3. 데이터프레임 다루기(중급)
3.1 데이터프레임 클래스
- Python의 모든 자료구조는 클래스(class)
- 클래스는 객체로서 변수와 메소드(함수)의 집합체. 따라서 데이터프레임 객체의 변수와 메소드는 직접 사용이 가능
클래스 : 객체의 설계도 -> 객체의 특성(attribute)과 동작(method)을 정의
인스턴스 : 실제로 그 설계도를 바탕으로 만들어진 객체
-> 클래스로부터 여러 개의 인스턴스를 생성할 수 있으며, 각 인스턴스는 클래스에서 정의된 속성과 동작을 공유하지만 그 값과 상태는 각각 다름
print(dir(menu_df)[:20])
데이터프레임 객체에서 사용할 수 있는 메서드와 속성을 나열하고, 처음 20개만 출력
-> dir() 함수는 파이썬에서 사용 가능한 객체(모듈, 클래스, 인스턴스 등)의 속성(attribute)과 메서드(method)를 나열하는 함수
-> dir() 함수는 주로 디버깅이나 객체의 사용 가능한 속성 및 메서드를 조사할 때 활용
3.2 데이터프레임 변수
데이터프레임의 열
display(menu_df.ItemName)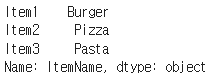
데이터프레임에서 특정 열(column)을 선택하여 출력하는 예시
-> 'ItemName' 열을 선택하여 해당 열의 데이터를 출력, 열 이름을 점(.)을 사용하여 선택할 수 있으며, 선택된 열은 시리즈(Series)로 표시
데이터프레임의 T(transpose, 전치행렬)
전치행렬(Transpose Matrix)은 행렬의 행과 열을 서로 바꾼 행렬을 의미
display(menu_df.T)
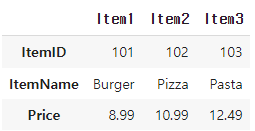
아래가 .T의 결과
3.3 사칙연산
menu_df1 = pd.DataFrame({'MenuID': [101, 102, 103],
'ItemName': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49]},
index=['Item1', 'Item2', 'Item3'])
# 다른 음식점 메뉴 데이터프레임 생성 (df2)
menu_df2 = pd.DataFrame({'MenuID': [101, 102, 104],
'ItemName': ['Burger', 'Pizza', 'Salad'],
'Price': [8.99, 10.99, 6.99]},
index=['Item1', 'Item2', 'Item4'])
이렇게 각각의 메뉴판이 존재할때,
print(menu_df1+menu_df2) 가격 정보가 매칭된 항목에서 합산되고, 일치하지 않는 항목은 NaN으로 표시
-> 'Burger'와 'Pizza' 메뉴는 두 데이터프레임 모두에 있으며, 가격이 더해짐짐
-> 'Pasta'는 df1에만 있고 'Salad'은 df2에만 있으므로 이 두 항목은 NaN으로 표시
fill_value는 두 데이터프레임을 연산할 때 일치하지 않는 항목을 대체하는 값을 설정하는 매개변수
더하기의 경우에는 fill_value= 0
곱하기의 경우에는 fill_value= 1
결과는 아래 확인
다른 예시로 설명을 들면
df1 = pd.DataFrame({'A':[11,21,31], 'B':[12,22,32], 'C':[13,23,33]}
, index=['1st','2nd','3rd'])
df2 = pd.DataFrame({'A':[11,21,41], 'B':[12,22,42], 'E':[14,24,44]}
, index=['1st','2nd','4th'])
print(df1+df2) # 각 원소별 매칭되는 것만 더하기
print(df1.add(df2, fill_value=0)) # 값이 없는 것은 0으로 대체하여 각 원소별 더하기
print(df1.mul(df2, fill_value=1)) # 값이 없는 것은 1로 대체하여 각 원소별 곱하기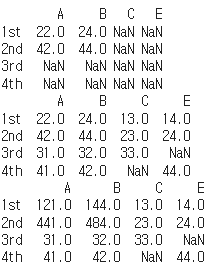
이와 같은 결과가 나올 수 있음
3.4 Assign
assign 메서드는 Pandas 데이터프레임에 새로운 컬럼을 추가하거나 기존 컬럼을 변경하는 데 사용되는 메서드
order_df = pd.DataFrame({'Item': ['Burger', 'Pizza', 'Pasta'],
'Quantity': [2, 3, 1],
'Price': [8.99, 10.99, 12.49]})
display(order_df.assign(A_plus_B=order_df['Quantity'] * order_df['Price'])
)
display(order_df.assign(log_A=lambda x: pd.Series(x['Price']).apply(lambda y: np.log(y)))
)음식점 관련 예시를 계속 해서 들고 있어서,
식자체의 의미는 많이 떨어지지만
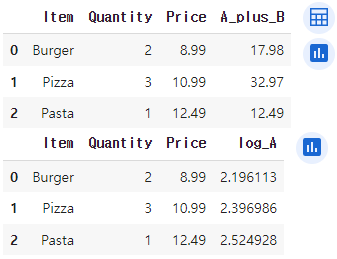
다음과 같은 결과를 보여줌
assign 메서드를 사용하여 'A_plus_B' 컬럼에 주문 수량과 가격을 곱한 값을 저장하고, 'log_A' 컬럼에 'Price' 컬럼의 로그 값을 저장
3.5 열 수정
menu_df = pd.DataFrame({'Menu': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49]},
index=['Item1', 'Item2', 'Item3'])
menu_df.insert(loc=0, column='D', value=[14, 24, 34])
menu_df.insert(loc=2, column='E', value=5)
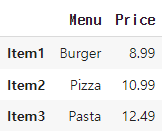
이와 같은 데이터에서
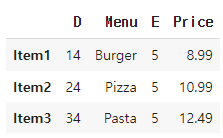
이렇게 바뀌게 됨
->
insert 메서드를 사용하여 'D' 열과 'E' 열을 데이터프레임에 추가 'D' 열은 0번 인덱스 위치에 [14, 24, 34]라는 값으로 추가
'E' 열은 2번 인덱스 위치에 모든 행에 값 5로 추가
menu_df = pd.DataFrame({'Menu': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49],
'D': [14, 24, 34],
'E': [5, 5, 5]},
index=['Item1', 'Item2', 'Item3'])
menu_df = menu_df.drop(columns=['D', 'E'])
menu_df = menu_df.rename(columns={'Menu': 'ItemName', 'Price': 'ItemPrice'})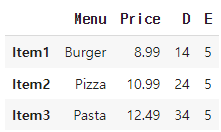
이와 같은 데이터에서
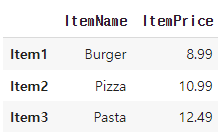
이렇게 바뀜
-> drop 메서드를 사용하여 'D'와 'E' 열을 삭제
rename 메서드를 사용하여 'Menu' 열의 이름을 'ItemName'으로, 'Price' 열의 이름을 'ItemPrice'로 변경
3.6 값 수정
menu_df = pd.DataFrame({'Menu': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49]},
index=['Item1', 'Item2', 'Item3'])
menu_df['Item2', 'Price'] = 201다음과 같이 코드를 작성시 특정 셀에 값을 할당할 때에는 df.loc[row, column] 형식을 사용하여 특정 행(row)과 열(column)을 지정한 후 값을 할당해야함
따라서
menu_df.loc['Item2', 'Price'] = 201이렇게 코드를 바꾸면
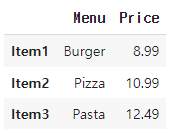
의 코드가 아래와 같이 변경됨
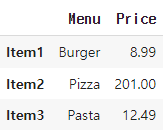
loc이 아닌 iloc을 사용한다면
menu_df.iloc[:, 1] = 'NA'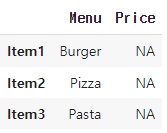
와 같은 결과가 나오게 됨
위의 결과에서
menu_df2 = menu_df.replace('NA', 1000)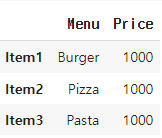
->replace 메서드를 사용하여 데이터프레임 내의 모든 'NA' 값을 1000으로 변경
-> 만약 'NA' 자리에 특정 열의 특정 값을 지정하고 싶다면 '특정열':특정값 형태로 넣어주면 됨
3.7 데이터 정렬
정렬
- df.sort_values(by='A', ascending=False): 데이터프레임을 'A' 열의 값에 따라 내림차순(큰 값부터 작은 값 순서)으로 정렬
- df.sort_index(axis=0): 데이터프레임의 행 인덱스를 기준으로 오름차순으로 정렬, axis=0은 행 인덱스를 기준으로 정렬하라는 의미
-> 여기서 ascending=TRUE 가 default 값
그래서 1번은 열이 내림차순 2번은 행이 오름차순 이 된 것
랭크
data = {'A': [10, 20, 30],
'B': [25, 15, 35],
'C': [15, 10, 20]}
df = pd.DataFrame(data)
df_rank = df.rank(axis=0, method='average', ascending=False)
print("원본 데이터프레임:")
print(df)
print("\n순위가 부여된 데이터프레임:")
print(df_rank)

- df.rank(axis=0, method='average', ascending=False): rank 메서드를 사용하여 데이터프레임의 열을 기준으로 순위를 정함
axis=0은 열을 기준으로 순위를 매기라는 의미
method='average'는 동일한 값이 있을 때 평균 순위를 부여
ascending=False는 내림차순으로 순위를 부여
3.8 Melt
'melt'하면 열(column)을 행(row)으로 변환
df = pd.DataFrame({'order': ['1st','2nd','3rd'],'A':[11,21,31], 'B':[12,22,32], 'C':[33,32,31]})
display(df)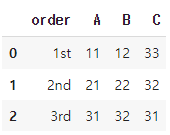
여기에서
df_melted = pd.melt(df, id_vars=['order'], value_vars=['A','B','C'], var_name='name', value_name='score')
다음과 같은 코드를 사용한다면,
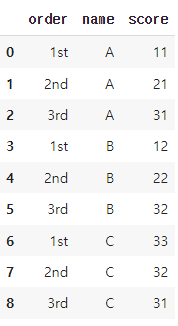
- id_vars=['order']: 'order' 열을 기준으로 유지하고 싶다는 의미
- value_vars=['A','B','C']: 'A', 'B', 'C' 열을 'melt'할 열로 지정
- var_name='name': 'name' 열의 이름을 변경
- value_name='score': 'score' 열의 이름을 변경
3.9 통계 처리
data = {'Order': ['1st', '2nd', '3rd'],
'A': [11, 21, 31],
'B': [12, 22, 32],
'C': [33, 32, 31]}
df = pd.DataFrame(data)
print(df.mean(axis=1)) #평균
print(df.max(axis=0)) #최대값
print(df.var(axis=1, ddof=1)) #분산 ddof=1: 표본 자유도 반영
print(df.corr()) #상관계수
print(df.describe()) #기술 통계량
print(df.sample(n=2)) #샘플링->무작위 행2개 출력
print(df.sample(frac=0.5)) # 전체 행중 50프로 무작위 출력
다음과 같은 형태로 다양한 통계 값들을 계산 할 수 있다.
-> 최근 파이썬 부터는 수치형이 아닌경우엔 오류가 발생 참고!
3.10 데이터 정제
df = pd.DataFrame({'A':[11,21,31,None,31], 'B':[12,22,32,42,32], 'C':[13,None,33,43,33]}
, index=['1st','2nd','3rd','4th','7th'])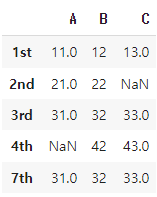
위와 같은 데이터 형태에서
중복 데이터 제거
print(df.drop_duplicates())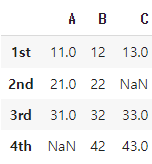
df 데이터프레임에서 중복된 행을 제거할 수 있다.
결측치 행 제거
df.dropna()를 사용하면 결측값이 있는 행을 제거한 결과를 얻을 수 있음
df.dropna(axis=0)와 동일한 결과
df.dropna(axis=1)을 사용하면 결측값이 있는 열을 제거
print(df.dropna())
print(df.dropna(axis=1))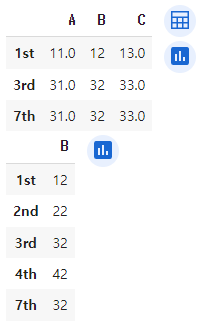
각각의 코드를 사용하면 다음과 같은 결과를 얻을 수 있음
결측치 대체
- df.fillna(특정값): 결측값을 지정된 특정값으로 채움
- df.fillna(method='ffill') / df.fillna(method='pad'): 결측값을 해당 열의 이전 행의 값으로 채움, 이전 행에 값이 없으면 결측값이 그대로
- df.fillna(method='bfill') / df.fillna(method='backfill'): 결측값을 해당 열의 다음 행의 값으로 채움, 다음 행에 값이 없으면 결측값이 그대로
- df.fillna(df.mean()): 결측값을 해당 열의 평균 값으로 채움
df = pd.DataFrame({'A':[11,21,31,None,31], 'B':[12,22,32,42,32], 'C':[13,None,33,43,33]}
, index=['1st','2nd','3rd','4th','7th'])
display(df)
display(df.fillna(100))
display(df.fillna(axis=1, method='bfill'))
display(df.fillna(axis=1, method='ffill'))
display(df.fillna(df.mean()))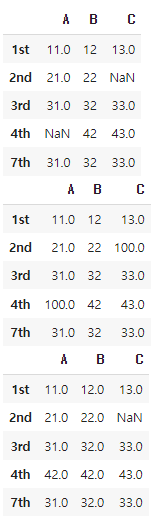
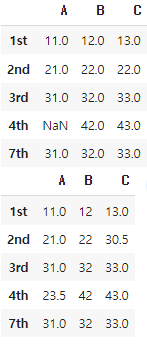
다음과 결과를 얻을 수 있다.!
3.11 Filter
슬라이싱과 헷깔릴 수 있음
필터링은 행을 선택하는 작업이며, 슬라이싱은 열을 선택하는 작업
필터링은 조건을 사용하여 데이터를 선택하고, 슬라이싱은 열의 이름 또는 위치를 사용하여 데이터를 추출
df = pd.DataFrame({'abc':[1,4,7], 'bcd':[2,5,8], 'abd':[3,6,9]}, index=['1st','2nd','3rd'])
print(df)
print(df.filter(items=['abc', 'abd']))
print(df.filter(regex='^ab', axis=1)) # 열이름이 ab로 시작하는 열 선택
print(df.filter(like='d', axis=0)) # 인덱스명에 d가 포함된 행 선택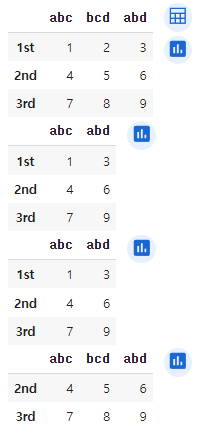
-> regex : 문자열 패턴을 정의하고 일치하는 문자열을 검색하거나 변형하는 데 사용
3.12 Query
조건에 부합하는 데이터를 추출할 때 가장 많이 사용
.loc[ ] 로 구현한 것보다 속도가 느림
-query는 sql 스타일, loc은 행과 열을 지정하여 인덱싱
data = {'Name': ['Burger', 'Pizza', 'Pasta'],
'Price': [8.99, 10.99, 12.49],
'Rating': [4.5, 4.2, 4.8]}
menu_df = pd.DataFrame(data, index=['Item1', 'Item2', 'Item3'])
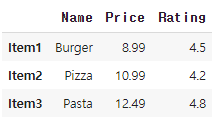
다음과 같이 메뉴판이 존재할때
price에서 가격이 11보다 큰 항목을 검색하려면:
result1 = menu_df.query('Price > 11')
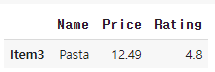
price가 11보다 크고 rating 이 4.5보다 작은 항목을 검색하려면:
result2 = menu_df.query('(Price > 11) & (Rating < 4.5)')
결과는 없다는 것을 확인
abd_max = 4.5
result3 = menu_df.query('(Price > 11) & (Rating < @abd_max)')
다음과 같이 외부 값을 참조해도 같은 값을 얻음
Groupby
데이터를 그룹으로 나누고 각 그룹에 대해 연산을 수행
data = {'Category': ['Burger', 'Pizza', 'Pasta', 'Burger', 'Pizza'],
'Price': [8.99, 10.99, 12.49, 9.99, 11.99],
'Rating': [4.5, 4.2, 4.8, 4.3, 4.7]}
menu_df = pd.DataFrame(data)
category_groups = menu_df.groupby('Category')
average_price_by_category = category_groups['Price'].mean()
다음과 같이 그룹으로 묶어서 계산을 진행할 수 있는데,
Category 열을 기준으로 데이터를 그룹화하고,
각 그룹 내에서 가격(Price)의 평균을 계산
->각 카테고리별로 가격의 평균이 계산되어 출력 가능
df = pd.DataFrame({'scale':['small','large','small','large']
, 'location':['east','east','south','south'], 'sales':[10,20,30,40]})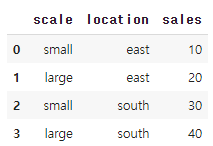
그룹 나누어 합계 구하기
위의 데이터에서
data_s = df.groupby(by='scale')['sales'].sum()데이터프레임을 'scale' 열을 기준으로 그룹화하고, 각 그룹 내에서 'sales' 열의 합계를 계산한 후 이 결과를 Series 형태로 출력
- groupby(by='scale'): 'scale' 열을 기준으로 데이터프레임을 그룹화하는 메서드
- ['sales']: 그룹화된 데이터프레임에서 'sales' 열을 선택하는 부분, 집계 함수를 적용할 대상
- .sum(): 선택한 'sales' 열에 대해 합계를 계산하는 집계 함수
-> type(): 변수의 데이터 타입을 확인
-> .index: Series 객체의 인덱스를 출력하는 코드
-> .values: Series 객체의 값을 출력하는 코드
인덱스 : 데이터 구조 내에서 각 항목을 고유하게 식별하는 역할
값 : 각 항목의 실제 데이터 또는 내용
그룹을 나누어, 평균을 구하여, 데이터프레임 변환
data_sl = df.groupby(by=['location', 'scale'])[['sales']].mean()- 'location'과 'scale' 두 열을 그룹화한 결과로 생성된 MultiIndex(다중 인덱스)
- 다중 인덱스가 DataFrame의 인덱스
- 출력하면, 그룹화된 데이터의 평균 판매량을 'location' 및 'scale'에 대한 다중 인덱스로 표시한 DataFrame을 출력
3.14 Apply
객체(함수)를 반복하여 적용
파이썬 내장함수 map과 유사
-apply 메서드는 시리즈 또는 데이터프레임에 함수를 적용
-map 메서드는 시리즈에만 적용
data = {'음식점명': ['레스토랑 A', '레스토랑 A', '레스토랑 B', '레스토랑 B'],
'음식명': ['파스타', '스테이크', '피자', '스파게티'],
'가격': [15, 25, 10, 12]}
df = pd.DataFrame(data)
display( list(map(lambda x: x**2, df['가격'])))
display( df['가격'].apply(lambda x: x**2))
맵의 경우에는 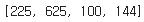
이렇게 결과는 리스트로 반환
어플라이의 경우에는 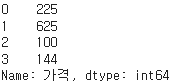
이렇게 시리즈 형태로 반환
3.15 Join
SQL과 비슷한 방식
df1 = pd.DataFrame({'주문번호': ['주문1', '주문2', '주문3'],
'메뉴': ['햄버거', '피자', '파스타'],
'가격': [8.99, 10.99, 12.49]})
df2 = pd.DataFrame({'주문번호': ['주문2', '주문3', '주문4'],
'리뷰': ['맛있어요', '서비스 좋아요', '음식 괜찮아요']})
print('메뉴 주문 정보:\n', df1)
print('고객 리뷰 정보:\n', df2)
와 같이 2개의 데이터프레임이 존재한다고 할때,
합치기
axis = 0: 행으로 합침, axis = 1: 열로 합침
concat 함수에 합칠 데이터프레임을 리스트로 전달하면, 이 함수는 해당 데이터프레임들을 지정한 방향으로 합침
merged_df1 = pd.concat([df1, df2], axis=0)
merged_df2 = pd.concat([df1, df2], axis=1)다음과 같은 형태로 두 데이터프레임을 합칠 수 있음
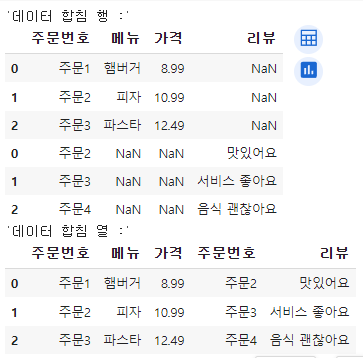
조인
내부 결합(Inner Join): 두 개의 테이블 키가 일치하는 데이터만 추출
외부 결합(Outer Join): 두 개의 테이블 키와 관련된 모든 데이터 추출
merge 함수를 사용하면 두 데이터프레임 간의 공통된 열을 기준으로 합침
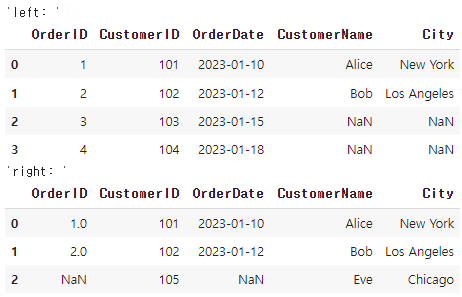
orders = pd.DataFrame({
'OrderID': [1, 2, 3, 4],
'CustomerID': [101, 102, 103, 104],
'OrderDate': ['2023-01-10', '2023-01-12', '2023-01-15', '2023-01-18']
})
customers = pd.DataFrame({
'CustomerID': [101, 102, 105],
'CustomerName': ['Alice', 'Bob', 'Eve'],
'City': ['New York', 'Los Angeles', 'Chicago']
})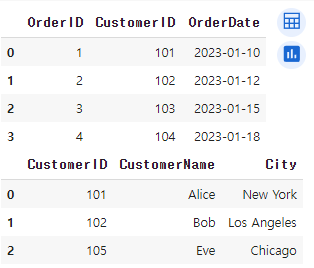
이렇게 두 데이터프레임이 존재할때
inner_join = pd.merge(orders, customers, on='CustomerID', how='inner')
outer_join = pd.merge(orders, customers, on='CustomerID', how='outer')
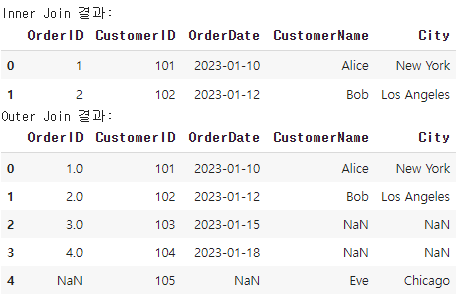
다음과 같이 합칠 수 있음
-on 매개변수에는 어떤 열을 기준으로 합칠지를 지정
-how 매개변수에는 어떤 방식으로 합칠지를 지정
좌 결합(Left Join): 왼쪽 테이블 키와 일치하는 데이터 추출
우 결합(Right Join): 오른쪽 테이블 키와 일치하는 데이터 추출
같은 방식으로도 가능 위의 같은 데이터 프레임에서
left_join = pd.merge(orders, customers, on='CustomerID', how='left')
right_join = pd.merge(orders, customers, on='CustomerID', how='right')