
1. 단일 범주형 변수
1. 단일 범주형 변수 빈도분석
# tidyverse 라이브러리 구동
library('tidyverse’)
library('readxl’)
library('haven’)
library('magrittr’)
setwd(“______________”)
# 데이터 불러오기
data_131 = read_spss("data_TESS3_131.sav")1. 단일 범주형 변수 사전처리(Pre-processing)
# 응답거부 (-1) 존재
e.g. CaseID=200
# 음수로 입력된 변수값은 결측값으로 변환
mydata = data_131 %>%
mutate_if(
is.double,
funs(ifelse(. < 0,NA,.))
)# 간단한 명목변수 분석: 성별 응답자 빈도
mydata %>%
count(PPGENDER)
# 변수에 라벨 붙이기
mydata = mydata %>%
mutate(
female=labelled(PPGENDER,c(남성=1,여성=2))
)
mydata %>%
count(as_factor(female))ggplot2 패키지의 구성 요소
- 기존에생성한도표영역위에 기하학적요소추가: + 연산자이용
- 기하학적요소는함수명이geom_xxx() 형태

2. 단일 범주형 변수 시각화
# 시각화
ggplot(mydata,aes(x=as_factor(female)))+
geom_bar()
또는
mydata %>% ggplot(aes(x=as_factor(female)))+
geom_bar()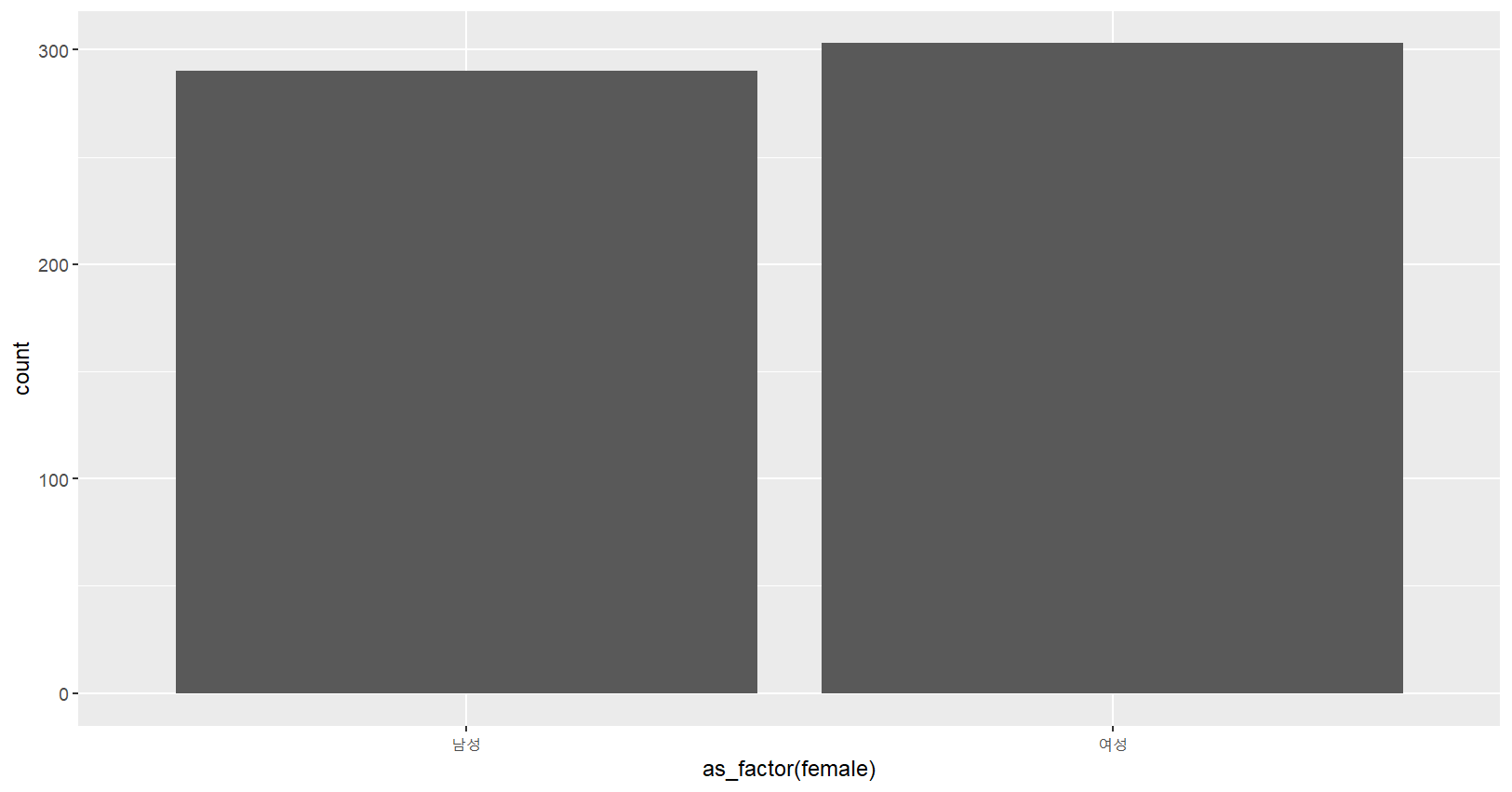
# 그래프를 보다 보기 좋게 변경한다.
(1) X축과 Y축의 라벨에 정보 입력
(2) Y축의 범위를 280부터 320으로 조정
mydata %>% ggplot(aes(x=as_factor(female)))+
geom_bar()+
labs(x="응답자의 성별",y="빈도수")+
coord_cartesian(ylim=c(280,320))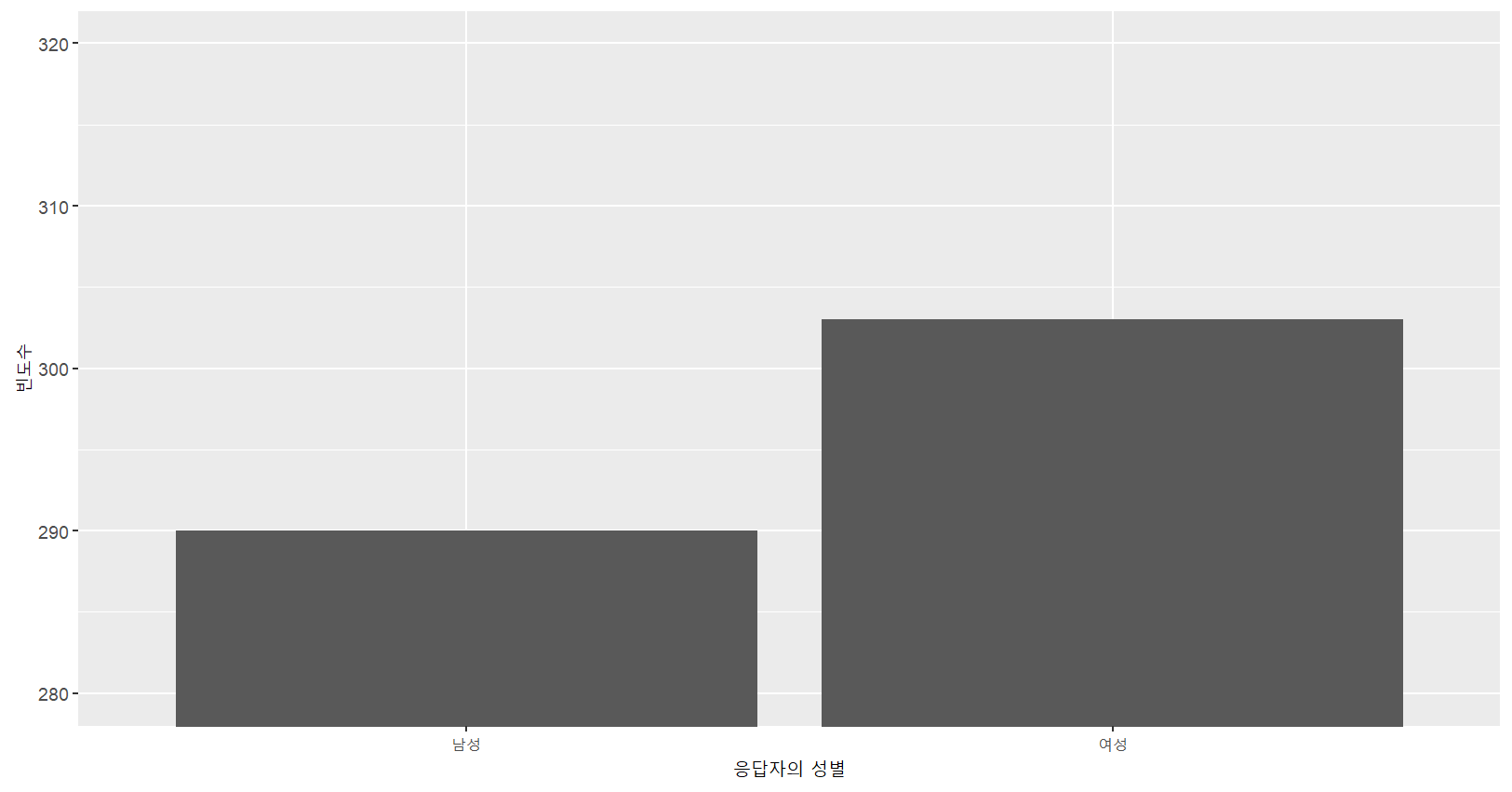
3. 범주형 변수의 수준이 많은 경우 빈도분석
# 범주형 변수의 수준이 많은 경우
mydata = mydata %>%
mutate(
religion=as.character(as_factor(data_131$REL1))
)
mydata %>%
count(religion)#A tibble: 14 × 2
religion
1 Baptist-any denomination 78
2 Buddhist 3
3 Catholic 141
4 Eastern Orthodox 3
5 Hindu 4
6 Jewish 15
7 Mormon 11
8 Muslim 3
9 None 114
10 Other Christian 71
11 Other non-Christian 10
12 Pentecostal 21
13 Protestant (e.g., Methodist, Lutheran, Presbyterian, Episcopal) 116
14 Refused 3
# 시각화: 복잡한 경우 빈도표를 저장하면 편리
myresult = mydata %>% count(religion)
ggplot(myresult,aes(x=religion,y=n))+
geom_bar(stat="identity")+
labs(x="Respondents' religions (including 'Refused' & 'None')",
y="Number of respondents")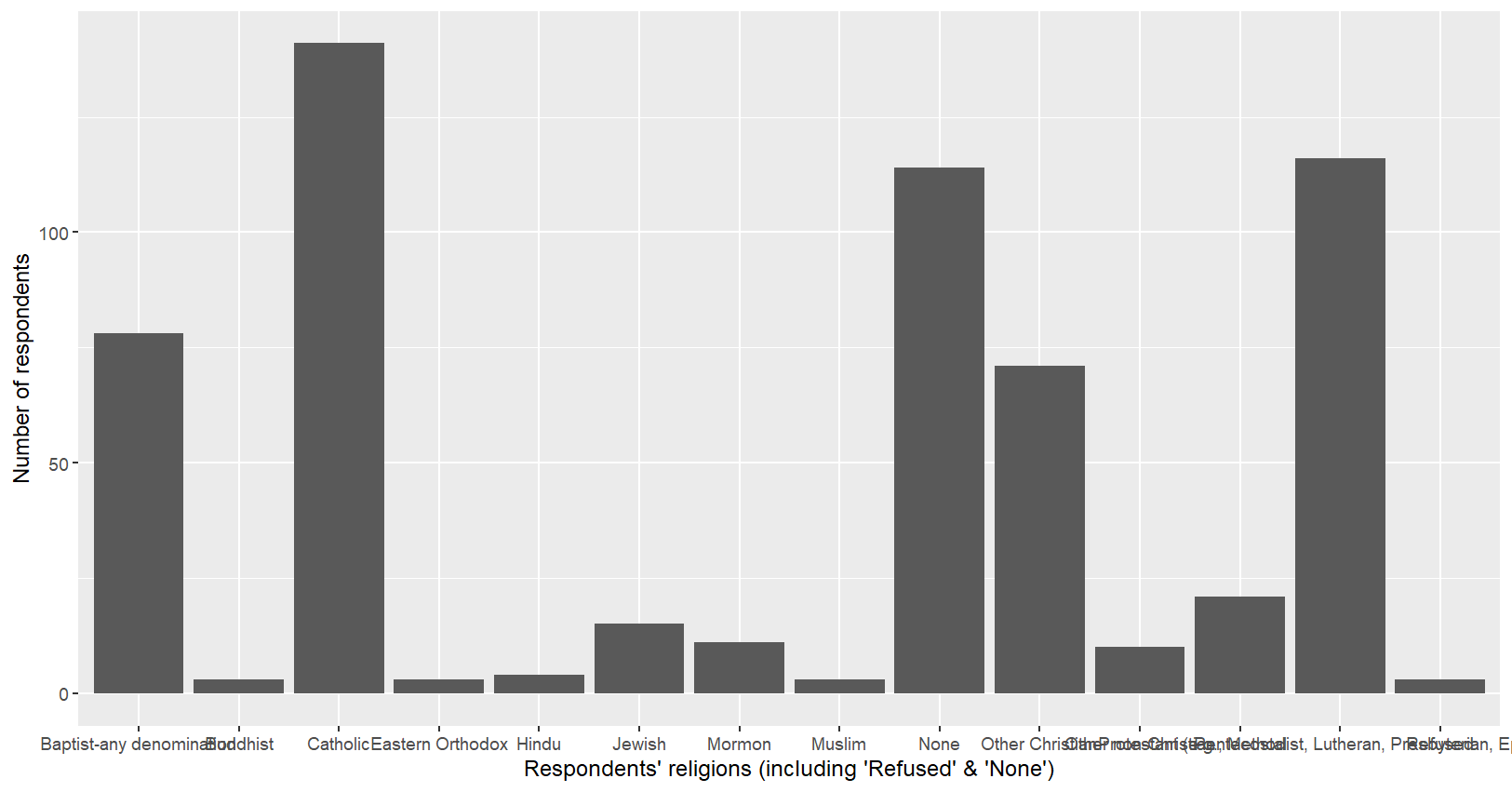
# 그래프 뒤집기
ggplot(myresult,aes(x=religion,y=n))+
geom_bar(stat="identity")+
labs(x="Respondents' religions (including 'Refused' & 'None')",
y="Number of respondents")+
coord_flip()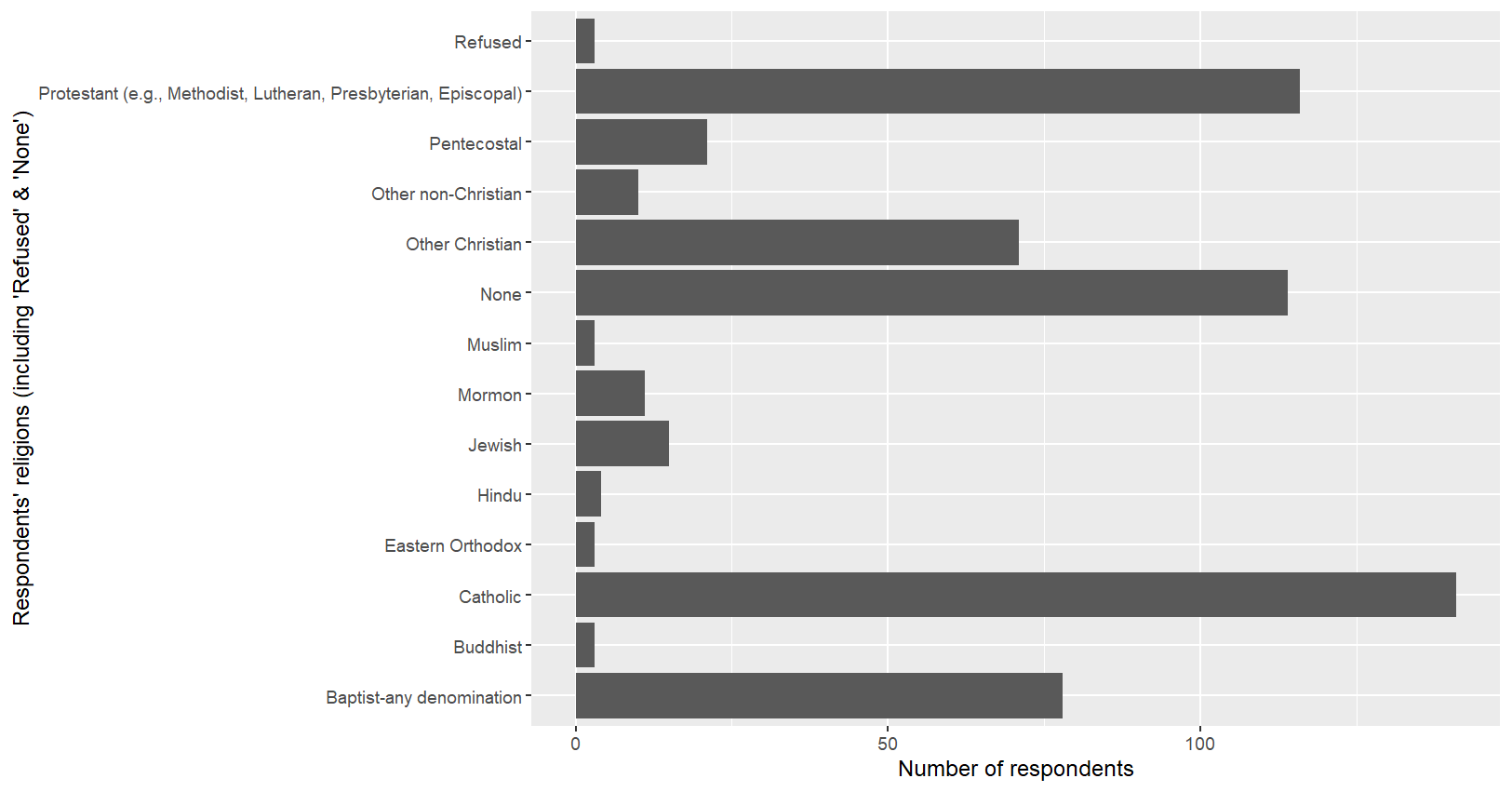
# 리코딩 : 라벨 정리
myresult = myresult %>%
mutate(
religion=ifelse(str_detect(religion,"Protestant"),"Protestants",religion)
)
ggplot(myresult,aes(x=religion,y=n))+
geom_bar(stat="identity")+
labs(x="Respondents' religions (including 'Refused' & 'None')",
y="Number of respondents")+
coord_flip()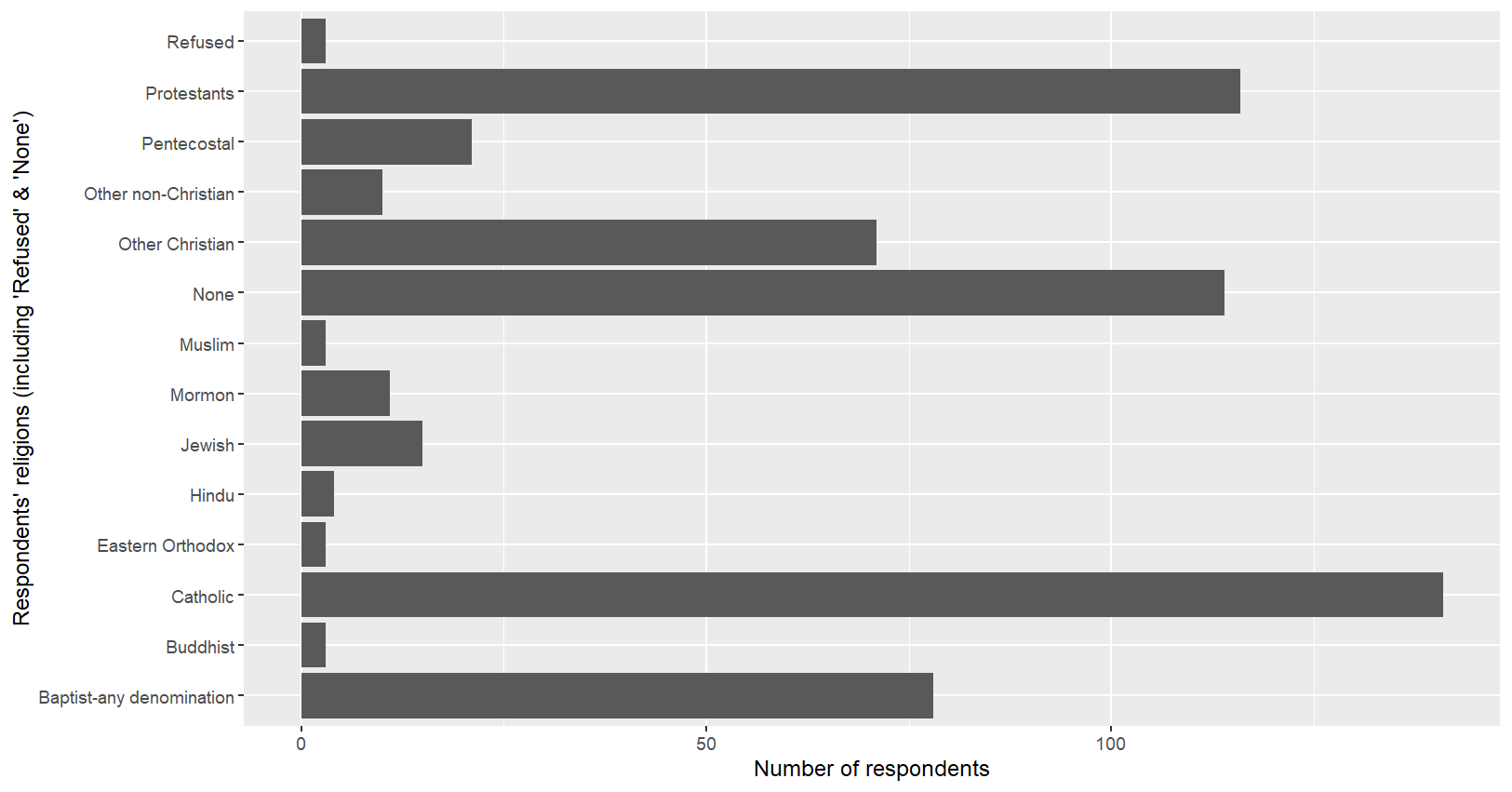
# 범주형 변수 수준을 빈도수에 따라 정렬
myresult = myresult %>%
mutate(
religion=fct_reorder(religion,n,"mean")
)
ggplot(myresult,aes(x=religion,y=n))+
geom_bar(stat="identity")+
labs(x="Respondents' religions (including 'Refused' & 'None')",
y="Number of respondents")+
coord_flip()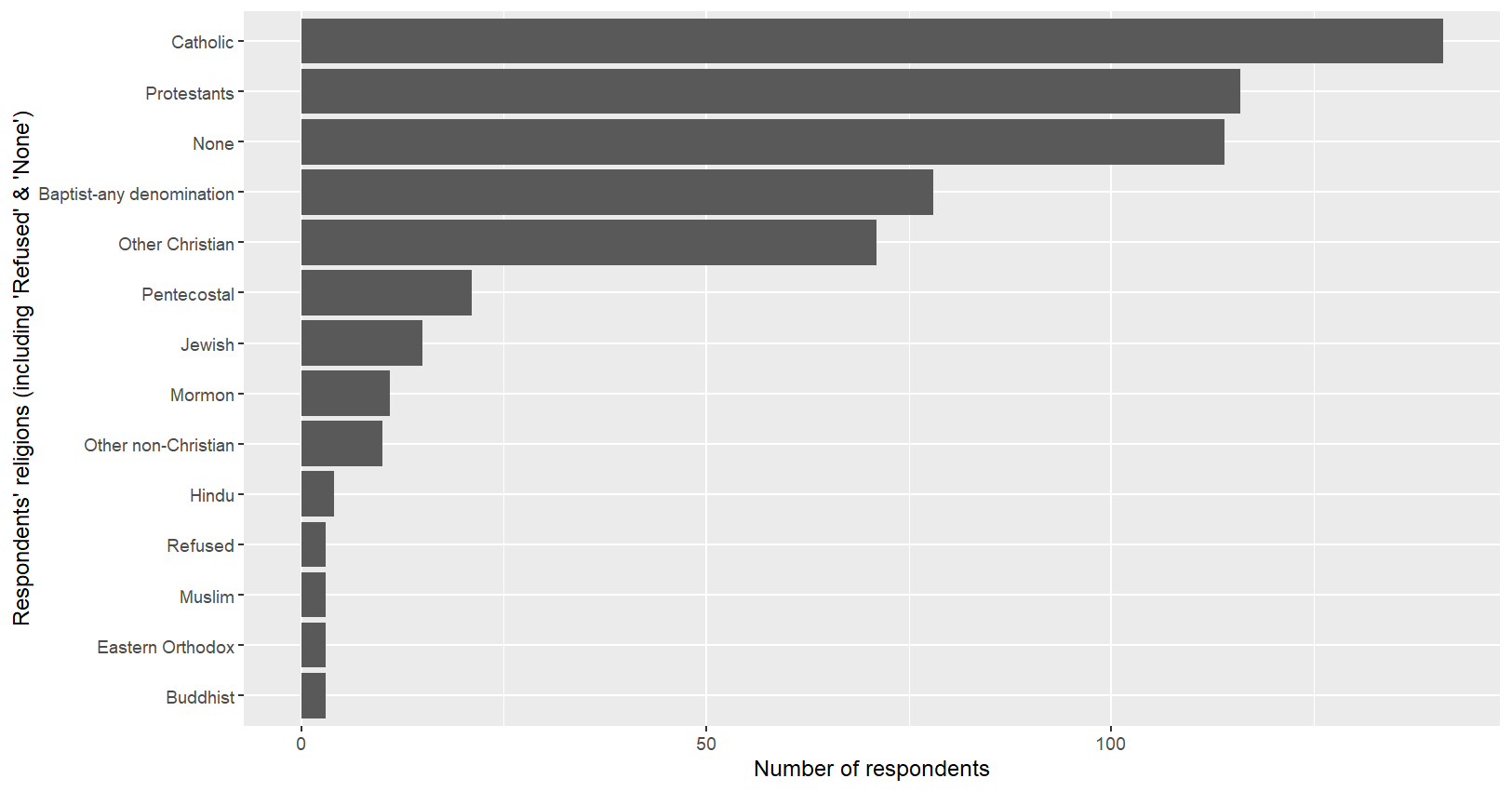
2. 복수의 범주형 변수
1. 두 개의 범주형 변수들을 교차한 빈도분석 : 교차표(cross-tabulate)
- 두 범주형 변수의 상관관계를 살펴보기 위해 실시
- 교차표분석과 카이제곱분석을 동시에 고려 → 두 범주형 변수의 상관관계 결정
- 교차표분석 : 기술통계분석 / 카이제곱분석 : 모형추정
Q. 응답자의 정치적 성향과 성별은 어떤 관계가 있을까?
# 변수의 변환
• 리커트 7점 척도로 측정된 정치적 성향 변수 (IDEO)
> mydata %>% count(IDEO)
# A tibble: 8 × 2
IDEO n
<dbl> <int>
1 1 18
2 2 86
3 3 60
4 4 217
5 5 75
6 6 103
7 7 30
8 NA 4# 변수의 변환
• 리커트 7점 척도로 측정된 정치적 성향 변수 (IDEO)를 이용해 [진보, 중도,
보수]의 세 정치적 성향 집단 변수를 만든다.
• IDEO=1, 2, 3 → 진보
• IDEO=4 → 중도
• IDEO=5, 6, 7 → 보수
# 정치적 성향(IDEO)변수를 3집단으로 리코딩
mydata = mydata %>%
mutate(
libcon3=as.double(cut(IDEO,c(0,3,4,Inf),1:3)),
libcon3=labelled(libcon3,c(진보=1,중도=2,보수=3)) # libcon3과 female 변수의 교차표
mydata %>%
count(as_factor(female),as_factor(libcon3))
# A tibble: 8 × 3
`as_factor(female)` `as_factor(libcon3)` n
<fct> <fct> <int>
1 남성 진보 69
2 남성 중도 108
3 남성 보수 110
4 남성 NA 3
5 여성 진보 95
6 여성 중도 109
7 여성 보수 98
8 여성 NA 1# NA를 제외, 성별X정치성향의 교차표
myresult = mydata %>%
count(as_factor(female),as_factor(libcon3)) %>%
drop_na()
# A tibble: 8 × 3
`as_factor(female)` `as_factor(libcon3)` n
<fct> <fct> <int>
1 남성 진보 69
2 남성 중도 108
3 남성 보수 110
4 여성 진보 95
5 여성 중도 109
6 여성 보수 98# NA를 제외, 성별X정치성향의 교차표
myresult %>%
spread(key=`as_factor(libcon3)`,value=n)
# A tibble; 2 X 4
`as_factor(female)` 진보 중도 보수
<fct> <int> <int> <int>
1 남성 69 108 110
2 여성 95 109 98# 막대그래프로 시각화
ggplot(myresult,aes(x=‘as_factor(female)’, y=n, fill=‘as_factor(libcon3)’))+
geom_bar(stat="identity")+
labs(x="응답자의 성별",y="빈도수",fill="정치적 성향")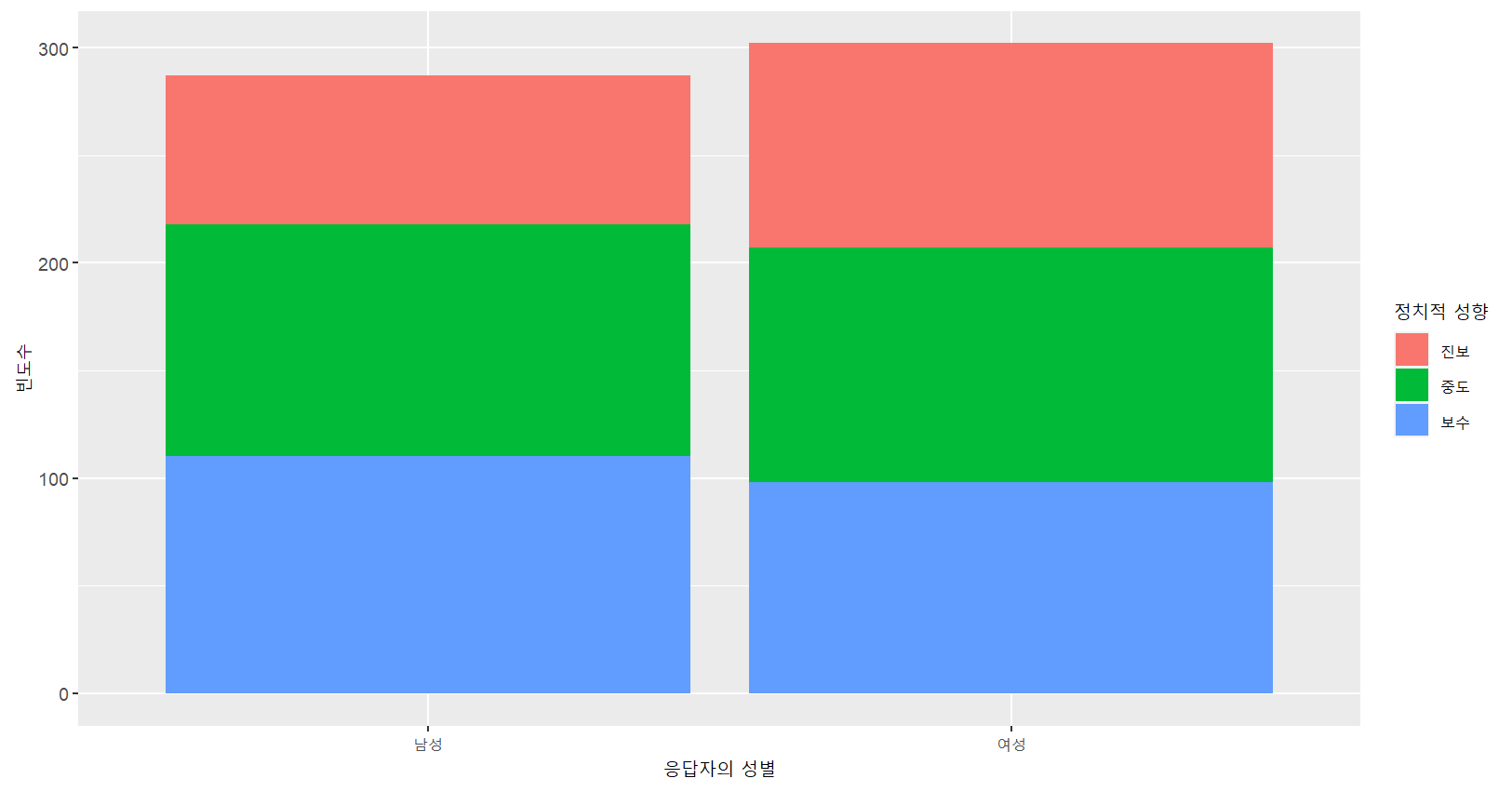
# 정치적 성향별 응답자를 쌓아두는 방식이 아니라 병렬시키는 방식
# 보다 보기 좋은 방식으로 시각화
ggplot(myresult,aes(x=‘as_factor(female)’, y=n, fill=‘as_factor(libcon3)’))+
geom_bar(stat="identity", position="dodge")+
labs(x="응답자의 성별",y="빈도수",fill="정치적 성향")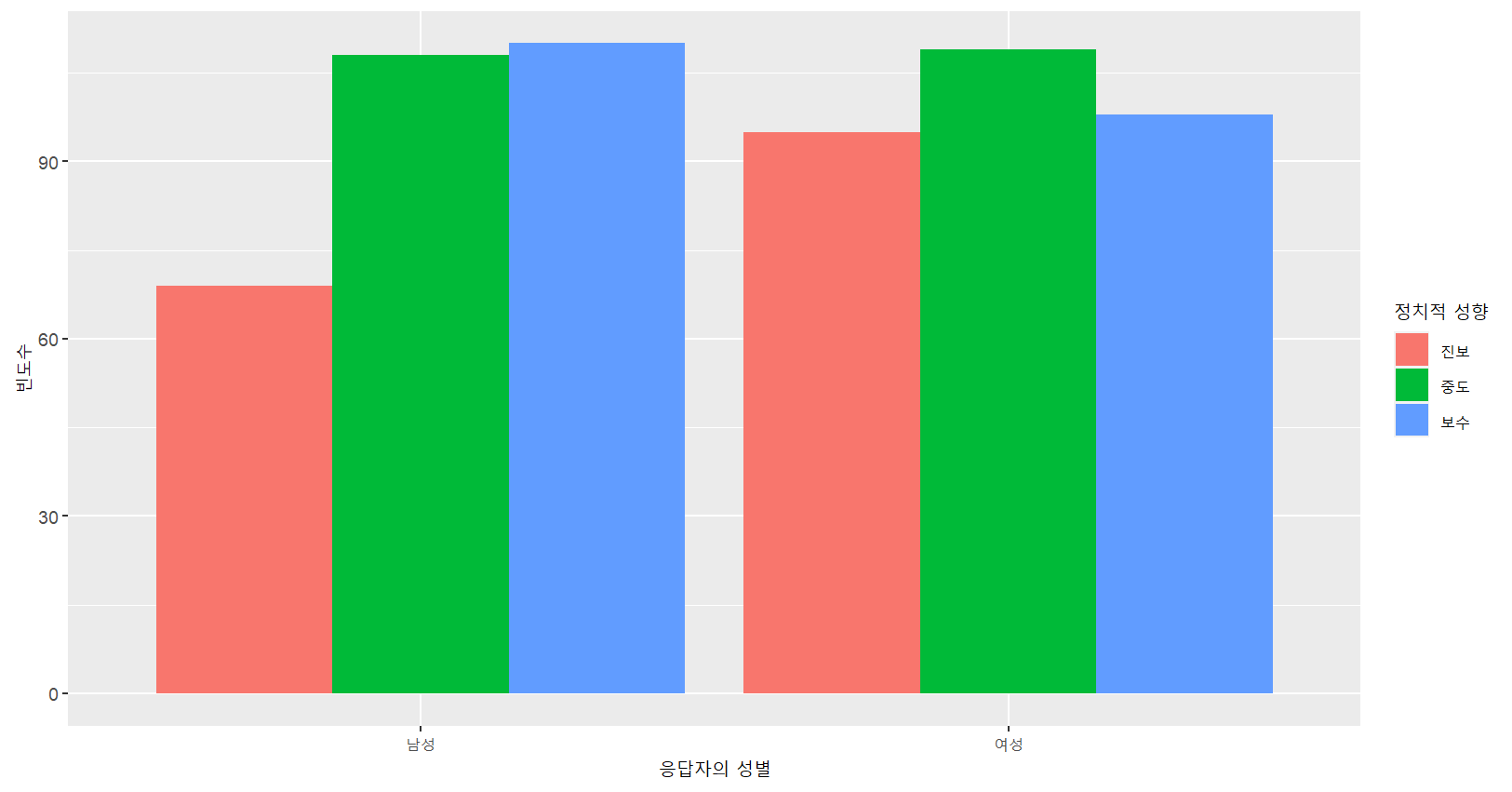
# 정치적 성향을 X축에, 성별을 범례로
ggplot(myresult,aes(x=‘as_factor(libcon3)’, y=n, fill=‘as_factor(female)’))+
geom_bar(stat="identity", position="dodge")+
labs(x="정치적 성향",y="빈도수",fill="응답자의 성별")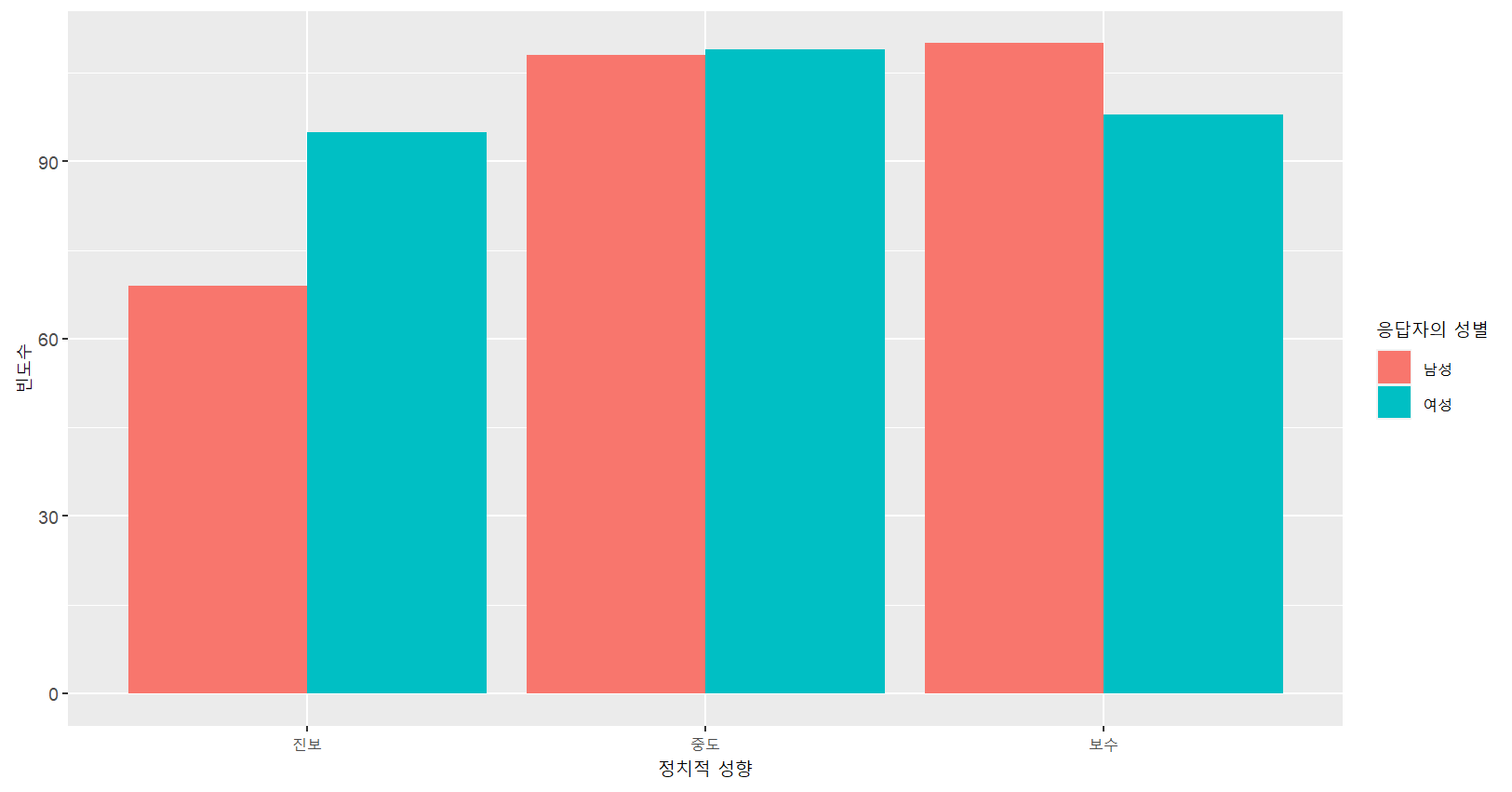
3. 두 개의 범주형 변수들을 교차한 빈도분석 : Unbalanced 인 경우
- 두 범주형 변수의 크기가 차이가 많이 나는 경우
- 예. 남자 : 200명(80%), 여자 : 50명(20%)
- 데이터의 비율이 Unbalanced인 경우 : 빈도를 제시하는 것보다는 상대적 비율(proportion, %)을 제시
1. Proportion을 계산한 결과를 저장한 뒤 시각화
# 정치적 성향별 남녀 퍼센트 계산
myresult %>%
spread(key=`as_factor(libcon3)`,value=n) %>%
mutate_if(
is.integer,
funs(100*(./sum(.)))
)#. A tibble: 2 × 4
as_factor(female)진보 중도 보수
1 남성 42.1 49.8 52.9
2 여성 57.9 50.2 47.1
#. A tibble: 2 × 4
as_factor(female)진보 중도 보수
1 남성 69 108 110
2 여성 95 109 98
2. position=“fill” 옵션을 이용하여 막대그래프를 빈도에서 비율로 전환
# 만약 성별 내부의 정치적 성향 응답자 비율을 표시
ggplot(myresult,aes(x=`as_factor(libcon3)`, y=n, fill=`as_factor(female)`))+
geom_bar(stat="identity", position="fill")+
labs(x="정치적 성향",y="응답자 비율",fill="응답자의 성별")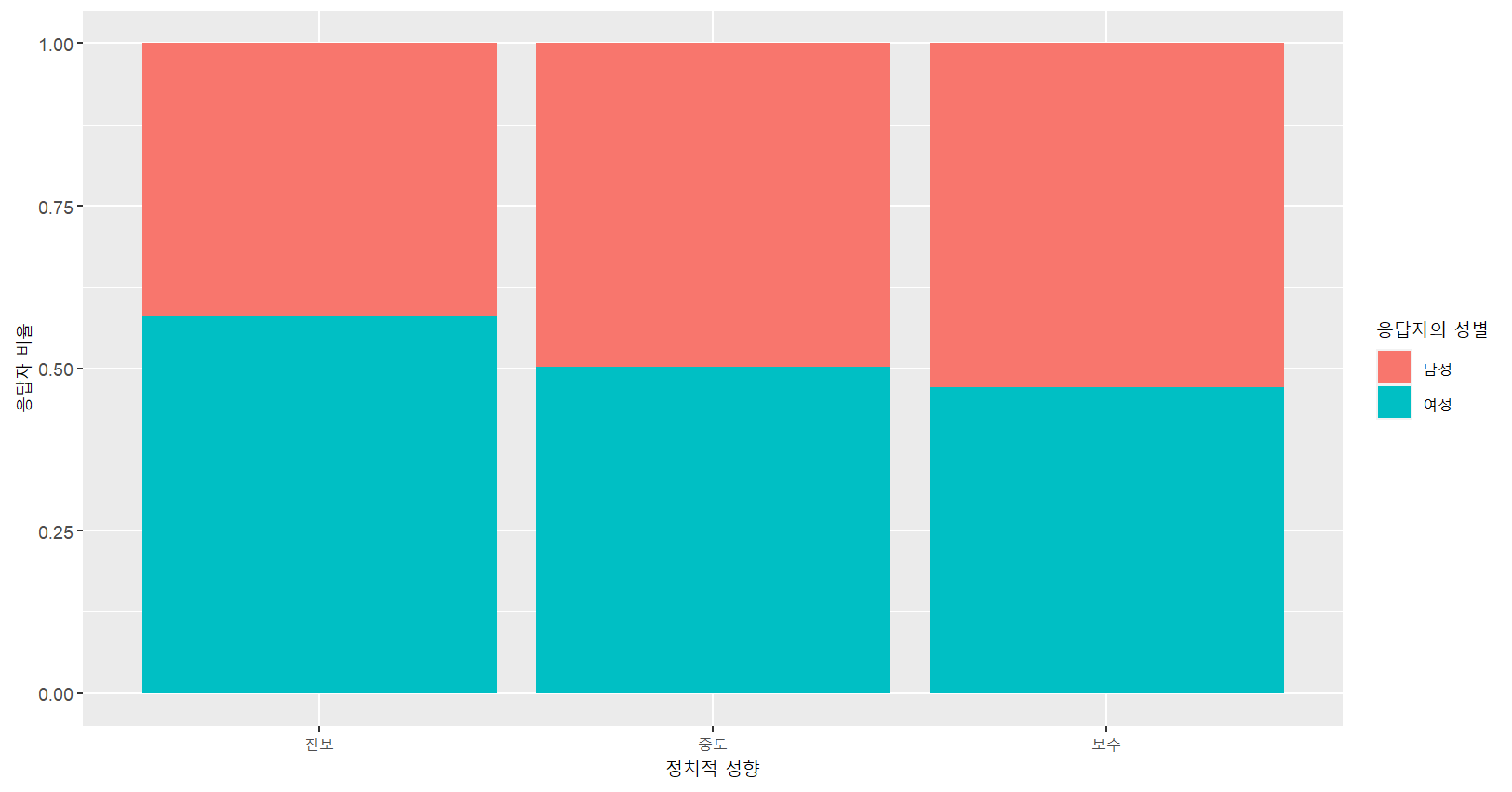
# 정보 추가
(1) Y축을 비율이 아닌 %로 변환
(2) 응답자의 성렬 범례를 그래프 상단부로 위치 변경
# 그래프에 대한 추가작업
ggplot(myresult,aes(x=`as_factor(libcon3)`, y=n, fill=`as_factor(female)`))+
geom_bar(stat="identity", position="fill")+
labs(x="정치적 성향", y="응답자 퍼센트", fill="응답자의 성별")+
scale_y_continuous(breaks=0.2*(0:5),
labels=str_c(20*(0:5),"%",sep=""))+
theme(legend.position="top")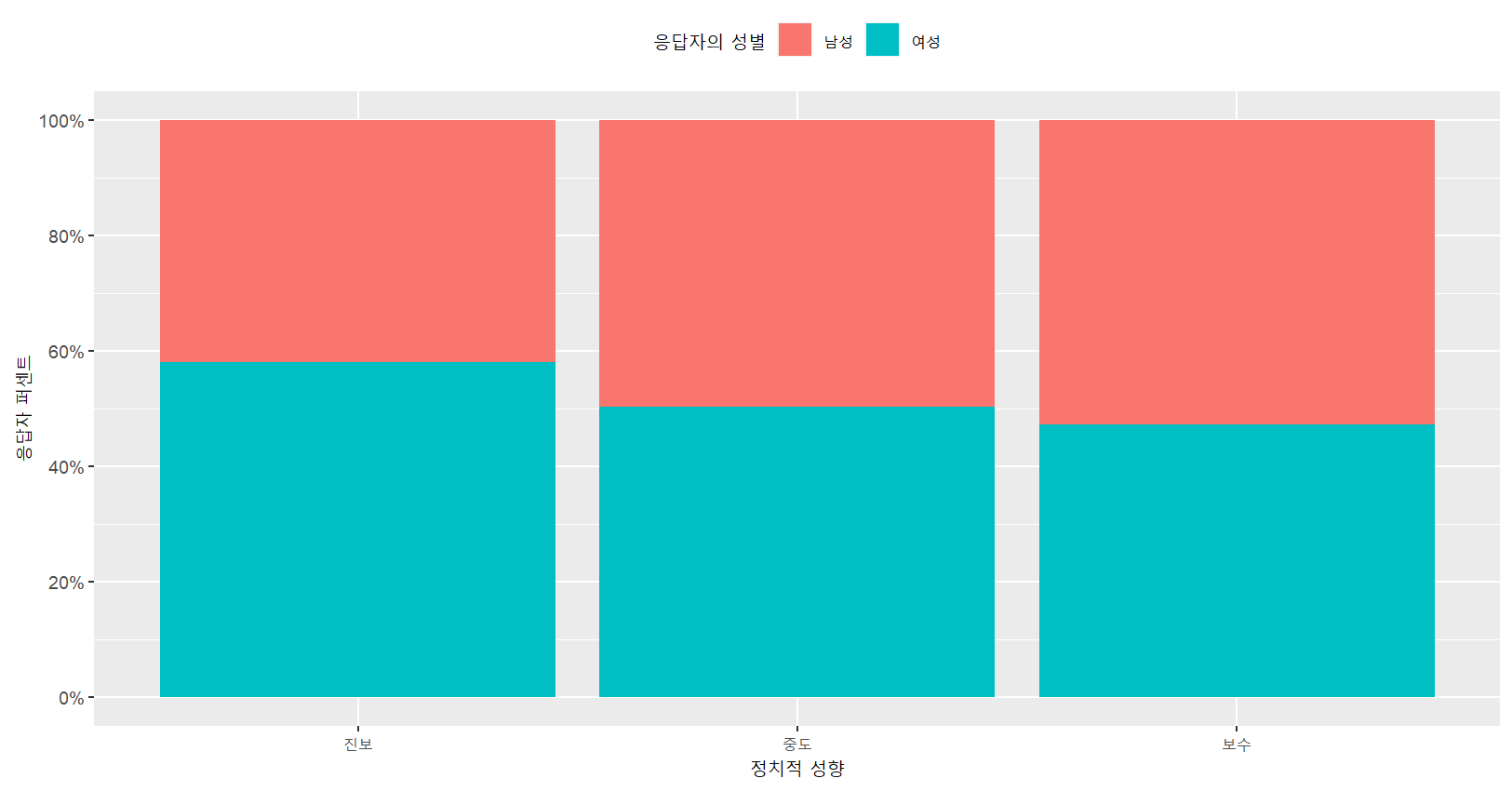
4. 3개의 범주형 변수들을 교차한 빈도분석
Q. 응답자의 정치적 성향과 성별의 관계가 인종에 따라 어떻게
다른가?
# 정치적 성향(진보, 중도, 보수), 성별(남성, 여성)에 인종 변수 추가
# 인종 변수(PPETHM)을 다수인종(백인)과 소수인종(그 외 모두)로 리코딩
mydata = mydata %>%
mutate(
white=ifelse(PPETHM==1,1,0),
white=labelled(white,c(다수인종=1,소수인종들=0))
)
myresult = mydata %>%
count(as_factor(white),as_factor(female),as_factor(libcon3))
myresult# A tibble: 15 × 4
`as_factor(white)` `as_factor(female)` `as_factor(libcon3)` n
<fct> <fct> <fct> <int>
1 소수인종들 남성 진보 21
2 소수인종들 남성 중도 24
3 소수인종들 남성 보수 15
4 소수인종들 남성 NA 1
5 소수인종들 여성 진보 26
6 소수인종들 여성 중도 27
7 소수인종들 여성 보수 16
8 소수인종들 여성 NA 1
9 다수인종 남성 진보 48
10 다수인종 남성 중도 84
11 다수인종 남성 보수 95
12 다수인종 남성 NA 2
13 다수인종 여성 진보 69
14 다수인종 여성 중도 82
15 다수인종 여성 보수 82# 결측값 제거 후 넓은 형태 데이터 교차표로 정리
myresult %>%
drop_na() %>%
spread(key=`as_factor(libcon3)`,value=n)
# A tibble: 4 × 5
`as_factor(white)` `as_factor(female)` 진보 중도 보수
<fct> <fct> <int> <int> <int>
1 소수인종들 남성 21 24 15
2 소수인종들 여성 26 27 16
3 다수인종 남성 48 84 95
4 다수인종 여성 69 82 82# 인종변수 수준에 따라 정치적 성향집단별 남녀 응답자 퍼센트
myresult %>%
drop_na() %>%
group_by(`as_factor(white)`) %>%
spread(key=`as_factor(libcon3)`,value=n) %>%
mutate_if(
is.integer,
funs(100*(./sum(.)))
)# A tibble: 4 × 5
# Groups: as_factor(white) [2]
`as_factor(white)` `as_factor(female)` 진보 중도 보수
<fct> <fct> <dbl> <dbl> <dbl>
1 소수인종들 남성 44.7 47.1 48.4
2 소수인종들 여성 55.3 52.9 51.6
3 다수인종 남성 41.0 50.6 53.7
4 다수인종 여성 59.0 49.4 46.3# 패시팅을 이용한 데이터 시각화
myresult %>%
drop_na() %>%
ggplot(aes(x=`as_factor(female)`,y=n,fill=`as_factor(libcon3)`))+
geom_bar(stat='identity’, position="fill")+
labs(x="응답자의 성별",y="응답자 퍼센트",fill="정치적 성향")+
scale_y_continuous(breaks=0.2*(0:5),
labels=str_c(20*(0:5),"%",sep=""))+
theme(legend.position="top")+
facet_grid(.~`as_factor(white)`) 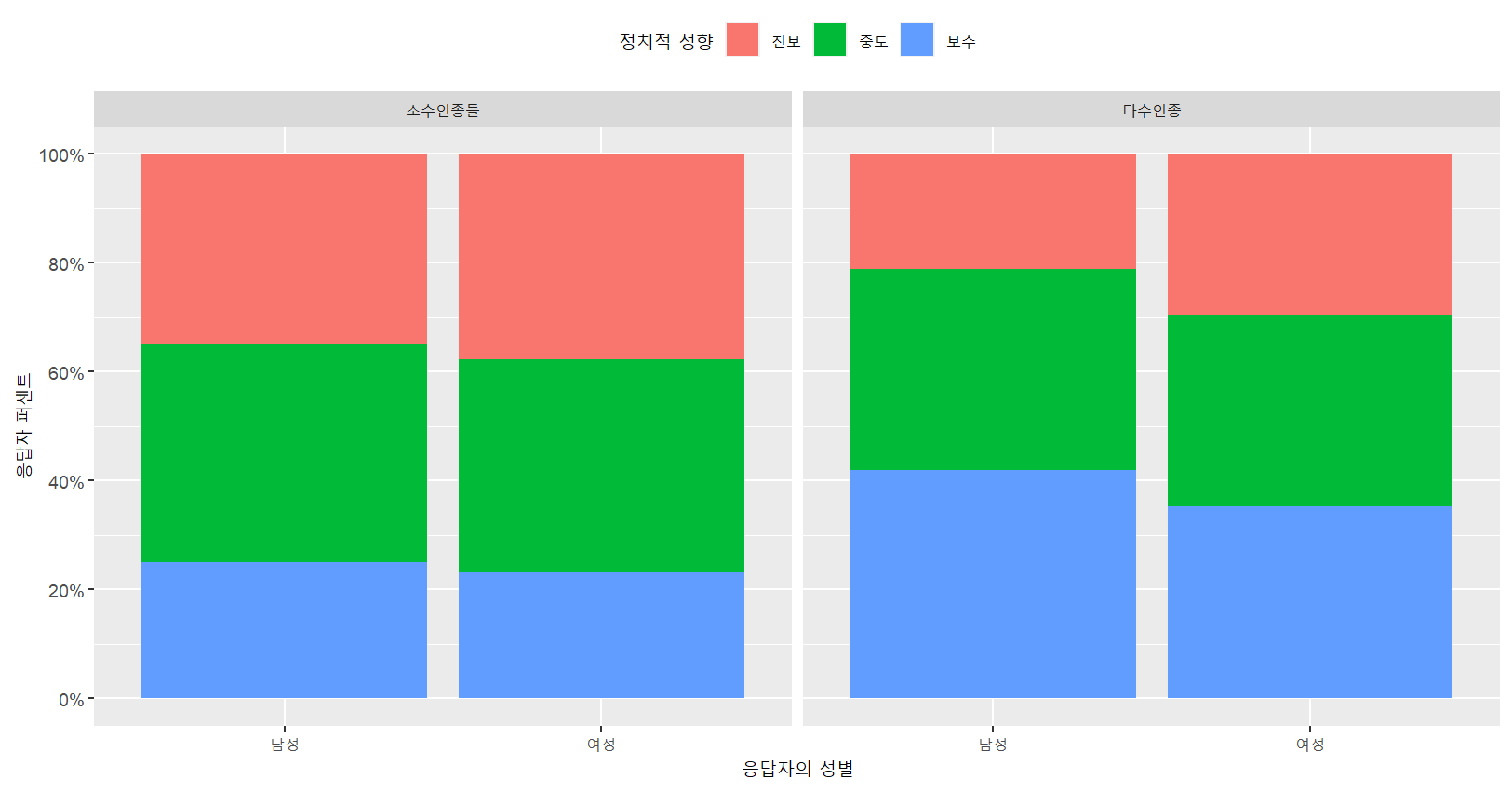
Q. 응답자의 정치적 성향과 성별의 관계가 인종과 연령에 따라
어떻게 다른가?
# 패시팅을 하면 4개 이상의 명목변수들도 고려할 수 있음
# 연령을 추가적으로 고려
# 50세 이하를 저연령층, 51세 이상을 고연령층으로 구분
mydata = mydata %>%
mutate(
gen2=as.double(cut(PPAGE,c(0,50,99),1:2)),
gen2=labelled(gen2,
c(`저연령(50세 이하)`=1,`고연령(51세 이상`=2))
)
myresult = mydata %>%
count(as_factor(gen2),as_factor(white),
as_factor(female),as_factor(libcon3))# 패시팅을 하면 4개 이상의 명목변수들도 고려할 수 있지만 권장하지 않음
myresult %>% drop_na() %>%
ggplot(aes(x=`as_factor(female)`,y=n,fill=`as_factor(libcon3)`))+
geom_bar(stat='identity',position="fill")+
labs(x="응답자의 성별",y="응답자 퍼센트",fill="정치적 성향")+
scale_y_continuous(breaks=0.2*(0:5),
labels=str_c(20*(0:5),"%",sep=""))+
theme(legend.position="top")+
facet_grid(`as_factor(gen2)`~`as_factor(white)`)
ggsave("freq_gender_ideo_race_generation.jpeg",
width=16,height=16,units="cm") 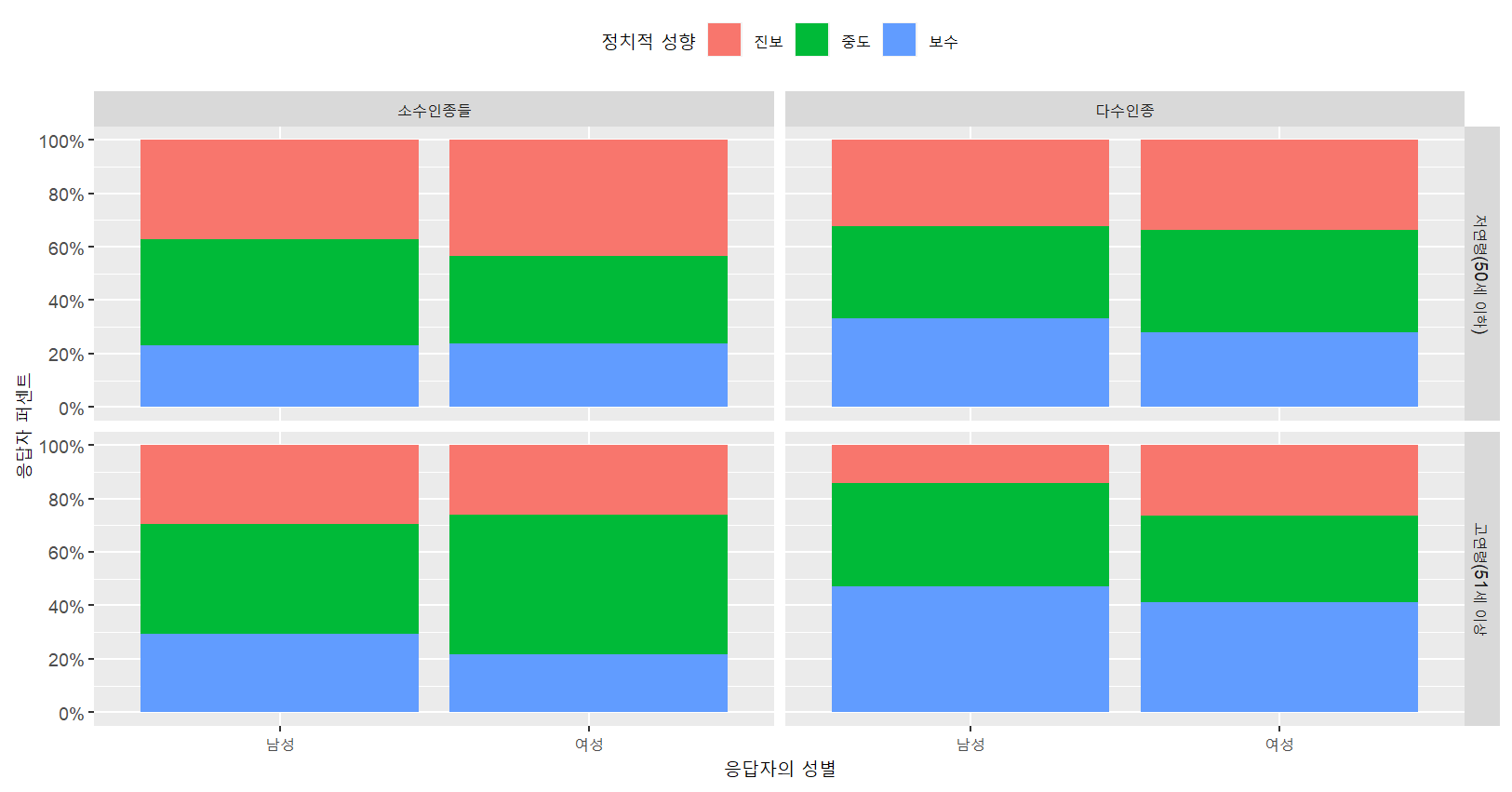

DRUDGER