1. 데이터 개요
- 데이터셋: 경찰서별 5대범죄 발생 검거 현황
- 배경 설명
- 대한민국의 범죄는 종류가 다양해지고 있고, 그 심각성은 갈수록 커지고 있다.
- 서울시에서 제공하는 공공데이터를 활용하여 범죄 데이터를 분석하고 유의미한 인사이트를 도출한다.
2. 데이터 불러오기
crime = pd.read_csv("./data/seoul_crime_2023.csv", encoding="cp949")
# 데이터 개요 확인
crime.info()
# 출력 정보
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 310 entries, 0 to 309
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 구분 310 non-null object
# 1 죄종 310 non-null object
# 2 발생검거 310 non-null object
# 3 건수 310 non-null int64
# dtypes: int64(1), object(3)
# memory usage: 9.8+ KB# 데이터 첫 5행 확인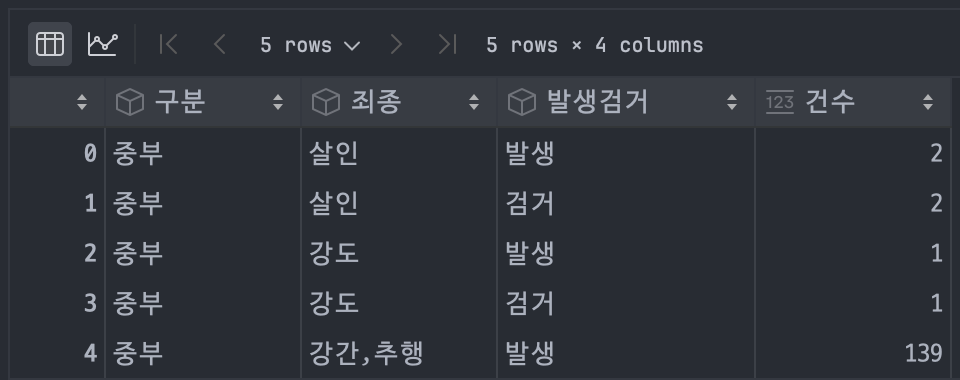
3. 데이터 들여다보기
# '구분' 컬럼 정보 확인
print(crime["구분"].nunique())
print(crime["구분"].unique())
## 출력 정보
# 31
# ['중부' '종로' '남대문' '서대문' '혜화' '용산' '성북' '동대문' '마포'
# '영등포' '성동' '동작' '광진' '서부' '강북' '금천' '중랑' '강남' '관악'
# '강서' '강동' '종암' '구로' '서초' '양천' '송파' '노원' '방배' '은평'
# '도봉' '수서']
# '죄종' 컬럼 정보 확인
print(crime["죄종"].nunique())
print(crime["죄종"].unique())
## 출력 정보
# 6
# ['살인' '강도' '강간,추행' '절도' '폭력' '강간']
# '죄종' 컬럼 리팩터링
crime["죄종"] = crime["죄종"].replace(["강간,추행", "강간"], "성범죄")
print(crime["죄종"].unique())
## 출력 정보
# ['살인' '강도' '성범죄' '절도' '폭력']
# '발생검거' 컬럼 정보 확인
print(crime["발생검거"].nunique())
print(crime["발생검거"].unique())
## 출력 정보
# 2
# ['발생' '검거']4. 데이터 변형해보기
4-1. 지점별 범죄건수 피벗 생성
# 구분 별 건수 합계 피벗 생성
crime_per_station = pd.pivot_table(
data=crime,
index="구분",
columns=["죄종", "발생검거"],
values="건수",
aggfunc="sum"
)
print(crime_per_station.head(5))
## 출력 정보
# 죄종 강도 살인 성범죄 절도 폭력
# 발생검거 검거 발생 검거 발생 검거 발생 검거 발생 검거 발생
# 구분
# 강남 7 10 6 9 399 489 696 1636 2034 2322
# 강동 4 5 6 4 122 144 980 1676 1383 1569
# 강북 1 1 7 7 102 141 730 917 1302 1431
# 강서 4 6 2 1 225 300 1243 1794 2070 2195
# 관악 10 10 17 16 268 328 1166 2013 2035 2402
# 강도 검거 수 상위 5개 지점
crime_per_station["강도","검거"].sort_values(ascending=False).head()
## 출력 정보
# 구분
# 수서 11
# 영등포 10
# 관악 10
# 송파 8
# 구로 7
# Name: (강도, 검거), dtype: int64
# 살인 검거 수 상위 5개 지점
crime_per_station["살인","검거"].sort_values(ascending=False).head()
## 출력 정보
# 구분
# 관악 17
# 영등포 12
# 구로 12
# 서초 8
# 강북 7
# Name: (살인, 검거), dtype: int64
# 성범죄 검거 수 상위 5개 지점
crime_per_station["성범죄","검거"].sort_values(ascending=False).head()
## 출력 정보
# 구분
# 강남 399
# 마포 339
# 관악 268
# 서초 261
# 송파 229
# Name: (성범죄, 검거), dtype: int64
# 절도 검거 수 상위 5개 지점
crime_per_station["절도","검거"].sort_values(ascending=False).head()
## 출력 정보
# 구분
# 강서 1243
# 양천 1243
# 송파 1243
# 영등포 1192
# 관악 1166
# Name: (절도, 검거), dtype: int64
# 폭력 검거 수 상위 5개 지점
crime_per_station["폭력","검거"].sort_values(ascending=False).head()
## 출력 정보
# 구분
# 강서 2070
# 송파 2035
# 관악 2035
# 양천 2035
# 강남 2034
# Name: (폭력, 검거), dtype: int64
# 다중 컬럼을 병합하여 컬럼명 대치
new_colname = crime_per_station.columns.get_level_values(0) + crime_per_station.columns.get_level_values(1)
crime_per_station.columns = new_colname
print(crime_per_station.head())
## 출력 정보
# 강도검거 강도발생 살인검거 살인발생 성범죄검거 성범죄발생 절도검거 절도발생 폭력검거 폭력발생
# 구분
# 강남 7 10 6 9 399 489 696 1636 2034 2322
# 강동 4 5 6 4 122 144 980 1676 1383 1569
# 강북 1 1 7 7 102 141 730 917 1302 1431
# 강서 4 6 2 1 225 300 1243 1794 2070 2195
# 관악 10 10 17 16 268 328 1166 2013 2035 24024-2. 지역별 범죄건수 피벗 생성
seoul_gu = {
'종로구':['종로', '혜화'], '중구':['남대문', '중부'],
'용산구':['용산'], '성동구':['성동'],
'광진구':['광진'], '동대문구':['동대문'],
'중랑구':['중랑'], '성북구':['성북', '종암'],
'강북구':['강북'], '도봉구':['도봉'],
'노원구':['노원'], '은평구':['서부', '은평'],
'서대문구':['서대문'], '마포구':['마포'],
'양천구':['양천'], '강서구':['강서'],
'구로구':['구로'], '금천구':['금천'],
'영등포구':['영등포'], '동작구':['동작'],
'관악구':['관악'], '서초구':['방배', '서초'],
'강남구':['강남', '수서'], '송파구':['송파'],
'강동구':['강동']
}
gu_list = list()
for station_name in crime_per_station.index:
for gu, sub in seoul_gu.items():
if station_name in sub:
gu_list.append(gu)
crime_per_station["구"] = gu_list
crime_per_gu = pd.pivot_table(
data=crime_per_station,
index="구",
aggfunc="sum"
)
print(crime_per_gu.head(1))
# 강도검거 강도발생 살인검거 살인발생 성범죄검거 성범죄발생 절도검거 절도발생 폭력검거 폭력발생
# 구
# 강남구 8 20 11 14 567 678 1284 2480 3112 35714-3. 검거율 컬럼 생성
# 검거 관련 컬럼명만 추출
arrest_col = crime_per_gu.columns[crime_per_gu.columns.str.endswith("검거")].tolist()
# 발생 관련 컬럼명만 추출
occur_col = crime_per_gu.columns[~crime_per_gu.columns.str.endswith("검거")].tolist()
# 검거율 컬럼명 생성
rate_col = ["강도검거율", "살인검거율", "성범죄검거율", "절도검거율", "폭력검거율"]
# 검거율 계산 및 데이터프레임에 추가
rate_df = round(crime_per_gu[arrest_col].div(crime_per_gu[occur_col].values)*100, 2)
# 검거율이 100% 이상인 경우 100%로 대치
rate_df[rate_df > 100] = 100
# 검거율의 경우 분모가 0인 경우 0으로 대치
rate_df = rate_df.replace(np.Inf, 0)
crime_per_gu[rate_col] = rate_df4-4. 불필요 컬럼(검거건수) 삭제
crime_per_gu.rename(columns={
"강도발생": "강도",
"살인발생": "살인",
"성범죄발생": "성범죄",
"절도발생": "절도",
"폭력발생": "폭력",
}, inplace=True)
crime_per_gu.drop(columns=arrest_col, inplace=True)
print(crime_per_gu.head(1))
## 출력 정보
# 강도 살인 성범죄 절도 폭력 강도검거율 살인검거율 성범죄검거율 절도검거율 폭력검거율
# 구
# 강남구 20 14 678 2480 3571 90.0 78.57 83.63 51.77 87.154-5. 건수 컬럼 정규화
# 범죄유형별로 최대값의 차이가 지나치게 큰 편
# 각 유형별로 가장 큰 범죄 건수를 1로 하는 정규화 적용
crime_col = ["강도", "살인", "성범죄", "절도", "폭력"]
crime_per_gu_norm = crime_per_gu[crime_col] / crime_per_gu[crime_col].max()
# 기존에 계산한 검거율 컬럼은 다시 추가
crime_per_gu_norm[rate_col] = rate_df
# 구역 및 범죄유형별 막대 그래프 시각화
crime_per_gu_norm[crime_col].plot(kind="bar", figsize=(12,3))
plt.show()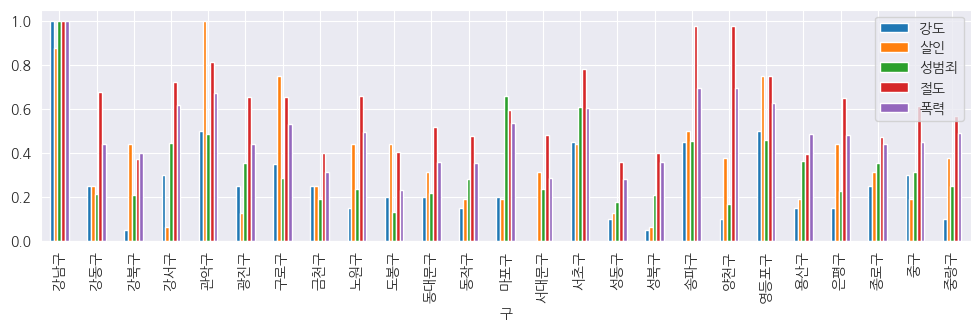
4-6. 5대범죄의 건수 및 검거율 평균 컬럼 생성
# 평균 건수 컬럼 생성
crime_per_gu_norm["평균건수"] = np.mean(crime_per_gu_norm[crime_col], axis=1)
# 평균 검거율 컬럼 생성
crime_per_gu_norm["평균검거율"] = np.mean(crime_per_gu_norm[rate_col], axis=1)
# 평균 건수 기준 상위 5개 구
print(crime_per_gu_norm["평균건수"].sort_values(ascending=False).head())
## 출력 예시
# 구
# 강남구 0.975000
# 관악구 0.693622
# 영등포구 0.615969
# 송파구 0.614464
# 서초구 0.576149
# Name: 평균건수, dtype: float64
# 평균 검거율 기준 상위 5개 구
print(crime_per_gu_norm["평균검거율"].sort_values(ascending=False).head())
## 출력 예시
# 구
# 강서구 101.054
# 용산구 93.118
# 강동구 92.268
# 노원구 89.000
# 강북구 88.588
# Name: 평균검거율, dtype: float645. 데이터 저장 및 다시 불러오기
# csv 파일로 저장
crime_per_gu_norm.to_csv("./data/seoul_crime_2023_cleaned.csv")
# 시각화 작업의 편의를 위해 crime 이름으로 재로딩
crime = pd.read_csv("./data/seoul_crime_2023_cleaned.csv", index_col=0)6. 시각화
6-1. 5대 범죄 건수 Boxplot
- 절도와 폭력 다음으로 살인 범죄가 많이 발생되고 있다는 점에서 심각성을 확인할 수 있음
fig, ax = plt.subplots(figsize=(6,3))
ax.set_title("2023년 5대 범죄 건수 박스 플롯")
sns.boxplot(crime[crime_col])
plt.show()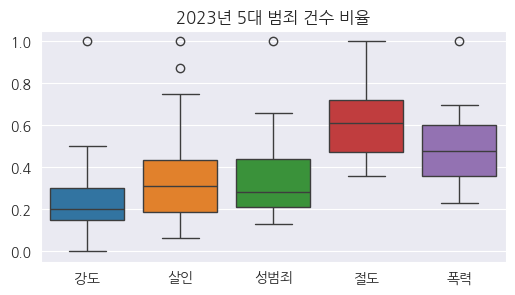
6-2. 5대 범죄 평균 건수 Bar Plot
- 강남구 지역에서 평균 범죄 건수가 가장 많았으며, 이어 관악구, 영등포구, 송파구, 서초구 지역에서의 5대 범죄 건수가 많았음
# 지역별 5대 범죄 건수 바 그래프
fig, ax = plt.subplots(figsize=(10,3))
ax.set_title("2023년 지역별 5대 범죄 건수")
sns.barplot(x=crime.index, y=crime.평균건수, color="red")
ax.set_xticks(ax.get_xticks(), ax.get_xticklabels(), rotation=90)
ax.set_ylabel(None)
ax.set_xlabel(None)
plt.show()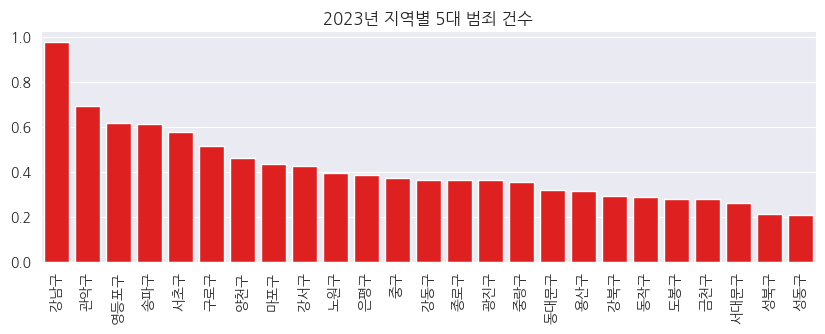
6-3. 5대 범죄 건수 Stacked Bar Plot
- 5대 범죄가 가장 많이 발생하고 있는 강남구의 경우, 각 범죄의 비율은 비슷함
- 관악구와 영등포구의 경우 살인 범죄의 비중이 높고, 송파구와 양천구의 경우 절도 범죄의 비중이 높은 것으로 확인됨
# 지역별 범죄 건수 Stakced 바 그래프
crime[crime_col].plot(kind="bar", stacked=True, figsize=(10, 3))
fig = plt.gcf()
ax = plt.gca()
ax.set_title("2023년 지역별 5대 범죄 건수")
ax.set_ylabel(None)
ax.set_yticklabels("")
ax.set_xlabel(None)
plt.show()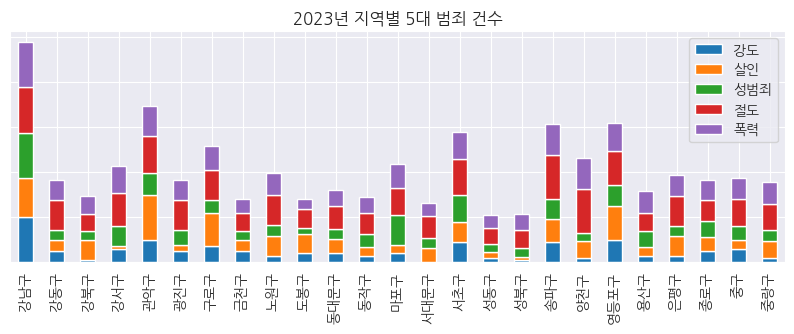
6-4. 5대 범죄 건수 Heatmap
- 수치형 변수는 히트맵을 통해서도 효과적으로 나타낼 수 있음
- 살인 범죄의 경우 강남구 보다 관악구 지역에서 훨씬 심각하게 발생하고 있음
- 절도 범죄의 경우 송파구와 양천구에서도 상당히 발생하고 있음
# 지역별 범죄건수 및 평균검거율 히트맵
fig, ax = plt.subplots(figsize=(4,8))
sns.heatmap(data=crime[crime_col], annot=True, fmt=".2f", ax=ax, cmap="RdBu_r")
ax.set_ylabel(None)
ax.set_title("2023년 지역별 범죄건수")
plt.show()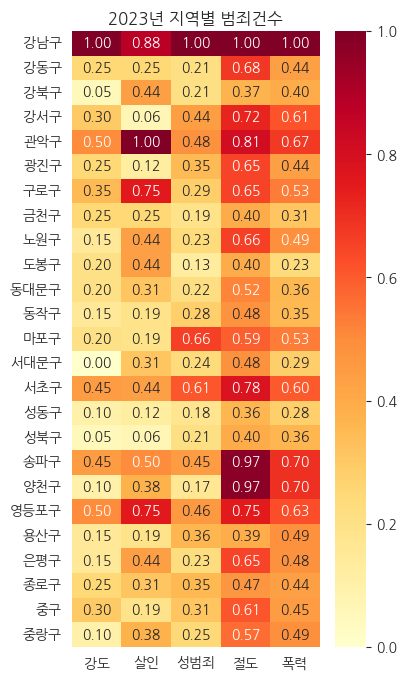
6-5. 성범죄 건수 Choropleth Map
- 지리에 익숙한 사람의 경우, 강남구와 마포구의 성범죄 발생 건수가 타 지역 대비 상당히 높은 편임을 알아챌 수 있음
# folium 라이브러리 로드
import folium
# 지역별 성범죄 건수 시각화
crime_map = folium.Map(location=[37.57, 127], zoom_start=11, tiles="Cartodb Positron")
folium.Choropleth(
geo_data="./data/seoul_municipalities_geo_simple.json", # 지리 데이터 경로
data=crime["성범죄"].reset_index(), # 매핑 데이터
columns=["구", "성범죄"], # 매핑 컬럼 (지리정보, 변수)
key_on="properties.name",
fill_opacity=".5",
line_opacity=".3",
fill_color="YlOrRd",
legend_name="정규화된 살인 범죄 건수"
).add_to(crime_map)
crime_map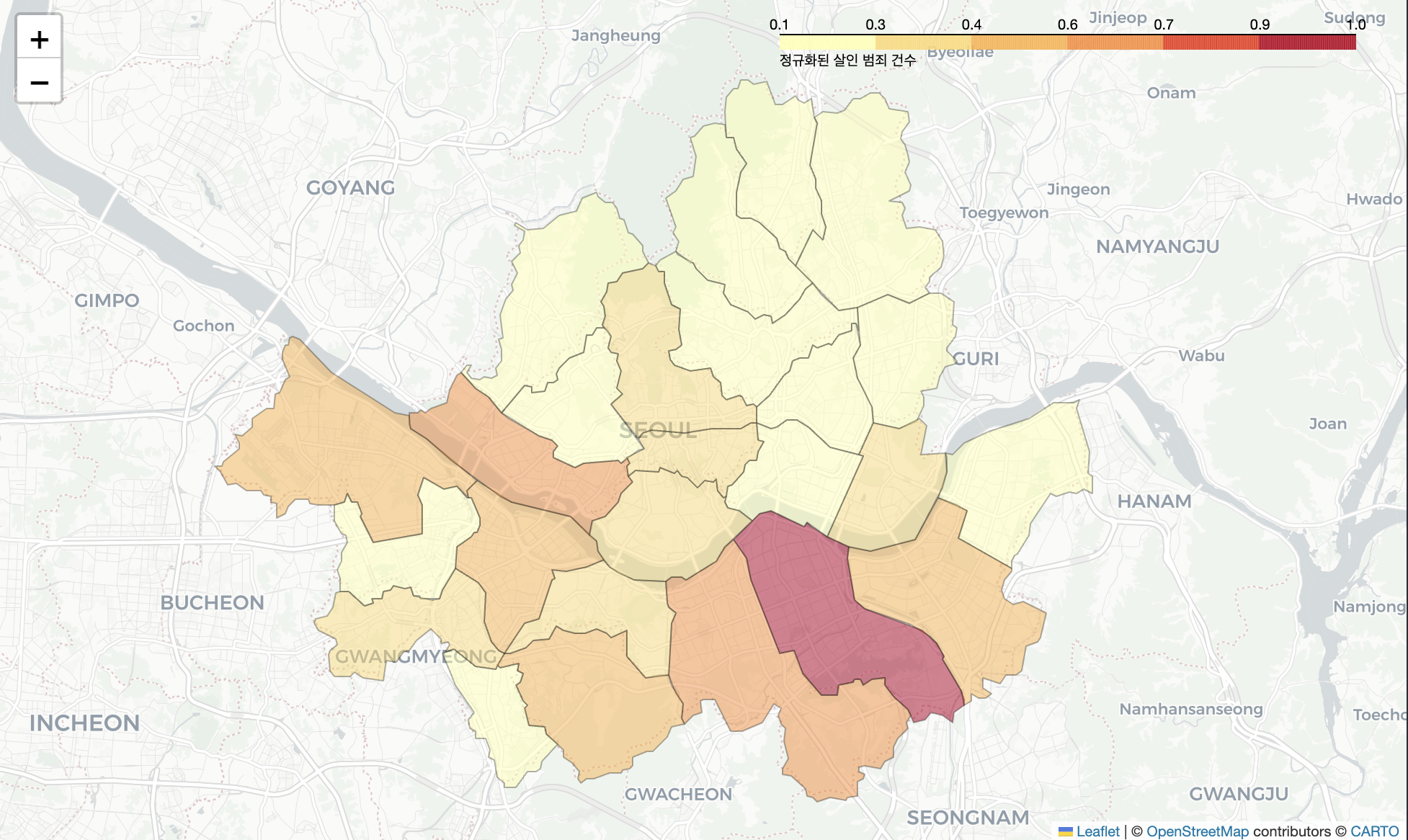
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소