https://www.youtube.com/watch?v=zkeh7Tt9tYQ&t=1900s
다음 강의를 듣고 정리하였습니다.
1. Background
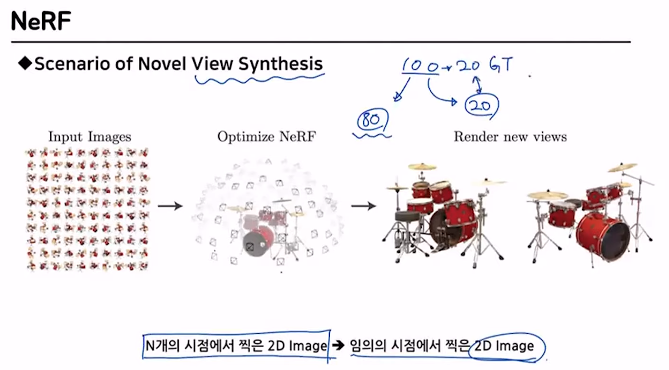
1.1 Novel View Synthesis

View Synthesis가 무엇일까?
이미지를 한 개 혹은 여러개를 input으로 받은 후, continuous하게 임의의 시점에서 바라본 모습을 합성하는 방식
1.2 Pinhole Camera Model
우리가 보는 2D image가 3D 공간으로부터 어떻게 왔는지를 이해하는 모델
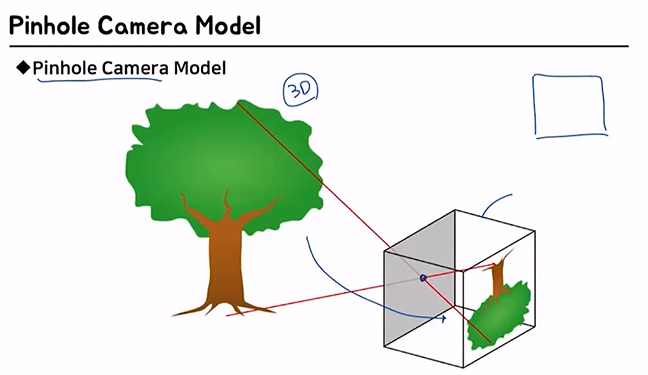
실제 세상 ------ Camera의 이미지
둘 사이의 관계를 알아내고 싶은 모델
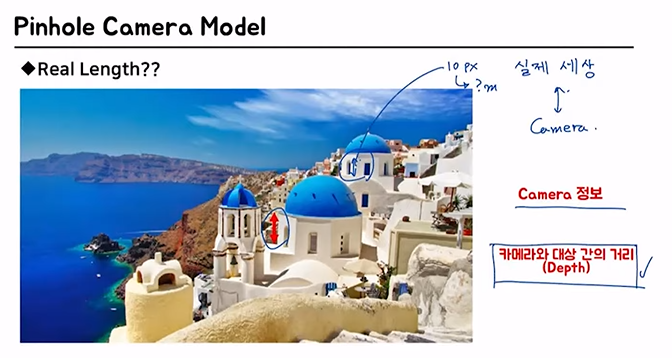
Q. 실제 저 높이가 어떻게 되냐?
A.
이미지만으로는 대답하기 어렵지
우리에게 필요한건
(1) Camera 정보 (2) 카메라와 대상 간의 거리(depth)
- (1)의 역할: 높이가 10px일 때, 몇 m인지 설명해줌
- (2)의 역할: 사진상 같은 픽셀 거리라도 실제로는 멀리 있을 때 그 길이가 더 긴 것을 설명해줌
1.2.1 Normalized Plane
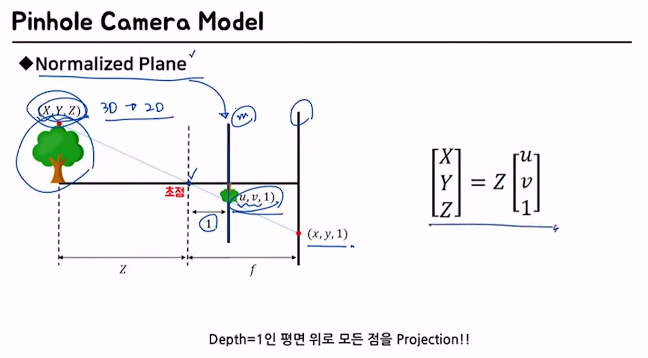
나무 - 3D space에 있음
초점 - 카메라의 위치
normalized plane - 카메라로부터 거리가 1m만큼 떨어진 곳에 projection을 시켰을 때 어떤 위치에 있을 것이냐를 나타낸 평면 (기준점)
초점으로부터의 거리가 1인 경우에 이므로
거리가 인 경우에는 이를 배를 한 것과 같겠지
1.2.2 Intrinsic Parameter
카메라의 초점 거리, aspect ratio, 중심점 등 카메라 자체의 내부적인 파라미터
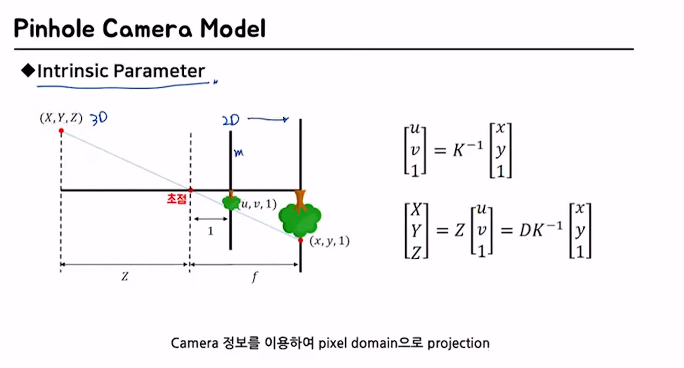
2D로 projection 시킨 결과를 m 단위에서 px 단위로 바꿔줘야 함
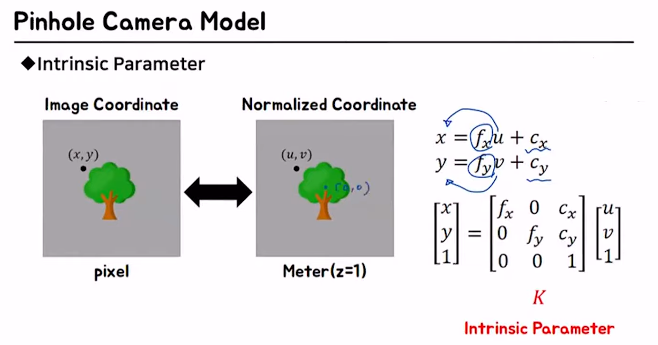
즉, normalized plane에서 사용한 을 로 바꿔주는 과정
1.2.3 Extrinsic parameter

카메라의 설치 높이, 방향 등 카메라와 외부공간과의 기하학적 관계에 관련된 파라미터
(이전에 정리해둔 블로그: https://velog.io/@dusruddl2/Photogrammetry-Camera-Calibration-%ED%98%BC%EC%9E%90-%EC%A0%95%EB%A6%AC%ED%95%B4%EB%B3%B4%EA%B8%B0)
2. NeRF
2.1 Neural Radiance Field
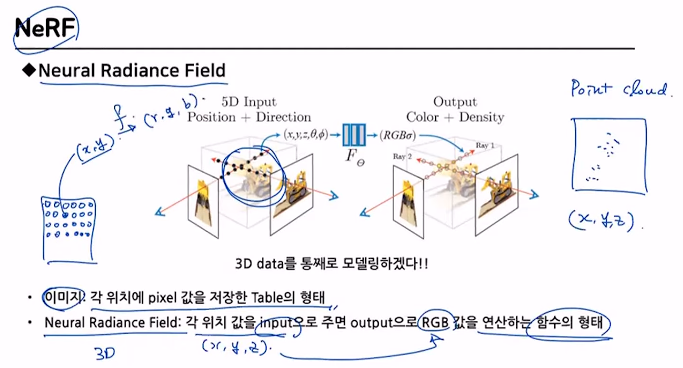
3D data는 2D data인 이미지와 다르게 시작과 끝이 정해지지 않았기 때문에 이를 표현하기에 매우 쉽지 않다.
이 과정을 Neural Radiance Field를 이용해서 쉽게 나타내자.
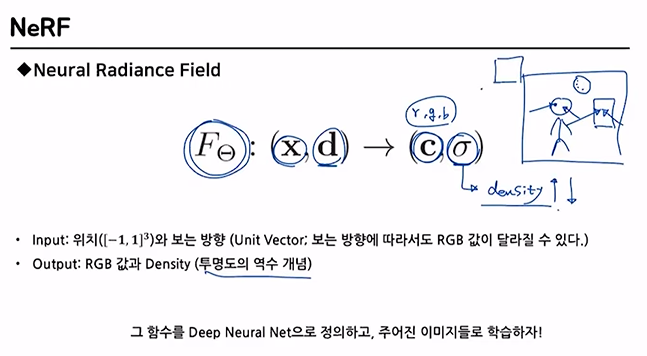
(input)
: Position위치를 나타내는 변수
: Direction보는 방향
(output)
: Color색상을 나타내는 변수
: Density투명도의 역수
다음과 같은 함수를 DNN으로 정의를 하게 된게 바로 NeRF
- 즉, train을 미리 하는게 아니라 test 시에 input이 들어오면 그 input에 대해서만 학습을 새로 하는 개념
- Zero-shot learning과 유사: 학습 과정에서 이전에 본 적이 없는 클래스 또는 레이블을 식별하는 능력. 기존의 분류 모델이 훈련된 클래스 외에도 새로운 클래스를 식별하고 구분할 수 있도록 하는 것
2.2 Ray

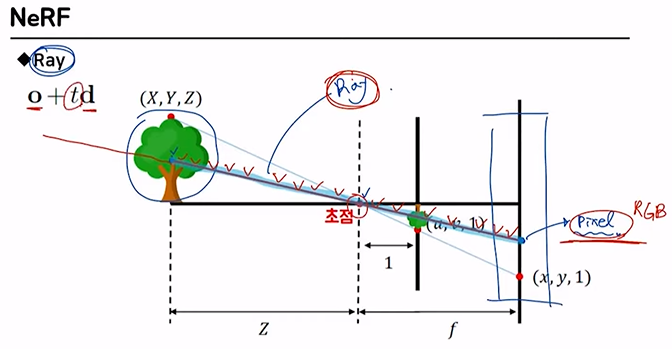
나뭇가지 꼭대기를 pixel값으로 담는다고 할때,
이 pixel값을 만드는데 영향을 미치는 직선 상의 모든 것 =
Ray
2.2.1 Projection
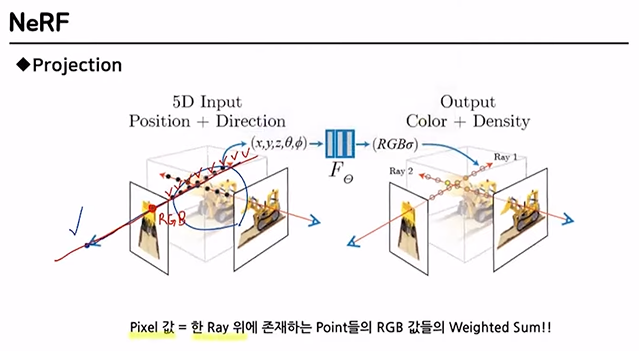
특정 시점에서 본 image를 얻고 싶으면
모든 pixel에 대해서 ray를 정의하면 된다.
그리고 각각의 pixel 값은 ray위의 point들의 RGB값을 weighted sum 하면 됨


[weight를 결정하는 방법]
- density가 클수록 weight 커야 함 ->
- 그 지점을 가로막고 있는 점들의 density의 합이 작을수록 weight가 커야 한다 ->
- 가로 막고 있는 점들의 density 합이 작다는 뜻은 별로 중요하지 않고 그 이후가 중요하다는거니까 weight가 커야겠지!
- : 시작점, : 현재 위치
그 합이 크면 의 값은 작아짐
++
이 작아지는 방향으로 학습
즉, 학습 결과인 와 Ground Truth인 을 비교
2.3 Implementation
2.3.1 continuos->discrete

continuos -> discrete
- sampling 과정
- ray를 N등분
2.3.2 Hierarchical Volume Sampling
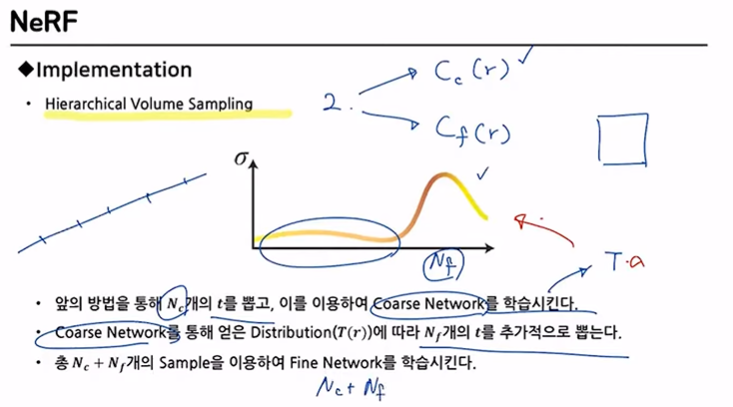
2개의 network 사용
- = course network
- = fine network
++
1.개의 를 뽑은 후 을 학습시킴
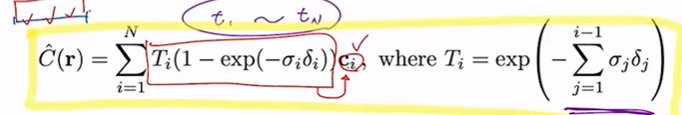
- 다음과 같은 distribution을 구할 수 있음
2.에 따라서 개의 를 추가적으로 뽑음
d
3.최종적으로 개의 Sample을 이용해 을 학습시킴
핵심 point - 중점적으로 봐야할 애를 더 집중적으로 본다!
2.3.3 Positional Encoding
총 6차원의 input -> 4차원의 output
그러나 이 경우 선명하게 잘 나오지 않는다고 함
input의 차원이 작기 때문에 발생하는 문제

그래서 의 차원을 뻥튀기 시켜주는 과정 (2L 배)
-> 선명도에 대한 게 어느정도 해결됨
ex) : rgb(3) -> 60
ex) : rgb(3) -> 24
NOTE)
게임이나 메타버스와 같이 어떤 객체를 360도 돌려가며 다양한 뷰에서 관측하기 위해서는 3D 렌더링이 필요함.
기존의 3D 렌더링 기술은 mesh / point cloud / voxel로 이루어진 3D 모델이 사용되었음.
SFM(Structure From Motion) 기술을 활용해 실제 세계의 객체를 3D reconstruction하여 3D 공간을 만들었음.
이와 달리 NeRF는 3D 모델을 생성하는 기술이 아닌,
객체를 바라보는 모든 장면을 생성하는 View Synthesis 기술
즉, 주어진 이미지로 실제로 촬영되지 않은 각도에서의 view를 만들어내어 마치 3D 렌더링된 것처럼 볼 수 있는 기술
새로운 view를 관측할 때마다 MLP네트워크를 통해 결과를 생성하기 때문에, 미리 3D 정보를 저장하는게 아님.
- https://kyujinpy.tistory.com/16
정말 잘 설명해준 블로그
