
2. 데이터프레임 다루기(기초)
2.1 데이터프레임 생성하기
데이터 프레임 생성 코드
- pandas.DataFrame()은 판다스(Pandas) 라이브러리에서 사용되는 데이터 프레임을 생성하는 함수
- data: 데이터 프레임에 포함될 데이터.
- index: 행 인덱스를 지정
- columns: 열 이름을 지정
- dtype: 열별로 데이터 유형을 지정할 수 있는 매개변수
- copy: 데이터를 복사할지 여부를 지정
**판다스를 사용하기 전엔 항상
import pandas as pd까먹지 말기 **
5가지에 대한 예시 코드
import pandas as pd # 항상 까먹지말고!
# 데이터: 리스트, 딕셔너리, 넘파이 배열, 행 인덱스/열 이름, 데이터 유형 을 이용해서 만들수 있음.
data = [[1, 'Alice'],
[2, 'Bob'],
[3, 'Charlie']]
df_data = pd.DataFrame(data, columns=['ID', 'Name'])
print(df_data)
# 인덱스: 행 인덱스 설정
df_index = pd.DataFrame(data, columns=['ID', 'Name'], index=['Row1', 'Row2', 'Row3'])
print(df_index)
# 컬럼: 열 이름 설정
df_columns = pd.DataFrame(data, columns=['ID', 'Full Name'])
print(df_columns)
# 복사: 데이터 복사 여부 설정
data_copy = [[1, 'Alice'],
[2, 'Bob'],
[3, 'Charlie']]
df_copy = pd.DataFrame(data_copy, columns=['ID', 'Name'], copy=True)

직접 데이터프레임 작성
menu_df = pd.DataFrame(np.array([[101, 'Burger', 8.99],
[102, 'Pizza', 10.99],
[103, 'Pasta', 12.49],
[104, 'Salad', 6.99]])
, index = ['Item1', 'Item2', 'Item3', 'Item4'],
columns = ['ItemID', 'ItemName', 'Price'])
print(menu_df)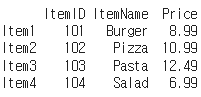
2D 어레이를 데이터프레임으로 변환
# 음식점 메뉴판 2차원 넘파이 배열 생성
menu_2darray = np.array([[101, 'Burger', 8.99],
[102, 'Pizza', 10.99],
[103, 'Pasta', 12.49],
[104, 'Salad', 6.99]])
# 데이터프레임 생성
menu_df = pd.DataFrame(menu_2darray)
# 열 이름 설정
menu_df.columns = ['ItemID', 'ItemName', 'Price']
# 데이터프레임 출력
print(menu_df)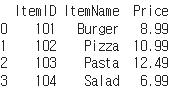
dictionary를 데이터프레임으로 변환
# 음식점 메뉴판을 나타내는 딕셔너리 생성
menu_dict = {
'ItemID': ['101', '102', '103'],
'ItemName': ['Burger', 'Pizza', 'Pasta'],
'Price': ['8.99', '10.99', '12.49']
}
# 데이터프레임 생성
menu_df = pd.DataFrame(menu_dict)
# 데이터프레임 출력
print(menu_df)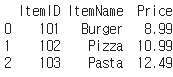
Series를 데이터프레임으로 변환
# 음식 레시피를 나타내는 판다스 Series 생성
recipe_series = pd.Series({
'Pasta Carbonara': 'Italian',
'Sushi Rolls': 'Japanese',
'Taco Salad': 'Mexican',
'Chicken Curry': 'Indian'
})
# 데이터프레임 생성
recipe_df = pd.DataFrame(recipe_series, columns=['Cuisine'])
# 데이터프레임 출력
print(recipe_df)
외부 파일로 부터 불러오기
# 음식점 메뉴 데이터가 들어있는 CSV 파일 읽어오기
restaurant_data = pd.read_csv('restaurant_menu.csv', sep=',') # 파일 경로와 구분자 설정
# 처음 3개의 행 출력
print(restaurant_data.head(3))
# df.head(x) 데이터프레임에서 처음 x 개의 행을 반환하는 함수.
데이터프레임의 시작 부분에 있는 데이터 일부를 쉽게 확인
2.2 데이터프레임 살펴보기
메타데이터 확인하기
info() 간단한 정보 제공
-데이터프레임의 크기 (행 수와 열 수).
-각 열 (컬럼)의 이름과 데이터 타입.
-비어 있지 않은 데이터 (non-null)의 개수.
-각 열의 메모리 사용량 (대략적인 값).
menu_df = pd.DataFrame(np.array([[101, 'Burger', 8.99],
[102, 'Pizza', 10.99],
[103, 'Pasta', 12.49],
[104, 'Salad', 6.99]])
, index = ['Item1', 'Item2', 'Item3', 'Item4'],
columns = ['ItemID', 'ItemName', 'Price'])
menu_df.info()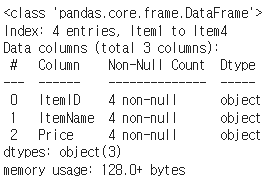
데이터 출력 제한걸기
- pd.options.display.max_rows: 이 옵션은 데이터프레임에서 최대로 표시되는 행의 수를 설정
pd.options.display.max_rows = 20ex) 데이터프레임의 첫 20개 행만 화면에 표시
- pd.set_option('display.min_rows', ...): 이 옵션은 최소로 표시되는 행의 수를 설정
d.set_option('display.min_rows', 5)
ex) 최소한 5개의 행은 항상 표시
- iloc는 인덱스 위치를 기반으로 데이터를 선택하는 메서드
dataframe.iloc[행_위치, 열_위치]
ex) dataframe.iloc[0, 1]은 첫 번째 행과 두 번째 열의 위치에 있는 데이터를 선택
데이터프레임의 형태 확인
- print(
x.shape): 데이터프레임의 크기를 확인
- 데이터프레임의 행과 열의 수를 튜플로 반환 - print(len(
x.index)): 이 코드는 데이터프레임의 인덱스(행)의 개수를 확인
- 데이터프레임의 행의 수를 반환
데이터프레임 데이터 확인하기 (출력)
- print(
x): x를 일반적인 텍스트 형식으로 표시 - display(
x): 데이터프레임을 더 직관적으로 볼 수 있으며 표의 정렬, 스크롤, 필터링 등과 같은 추가 기능을 사용 가능
menu_df = pd.DataFrame(np.array([[101, 'Burger', 8.99],
[102, 'Pizza', 10.99],
[103, 'Pasta', 12.49],
[104, 'Salad', 6.99]])
, index = ['Item1', 'Item2', 'Item3', 'Item4'],
columns = ['ItemID', 'ItemName', 'Price'])
display(menu_df)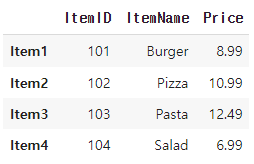
2.3 데이터 추가와 삭제
# 음식점 메뉴판 데이터프레임 생성
menu_df = pd.DataFrame({'ItemID': [101, 102, 103],
'ItemName': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49]},
index=['Item1', 'Item2', 'Item3'])
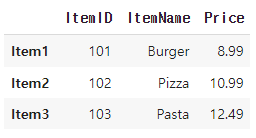
이 데이터 베이스를 기준으로 생각
행 추가
menu_df.loc['Item4'] = [104, 'Salad', 6.99]
menu_df.loc['Item5'] = [105, 'Sushi', 14.99]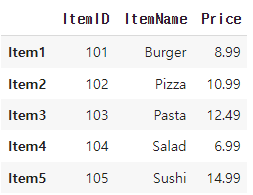
dataframe.loc[행라벨, 열라벨]
-하나의 행과 하나의 열을 선택하는 데 사용
-여러 행 또는 여러 열을 선택하는 데 사용
-조건을 만족하는 행을 선택하는 데 사용
열 추가
2가지 방법이 있음!
위의 loc 메서드를 사용하는 것과 그냥 열을 추가할수 있음
menu_df.loc[:, 'Category'] = ['Fast Food', 'Italian', 'Italian']menu_df['Category'] = ['Fast Food', 'Italian', 'Italian']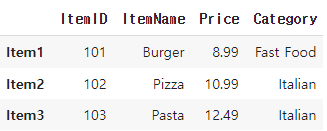
열 삭제
위의 만들어진 열을 다시 삭제하려면
menu_df.drop('Category', axis=1, inplace=True)drop 메서드를 사용하여 'Category' 열을 삭제
axis=1은 열을 나타내고,
inplace=True는 삭제 후 데이터프레임을 변경된 상태로 유지
행 삭제
만약위에 아이템 4와 5를 추가한 상태에서 다시 4와 5를 삭제하고 싶다면!
menu_df.drop(['Item4', 'Item5'], axis=0, inplace=True)drop 메서드를 사용하여 'Item4'와 'Item5'라는 행을 삭제
axis=0은 행을 나타내고,
inplace=True는 삭제 후 데이터프레임을 변경된 상태로 유지
2.4 인덱싱과 슬라이싱
인덱싱과 슬라이싱은 데이터를 접근하고 추출하는 기술
1. 인덱싱 : 데이터 타입에서 개별 항목을 선택하는 과정
2. 슬라이싱 : 작 인덱스와 끝 인덱스를 지정하여, 데이터의 일부를 추출하는 과정
열선택
df[‘colname’], df.colname, df[[‘colname1’,‘colname2’,‘colname3’]]
열을 선택하는 방법
df[‘colname’], df.colname 의 경우에는 시리즈(1차원배열) 형태로 반환
df[[‘colname1’,‘colname2’,‘colname3’]]의 경우에는 데이터프레임형태로 반환하게된다
item_name_column = menu_df['ItemName']
item_prices = menu_df.Price
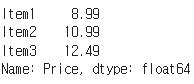
selected_columns = menu_df[['ItemName', 'Price']]
display(selected_columns)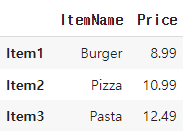
인덱스 선택
df.loc[]는 데이터프레임에서 특정 행 또는 열을 선택하는 데 사용되는 메서드
df.loc[], df.loc[[]], df.loc[:], df.loc[:,:]
- df.loc['label'] : 데이터프레임에서 특정 레이블(label)을 가진 행을 선택 / 시리즈 반환
selected_menu = menu_df.loc['Item2']
- df.loc[['label1', 'label2']] : 여러 메뉴 항목을 한 번에 선택 /데이터프레임 반환
selected_menus = menu_df.loc[['Item1', 'Item3']]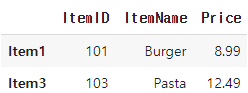
- df.loc[:] 예시: 모든 메뉴 항목을 선택
all_menus = menu_df.loc[:]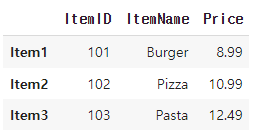
- df.loc[:, 'colname'] / df.loc[:, ['colname1', 'colname2']] : 특정 열 또는 여러 열을 선택
-위의 시리얼, 데이터프레임 반환을 선택해서 열을 선택할 수 있음
selected_price = menu_df.loc['Item2', 'Price']
selected_data = menu_df.loc[['Item1', 'Item3'], ['ItemName', 'Price']]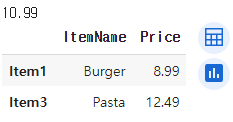
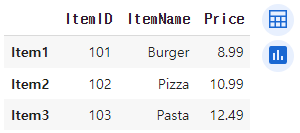
- df.loc['label', 'colname'] / df.loc[['label1', 'label2'], ['colname1', 'colname2']] : 특정 행과 열을 교차로 선택
selected_price = menu_df.loc['Item2', 'Price']
selected_data = menu_df.loc[['Item1', 'Item3'], ['ItemName', 'Price']]
절대 위치 선택
df.iloc[], df.iloc[[]], df.iloc[:], df.iloc[:,:]
위의 loc과 같은 방법으로 사용되지만
iloc은 정수 위치 기반으로 데이터를 선택
loc은 레이블 기반으로 데이터를 선택한다.
즉,
iloc은 행과 열의 위치
loc은 행과 열의 이름으로
데이터를 선택하는 메서드이다. (슬라이싱)
2.5 탐색하여 슬라이싱
위의 방법이 아닌 데이터프레임 코드의 변수를 통해서도 가능
menu_df = pd.DataFrame({'ItemID': [101, 102, 103],
'ItemName': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49]},
index=['Item1', 'Item2', 'Item3'])
display(menu_df[menu_df['Price'] < 30])
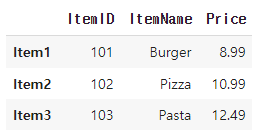
->'Price' 열의 값이 30 미만인 메뉴 선택
menu_df.loc[lambda x: x['Price'] < 30]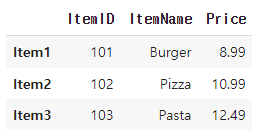
-> 여기서 람다함수는 함수를 만드는 방법중 하나, 선택조건을 정의하고 loc 메서드에게 전달한 것
display(menu_df.loc[menu_df['Price'] < 30, ['A', 'B']])
-> 'Price' 열의 값이 30 미만인 행 중 'ItemID'와 'ItemName' 열 선택
