation map을 생성합니다.
- 가장 세밀한 정보를 제공하며, 객체의 경계와 작은 디테일까지 잘 예측할 수 있습니다.
좀 더 자세히 알아보겠습니다!
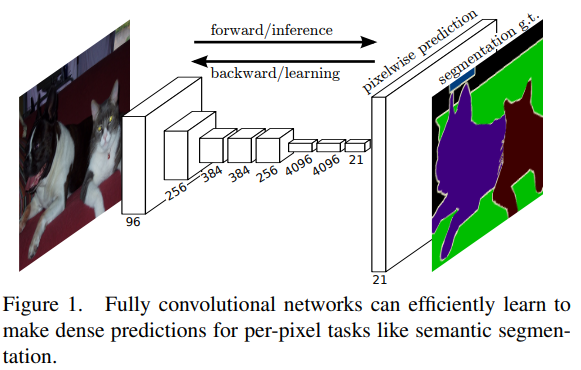
- FCN(Fully Convolutional Network) 논문에서 소개된 semantic segmentation 과정을 시각화한 그림입니다.
- FCN은 이미지의 각 pixel마다 특정 class를 예측하는 pixel-wise segmentation 작업을 수행합니다.
- 이 그림은 FCN이 이미지 분할을 위해 dense predictions를 수행하는 방법을 보여줍니다.
- FCN은 공간적 정보 소실 없이 end-to-end 학습을 통해 semantic segmentation을 수행할 수 있는 네트워크 구조를 제안하였고, 이 그림은 FCN 의 구조와 흐름을 간단히 시각화한 그림입니다.
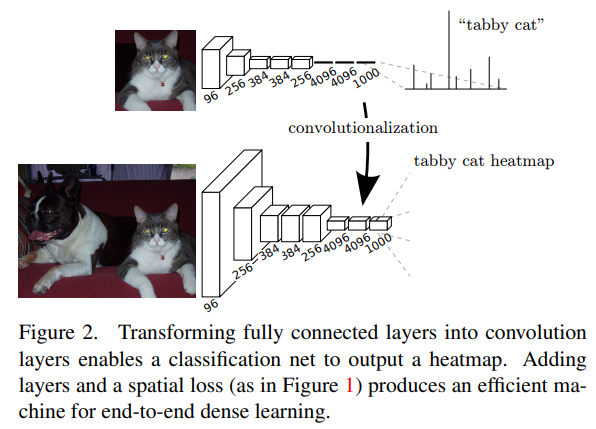
- 이 그림은 Fully Conovlutional Network(FCN)에서 classification 모델을 segmentation 모델로 변환하는 과정을 설명하고 있습니다.
- 구체적으로, 기존의 classification 네트워크를 convolutionalization을 통해 pixel-wise 예측을 할 수 있도록 변형하는 방법을 보여줍니다.
- 이 그림은 classification 네트워크가 segmentation을 수행할 수 있도록 FC layer를 convolution layer로 변환하여, 네트워크가 단일 class 예측 대신 각 pixel마다 해당 class의 확률을 예측할 수 있는 heatmap을 생성하는 방법을 설명하고 있습니다.
- 이를 통해 FCN이 end-to-end 학습이 가능한 효율적인 dense prediction 모델이 될 수 있음을 보여줍니다
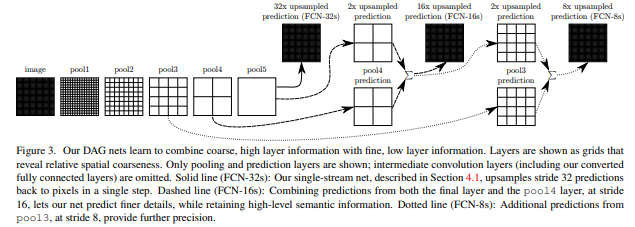
-이 그림은 FCN(Fully Convolutional Network)에서 사용되는 skip architecture의 구조를 시각화한 것입니다.
- 이 구조는 서로 다른 해상도(다른 stride)에서 생성된 feature map을 결합하여 coarse-to-fine segmentation을 가능하게 합니다.
- 각 단게에서는 FCN-32s, FCN-16s, FCN-8s에서 예측을 수행하는 방식을 나타내며, stride 크기에 따라 점진적으로 더 정밀한 예측을 제공합니다.
1. Pooling Layers(pool1, pool2, pool3, pool4, pool5)
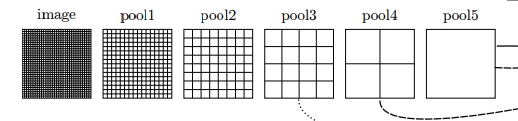
- 그림의 왼쪽 부분은 입력 이미지가 각 pooling layer를 거치면서 점점 더 coarse한 feature map으로 변환되는 과정을 보여줍니다.
- 각 pooling layer는 stride 크기에 따라 점진적으로 이미지의 해상도를 낮추며, pool5 layer까지 진행되면 가장 coarse한 해상도가 됩니다.
- 이러한 과정에서 spatial 정보가 손실되지만, 상위 layer는 고수준의 semantic 정보를 포함하게 됩니다.
2.Prediction Lyaers
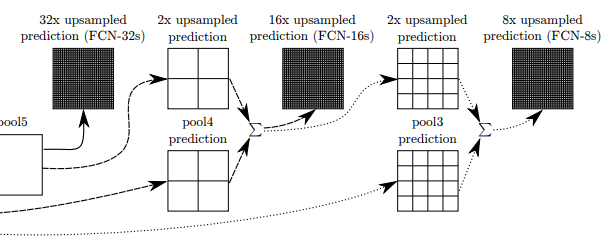
-
각 pooling layer는 prediction layer를 통해 segmentation 예측을 수행합니다.
-
이 예측은 특정 stride에서 upsampling되어 원래의 해상도에 가깝게 복원됩니다.
-
FCN-32s
- pool5 layer에서 생성된 가장 coarse한 feature map을 32배로 upsampling하여 segmentation map 생성 후 원본 해상도에 맞춰 예측을 수행합니다.
- 가장 높은 수준의 semantic 정보를 가지고 있지만, 세부적인 경계나 작은 객체의 예측이 어려울 수 있습니다.
-
FCN-16s
- pool5에서 생성된 예측 결과를 2배로 upsampling하여 pool4 layer의 feature map과 결합한 후, 16배로 다시 upsampling하여 더 정밀한 예측을 수행합니다.
-
FCN-8s
- pool4 layer에서 생성된 예측을 pool3 layer 와 결합하여 8배로 upsampling하여 최종 예측을 수행합니다.
- 이는 가장 세밀한 예측 결과를 제공합니다.
3.Upsampling 및 Skip Connections
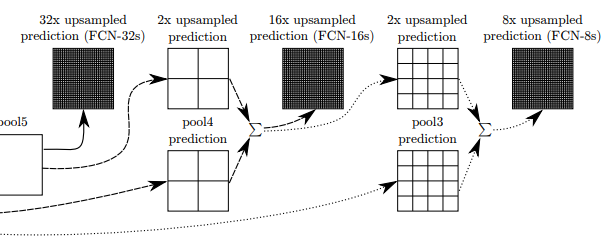
- Skip Connections
- 각 예측 단계에서는 이전 layer의 coarse한 feature map과 다음 layer의 fine 한 feature map을 결합하여 더 정확한 예측을 제공합니다.
- 이러한 skip connection은 FCN의 핵심 아이디어로, coarse-to-fine 정보를 통합하여 객체의 경계나 세부적인 부분을 더 잘 예측할 수 있게 해줍니다. - Upsampling
- 예측 결과는 각각 32배, 16배, 8배의 stride로 upsampling되어 최종 segmentation map을 생성합니다.
- 이는 deconvolution(transpose convolution)을 사용하여 이미지의 해상돌르 점진적으로 복원하는 과정입니다.
본 논문에서는 FCN 및 Skip Architecture를 사용한 모델을 제안했습니다
간단하게 정리해보겠습니다!
Fully Convolutional Network(FCN)
- 모든 layer를 convolution layer로 구성한 FCN 구조를 사용하여 end-to-end 학습을 가능하게 합니다.
- FCN은 이미지의 모든 위치에서 동시에 분류 및 분할을 수행하여 계산 효율성을 크게 향상시킬 수 있습니다.
- 전통적인 CNN의 fully connected layer를 제거하고, convolution 및 deconvolution을 통해 pixel-wise segmentation을 수행합니다.
Skip Architecture
- 다양한 해상도의 feature map을 결합하여 상세한 segmentation을 가능하게 하는 skip connection을 제안했습니다.
- FCN-32s, FCN-16s, FCN-8s 모델을 제안하여 점진적으로 더 세밀한 segmentation 결과를 얻습니다.
- 상위 feature map의 coarse 정보를 하위 feature map의 fine 정보와 결합하여 segmentation 성능을 개선합니다.
이번에는 논문에서 사용된 수식에 대해서 알아보겠습니다!
논문에서 사용된 수식
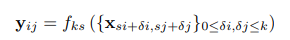
- 이 식은 convolution 연산을 설명하는 수식입니다.
- Convolution 연산은 CNN에서 중요한 역할을 하며, 입력 이미지 또는 feature map에서 local 패턴을 추출하는데 사용됩니다.

- 이 수식을 통해 pixel (i,j) 위치에서의 출력 값(yij)를 계산하는 방식이 나타나 있습니다.

- 이 수식은 convolution 연산이 입력 feature map의 작은 영역을 window(kernel)로 훑으면서 local 정보를 추출하여 출력 feature map을 생성하는 방식을 설명합니다.
- yij는 각 kxk 영역에서 계산된 특징을 나타내며, 이 과정을 반복하여 전체 이미지에 대한 feature map을 얻을 수 있습니다.
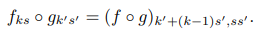
- 이 수식은 두 개의 filter f와 g를 합성하는 경우의 결과를 나타낸 것으로, 두 filter의 합성이 새로운 filter와 stride, kernel 크기에 어떤 영향을 미치는지를 설명하고 있습니다.


- 이 수식은 두 filter의 f와 g의 합성(convolution composition)을 통해 새로운 kernel 크기와 stride를 계산하는 방법을 나타냅니다.
- 이 결과는 두 개의 convolution layer를 연속으로 적용할 때, 전체 효과를 단일 필터로 표현할 경우의 kernel 크기와 stride가 어떻게 변화하는지를 설명합니다.
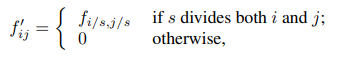
- 이 식은 filter f에 대해 stride s를 적용하여 새로운 filter f`를 정의하는 방법을 나타내고 있습니다.
- 이 과정은 convolution에서 stride를 적용할 때 filter 값이 어떻게 변하는지를 설명합니다

- 이 수식은 filter f에 stride s를 적용하는 과정을 설명합니다.
- stride는 convolution 연산에서 입력을 일정 간격 s로 건너뛰며 sampling하는 방식인데, 이 식은 filter가 stride s에 맞춰 '희소하게' sampling된 형태가 됨을 보여줍니다.
- stride s를 적용하면 filter f의 크기를 유지하면서도 실제로 계산에 참여하는 원소의 위치는 s 간격으로 떨어진 위치들만 남고, 나머지 위치는 0으로 채워집니다.
- 결과적으로 stride가 적용된 fitler f`는 원래 filter보다 희소한 형태를 가지며, 실제 연산에 참여하는 값들 사이에 0이 추가되어 sampling 밀도가 줄어듭니다.
- 이 수식은 filter에 stride를 적용할 때, stride 간격에 맞는 위치에만 값으 두고 나머지 위치는 0으로 채우는 방식으로 새로운 filter를 정의하는 방법을 설명합니다.
- 이는 convolution에서 stride 적용될 때 sampling 간격에 늘어나는 효과를 수식적으로 보여주는 것입니다.
4. 실험 검증 및 리뷰
이번에는 실험 및 결과에 대해서 알아보도록 하겠습니다!
먼저 사용된 데이터셋에 대해서 간단하게 알아보겠습니다
검증 데이터셋
- PASCAL VOC : 다양한 객체 class를 포함하는 유명한 데이터셋으로, semantic segmentation 성능을 평가하기 위해 자주 사용됩니다.
- NYUDv2 : 실내 장면의 RGB-D 데이터셋으로, 깊이 정보까지 포함되어 실내 객체 분할에 적합합니다.
- SIFT Flow : 다양한 야외 장면을 포함하는 데이터셋으로, FCN의 일반화 성능을 검증하는데 활용되었습니다.
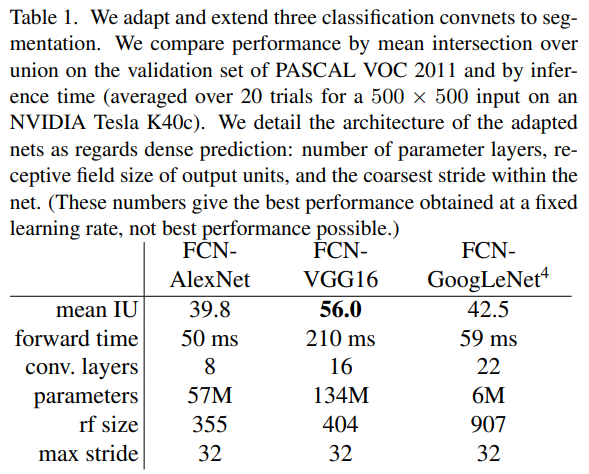
- FCN-AlexNet : AlexNet을 기반으로 FCN 구조로 변형한 모델
- FCN-VGG16 : VGG16을 기반으로 FCN 구조로 변형한 모델
- FCN-GoogLeNet : GoogLeNet을 기반으로 FCN 구조로 변형한 모델
-> 각각의 모델은 FCN 구조로 변환되며, 모든 layer가 convolution으로 대체되어 pixel-wise 예측이 가능합니다
- Mean IU : segmentation의 정확도를 나타냅니다.
- Forward Time : 모델이 한 이미지를 예측하는 데 걸리는 시간(ms 단위)
- Conv Layers : 각 모델의 convolution layer 수
- Parameters : 모델의 총 parameter 수(백만 단위)
- Receptive Field (rf) Size : 최종 출력 pixel이 입력 이미지의 몇 pixel 영역에 해당하는지 나타냅니다.(모델이 얼마나 큰 영역에서 정보를 수집하는지를 나타냅니다)
- Max Stride : 가장 큰 stride 값을 나타내며, FCN에서 stride가 클수록 output feature map의 해상도가 낮아집니다.
- 이 표는 논문에서 FCN을 세 가지 주요 CNN 모델(AlexNet, VGG16, GoogLeNet) 구조로 변형하여 semantic segmentation 성능을 비교한 결과를 보여줍니다.
- 각 모델의 성능은 PASCAL VOC 2011 데이터셋의 validation set에서 Mean Intersection over Union(mean IU)로 평가되었으며, 모델의 구조적 특징과 성능을 다양한 지표로 비교하고 있습니다.
- 이 표는 FCN을 다양한 CNN 구조로 변형했을 때의 성능 및 효율성을 비교한 결과입니다.
FCN-VGG16은 가장 높은 segmentation 성능을 보이며, GoogLeNet은 가장 작은 parameter 수로 효율적이지만 정확도는 상대적으론 낮습니다. - FCN 구조는 segmentation 성능과 모델의 효율성 간의 trade-off를 고려해야 함을 보여줍니다.

-이 그림은 FCN 논문에서 제안된 FCN-32s, FCN-16s, FCN-8s 모델이 출력한 semantic segmentation 결과와 ground truth를 비교한 것입니다.
- FCN-32s, FCN-16s, FCN-8s는 각각 다른 stride를 가지는 네트워크이며, 점진적으로 더 세밀한 segmenation 결과를 제공합니다.
- 이 그림은 FCN 모델에서 다양한 stride와 해상도 결합을 통해 segmentation의 세 밀도를 어떻게 개선한 수 있는지를 보여줍니다.
- FCN-32s는 coarse한 결과를 생성하는 반면, FCN-16s와 FCN-8s는 더 세밀한 해상도의 정보를 결합하여 segmentation 성능을 향상시킵니다.
- 특히 FCN-8s는 Ground truth에 가장 가까운 결과를 제공하여, 다중 해상도 feature map의 결합이 segmentation 성능 향상에 효과적임을 시각적으로 보여줍니다.
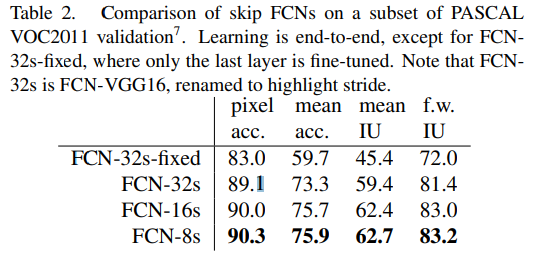
- pixel accuracy : 전체 pixel 중에서 올바르게 예측된 pixel의 비율입니다.
- Mean Accuracy : 각 클래스별 정확도를 평균한 값으로, 클래스 간 정확도의 균형을 나타냅니다.
- Mean Intersection over Union(mean IU) : 각 클래스에 대해 Intersection over Unio(IoU)를 계산하고, 이를 평균한 값입니다.
- Frequency Weighted Intersection over Union(f.w. IU) : 클래스의 빈도에 가중치를 두어 IoU를 계산한 값으로, 각 클래스의 빈도에 따라 결과가 영향을 받습니다.
-이 표는 FCN(Fully Convolutional Network) 모델의 성능을 비교한 것으로, PASCAL VOC2011 validation set에서 다양한 FCN 변형 모델의 성능을 보여줍니다.
- 각 모델은 FCN-32s, FCN-16s, FCN-8s로, 다중 해상도의 feature map을 결합하여 segmentation 성능을 향상시키는 skip architecture를 사용했습니다.
또한 FCN-32s 모델의 고정된 버전(Fixed)도 포함되어 있습니다. - 이 표는 FCN 모델에서 stride가 줄어들수록, 즉 더 세밀한 해상도의 feature map을 결합할수록 성능이 향상됨을 보여줍니다.
- FCN-8s 모델이 가장 높은 정확도와 IoU를 기록하여 Segmentation 성능이 가장 우수하다는 것을 입증하였으며, skip connection을 통한 다중 해상도 feature map 결합이 FCN의 성능을 크게 개선하는 것을 나타냅니다.
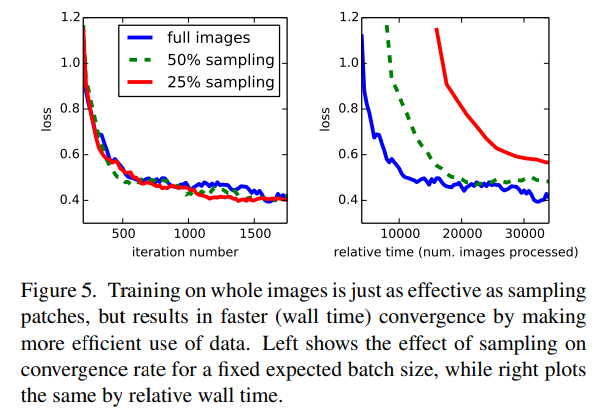
- 파란색 : 전체 이미지를 사용한 학습
- 녹색 : 이미지의 50%만 sampling하여 사용한 학습
- 빨간색 : 이미지의 25%만 sampling하여 사용한 학습
-이 그림은 FCN에서 전체 이미지로 학습하는 것과 부분 이미지를 sampling하여 학습하는 방법을 비교한 실험 결과를 나타냅니다.
- 학습 속도와 손실 함수의 수렴 속도를 비교하기 위해 전체 이미지, 50% 샘플링, 25% 샘플링의 세 가지 방식을 사용했습니다.
- 전체 이미지 학습이 효과적 : iteration 기준으로는 sampling과 큰 차이가 없지만, wall time 기준으로는 전체 이미지를 학습에 사용하는 것이 더 빠르게 수렴하여 효율적입니다.
- 데이터 활용 효율성 : sampling보다 전체 이미지를 사용하는 것이 데이터 활용면에서 효율적이며, 빠른 손실 감소와 수렴을 제공합니다.
- 이 결과는 FCN 모델이 전체 이미지를 학습하는 것이 더 나은 수렴 속도와 효율성을 제공한다는 점을 강조하고 있습니다.

-이 표는 FCN-8s 모델이 PASCAL VOC 2011 및 2012 test set에서 다른 모델과의 성능과 추론 시간(inference time)을 비교한 결과를 보여줍니다.
- 성능 향상
- FCN-8s 모델은 R-CNN과 SDS에 비해 PASCAL VOC 2011 및 2012 데이터셋에서 약 20%의 성능 향상을 보였습니다.- 이는 mean IU 기준으로 가장 우수한 성능입니다.
- 추론 시간 효율성
- FCN-8s는 약 175ms의 추론 시간으로, SDS보다 훨씬 빠르며 실시간 응용에 적합합니다.- FCN의 end-to-end 구조와 fully convolutional 설계 덕분에 높은 성능과 빠른 추론 속도를 동시에 달성할 수 있습니다.
- 이 표는 FCN-8s가 이전의 state-of-the-art 모델에 비해 정확도와 추론 시간에서 모두 우수함을 보여줍니다.
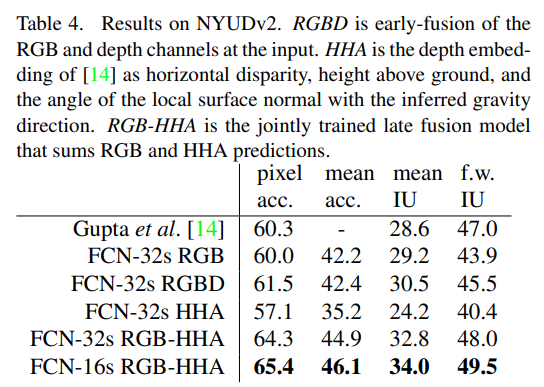
- RGB : 컬러 이미지의 Red, Green, Blue 채널
- RGBD : RGB와 depth 채널을 초기 단계에서 결합한 형태로, 입력에 RGB와 depth 정보를 동시에 사용합니다.
- HHA : depth 정보를 3개의 임베딩으로 변환한 것으로, 수평 불일치(horizontal disparity), 지면 위 높이(height above ground), 중력 방향에 대한 표면 법선의 각도(angle of the local surface normal)를 포함합니다.(depth 정보를 보다 풍부하게 표현 가능함)
- RGB-HHA : RGB와 HHA 정보를 late fution 방식으로 결합한 형태로, RGB와 HHA 각각에 대해 별도로 예측한 후 결과를 합산하여 최종 예측을 수행합니다.
-이 표는 FCN 모델이 NYUDv2 데이터셋에서 다양한 입력 방식(RGB, RGBD, HHA, RGB-HHA)을 사용하여 semantic segmentation 성능을 비교한 결과를 보여줍니다.
- NYUDv2 데이터셋은 실내 장면의 RGB-D 데이터를 포함하며, RGB와 depth 정보를 결합하여 segmentation 성능을 높일 수 있는 데이터셋입니다.
- RGB-HHA 조합의 효과
- RGB와 HHA를 함께 사용하는 모델이 성능이 가장 높아, depth 정보를 변환한 HHA가 RGB 정보와 함께 사용될 때 segmentation 성능을 향상시킴을 보여줍니다. - FCN-16s의 우수성
- 더 작은 stride를 사용한 FCN-16s 구조가 FCN-32s에 비해 더욱 정밀한 segmentation을 가능하게 하여, 최종 성능을 개선했습니다. - 이 표는 FCN 모델이 다양한 입력 조합을 통해 실내 장면에서의 semantic segmentation 성능을 개선할 수 있음을 보여주며, 특히 RGB와 HHA의 결합이 효과적임을 입증합니다.
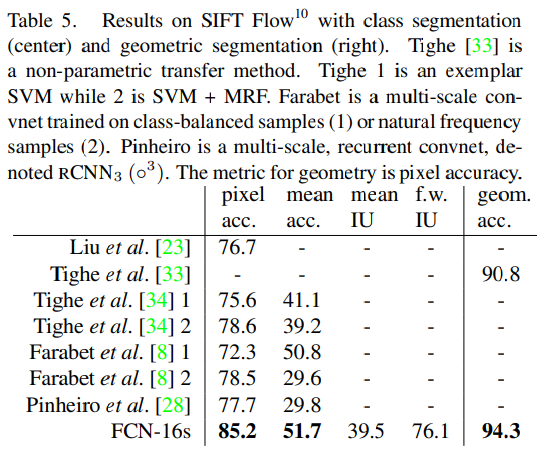
- pixel accuracy : 이미지 내에서 정확하게 예측된 pixel의 비율을 나타냅니다.
- mean accuracy : 클래스별 정확도의 평균을 나타냅니다.
- mean IU : 각 클래스에 대해 IoU 계산 후, 이를 평균한 값입니다.
- frequency weighted IU : 각 클래스의 빈도를 고려한 IoU의 가중 평균입니다.
- geometry accuracy : geometry 정보의 정확도를 평가하는 지표입니다(기하학적 특성을 예측하는 정확도를 평가합니다.)
-이 표는 SIFT Flow 데이터셋에서 다양한 모델이 수행한 class segmentation과 geometric segmentation의 성능을 비교한 결과를 보여줍니다.
-
각 모델은 SIFT Flow 데이터셋에서 클래스별 segmentation과 geometry segmentation을 수행했으며, pixel accuracy, mean accuracy, mean IU, frequency weighted IU, geometry acuracy 등의 지표로 성느을 평가했습니다.
-
FCN-16s의 우수한 성능
- FCN-16s 모델이 class segmentaiton과 geometry segmentation에서 기존 모델보다 높은 정확도를 기록했습니다.- 특히 geometry accuracy에서 94.3%로 최고의 성느을 보였으며, 이는 FCN 모델이 복잡한 geometry 정보를 효과적으로 학습할 수 있음을 의미합니다.
-
다양한 성능 지표
- 이 표는 각 모델의 pixel accuracy, mean IU 등 다양한 성능 지표를 제공하여 모델 간 성능을 다각도로 비교할 수 있게 합니다.- FCN-16s가 모든 성능 지표에서 전반적으로 우수한 결과를 보였습니다.
-
이 표는 FCN-16s가 SIFT Flow 데이터셋에서 다른 모델에 비해 전반적으로 우수한 성능을 보인다는 것을 입증하며, 특히 geometry segmentation에서 매우 강력한 성능을 보여줍니다.

-이 그림은 PASCAL 데이터셋에서 FCN-8s 모델과 기존 state-of-the-art 모델인 SDS의 segmentation 성능을 비교한 결과입니다.
- 각 행은 특정 상황에서 두 모델이 예측한 segmentation 결과와 해당 이미지의 ground truth를 비교하여 모델의 성능을 시각적으로 보여줍니다.
- FCN-8s의 강점
- FCN-8s는 SDS 모델보다 더 정밀한 객체 경계를 예측하며, 인접한 객체를 구분하는 성능이 뛰어납니다.- 또한, 일부 객체가 가려진 상황에서도 비교적 정확하게 예측을 수행할 수 있습니다.
- 한계점
- 복잡한 객체 간 상호작용이나 가려짐이 심한 경우에는 여전히 완벽한 예측을 수행하지 못하는 한계가 있습니다. - 이 그림은 FCN-8s가 기존 모델인 SDS에 비해 더 우수한 성능을 발휘하지만, 여전히 몇 가지 한계가 존재함을 시각적으로 보여줍니다.
지금까지 본 실험 결과를 간단하게 요약해보겠습니다!
성능 결과
- FCN-32s, FCN-16s, FCN-8s 모델 성능 비교
- FCN-32s는 가장 coarse한 segmentation map을 제공했지만, FCN-16s와 FCN-8s는 skip connection을 통해 더 세밀한 segmentation 성능을 보였습니다.- 특히 FCN-8s는 가장 높은 pixel 정확도와 IoU(Interesction over Union) 점수를 기록했습니다.
- 객체 경계 정확성 향상
- FCN은 전통적인 patch 기반 접근법에 비해 객체 경계를 더 정확히 예측할 수 있었으며, 이는 다양한 해상동의 정보를 결합한 skip connection 덕분에 가능했습니다.
이러한 실험을 통해 얻을 수 있는 실험적 의의에 대해 알아보도록 하겠습니다
실험적 의의
- End-to-End 학습의 우수성
- FCN의 end-to-end 학습 구조가 semantic segmentation 문제를 해결하는 데 효과적임을 입증했습니다. - Skip connection의 효과
- 다양한 해상도를 결합하여 coarse-to-fine segmentation이 가능하다는 점에서 skip connection의 중요성을 입증했습니다.
5. 결론 및 한계
마지막으로 Fully Convolutional Network의 결론과 한계점에 대해서 알아보고 마치겠습니다!
1. 결론
- Fully Convolutional Network(FCN)는 patch 기반 segmentation 방법의 한계를 극복하고, end-to-end 학습을 통해 효율적이고 정확한 semantic segmentation을 가능하게 합니다.
- Skip architecture의 효과를 통해 segmentation의 세밀도와 정확성을 향상시키고, 다양한 데이터셋에서 높은 성능을 입증하여 FCN의 유용성을 증명했습니다.
2. 한계
- 작은 객체 및 복잡한 경계 처리의 한계
- FCN은 물체의 복잡한 경계를 세밀하게 구분하는 데 한계가 존재하며, 이로 인해 작은 객체나 복잡한 배경에서 성능 저하를 보입니다.
- 계산 비용
- 모델의 크기와 계산량이 상당하여 실제 어플리케이션에서 실시간 처리에 제한적일 수 있습니다.
이러한 FCN을 통해 Convolutional Neural Network가 단순 분류가 아닌, pixel 단위의 예측에까지 확장이 가능하다는 점에서 의미 있는 연구라고 할 수 있습니다.
FCN의 skip architecture는 다양한 해상도의 정보를 결합해 더 세밀한 segmentation을 가능하게 하며, 이후 semantic segmentation 연구의 기반을 마련했다고 볼 수 있습니다
