4. 데이터프레임 다루기(고급)
메서드 결합
여러 개의 메서드 호출을 한 줄로 연결하여 사용하는 프로그래밍 기법으로 코드를 더 간결하고 가독성 있게 작성 가능
메서드 결합의 핵심 아이디어는 한 객체나 데이터 구조에 대해 연속적으로 메서드를 호출
메서드 : 객체(Object) 지향 프로그래밍에서 사용되는 용어로, 객체의 행동(behavior)을 정의하고 구현하는 함수와 비슷한 개념
df = pd.DataFrame({'name':['Kim','Lee','Park','Kim','Lee','Kim']
, 'sex':['M','F','F','M','F','M']
, 'age':[20,25,30,20,25,20]
, 'class':['DS','DS','DS','PP','PP','DV']})
print(df)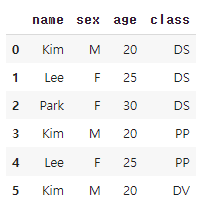
다음과 같은 데이터 프레임이 존재할때,
class별 수강학생수
df.groupby(by='class')['name'].count()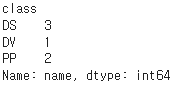
-> 데이터프레임을 'class' 열로 그룹화하고, 각 그룹 내에서 'name' 열의 개수(행의 개수)를 세는 작업을 수행
학생별 수강교과목의 갯수
df.groupby(by=['name','sex','age'])['class'].count()
->데이터프레임을 'name', 'sex', 'age' 열을 기준으로 그룹화하고, 각 그룹 내에서 'class' 열의 개수(행의 개수)를 세는 작업을 수행
학생별 수강교과목이 2개 이상인 데이터만 필터링
df.groupby(by=['name','sex','age']).filter(lambda x: len(x)>=2)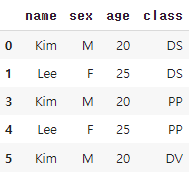
->데이터프레임을 'name', 'sex', 'age' 열을 기준으로 그룹화한 다음, 그룹의 길이(len(x))가 2 이상인 경우를 찾은다음, 'name', 'sex', 'age' 조합 중에서 두 번 이상 나타나는 조합만을 선택
2 class이상 수강하는 학생의 이름
df.groupby(by=['name','sex','age']).filter(lambda x: len(x)>=2)['name'].unique()
-> 데이터프레임을 'name', 'sex', 'age' 열을 기준으로 그룹화하고,같은 이름, 성별 및 나이를 가진 고객 중에서 두 번 이상 수강한 그룹을 선택,name' 열의 고유한 값을 추출
2 class이상 수강하는 학생의 평균나이
(df
.groupby(by=['name','sex','age'])
.filter(lambda x: len(x)>=2)[['name','age']]
.drop_duplicates()['age']
.mean())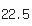
-> 데이터프레임을 'name', 'sex', 'age' 열을 기준으로 그룹화하고, 이름, 성별 및 나이를 가진 고객 중에서 두 번 이상 수강한 그룹을 선택,선택된 그룹에서 'name'과 'age' 열만을 선택, 중복된 행을 제거, age' 열의 고유한 값들을 추출, 추출된 'age' 값들의 평균을 계산
4.2 pandas 그래프
판다스는 Matplotlib 라이브러리의 기능을 일부 내장하고 있어 간단한 그래프를 그릴 수 있음
-
'line': 선 그래프를 생성
주로 시계열 데이터 또는 연속 데이터의 추세를 표시하는 데 사용 -
'bar': 수직 막대 그래프를 생성
주로 범주형 데이터의 빈도나 분포를 시각화하는 데 사용 -
'barh': 수평 막대 그래프를 생성
주로 범주형 데이터의 빈도나 분포를 수평으로 시각화하는 데 사용 -
'hist': 히스토그램을 생성
연속 데이터의 분포를 표시하고 이상치를 확인하는 데 사용 -
'box': 상자 그림 (박스 플롯)을 생성
데이터의 중앙값, 사분위수 및 이상치를 시각화하는 데 사용 -
'kde' / 'density': 커널 밀도 추정 플롯을 생성
연속 데이터의 확률 밀도 함수를 시각화하는 데 사용 -
'area': 영역 그래프를 생성
데이터의 영역 또는 누적 값을 표시하는 데 사용 -
'pie': 파이 차트를 생성
범주형 데이터의 상대적 비율을 나타내는 데 사용 -
'scatter': 산점도 그래프를 생성
두 변수 간의 관계를 표시하는 데 사용 -
'hexbin': 육각형 범위로 데이터를 시각화하는 hexbin 플롯을 생성
주로 밀도를 표시하거나 이상치를 확인하는 데 사용.
예시)
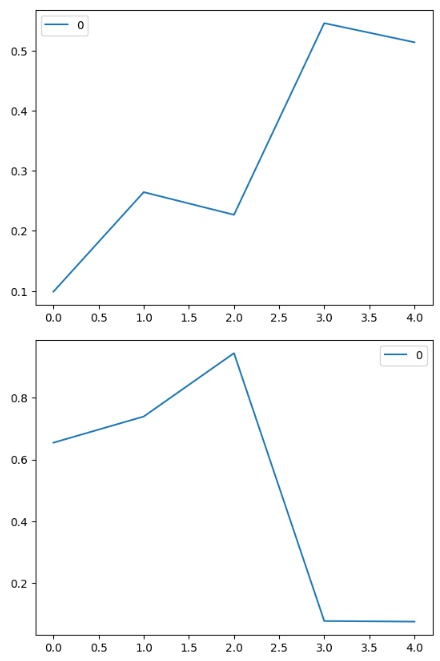
df1 = pd.DataFrame(np.random.rand(5))
print(df1.head())
df2 = pd.DataFrame(np.random.rand(5))
print(df2.head())데이터 프레임 생성

import matplotlib.pyplot as plt
#선언안해주면 NameError: name 'plt' is not defined 이렇게 오류가뜸
df1.plot()
df2.plot()
plt.title("랜덤 넘버 df1")
plt.show() 그래프그리기
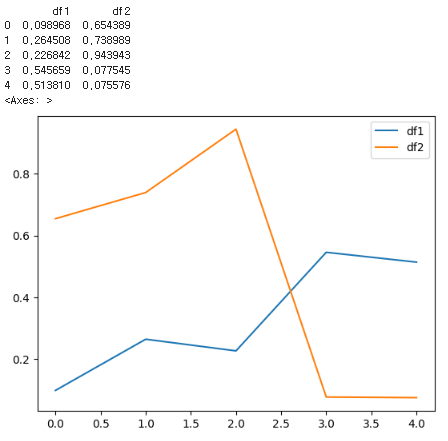
df = pd.concat([df1,df2], axis=1)
df.columns = ['df1', 'df2']
print(df.head())
df.plot()-> pd.concat([df1, df2], axis=1): pd.concat 함수를 사용하여 df1과 df2를 수평으로 합침
-> df.columns = ['df1', 'df2']: df 데이터프레임의 열 이름을 변경
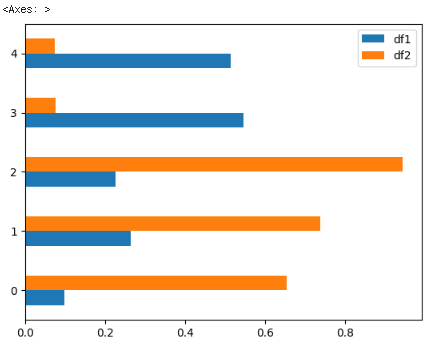
df.plot(kind='barh')df를 가로 막대 그래프(barh: horizontal bar plot)로 시각화하는 코드
df.plot(kind='area')df를 영역 그래프(area plot)로 시각화하는 코드
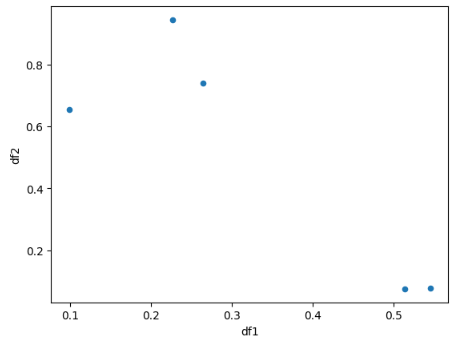
df.plot(kind='scatter', x='df1', y='df2')df를 산점도 그래프(scatter plot)로 시각화하는 코드
x='df1'과 y='df2' 파라미터는 x-축과 y-축에 어떤 열(또는 시리즈)을 사용할 것인지를 지정