
1. 결측치 탐색
1.1 결측치
- 데이터의 값이 누락된 것 = 결측값, Missing Values
- NA 또는 N/A(Not Applicable or Not Available), NaN(Not a Number), Null로 표기됨
- None: 파이썬의 내장 객체로서 '값이 없음'을 나타냄 None은 어떠한 데이터 타입에도 속하지 않는 특별한 값
- NaN (Not a Number): 숫자가 아님을 나타내는 특수한 실수 값 주로 NumPy 패키지와 pandas 패키지에서 사용
- NA 또는 N/A(Not Applicable or Not Available), NaN(Not a Number), Null로 표기됨
- 전산 오류, 입력 누락, 인위적 누락 등으로 발생
- 설문조사(survey)와 종단연구(longitudinal research)에서 보편적으로 발생
- 설문조사는 참가자 중 일부가 답변하기 곤란한 질문에 의도적으로 응답을 하지 않을 수 있음
- 종단연구는 특정 대상을 장기간에 걸쳐 조사하는 것이므로, 사망, 임의 탈퇴, 연락두절 등의 상태가 발생
1.2 결측치의 유형
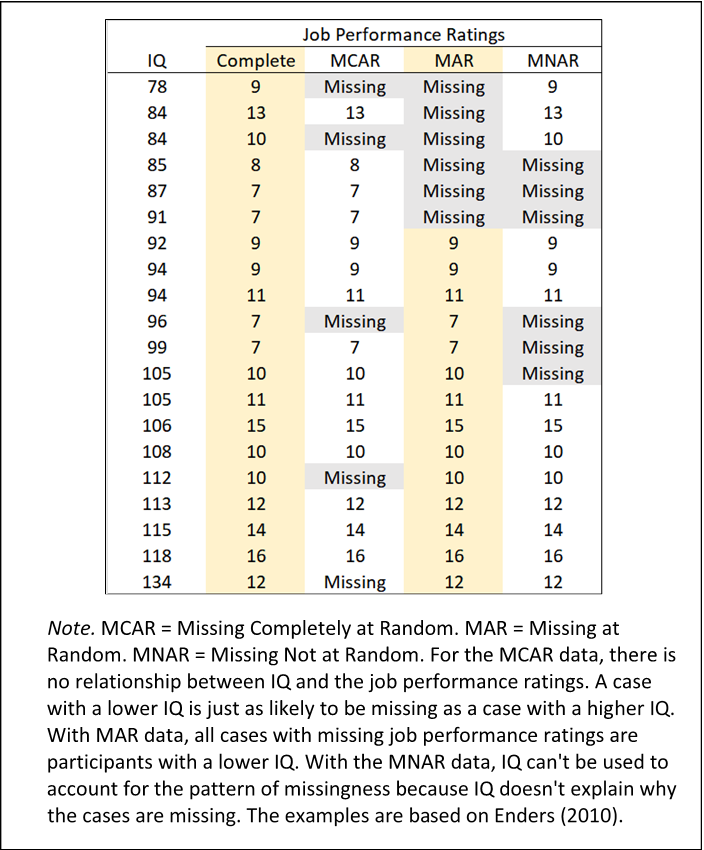
1. MCAR(Missing Completely At Random, 완전 무작위 결측)
-
결측치가 발생한 변수의 값에 상관없이 전체에 걸쳐 무작위로 발생한 경우
-
통계적으로 결측치의 영향이 없으므로 제거 가능
ex) 설문조사에서 응답자가 어떤 질문을 건너뛴 경우
MCAR의 경우 일반적으로 해당 데이터 포인트를 삭제하거나 평균/중앙값/모드 등으로 채우는 방법(imputation)을 사용할 수 있음
2. MAR(Missing At Random, 무작위 결측)
-
결측치가 발생한 변수의 값이 다른 변수와 상관관계가 있어 추정이 가능한 경우
-
통계적으로 결측치의 영향이 다소 있으나 편향은 없으므로 대체 가능
ex) 여성 응답자들이 특정 질문(예: 소득 관련 질문)에 대해 답변하지 않는 경향이 있다면, '성별' 변수가 결측치 발생 확률에 영향을 주는 것
회귀분석, 기대값 최대화 알고리즘(Expectation-Maximization algorithm), 다중 대입(Multiple Imputation) 등 접근법을 사용하여 결측치를 처리할 수 있음
3. MNAR(Missing Not At Random, 비무작위 결측)
- 결측치가 발생한 변수의 값과 관계가 있고 그 이유가 있는 경우
- 통계적으로 결측치의 영향이 크므로 결측치의 원인에 대한 조사 후 대응 필요
ex) 고소득자일수록 소득 정보를 제공하지 않는 경향이 있다면 '소득' 변수 자체가 결측치 발생 확률에 영향을 주는 것
해결하는 정확한 방법이 존재하진 않음

1.2 결측치 탐색
1.3.1 Pandas를 이용한 결측치 탐색
import pandas as pd
# 데이터세트 불러오기
df = pd.read_csv('../data/preprocessing_students.csv', sep=',')
df.head()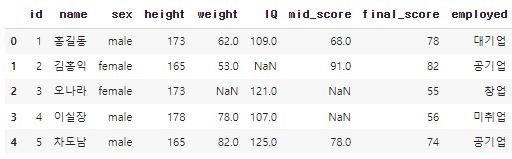
- 결측치 갯수 확인
- df.info(), df.isnull(), df.notnull(), .sum(0), .sum(1)
df.info()
다음과 같은 결과에서
이 정보는 pandas의 DataFrame에 대한 정보를 나타내는 것으로, 각 열(변수)에 대한 세부 정보를 제공
- RangeIndex: 데이터 프레임의 인덱스로, 0부터 19까지 총 20개의 행(row)이 있음을 나타냄
- Data columns (total 9 columns): 데이터 프레임에는 총 9개의 열(column)이 있음을 나타냄 이어서 각 열에 대한 상세 정보가 제공
- 마지막 줄인 'memory usage'는 이 DataFrame 객체가 메모리를 얼마나 차지하는 지를 보여줌
요약하면 주어진 DataFrame 객체는 id, name, sex, height, final_score 열에서 결측치가 없으며, weight, IQ, mid_score, employed 열에서는 일부 결측치를 가지고 있음
# isnull()의 True 개수를 합하여 확인
print(df.isnull().sum(axis=0)) # axis = 0 열기준, 1 행기준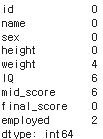
pandas DataFrame에서 결측치의 수를 계산하는 방법
- df.isnull(): 이 부분은 'df'라는 표(DataFrame)에서 비어 있는 값(결측치)이 어디에 있는지 찾아냄
비어있으면 True, 아니면 False로 표시 - .sum(axis=0): 이 부분은 위에서 찾아낸 True와 False를 세는 작업
'axis=0'이라는 것은 열(column) 방향으로 세라는 의미
즉, 각 열마다 True가 몇 개인지 셈
파이썬에서는 True를 1로, False를 0으로 계산하기 때문에 결국 결측치의 개수가 됨 - print(): 마지막으로 앞서 계산한 결과(각 열의 결측치 개수)를 화면에 출력
따라서 전체 코드의 의미는 "표(df)에서 각 열마다 비어 있는 값(결측치)이 몇 개인지 찾아내서 화면에 보여주기"
1.3.2 klib을 이용한 결측치 탐색
!pip install klib
klib 설치후에.
import klib
import warnings
# 경고 메시지 무시
warnings.filterwarnings(action='ignore')
# 결측치에 대한 프로파일링 플롯
klib.missingval_plot(df)'klib'라이브러리의 'missingval_plot' 함수를 사용하여 데이터프레임(df) 내의 결측치(missing value, 비어있는 값) 분포를 시각화
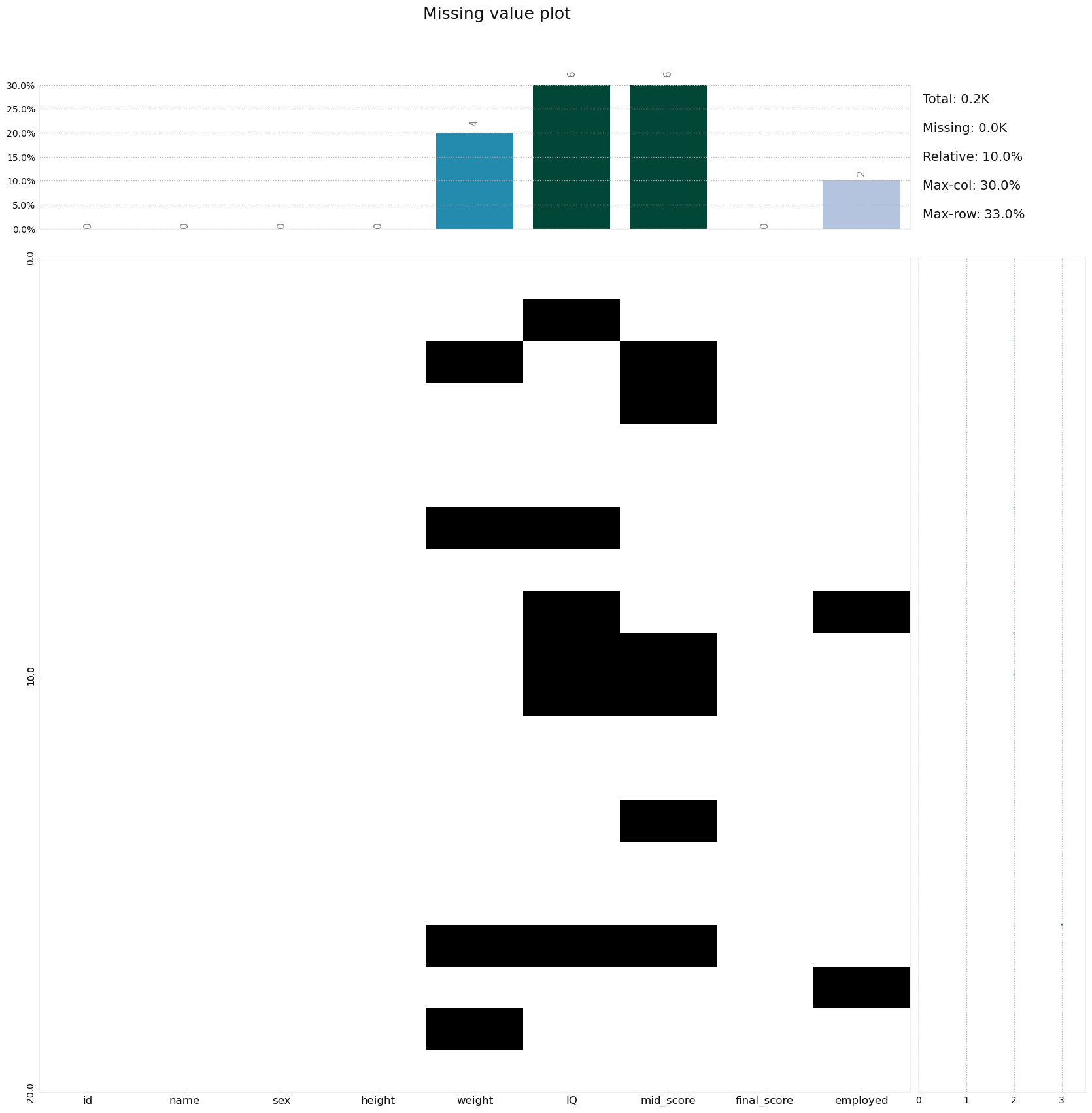
# 결측치에 대한 프로파일링 플롯
klib.missingval_plot(df, sort=True)
이 코드는 'klib' 라이브러리의 'missingval_plot' 함수를 사용하여 데이터프레임(df) 내의 결측치(비어있는 값) 분포를 시각화하고, 그 결과를 결측치가 많은 순서대로 정렬해서 보여쥼
sort=True 옵션은 결측치가 많은 열(column)을 위로 정렬하라는 의미
# 상관관계 플롯
klib.corr_plot(df) 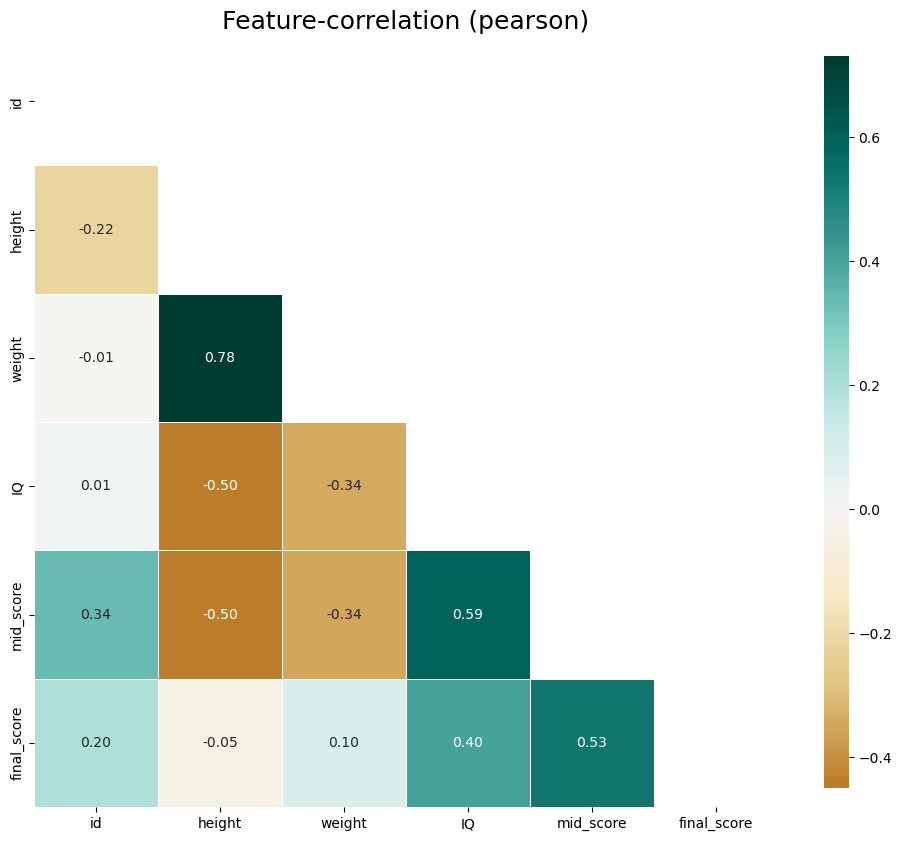
변수간 상관분석 결과 weight와 height의 상관관계가 강한 양의 상관관계(0.78), IQ와 mid_score가 양의 상관관계(0.59), mid_score와 final_score가 양의 상관관계(0.53)을 보이고 있음
# 한글이 안나올 경우 폰트 지정
import matplotlib.pyplot as plt
plt.rc('font', family='Malgun Gothic')
-> 사실상 아래코드와 연관은 없음
# 범주형 변수에 대한 분석
klib.cat_plot(df)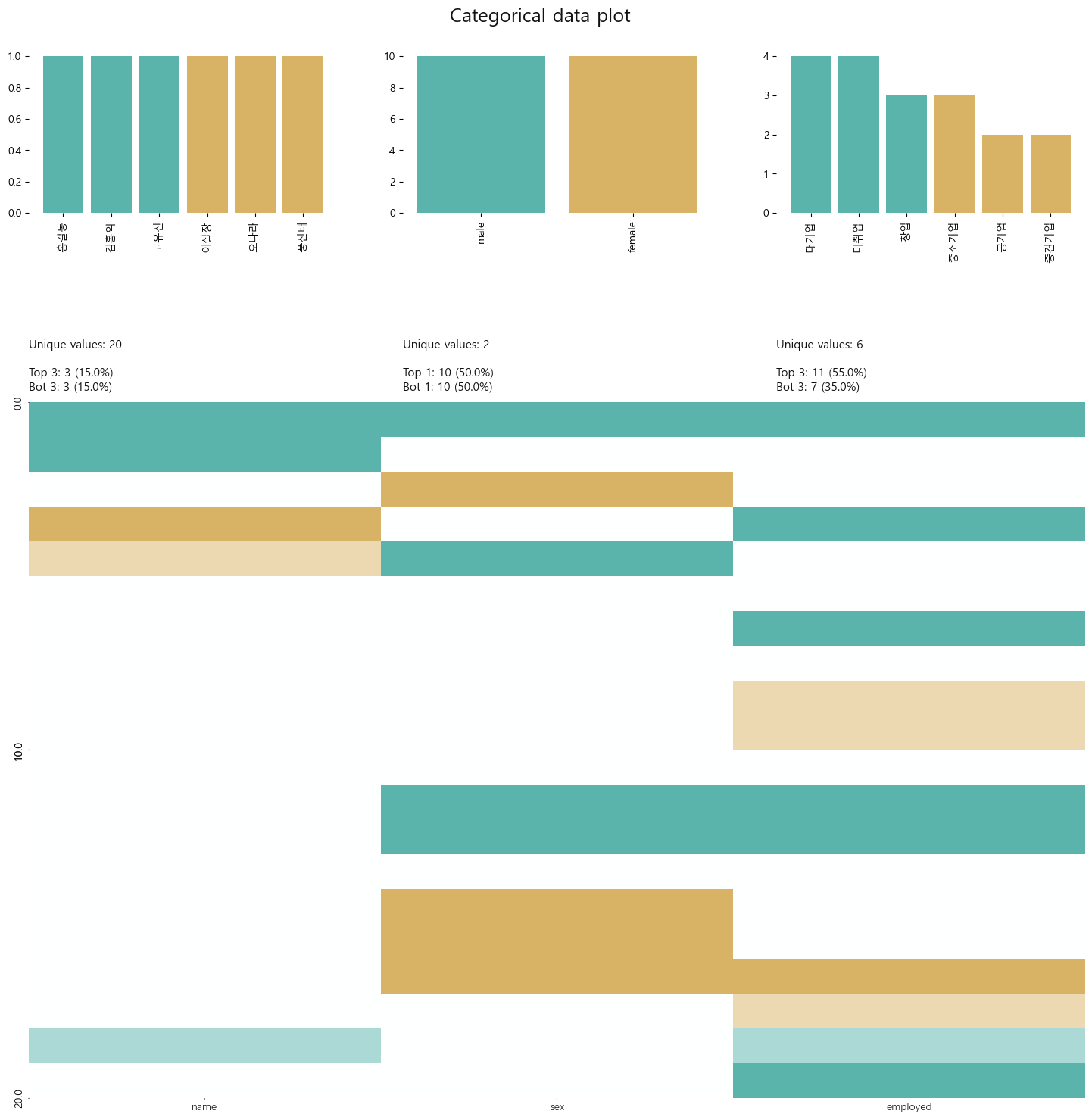
# 결측치가 있는 변수의 분포 확인
klib.dist_plot(df.weight)
klib.dist_plot(df.IQ)
klib.dist_plot(df.mid_score)
-
weight는 특정한 패턴이 보이지 않음

-
IQ는 중간 영역대의 밀도가 낮아 중간영역대의 데이터가 누락되었음을 확인 가능

-
mid_score는 낮은 점수대의 데이터가 누락되었음을 확인 가능
2. 결측치 처리
2.1 결측치 처리방법 개요
-
제거(deletion)
- MCAR(완전 무작위 결측)일 때 사용 가능
- 데이터의 손실이 발생 → 자유도 감소 → 통계적 검정력 저하
- 표본의 수가 충분하고 결측값이 10-15% 이내일 때에는 결측값을 제거한 후 분석하여도 결과에 크게 영향을 주지 않음
-
대체(imputation)
- 표본 평균과 같은 대표값으로 대체할 경우 → 대표값 데이터가 많아짐 → 잔차 변동이 줄어듬 → 잘못된 통계적 결론 유도
- 모수 추정 시 편향(bias) 발생
2.2 결측치 제거(deletion)
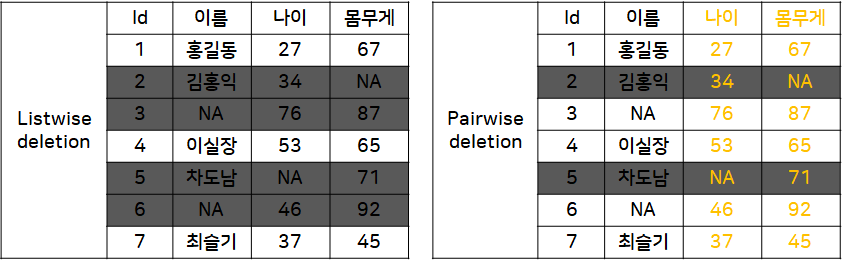
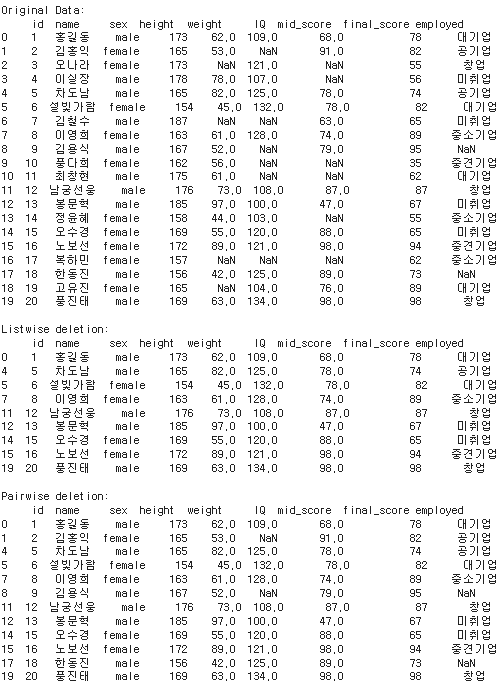
- Listwise deletion
- 결측치가 존재하는 행(instance) 자체를 삭제하는 방식
- MCAR일 때만 가능
- 데이터 표본의 숫자가 적은 경우 표본의 축소로 인한 검정력 감소
- Pairwise deletion
- 분석에 사용하는 속성의 결측치가 포함된 행만 제거하는 방식
- MCAR일 때만 가능
import pandas as pd
# Listwise deletion
df_listwise = df.dropna()
# Pairwise deletion
df_pairwise = df.dropna(subset=['weight', 'mid_score'])
print(f'Original Data:\n {df}\n')
print(f'Listwise deletion:\n {df_listwise}\n')
print(f'Pairwise deletion:\n {df_pairwise}\n')-
df_listwise = df.dropna(): 이 코드는 'listwise deletion'(전체 행 삭제) 방법을 사용하여 결측치를 처리
즉, 어떤 행에 하나라도 결측치가 있다면 그 전체 행을 삭제 -
df_pairwise = df.dropna(subset=['weight', 'mid_score']): 이 코드는 'pairwise deletion'(부분적인 삭제) 방법을 사용하여 결측치를 처리
여기서는 오직 'weight'와 'mid_score' 열에 대해서만 고려하며, 이 열들 중 어느 하나라도 결측치가 있는 행만 삭제'\n'(줄바꿈 문자)
2.3 결측치 대체(Imputation)
2.3.1 Single Imputation(단순대체법)
- 결측치의 대체값으로 하나의 값을 선정하는 것
- mean, correlation, 회귀계수와 같은 파라미터 추정 시 편향(bias) 발생가능성 높음
- 이러한 추정 편향으로 인해 아예 결측값을 제거하는 것보다 통계적 특성이 나빠질 수 있음
💠 단순대체법 종류
Explicit Modeling
- Mean imputation
데이터의 평균값(mean, median, mode)으로 결측값을 대체
평균 대체 -> 표본오차 왜곡, 축소 -> 부정확한 p-value -> 검정력 약화 - Regression imputation
회귀식을 만들어 예측 된 값으로 결측값 대체
회귀 예측값 대체 -> 잔차 축소, 왜곡 -> 𝑅^2
증가, 왜곡 - Stochastic regression imputation
회귀 예측값으로 대체하는 것과 유사하나, random error term을 추가하여 예측값에 변동을 주는 방법
표본오차의 과소 추정 문제 있음
Implicit Modeling
- Hot deck imputation
- 연구중인 자료에서 표본을 바탕으로 비슷한 규칙을 찾아 결측값을 대체
- 다른 변수에서 비슷한 값을 갖는 데이터 중에서 하나를 랜덤 샘플링하여 그 값을 복사
- 결측값이 존재하는 변수가 가질 수 있는 값의 범위가 한정되어 있을 때 사용
- Cold deck imputation
- 외부 출처에서 비슷한 연구를 찾아 결측값을 대체
- Hot deck imputation과 유사하나, 어떠한 규칙 하(예를 들면, k번째 샘플의 값을 취해온다는 등)에서 하나를 선정
2.3.2 단순대체법 Python 적용
- Mean imputation
- scikit-learn의 SimpleImputer 클래스를 사용
- strategy: mean/mode/most_frequent
- 데이터가 실수 연속값인 경우에는 평균 또는 중앙값을 사용, 값의 분포가 대칭적이면 평균이 좋고 값의 분포가 심하게 비대칭인 경우에는 중앙값이 적당
- 데이터가 범주값이거나 정수값인 경우에는 최빈값을 사용
- Regression/Stochastic regression imputation
- scikit-learn의 LinearRegression 사용
- Hot deck/Cold deck imputation
- Pandas의 fillna()적용
from sklearn.impute import SimpleImputer
df_imputed = pd.DataFrame.copy(df)
# 110대가 결측인 IQ는 평균으로 대체
df_imputed[['IQ']] = SimpleImputer(strategy="mean").fit_transform(df[['IQ']])
# 비대칭 분포를 갖는 mid_score는 중앙값으로 대체
df_imputed[['mid_score']] = SimpleImputer(strategy="median").fit_transform(df[['mid_score']])
# 범주형 employed는 Hot deck으로 대체
df_imputed['employed'].fillna(method='bfill', inplace=True)
# height와 양의 상관관계가 있는 weight는 Stochastic regression으로 대체
from sklearn.linear_model import LinearRegression
import numpy as np
# 결측치가 있는 인덱스 검색
idx = df.weight.isnull() == True
# 학습을 위한 데이터 세트 분리
X_train, X_test, y_train = df[['height']][~idx], df[['height']][idx], df[['weight']][~idx]
# 선형회귀모형 인스탄스 생성 후 학습
lm = LinearRegression().fit(X_train, y_train)
# 예측값 + 변동값하여 결측치를 대체
df_imputed.loc[idx, 'weight'] = lm.predict(X_test) + 5*np.random.rand(4,1)
df_imputed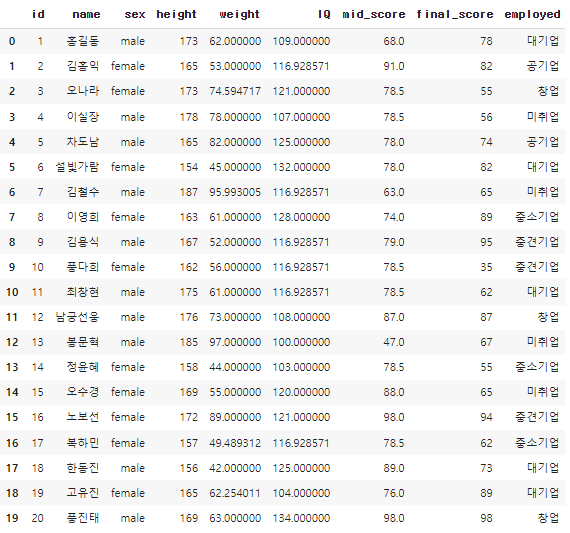
- df_imputed = pd.DataFrame.copy(df): 원본 데이터프레임(df)의 복사본을 만들어 df_imputed에 저장
이렇게 하는 이유는 원본 데이터를 보존하고, 복사본에서 결측치 대체 작업
- df['IQ']와 같이 하나의 대괄호를 사용하면 해당 열을 시리즈(Series) 형태로 반환
- df[['IQ']]와 같이 두 개의 대괄호를 사용하면 해당 열만 포함하는 데이터프레임(DataFrame)을 반환
- df_imputed[['IQ']] = SimpleImputer(strategy="mean").fit_transform(df[['IQ']]): 'IQ' 열의 결측치를 평균값으로 대체
SimpleImputer 함수는 주어진 전략(여기서는 "mean" 즉, 평균)에 따라 결측치를 대체하는 역할
fit_transform()은 사이킷런(scikit-learn) 라이브러리의 변환기(transformer) 클래스에 포함된 메소드
이 메소드는 '학습'과 '변환' 두 가지 작업을 한 번에 수행
fit(): 이 단계에서는 변환기가 데이터를 분석하고, 그 결과를 내부적으로 저장
예를 들어 SimpleImputer(strategy="median")의 경우, fit() 메소드는 데이터에서 각 열의 중앙값을 계산하고 이 값을 내부에 저장
transform(): 이 단계에서는 fit() 단계에서 학습한 정보(여기서는 중앙값)를 사용하여 데이터를 변환
SimpleImputer의 경우, transform() 메소드는 결측치를 해당 열의 중앙값으로 대체
fit_transform()은 두 단계를 한 번에 수행
정리하면 ,
'mid_score' 열의 중앙값을 계산(fit)
'mid_score' 열의 결측치를 그 중앙값으로 대체(transform)
그 결과로 반환된 데이터프레임을 df_imputed의 'mid_score' 열에 할당
-
df_imputed[['mid_score']] = SimpleImputer(strategy="median").fit_transform(df[['mid_score']]): 'mid_score' 열의 결측치를 중앙값으로 대체
-
df_imputed['employed'].fillna(method='bfill',
inplace=True): 'employed' 열의 결측치를 Hot deck 방식으로 대체
Hot deck 방식은 바로 다음 행의 값('bfill': backward fill) 또는 바로 앞 행의 값('ffill': forward fill)으로 결측치를 채우는 방법 -
선형 회귀 모델(LinearRegression)을 사용해서 'weight'열의 결측값을 예상하고 그 값을 채워 넣는것
idx = df.weight.isnull() == Trueidx 변수에 weight 칼럼이 null인 경우 True 값을 저장
X_train, X_test, y_train = df[['height']][~idx], df[['height']][idx], df[['weight']][~idx]학습용 데이터(X_train, y_train)와 예상해야 하는 데이터(X_test)로 분리
lm = LinearRegression().fit(X_train, y_train)선형회귀모형 인스턴스(lm) 생성 후 학습용 데이터로 학습(fit())시킵니다.
"인스턴스 생성"은 특정 클래스로부터 객체를 만드는 과정을 의미
df_imputed.loc[idx, 'weight'] = lm.predict(X_test) + 5*np.random.rand(4,1)'weight' 열의 결측치를 선형 회귀 모델을 사용해 예측한 값과 랜덤한 변동값을 더한 값으로 대체하는 작업을 수행합니다.
-
lm.predict(X_test): 이 부분은 선형 회귀 모델(lm)을 사용해 'height'에 대응하는 'weight' 값을 예측
여기서 X_test는 'height' 열에서 결측치가 있는 행 -
5*np.random.rand(4,1): 이 부분은 0부터 1사이의 균일 분포(uniform distribution)에서 랜덤하게 생성된 숫자에 5를 곱해서 변동값을 만듬
(4,1)은 변동값을 생성할 배열의 크기(shape)를 의미하며, 이 경우에는 4행 1열짜리 배열 -> 임의적 변동성을 만드는것 -
lm.predict(X_test) + 5*np.random.rand(4,1): 위 두 부분을 합치면, 선형 회귀로 예측한 값에 임의의 변동값이 추가된 결과
-
df_imputed.loc[idx, 'weight'] = ...: 마지막으로 .loc 메소드를 사용해 df_imputed 데이터프레임에서 결측치가 있는 위치(idx)에 위에서 계산한 값을 할당하여 원래의 결측치를 대체
코드는 선형 회귀로 예상된 값과 임의적인 변동성을 고려하여 원래 데이터셋에서 발생한 'weight' 열의 결측치를 보완하는 방법
2.3.3 다중대체법(Multiple Imputation)
-
결측치의 대체값을 여러 추정값을 종합하여 선정하는 것
-
Multiple Imputation 3단계
- Imputation Phase: 가능한 대체 값의 분포에서 추출된 서로 다른 값으로 복수의 데이터 셋을 생성
- Analysis Phase: 각 데이터 셋에 대하여 모수의 추정치와 표본오차 계산
- Pooling Phase: 모든 데이터 셋의 추정치와 표본오차를 통합하여 하나의 대치값 생성
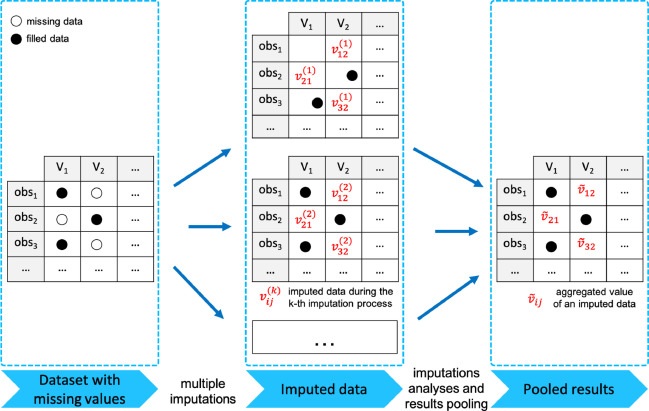
MICE(Multiple Imputation by Chained Equations)
- 다중대체법의 한 종류
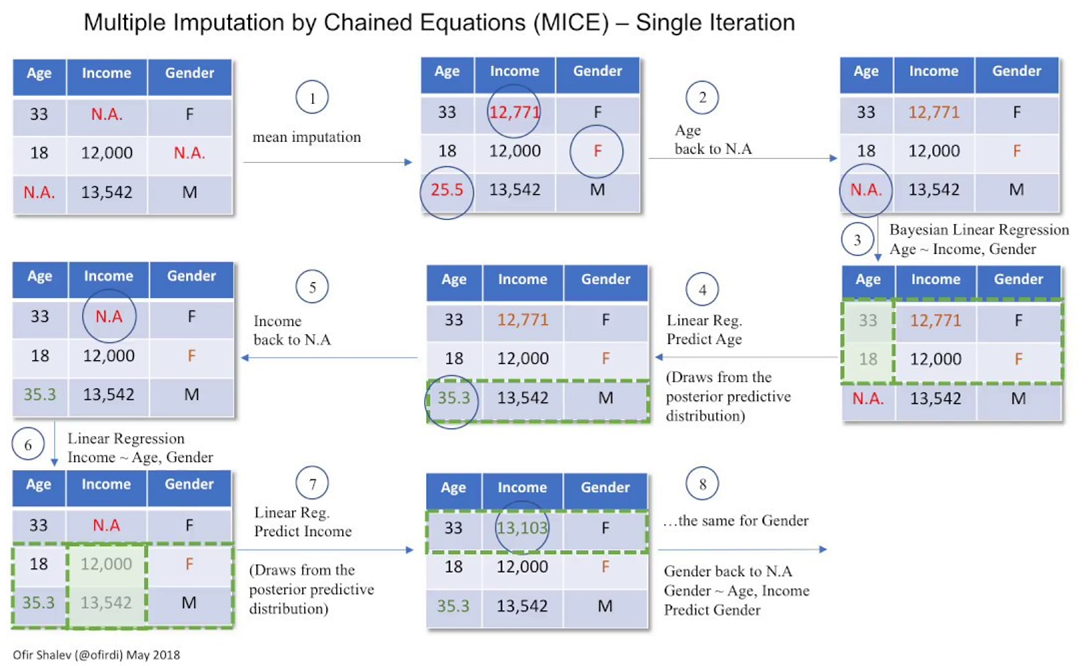
import numpy as np
# scikit-learn에서 R의 MICE 패키지를 따라서 실험적으로 개발 중
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer# 데이터 세트
X_train = [[33, np.nan, .153], [18, 12000, np.nan], [np.nan, 13542, .125]]
X_test = [[45, 10300, np.nan], [np.nan, 13430, .273], [15, np.nan, .165]]두 개의 2차원 리스트를 생성하고, 각각 X_train과 X_test라는 변수에 할당하는 과정
# mice 인스탄스 생성 (붕어빵틀..)
mice = IterativeImputer(max_iter=10, random_state=0)
mice.fit(X_train)- IterativeImputer(max_iter=10, random_state=0) 코드 부분은 IterativeImputer 클래스의 인스턴스를 생성
- max_iter=10: 결측치 대체 작업을 최대 10번 반복하도록 설정
- random_state=0: 난수 생성기의 시드값으로서, 코드가 동일한 결과를 출력하도록 보장하는 역할
- fit 메소드는 모델 학습 과정
여기서 모델 학습이란 결측치 대체 작업에서 필요한 정보를 추출하여 저장하는 과정- 예: 각 변수간의 상관관계
np.set_printoptions(precision=5, suppress=True)
print('X_train MICE: \n', mice.transform(X_train))
print('X_test MICE: \n', mice.transform(X_test))결측치가 대체된 데이터 출력과정...
과정이 너무 복잡해서 여기는 그냥 그렇다고 기억.

KNN Imputation
- KNN(K-Nearest Neighbor)은 분석대상을 중심으로 가장 가까운 k개 요소(이웃)들 중에서 가장 많은 수의 집단으로 분류하는 지도학습 알고리즘
- KNN Imputation은 결측치가 범주형이면 이웃 데이터 중 최빈값으로 대체하고 연속형이면 이웃 데이터들의 중앙값으로 대체하는 방법
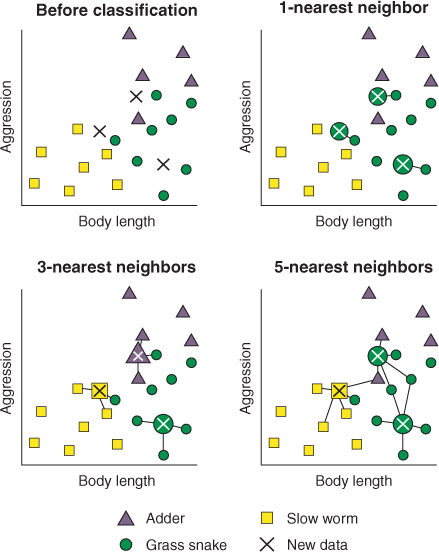
import numpy as np
from sklearn.impute import KNNImputerknn = KNNImputer(n_neighbors=2, weights="uniform")
knn.fit(X_train)
print('X_train KNN: \n', knn.transform(X_train))
print('X_test KNN: \n', knn.transform(X_test))- n_neighbors=2: k-Nearest Neighbors 알고리즘에서 고려할 이웃의 수를 2로 설정
- weights="uniform": 각 이웃에 동일한 가중치를 부여하는 방식으로 결측치를 대체하도록 설정
- 그리고 이렇게 생성된 인스턴스를 knn라는 변수에 할당

