
동아리 문의 해결을 위한 AI 챗봇 프로젝트에 관한 글입니다.
배경
현재까지 동아리 에코노베이션에 관한 문의는 다음 방식을 통해서 이루어집니다
- 에코노베이션 홈페이지 CONTACT https://econovation.kr/contact
- SNS ( 카카오톡, 인스타그림, 에브리타임 등)
이런 문의 방식에서 다음과 같은 불편한 점을 발견하였습니다.
- 상담직원 대기로 인한 응답 시간 지연
- 다수의 중복된 질문
- 정보 탐색 노동 필요
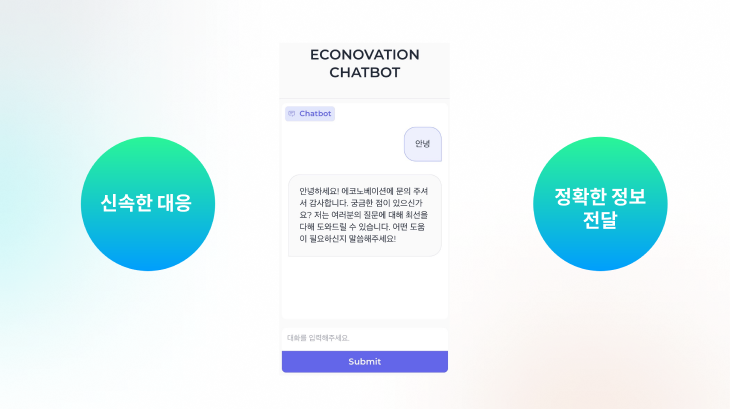
따라서 신속한 대응과 정확한 정보 전달을 목표로 챗봇 프로젝트를 시작하였습니다.
👏👏
RAG
RAG(Retrieval-Augmented Generation)은 Knowledge Intensive Task를 해결하기 위한 정보 검색과 생성이 결합된 모델입니다. 해당 프로젝트의 Task는 주어진 질문에 대한 답을 문서에서 찾는 ODQA(Open Domain Question Answering)입니다.
RAG 기반 모델 선택 이유
동아리 문의 해결이라는 특정 목적을 둔 챗봇으로 할루시네이션 현상을 우려하였습니다. 가지고 있는 데이터의 크기를 고려하여 파인튜닝보다 RAG를 선택하게 되었습니다.
과정
STEP 1
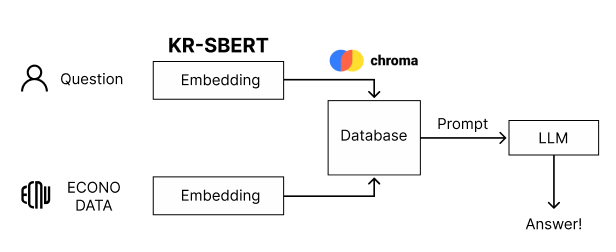
관련 문서를 임베딩을 통해 벡터 형식으로 벡터 데이터베이스에 저장합니다.
ChromaDB 선택 이유
프로젝트를 진행하면서 여러 벡터 데이터 베이스 중에서 Pinecone과 ChromaDB를 시도해보았습니다. 프로젝트의 확장성을 고려해보았을 때 크로마디비가 적합하다고 판단하였고 파인콘의 비용과 제한된 기능으로 인해 결과적으로 크로마디비를 선택하였습니다.
STEP 2
사용자가 질문을 인풋으로 입력하면 임베딩을 거쳐 데이터베이스에서 가장 유사한 데이터를 검색합니다.
KR-SBERT 선택 이유
해당 모델은 증강된 센텐스버트 모델입니다. STS(Semantic Textual Similarity) 문장이 유사한지를 구하는 task에서 성능을 올리기 위해서 KorSTS데이터를 증강하였습니다. 이로부터 쿼리를 분류하는 task를 가진 RAG에 적합하다고 판단하여 선택하게 되었습니다.
STEP 3
검색한 결과를 가지고 프롬프트를 작성하여 LLM에 전달합니다. LLM은 이를 바탕으로 답변을 생성합니다.
프롬프트에 관해서는
전달받은 결과를 가지고서만 답변을 생성하도록 하였고 전달받은 데이터를 가지고 답변이 어렵다고 판단될 경우에는 상담직원을 연결하도록 하였습니다.
또한, 유사도가 낮아 전달받은 결과가 없을 경우에는 특정 답변을 지정하였습니다.
결과
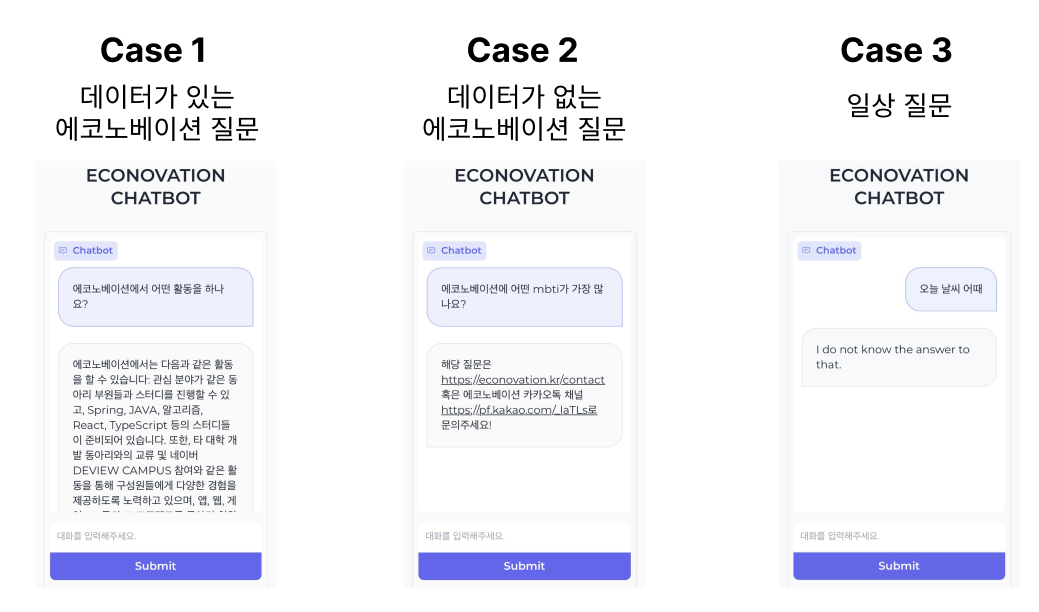
다음과 같은 세 가지 경우에 대해서 결과를 확인하였습니다.
-
정확한 답변이 준비되어 있는 에코노베이션 질문에 대해서 올바르게 답변하는 것을 확인하였습니다.
-
준비되지 않은 에코노베이션 질문에 관해서는 상담 직원을 연결하였습니다.
-
에코노베이션 관련 질문이 아닌 일상 대화의 경우 답변하지 않도록 하였습니다.
웹 구현은 그라디오와 스트림릿을 사용하였습니다.
이 두 라이브러리는 배포 또한 지원합니다.
모델 개선
RAG 모델에서
- 10초가 넘는 응답시간
- 증강된 데이터로 인한 무조건적 검색
2가지 문제를 발견하였습니다.
이를 파시스를 통해 개선하였습니다.
Faiss
Facebook AI에서 개발한 유사도 검색 모델
Faiss는 밀집 벡터의 효율적인 유사성 검색 및 클러스터링을 위한 라이브러리입니다. 인덱싱, 벡터 양자화 기능을 제공하며 쿼리가 들어왔을 때 가장 가까운 cluster를 방문하여 유사도가 높은 벡터를 빠르게 검색할 수 있습니다.
1. 성능 최적화
10초가 넘는 응답시간 지연 문제를 직면하였고 파시스를 통해
평균적으로 약 1.5배 정도 빨라진 것을 확인하여 개선하였습니다.
또한, 파시스는 대량의 벡터 데이터에 엄청난 성능 향상을 보이므로 앞으로 확장된 에코노 데이터를 고려했을 때 기대 효과가 있습니다.
2. 유사도 조절
증강된 데이터로 인한 무조건적 검색이 일어나 일상 대화를 제대로 분류하지 못하는 문제가 있었습니다.
파시스를 통해 벡터 간 유사도를 확인하여 유사도 거리 1.1 이하인 것에 대해서만 결과로 전달하도록 하여 조정하였습니다.
느낀 점
리소스 문제로 LLM에서 KoAlpaca를 사용하지 못해 아쉬웠다. 경량화를 공부해서 최적화해서 FlaskAPI로 카카오톡 채널 챗봇 배포를 하고 싶다.
챗봇이라는 주제로 자연어 분야에서 공부할 수 있는 것이 많아 좋았다. 자연어 처리는 강화학습이나 멀티모달 등 다른 분야와 확장성이 좋은 주제인 것 같다.

멋지네요~~