1. 모델 저장 및 불러오기
- PyTorch에서는 Tensorflow와 마찬가지로 가중치만 저장하거나 모델 전체를 저장하는 두가지 기능을 제공함
- 양 방법 모두
torch.save()+torch.load()조합을 기본으로 하며, 가중치만 저장할 경우state_dict()를 사용하여 가중치를 추가로 추출하고 로드하는 작업이 필요
2. 예제 코드
2-1. 기본 모델 정의, 데이터 로드 및 학습
- CNN 분류 모델 정의
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchsummary as ts
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
from torch.utils.data import Dataset, DataLoader
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1, 1)
self.conv2 = nn.Conv2d(32, 64 , 3, 1, 1)
self.dropout = nn.Dropout(0.25)
self.fc1 = nn.Linear(64 * 7 * 7, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = F.log_softmax(self.fc2(x), dim=1)
return x
cnn = CNN().to(device)
print(cnn)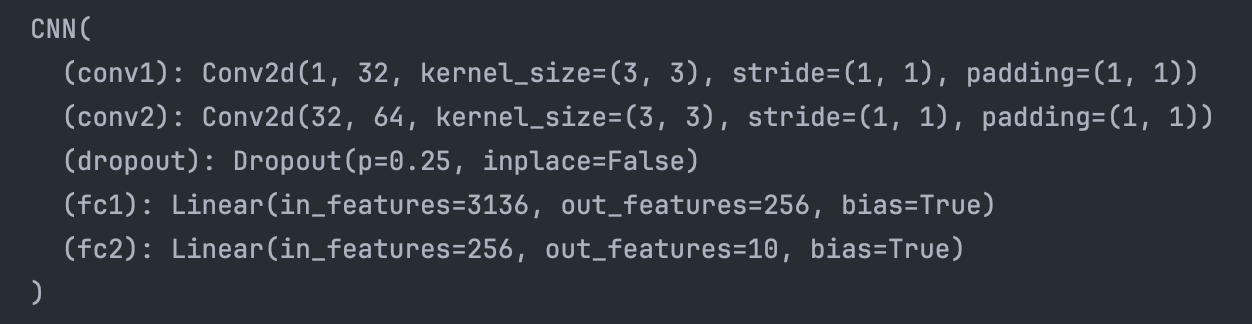
- MNIST 데이터 로드
train_data = datasets.MNIST(
"./data",
train=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
),
)
test_data = datasets.MNIST(
"./data",
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
),
)
train_loader = DataLoader(
train_data,
shuffle=True,
batch_size=256,
)
test_loader = DataLoader(
test_data,
shuffle=False,
batch_size=256,
)- 최적화 함수 정의 및 훈련
optimizer = optim.Adam(cnn.parameters(), lr=0.03)
scheduler = lr_scheduler.ReduceLROnPlateau(
optimizer,
mode="min",
patience=2, # 2 epoch 동안 손실이 감소되지 않는다면,
factor=0.1, # 학습률을 기존의 0.1 수준으로 줄임
)
for epoch in range(10):
cnn.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = cnn(images)
loss = F.nll_loss(outputs, labels)
loss.backward()
optimizer.step() # 가중치 조정
print(f"[Epoch {epoch+1}] Train Loss: {loss.item():.5f}")
scheduler.step(loss) # 학습률 조정
cnn.eval()
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = cnn(images)
loss = F.nll_loss(outputs, labels)
print(f"[Epoch {epoch+1}] Test Loss: {loss.item():.5f}")
# [Epoch 1] Train Loss: 0.47822
# [Epoch 1] Test Loss: 0.06771
# [Epoch 2] Train Loss: 0.24769
# [Epoch 2] Test Loss: 0.07236
# [Epoch 3] Train Loss: 0.24033
# [Epoch 3] Test Loss: 0.04768
# [Epoch 4] Train Loss: 0.13009
# [Epoch 4] Test Loss: 0.00878
# [Epoch 5] Train Loss: 0.14712
# [Epoch 5] Test Loss: 0.00319
# [Epoch 6] Train Loss: 0.18090
# [Epoch 6] Test Loss: 0.01081
# [Epoch 7] Train Loss: 0.19649
# [Epoch 7] Test Loss: 0.00811
# [Epoch 8] Train Loss: 0.06929
# [Epoch 8] Test Loss: 0.00624
# [Epoch 9] Train Loss: 0.07021
# [Epoch 9] Test Loss: 0.00735
# [Epoch 10] Train Loss: 0.10174
# [Epoch 10] Test Loss: 0.00636]2-2. 가중치 저장/로드
# 가중치 저장
torch.save(cnn.state_dict(), "./model/cnn_weights.pt")
# 모델 생성
cnn_only_weights = CNN().to(device)
# 가중치 로드
cnn_only_weights.load_state_dict(torch.load("./model/cnn_weights.pt", weights_only=True))2-3. 모델 저장/로드
# 모델 저장 (가중치 포함)
torch.save(cnn, "./model/cnn_model.pt")
# 모델 로드
cnn_model = torch.load("./model/cnn_model.pt", weights_only=False)*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소