https://ffighting.net/deep-learning-paper-review/diffusion-model/diffusion-model-basic/
위의 블로그를 정리한 글입니다.
2. Diffusion Model 이란?
2.1 Image Generative Model

- 학습 데이터에 없는 형태의 이미지들도 생성 가능
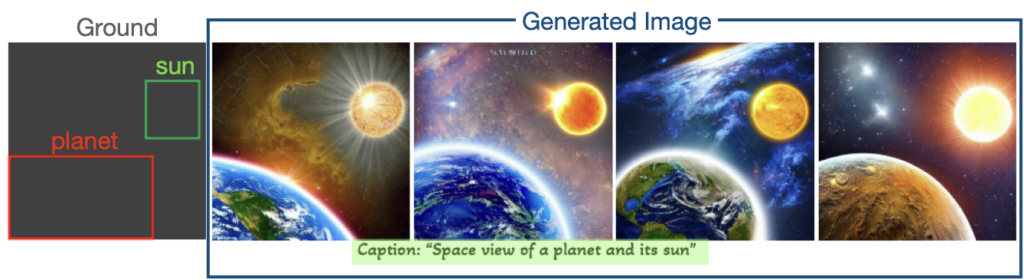
- text뿐 아니라 layout이라는 위치정보까지 입력으로 넣어서 생성 가능
이렇게 기존 Image Generative Model과는 달리 다양한 요구조건에 맞는 고화질 이미지를 생성할 수 있는 모습을 보여주면서 최근 Diffusion Model이 큰 화제가 되고 있다.
2.2 Diffusion Model 작동 원리
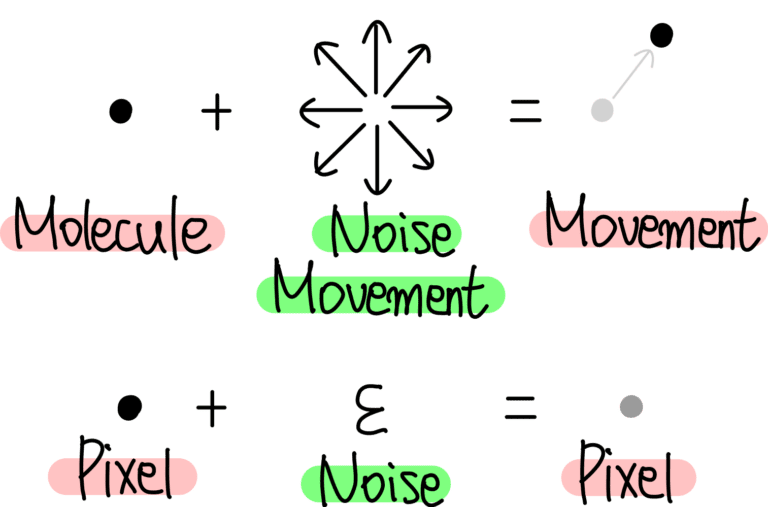

이미지의 모든 픽셀값에 Noise를 추가하여 이미지를 만듦


시간 t 마다 이미지 픽셀값에 첨가된 Noise 값을 계산할 수 있다면 Noise 이미지 xT 로부터 진짜 이미지 x0로 되돌리는 것이 가능
Diffusion Model은 각 픽셀마다 첨가된 Noise를 예측하는 것이 핵심!!!
2.3 Architecture
Diffusion Model이 갖춰야 하는 몇 가지 조건
1. Input은 이미지, 또는 Noisy 이미지
2. 몇 번째 Process 인지를 의미하는 t도 주어져야 함
3. 추가 Condition (조건) 이 있다면 이 조건 또한 Diffusion Model에게 주어져야 함
--- 특정 클래스 정보, 또는 생성한 이미지를 표현할 Text 정보 등
4. Output은 Input과 동일한 형태
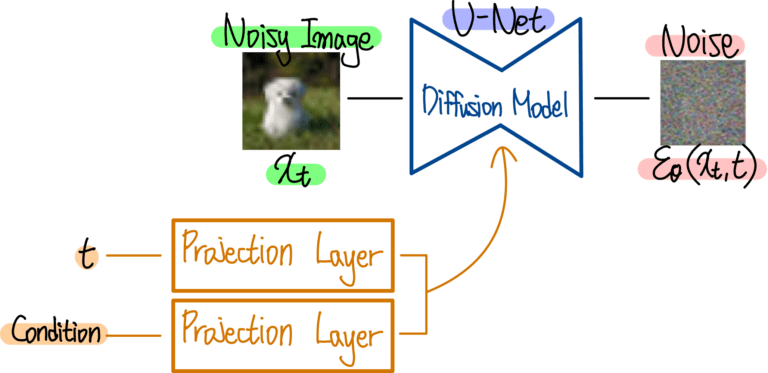
UNet: Input과 동일한 Resolution의 Output을 내기에 적절한 구조
2.4 Loss function
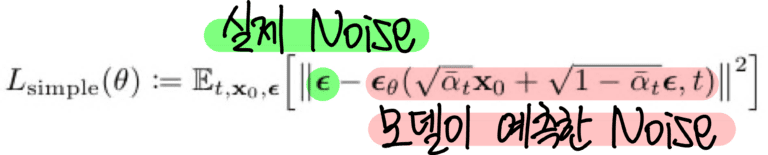 각 픽셀마다 첨가된 Noise를 예측, GT와 차이가 줄어나가는 방향으로 학습
각 픽셀마다 첨가된 Noise를 예측, GT와 차이가 줄어나가는 방향으로 학습
3. Diffusion Model 응용하기
3-1. Class Guided Image Generation
내가 원하는 Class의 이미지만 생성하는 방법
예를 들어 ImageNet 데이터셋을 학습한 Diffusion Model이 있다고 가정해볼 때, 100개의 클라스 중 내가 원하는 클래스의 이미지만 생성하는 방법.
1. Classifier Guidance


(2022년 NIPS에 발표된 Diffusion Models Beat GANs on Image Synthesis 논문)
먼저 noisy image를 사용해서 classifier 학습함
-> classifier는 freeze하고, 학습된 classifier로부터 나오는 gradient가 diffusion model이 학습하는 과정에서 guidance 역할
ex. 강아지 이미지 생성하고 싶다면, 고양이 이미지를 생성하려고 할 때마다 큰 gradient를 보내서 방향을 틀어줌
2. Classifier Free Guidance
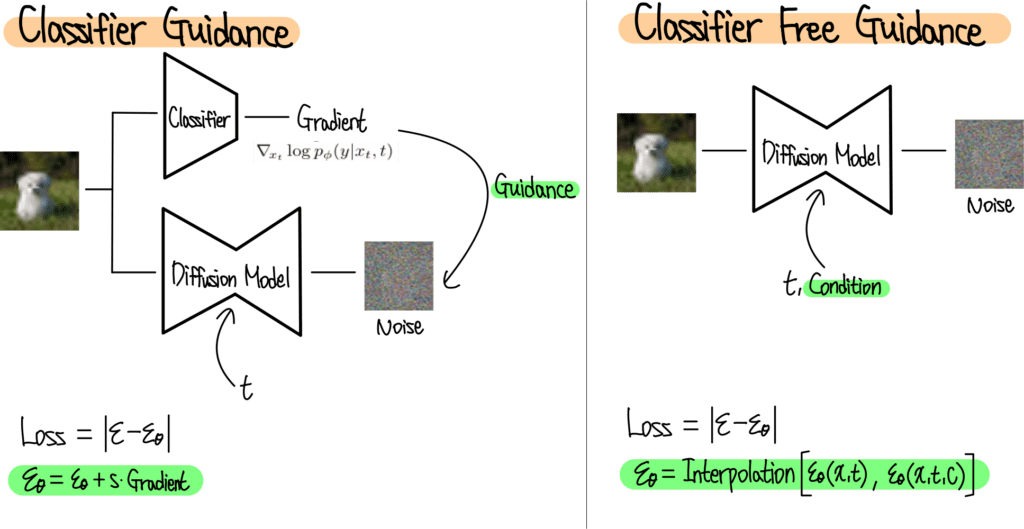
(2021년 NIPS Workshop에 발표된 Classifier-free diffusion guidance 논문)
classifier guidance가 classifier를 별도로 학습해야 하기에 귀찮기 때문에, classifier없이 한번에 guidance하는 방법 제안
즉, classifier대신에 condition 사용함
원래 Diffusion Model에서는 t를 Positional Encoding 방식을 통해 Condition으로 입력해주는데 유사한 방식으로 Class 정보 또한 Condition으로 Diffusion Model에 입력해줌
이렇게 Diffusion Model은 Condition을 받았을때와 받지 않았을때 두 가지의 Noise를 예측하게 됨. 최종적으로는 이 둘의 Interpolation을 통해 최종 예측 Noise를 계산
 w가 0일때는 다양한 형태의 이미지가 생성되는 모습
w가 0일때는 다양한 형태의 이미지가 생성되는 모습
w가 커질수록 특정 형태의 이미지만 생성됨
3-2. Super-Resolution
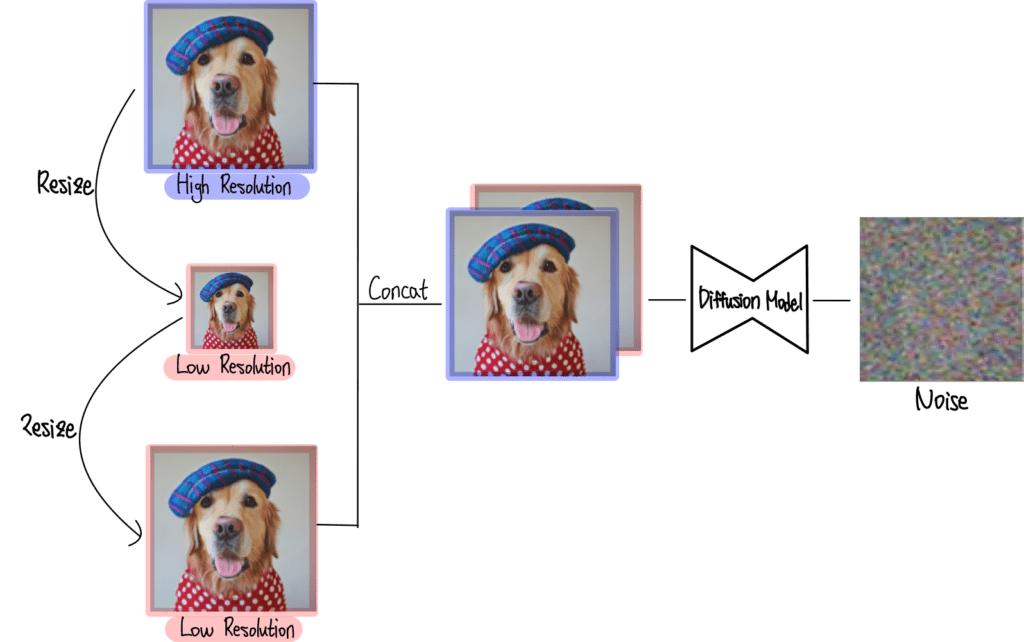
Super-Resolution이란 저화질 이미지를 고화질 이미지로 변환하는 작업
Diffusion Model의 입력으로 High Resolution 이미지와 Low Resolution 이미지가 들어감
이렇게 학습한 Diffusion 모델은 Low Resolution 이미지만을 받아서 High Resolution 이미지를 생성

3-3. Inpainting
Inpainting이란 이미지의 가려진 부분을 그럴듯하게 채워 넣는 기술

Diffusion Model의 입력으로 Mask 처리된 이미지가 들어가고
Mask 정보는 Condition으로 주어짐
그럼 Diffusion 모델은 Mask 처리된 부분의 원래 모습을 예측하도록 학습해줌
3-4. Text Guided Image Generation (T2I)
3-4-1. GLIDE (OpenAI)
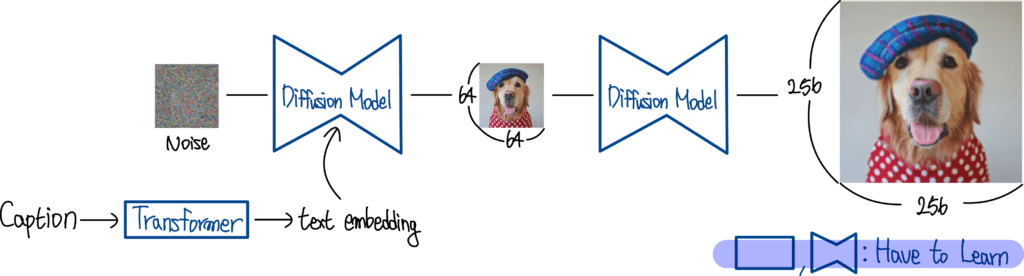
- Text Embedding을 학습하는 Transformer
- 이미지 생성을 위한 Diffusion Model
- Super-Resolution을 위한 Diffusion Model
이후 발표된 모델들과의 결정적인 차이라고 한다면 Text Embedding을 학습하기 위한 Transformer
-> 이후 모델들은 Text Embedding을 이렇게 따로 학습하지 않고 대규모 언어 데이터로 학습한 Pretrained Text Encoder를 사용함
3-4-2. Imagen (Google Research)
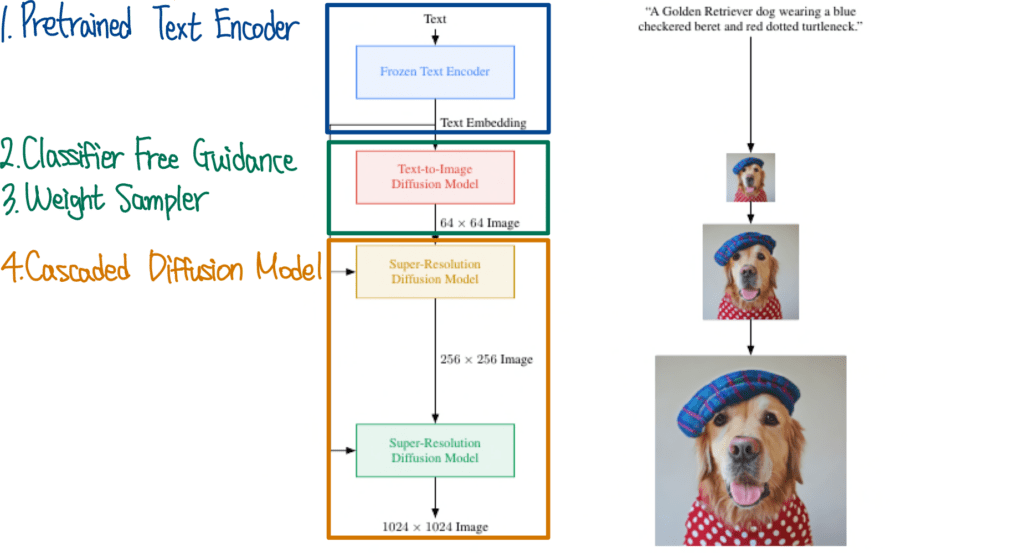
GLIDE와 비슷한 구조를 하고 있지만 Pretrained Text Encoder를 사용했다는 점과 더 고화질의 Super-Resolution을 수행했다는 차이

3-4-2. DALLE2
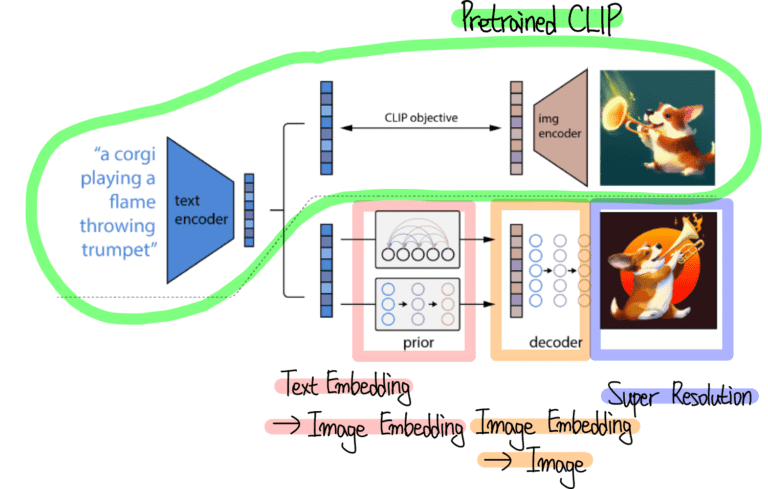
Pretrained CLIP을 사용하여 Text와 Image의 Embedding을 추출함
Prior와 Decoder로 표현되어 있는 Diffusion Model에서는 각각 Image Embedding과 이미지를 생성하도록 학습하는 모습

또한, DALLE2에서는 이미지 생성뿐만 아니라 이미지 조작 (Manipulation) 방법도 제안
3-5. Multi Modal Guided Image Generation
3-4 모델들의 한계는, Condition으로 Text만 입력받을 수 있다는 것
bounding box를 condition으로 입력 받을 수는 없을까?

이를 해결한 모델 Stable Diffusion
Stable(Latent) Diffusion Model은 AutoEncoder를 사용해 이미지를 압축한 후 DIffusion model을 학습해줌
-> 계산량도 줄고, semantic한 부분에 더 초점을 맞출 수 있음
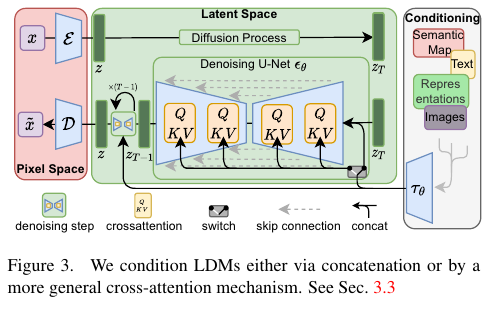
- 가장 왼쪽의 빨간색 음영 부분은 Auto Encoder
- 가운데 초록색 음영 부분은 Latent Diffusion Model
- 오른쪽의 회색 음영은 Condition 입력 부분
이렇게 입력된 Condition은 Diffusion Model 내부에서 Cross Attention 연산을 사용하여 적용됨


3-6. Multi Modal Input Image Generation
-
Stable Diffusion에도 한계: 다양한 형태의 Condition을 입력으로 받을 수 있지만, 하나만 선택해야 함. 예를 들어 Text와 Layout을 동시에 입력으로 받을 수는 없음..
--- 여러 개도 입력 받을 수 있게 해결 완 -
게다가 Diffusion Model을 처음부터 학습하기 위해서는 엄청난 Computing Resource를 필요로 함
--- Diffusion Model의 모든 가중치는 고정한 채 새로 추가된 모듈만 학습
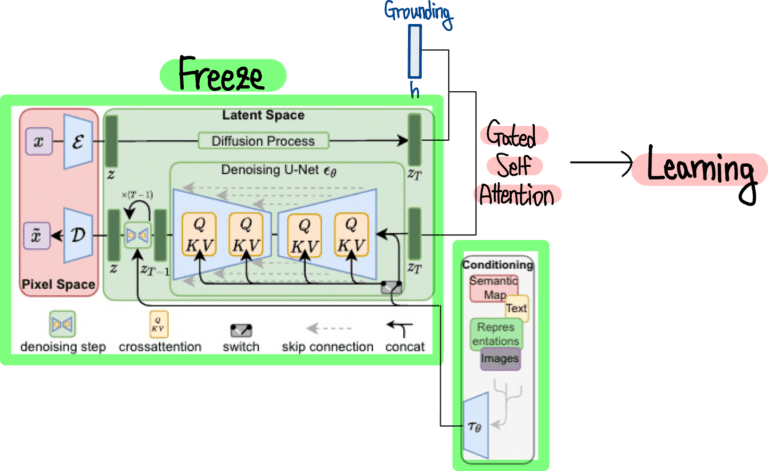
이를 해결한 모델 GLIGEN
몸통 부분은 Stable Diffusion이 그대로 들어있는 모습, 이 외에 Grounding 정보를 연산하기 위한 Gated Self Attention 부분만 추가
- Grounding은 Layout과 같이 Text 외의 추가 정보를 의미
GLIGEN은 Stable Diffusion 부분은 Freeze 한 채로 Gated Self Attention 부분만 학습해줌

Caption과 다양한 형태의 Grounding을 입력 받아 이미지를 생성하고 있는 모습
- Key Points, Depth Map, HED Map, Normal Map, Semantic Map 등 다양한 형태의 Grounding을 입력 받음
