Grafana를 사용해 MSA 서버 모니터링 구축하기 (Loki, Tempo, Prometheus)
입사 후 처음으로 맡게 된 신규 프로젝트에서 서버와 서비스 모니터링을 위해 Grafana를 선택한 이유와 이를 구축한 방법을 공유하고자 합니다.
서버 시스템 모니터링 구축에는 일반적으로 솔루션 사용과 오픈소스를 이용한 방법이 있습니다. 솔루션을 구매하는 방법도 있지만, 2023년부터 회사 내 AWS에서 불필요한 리소스를 정리하고 비용을 절감하기 위한 노력이 있었기에, 비용 절감과 비교적 높은 자유도를 위해 오픈소스인 Grafana를 사용하기로 결정했습니다.
왜 Grafana를 선택 했는가?
Prometheus, Zabbix, Loki, CloudWatch, Scouter, PinPoint 등 다양한 오픈소스 모니터링 툴이 존재합니다. 각 역할에 맞는 오픈소스를 선택하여 사용할 수 있지만 그럴 경우 각 오픈소스마다 대시보드가 나뉘어 있고, 유지보수가 쉽지 않다고 판단했습니다.
그래서 선택에 있어서 최우선 조건은 '단일 대시보드'였습니다.
시스템 모니터링, 로그 모니터링, 경고 알람, 분산 트레이싱 등 모든 기능을 한 대시보드에서 확인할 수 있고, 이 모든 것을 지원하는 Grafana를 선택하게 되었습니다. 또한, Grafana에서 제공하는 Loki, Tempo를 함께 사용하면 더욱 강력한 연동성을 보여줄 것으로 기대했습니다.
Grafana에서 제공하는 툴을 줄여서 LGTM Stack이라고 부르고 있습니다. Loki, Grafana, Tempo, Mimir 4가지로 구성되어있지만 이번 모니터링 구축에서는 Mimir를 대신해 Prometheus를 사용하고 추후에 Mimir로 변경하기로 결정했습니다.
각 도구에 대해 간단하게 알아봅시다.
Grafana - 대시보드
Grafana는 오픈소스 분석 및 시각화 도구입니다. Loki, Prometheus, ElasticSearch, Jaeger 등 다양한 모니터링 시스템을 데이터 소스로 연결할 수 있고 각 플랫폼에 맞는 설정 혹은 언어를 통해 데이터를 조회하고 이를 기반으로 대시보드를 구성할 수 있습니다.
Panel들은 Json 형태로 관리되며 이미 생성되어 배포되는 다른 패널들을 쉽게 가져와서 사용할 수도 있고 직접 나만의 대시보드를 만들 수 있습니다.
높은 자유도와 다양한 플랫폼에 대한 연결을 지원하는 점이 Grafana를 선택하게된 가장 큰 이유가 되었습니다.

Loki - 로그 모니터링
Loki는 Grafana Labs에서 개발된 로깅 시스템입니다. Grafana Labs에서는 Scalability, Multi-tenancy, Third-party integrations, Efficient storage 등을 장점으로 설명하고 있습니다.
가장 중요하게 본 장점은 쉽게 설정 가능한 외부 저장소 그리고 쉽게 시스템을 구성하여 사용할 수 있다는 점입니다.
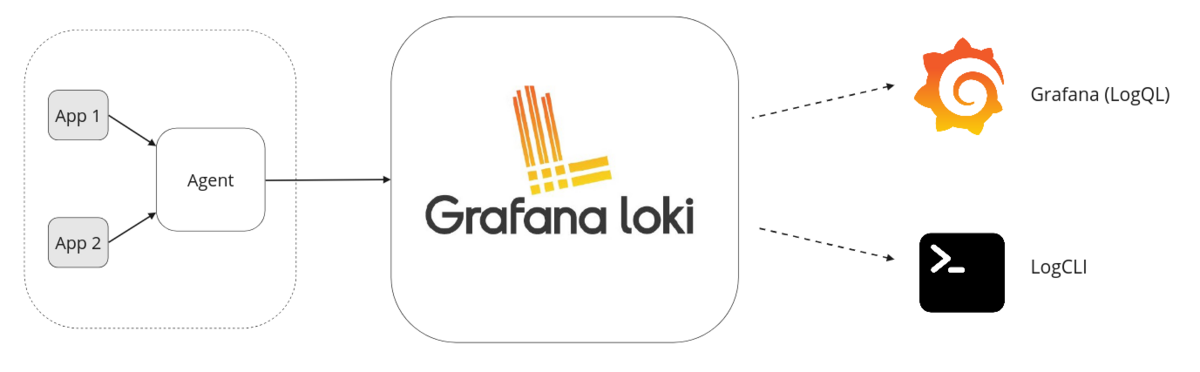
Loki는 크게 Agent와 Loki, Grafana 3단계로 구성되어있습니다.
- Agent - 로그 수집이 필요한 각 서버에서 로그 파일을 Loki로 전송해주는 역할을 담당합니다. 일반적으로는 Promtail을 가장 많이 사용합니다.
- Loki - agent로부터 전달 받은 로그의 메타데이터만을 분석하고 압축하여 작은 Chunk 단위의 파일을 저장합니다. 이때 Chunk 파일이 저장되는 장소로 S3, GCS, Azure blob storage 등 다양한 선택지를 제공합니다.
- Grafana - LogQL을 사용하여 최종적으로 수집된 로그를 조회하기 위해 Grafana 대시보드를 사용합니다.
Prometheus - 메트릭 정보 수집
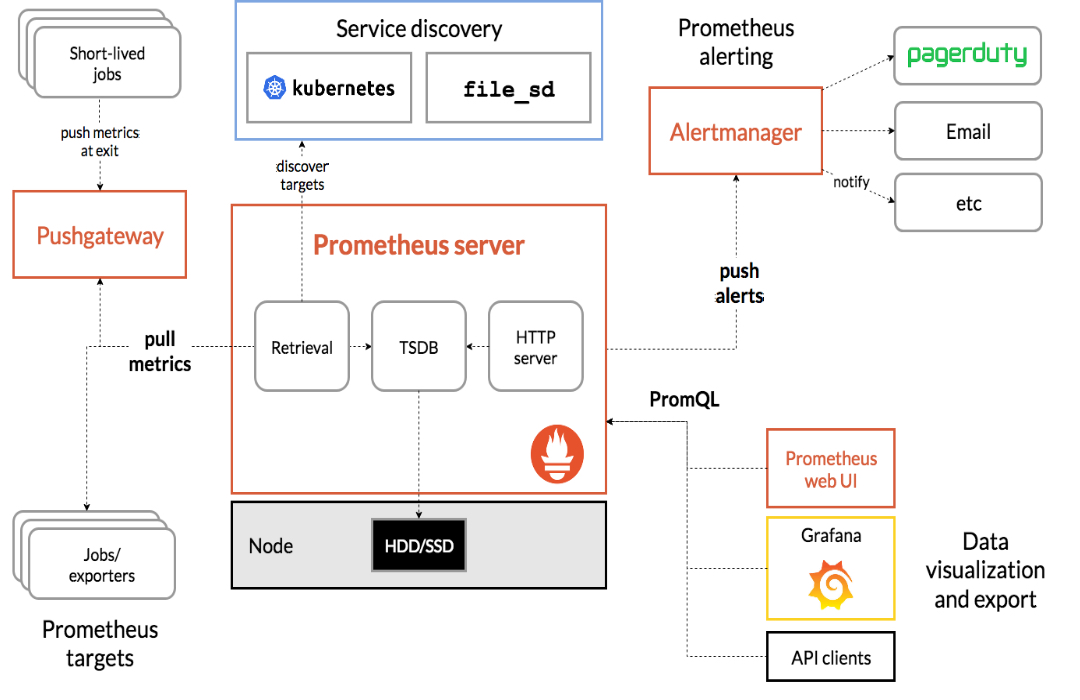
Prometheus는 SoundCloud에서 개발된 메트릭 정보를 기반으로 하는 오픈소스 모니터링 시스템입니다. 서비스 자체에서 메트릭 정보를 지원하는 k8s, istio 등과 추가로 세팅하여 사용하는 3rd party Exporter 도구들을 통해 모니터링을 위한 각종 데이터를 수집하고 시계열 데이터베이스에 저장합니다.
저장된 정보는 PromQL을 통해 조회할 수 있고 사용자가 원하는 조건에 따라 Alert를 보내 장애 파악 및 대응에 도움을 줍니다.
Tempo - 분산 추적 시스템
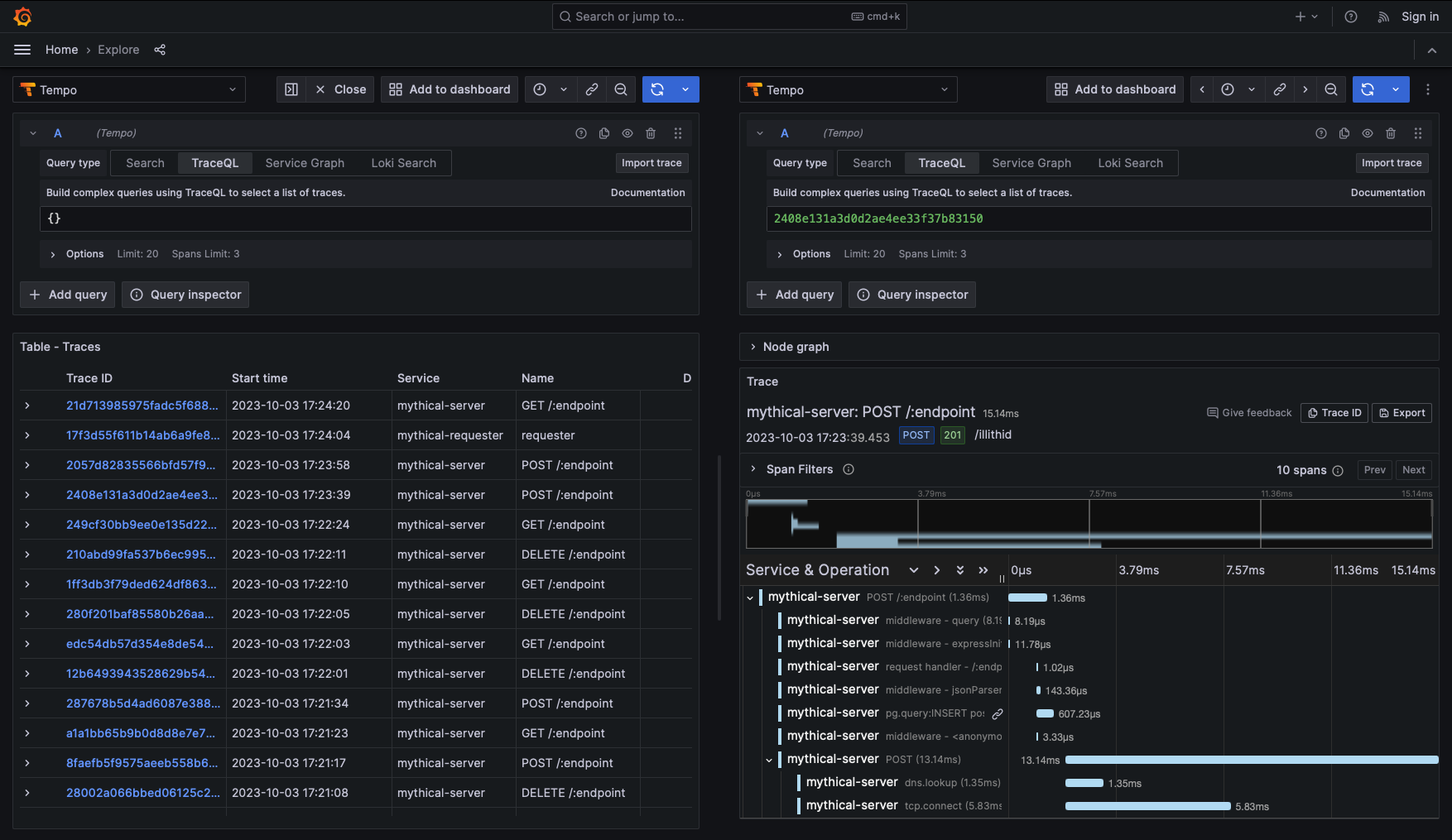
Tempo의 분산 추적은 일련의 요청이 어플리케이션에서 처리될 때의 생명주기를 시각화할 수 있게 도와줍니다.
Grafana, Prometheus 또는 Mimir, Loki와 연동되고 Jaeger, Zipkin, opentelemetry 등과 같은 오픈소스와도 함께 사용할 수 있습니다.
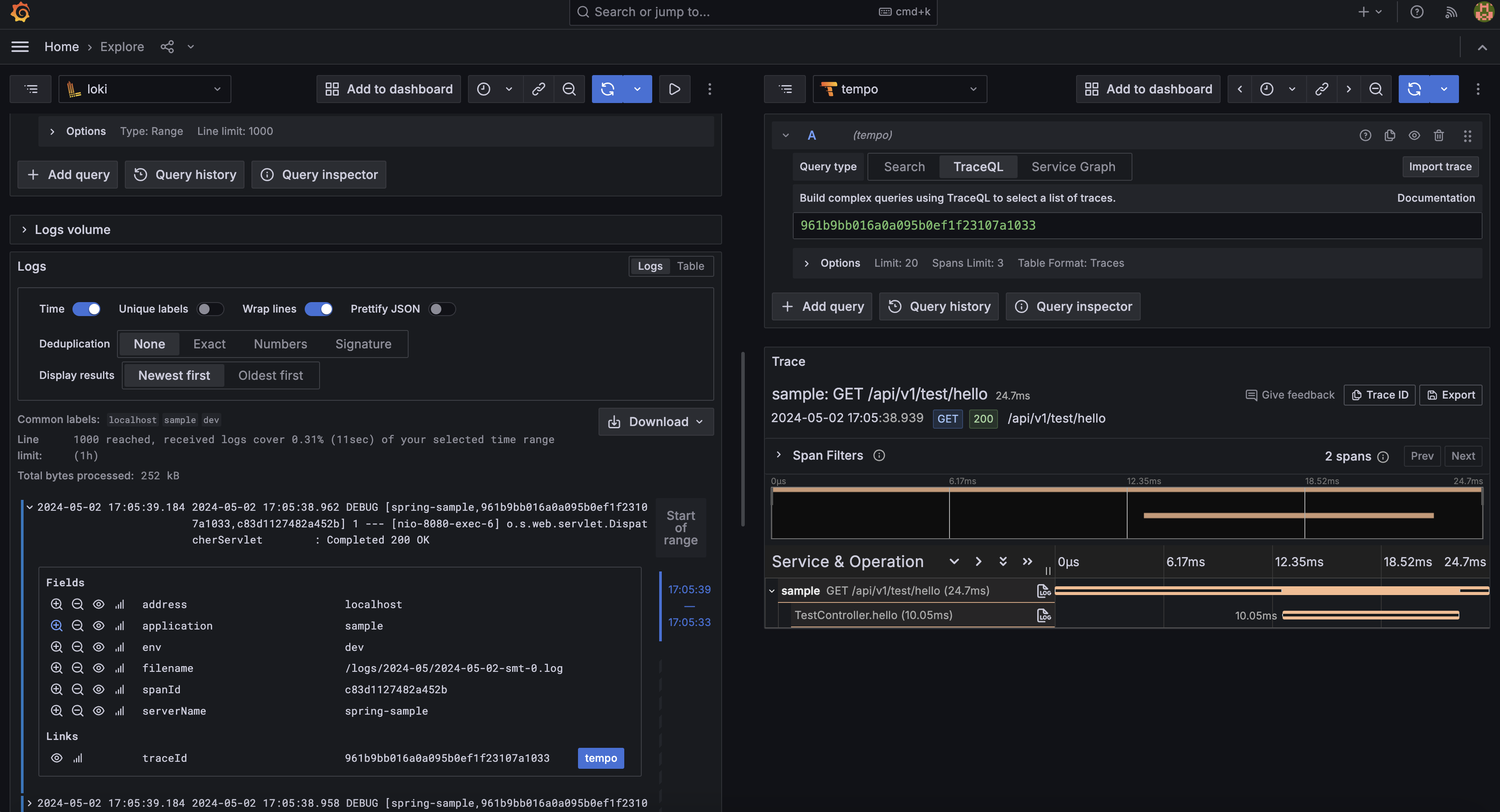
서버에서 기록되는 각 로그에 trace id와 span id가 부여되고 수집된 로그에서 해당 값들을 추적하여 특정 요청의 흐름을 추적할 수 있습니다. Loki와 Prometheus와 연동한다면 문제가 되는 로그 혹은 지표에서 바로 추적을 사용할 수 있고 이는 MSA 형태로 구성된 서비스에서 에러 추적에 많은 도움을 줄 것이라 생각되어 꼭 사용해보고 싶었던 서비스입니다.
Docker로 모니터링 시스템 구축해보기
모니터링 시스템 구축에 사용된 코드는 Github Repository 에서 확인 가능합니다.
모니터링 대상 서버 구성 : Spring Cloud Gateway, Eureka Discovery Service, Docker
모든 모니터링 시스템은 추후 확장 및 이동 그리고 버전 관리를 위해 Docker 이미지 기반으로 구성하였습니다.
준비사항
- Docker 및 Docker Compose 설치
Grafana 설치
- docker-compose.yml 파일 작성
version: '3.8'
services:
grafana:
image: grafana/grafana:latest
container_name: grafana
environment:
- TZ=Asia/Seoul
ports:
- "3000:3000"
volumes:
- ./grafana/volume:/var/lib/grafana
- ./grafana/config/grafana.ini:/etc/grafana/grafana.ini:ro
restart: always- 도커 내부 파일과 폴더를 연결해주기 위해 ./grafana/config와 ./grafana/volume 폴더를 생성
- grafana.ini 파일 생성
필요로 하는 옵션은 Grafana 문서 페이지에서 확인 가능합니다.
app_mode = production
[server]
protocol = http
http_addr =
http_port = 3000
[log]
mode = console
level = info
[unified_alerting]
enabled = true
[unified_alerting.screenshots]
capture = true
upload_external_image_storage = true
[alerting]
enabled = false
[external_image_storage]
provider = local
[feature_toggles]
newVizTooltips = truedocker-compose up -d명령어를 통해 실행http://localhost:3000로 접속
기본 계정인admin/admin으로 접속하여 초기 비밀번호 설정
Prometheus 설치
- docker-compose.yml 파일 작성
version: '3.8'
services:
prometheus:
image: prom/prometheus:main
container_name: prometheus
volumes:
- ./prometheus/config:/etc/prometheus
- ./prometheus/volume:/prometheus
ports:
- 9090:9090
command:
- '--web.enable-lifecycle'
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-remote-write-receiver'
- '--enable-feature=exemplar-storage'
- '--storage.tsdb.retention=7d'
restart: always
environment:
- TZ=Asia/Seoul
logging:
driver: "json-file"
options:
max-size: "8m"
max-file: "10"- 도커 내부 파일과 폴더를 연결해주기 위해 ./prometheus/config와 ./prometheus/volume 폴더를 생성
- prometheus/config/prometheus.yml 파일 생성
필요로 하는 옵션은 Prometheus 문서 페이지에서 확인 가능합니다. docker-compose up -d명령어를 통해 실행http://localhost:9090로 접속하면 프로메테우스 메인 페이지를 확인할 수 있습니다.
node-exporter 설치
서버의 메트릭 정보를 수집하기 위해서 node-exporter를 설치하고 Promtheus와 연결해보겠습니다.
1. docker-compose.yml 파일 작성
version: '3.8'
services:
node:
image: prom/node-exporter
container_name: node-exporter
ports:
- "9100:9100"
restart: alwaysdocker-compose up -d명령어를 통해 실행- 기존에 생성한 prometheus.yml 파일에 scrape_configs 설정 추가
node-exporter를 job_name으로 지정하고 targets에 node-exporter가 실행되고 있는 주소를 입력합니다. 여러대의 서버를 모니터링하고 싶다면 targets에 추가로 등록해줍니다.직접 서버 주소를 모두 등록할수도 있지만 프로메테우스는 docker_sd_configs, ec2_sd_configs, eureka_sd_configs 등 다양한 설정을 제공합니다. 이를 통해서 node-exporter가 실행되는 서버들을 자동으로 등록하여 편리하게 모니터링도 가능합니다.
global:
scrape_interval: 15s
scrape_timeout: 15s
evaluation_interval: 2m
external_labels:
monitor: 'monitor'
query_log_file: query_log_file.log
rule_files:
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['host.docker.internal:9100']
# targets에 node-exporter가 실행된 서버의 IP 혹은 도메인 주소를 넣으면 되지만 현재는 같은 디바이스에서 docker를 통해 실행중이기 때문에 host.docker.internal를 통해 설정해주었습니다.- Prometheus 설정 적용
docker-compose restart prometheus를 통해 재시작시 설정이 적용됩니다.
curl -X POST http://localhost:9090/-/reload다음 명령어를 통해 Prometheus에 reload를 호출해주면 재시작 없이 설정만 적용시킬 수 있습니다. - Grafana 연결
Grafana > Connections > Data sources > Prometheus 를 선택하여 연결할 수 있습니다.
Prometheus server URL에http://host.docker.internal:9090을 입력해주고 Save & Test 버튼을 통해 설정을 완료합니다.같은 디바이스가 아니라면 host.docker.internal 대신 prometheus가 설치된 서버의 주소를 통해 연결 가능합니다.
- Grafana 대시보드 생성
Home > Dashboards > New > Import 를 통해 Node-exporter를 추가합니다.
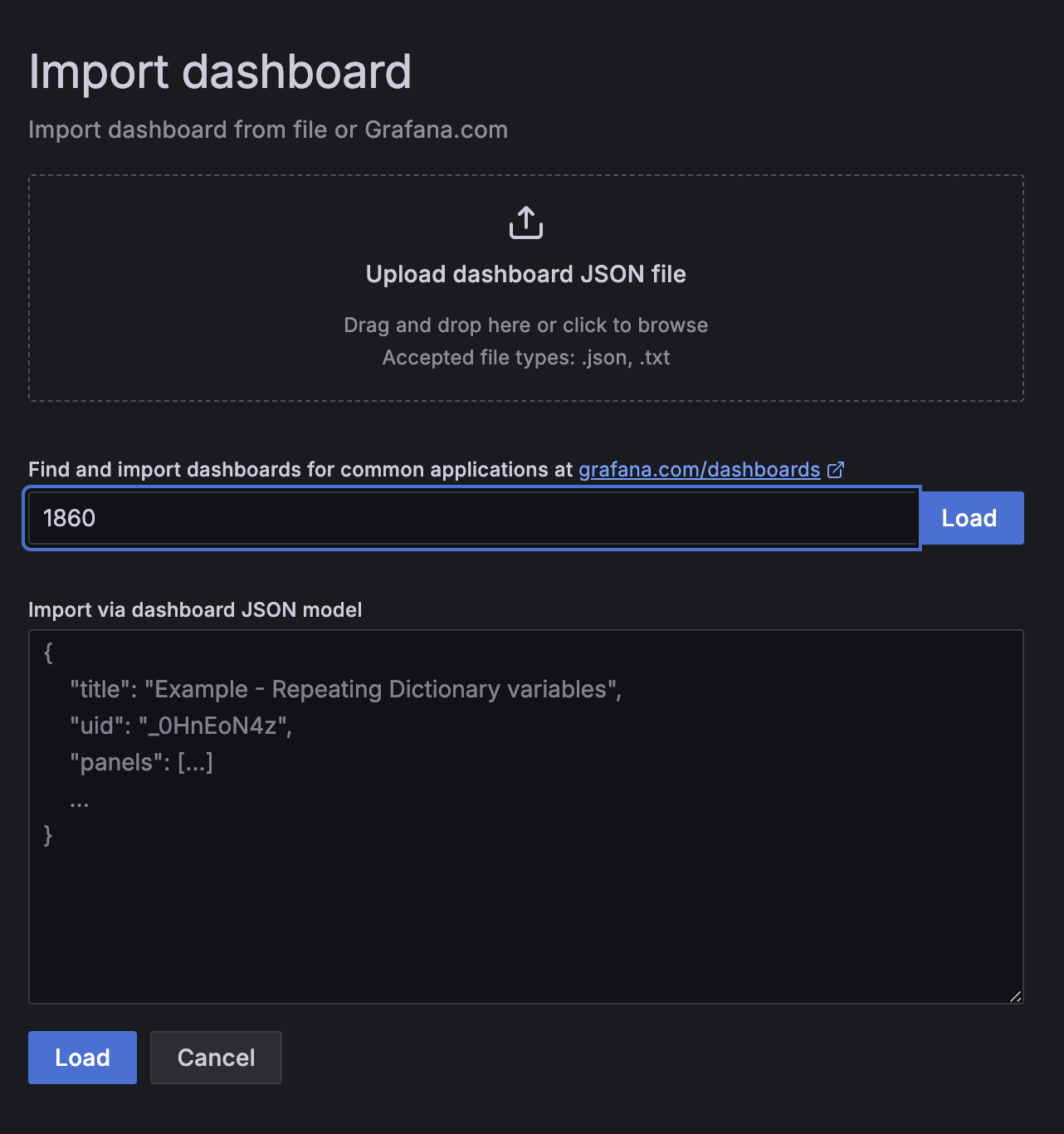 1860를 입력하고 Load를 누르면 원하는 대시보드를 불러올 수 있습니다.
1860를 입력하고 Load를 누르면 원하는 대시보드를 불러올 수 있습니다.
다른 대시보드는 Grafana 대시보드에서 찾고 Copy ID to clipboard 버튼을 통해 원하는 대시보드의 ID를 가져올 수 있습니다. 연결한 Prometheus를 데이터소스로 지정하고 Import를 진행하면 다음과 같은 대시보드가 생성됩니다.
연결한 Prometheus를 데이터소스로 지정하고 Import를 진행하면 다음과 같은 대시보드가 생성됩니다.
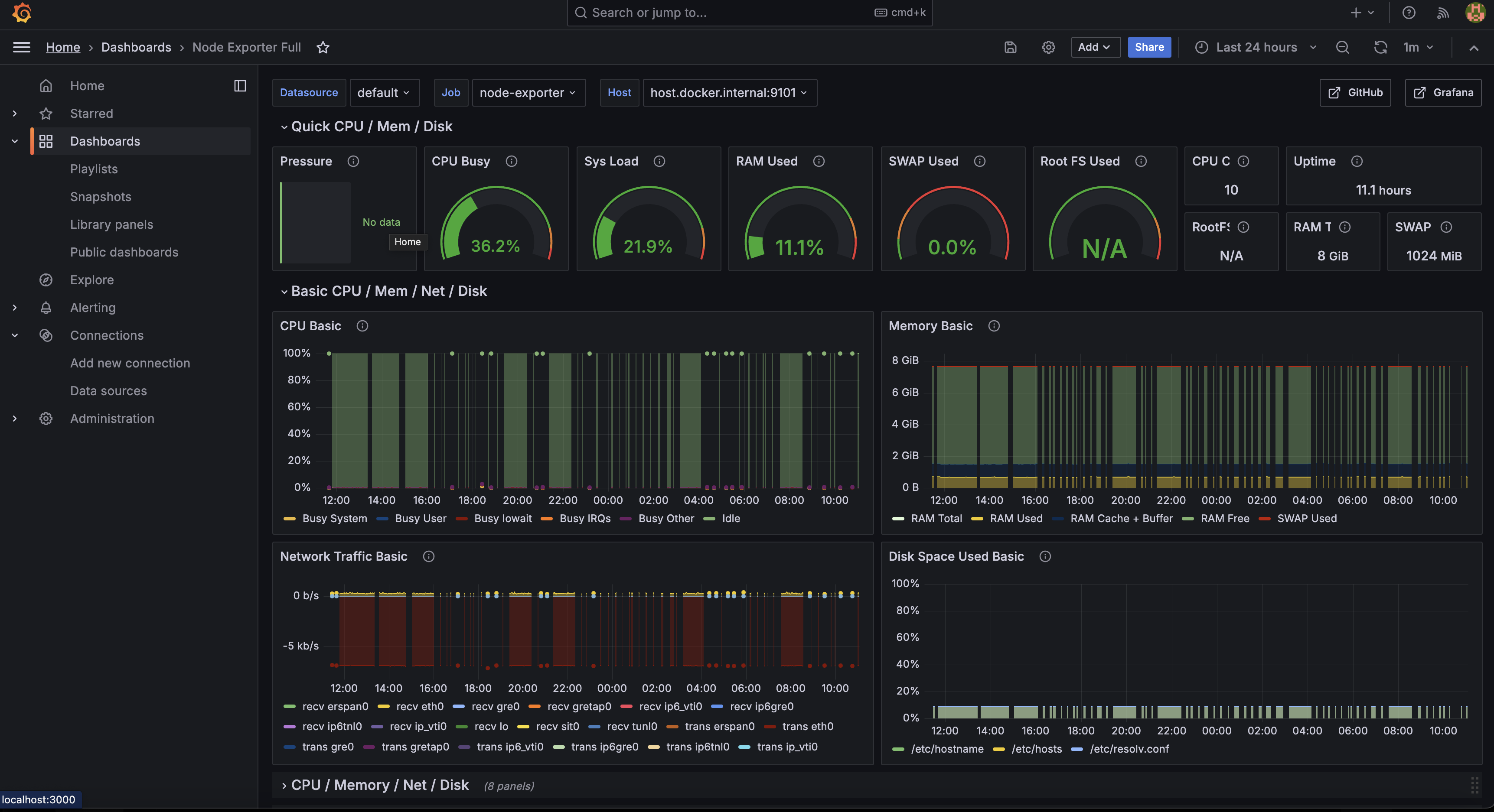
Loki 설치
로그 수집을 위한 Loki를 설치하고 Grafana에 연결해보겠습니다.
- docker-compose.yml 파일 작성
version: '3.8'
services:
loki:
container_name: loki
image: grafana/loki:latest
volumes:
- ./loki/config:/etc/loki
- ./loki/volume:/loki
ports:
- 3100:3100
- 9096:9096
restart: always- 도커 내부 파일과 폴더를 연결해주기 위해 ./loki/config와 ./loki/volume 폴더를 생성
- loki/config/local-config.yaml 파일 생성
필요로 하는 옵션은 Loki 문서 페이지에서 확인 가능합니다.
server:
http_listen_port: 3100
http_server_read_timeout: 3m
http_server_write_timeout: 3m
grpc_server_max_send_msg_size: 2147483647
grpc_server_max_recv_msg_size: 2147483647
common:
path_prefix: /loki
storage:
filesystem:
chunks_directory: /loki/chunks
rules_directory: /loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
ruler:
enable_api: true
limits_config:
enforce_metric_name: false
max_cache_freshness_per_query: 10m
reject_old_samples: true
reject_old_samples_max_age: 168h
split_queries_by_interval: 15m
per_stream_rate_limit: 512M
cardinality_limit: 200000
ingestion_burst_size_mb: 1000
ingestion_rate_mb: 10000
max_entries_limit_per_query: 1000000
max_global_streams_per_user: 10000
max_streams_per_user: 0
max_query_parallelism: 32
max_label_value_length: 20480
max_label_name_length: 10240
max_label_names_per_series: 300
frontend:
max_outstanding_per_tenant: 2048
compress_responses: true
querier:
max_concurrent: 2048
query_scheduler:
max_outstanding_requests_per_tenant: 2048
query_range:
split_queries_by_interval: 0docker-compose up -d명령어를 통해 실행
 Grafana > Connections > Data sources > Loki 를 선택하여 연결할 수 있습니다.
Grafana > Connections > Data sources > Loki 를 선택하여 연결할 수 있습니다.
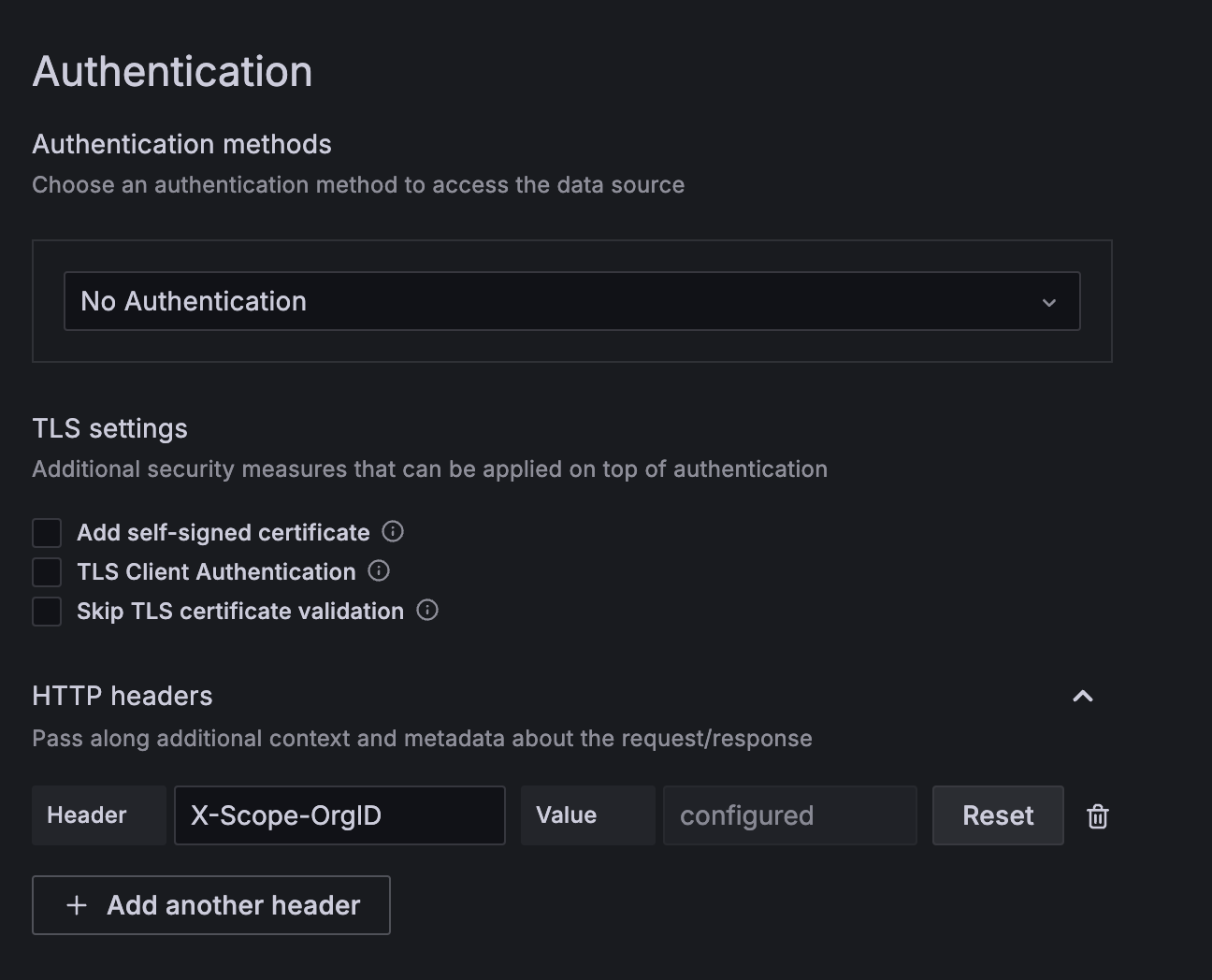
X-Scope-OrgID헤더를 추가하여 401 에러가 발생하지 않도록 합니다. Loki에서 구분값으로 사용되어 X-Scope-OrgID 헤더의 값을 기준으로 데이터가 저장되기 때문에 원하는 값을 입력하면 됩니다.
Promtail 설치
- docker-compose.yml 파일 작성
version: '3.8'
services:
promtail:
container_name: promtail
image: grafana/promtail:latest
ports:
- "9080:9080"
volumes:
- ./promtail/config:/etc/promtail/config
- ./promtail/volume:/promtail
- ./spring-sample/logs:/logs
command: -config.file=/etc/promtail/config/config.yaml
restart: always- 도커 내부 파일과 폴더를 연결해주기 위해 ./promtail/config와 ./promtail/volume 폴더를 생성
- promtail/config/config.yaml 파일 생성
필요로 하는 옵션은 Promtail 문서 페이지에서 확인 가능합니다.
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /etc/promtail/config/positions.yaml
clients:
- url: http://host.docker.internal:3100/loki/api/v1/push
headers:
- X-Scope-OrgID: monitoring
target_config:
sync_period: 10s
scrape_configs:
- job_name: sample-logs
static_configs:
- targets:
- localhost
labels:
application: sample
env: dev
__path__: /logs/**/**.log
relabel_configs:
- source_labels: ["__address__"]
target_label: addressdocker-compose up -d명령어를 통해 실행- Grafana + Loki를 이용해 수집된 로그 확인
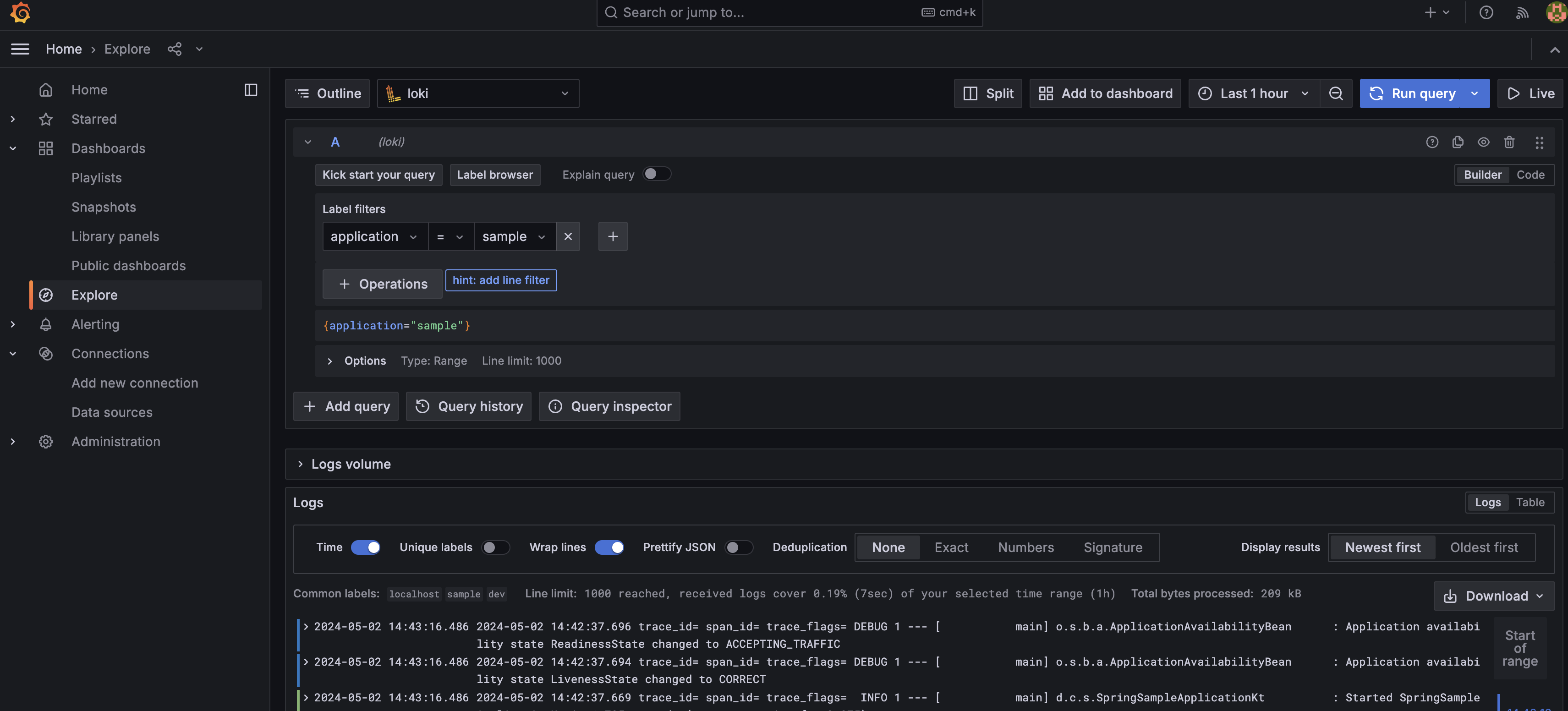
Promtail은 로그를 전송해주는 agent이기 때문에 서버가 구동되는 각 인스턴스에 모두 존재해야합니다. 현재는 AWS를 통해 서버를 운영중이기 때문에 모든 서비스에 Promtail이 포함될 수 있도록 설정이 모두 적용된 AMI(Amazon Machine Image)를 생성하고 이를 기반으로 서버를 배포하였습니다.
Tempo 설치
마지막으로 수집된 로그를 추적하기 위해 Tempo를 설치하고 Grafana에서 쉽게 에러를 찾을 수 있습니다.
- docker-compose.yml 파일 작성
version: '3.8'
services:
tempo:
container_name: tempo
image: grafana/tempo:latest
command:
[
"-config.file=/etc/tempo/config/tempo.yaml",
"--auth.enabled=false"
]
volumes:
- ./tempo/config:/etc/tempo/config
- ./tempo/volume:/var
ports:
- "3200:3200" # tempo
- "9095:9095" # tempo grpc
- "4317:4317" # otlp grpc
- "4318:4318" # otlp http
restart: always- 도커 내부 파일과 폴더를 연결해주기 위해 ./tempo/config와 ./tempo/volume 폴더를 생성
- tempo/config/tempo.yaml 파일 생성
필요로 하는 옵션은 Tempo 문서 페이지에서 확인 가능합니다.
server:
http_listen_port: 3200
ingester:
max_block_duration: 5m # cut the headblock when this much time passes. this is being set for demo purposes and should probably be left alone normally
trace_idle_period: 1s
lifecycler:
ring:
replication_factor: 1
distributor:
receivers:
otlp:
protocols:
http:
grpc:
compactor:
compaction:
max_block_bytes: 100_000_000
block_retention: 336h # overall Tempo trace retention. set for demo purposes
metrics_generator:
registry:
external_labels:
source: tempo
cluster: docker-compose
storage:
path: /tmp/tempo/generator/wal
remote_write:
- url: http://host.docker.internal:9090/api/v1/write
send_exemplars: true
storage:
trace:
backend: local # backend configuration to use
wal:
path: /tmp/tempo/wal # where to store the the wal locally
local:
path: /tmp/tempo/blocks
overrides:
metrics_generator_processors: [service-graphs, span-metrics] # enables metrics generatordocker-compose up -d명령어를 통해 실행- Grafana와 연결
Grafana > Connections > Data sources > Tempo 를 선택하여 연결할 수 있습니다.
Prometheus server URL에http://host.docker.internal:3200을 입력해줍니다.
Trace 화면에서 해당하는 로그로 바로 이동하기 위해 다음 설정도 적용합니다.
 Save & Test 버튼을 통해 설정을 완료합니다.
Save & Test 버튼을 통해 설정을 완료합니다. - Loki 연결
여기까지 설정하면 Loki와 Tempo 각각 설정은 완료됩니다. 하지만 Loki에서 Tempo를 통한 추적까지 바로 연결될 수 있도록 Loki 설정페이지에 Derived fields를 추가합니다.
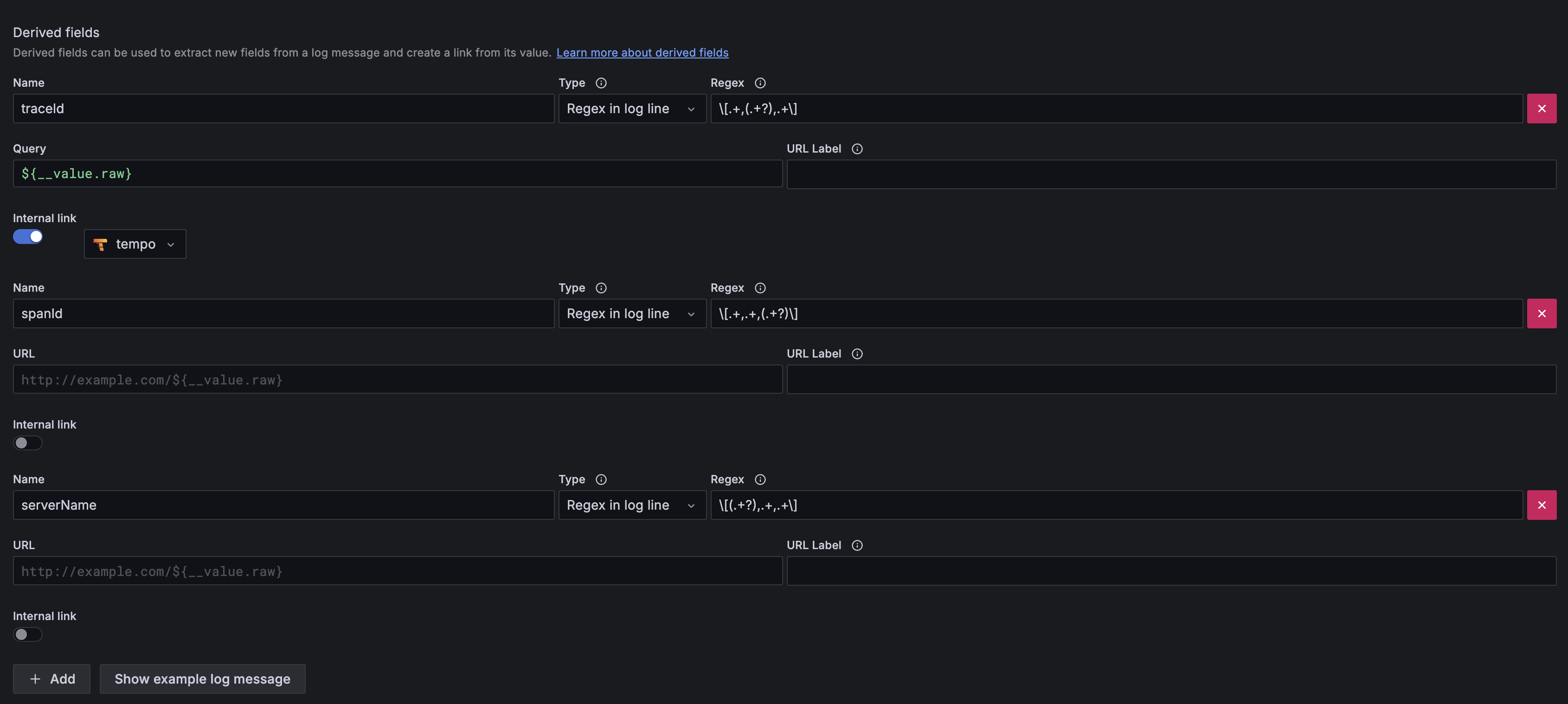 로그에서 정규식 조건에 맞는 traceId 값을 찾아내고 이를 Tempo로 보내 즉시 추적할 수 있습니다.
로그에서 정규식 조건에 맞는 traceId 값을 찾아내고 이를 Tempo로 보내 즉시 추적할 수 있습니다.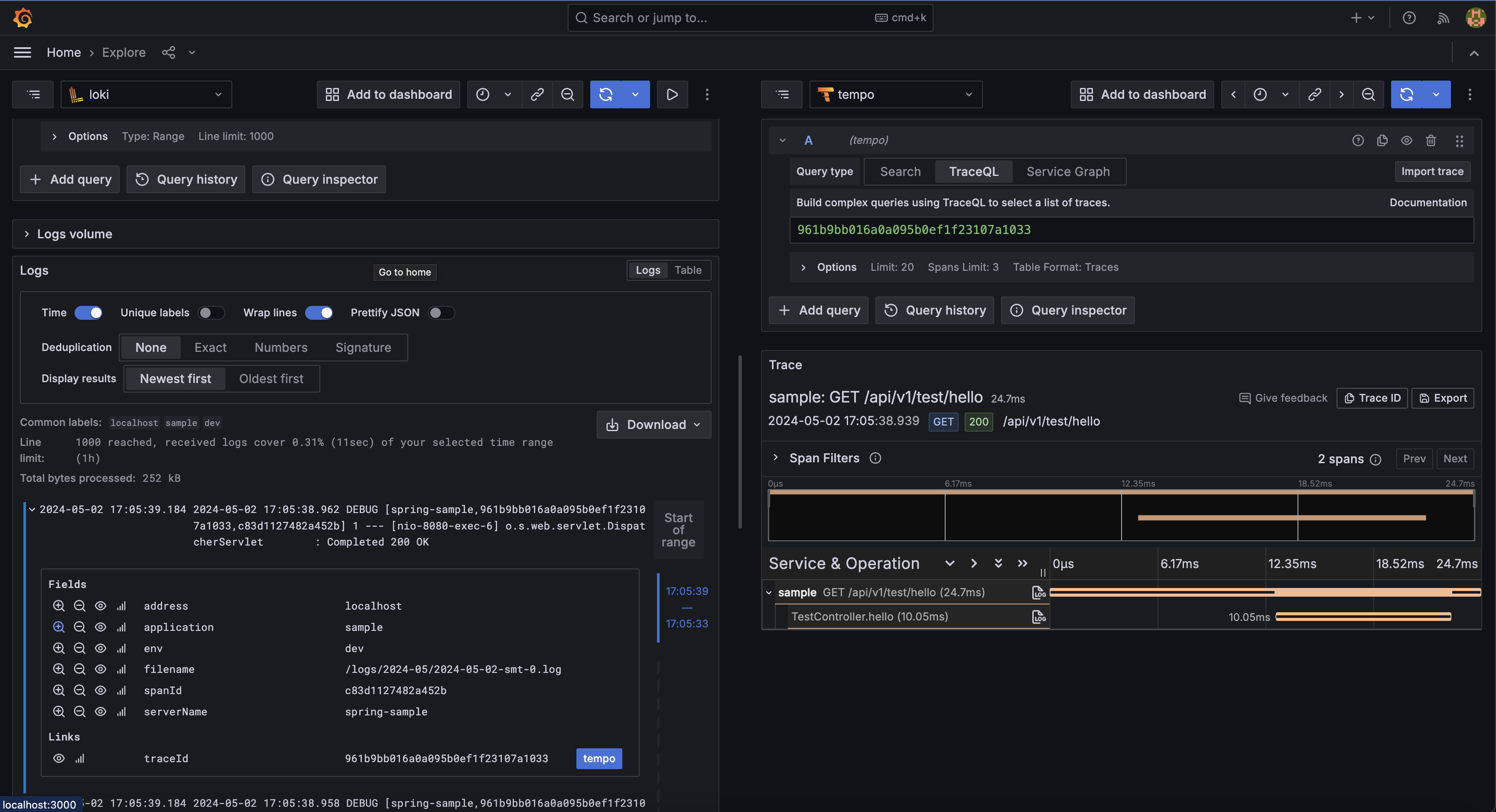
Spring Boot trace 설정
위에서 설치한 Tempo가 Spring 서버에서 각 요청을 추적하기 위해서는 traceId가 필요합니다. 이를 위해 Spring 프로젝트에 다음 라이브러리를 추가하면 로그에 traceId, spanId가 추가됩니다.
예시에 사용된 Spring Boot는 3.2.5 버전을 사용하고 있습니다. 이전 버전의 2.x.x 버전 대의 Spring Boot에서는 sleuth 라이브러리를 통해 traceId를 추가해주었지만 Micrometer Tracing 프로젝트로 이관되면서 더 이상 사용할 수 없게 되어 micrometer tracing을 사용하였습니다. 참고 링크
// build.gradle.kts
implementation("io.micrometer:micrometer-core")
implementation("io.micrometer:micrometer-registry-prometheus")
implementation("io.micrometer:micrometer-tracing-bridge-otel")# application.yml
management:
tracing:
propagation:
type: w3c
enabled: true
sampling:
probability: 1.0
logging:
level:
root: debug
config: classpath:logback-spring.xml
file:
path: ./logs
pattern:
level: "%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}]"결론
모니터링 시스템 구축 프로젝트를 통해 모니터링 및 장애 대응에 대한 효율성을 크게 향상시켰습니다. Grafana를 중심으로 한 통합 대시보드는 운영의 복잡성을 줄이고 장애 발생시 문제 해결 시간 역시 단축시킬 수 있었습니다. 추가로 기존 사용하던 모니터링 시스템에 비해 좀 더 많은 기능을 적은 비용으로 구현한 점이 큰 장점이었던것 같습니다.
추후에 이 글에서 다루지 못한 Docker에 대한 자세한 내용, Prometheus -> Mimir 전환, 모니터링 시스템에 S3 스토리지 적용 등의 내용도 다른 글로 작성할 예정입니다.
이 글이 여러분의 모니터링 시스템 구축에 도움이 되길 바랍니다. 추가 질문이나 피드백이 있으시면 언제든지 댓글로 남겨 주세요.
참고자료
https://grafana.com/docs/grafana/latest/
https://grafana.com/docs/loki/latest/get-started/overview/
https://grafana.com/docs/tempo/latest/
https://prometheus.io/
