Lab-10-1 Convolution
Convolution?
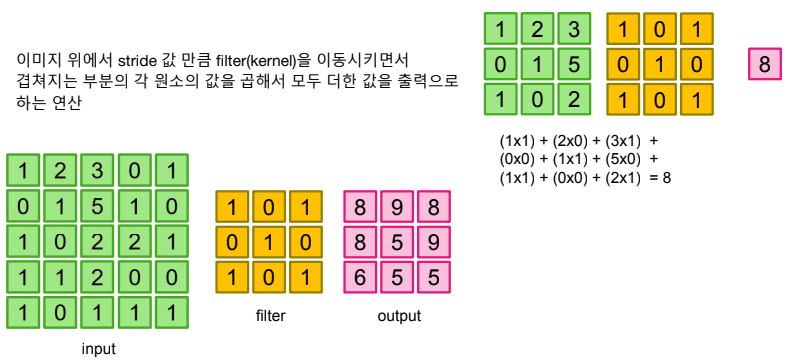
Stride and Padding
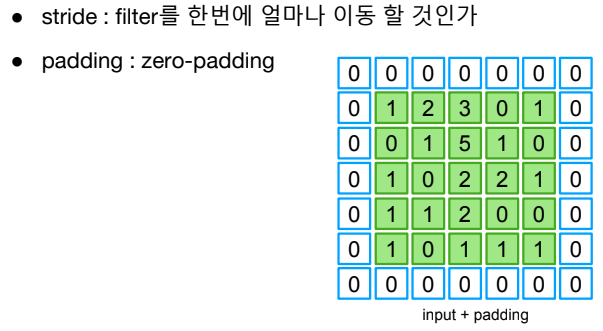 padding이 1이 적용되었을 때 결과는 다음과 같다.
padding이 1이 적용되었을 때 결과는 다음과 같다.
Pytorch nn.Conv2d
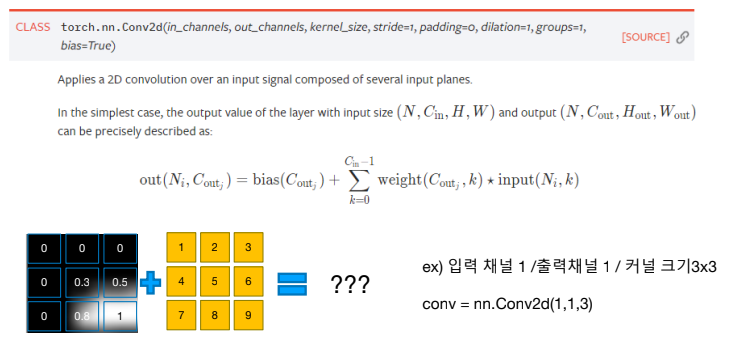 여기서 dilation과 group에 대해서는 설명 x, 많이 쓰이지 않기 때문
여기서 dilation과 group에 대해서는 설명 x, 많이 쓰이지 않기 때문
- in_channel: 입력 채널의 개수
- out_channel: 커널의 개수 = 출력 채널
- 만약 커널 사이즈를 위의 예제처럼 3x3이 아닌 다르게 설정하고 싶다면 kernel_size 자리에 (2,4) 이렇게 설정하면 된다.
- 위의 conv는 지금 필터에 대한 코드임
입력의 형태
 conv = nn.Conv2d(1,1,3) 이렇게 설정한 후에
conv = nn.Conv2d(1,1,3) 이렇게 설정한 후에
out = conv(input) 이러한 코드 짤 때 input의 꼴은 이렇게 따라야 함.
Convolution의 output 크기
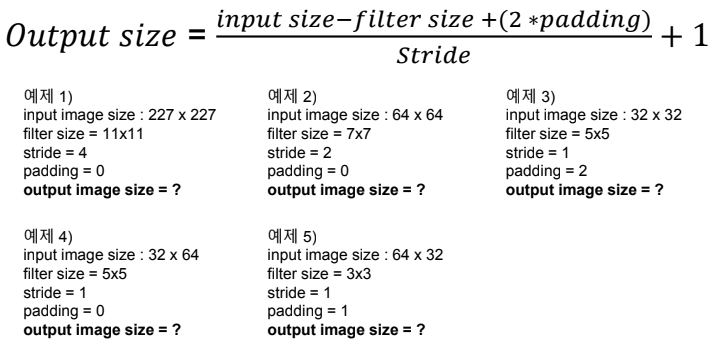
예제1:
예제2:
예제3: (input size와 동일)
예제4:
예제5:
import torch
import torch.nn as nn
conv = nn.Conv2d(1,1,11,stride = 4,padding=0)
inputs = torch.Tensor(1,1,227,227)
out = conv(inputs)
out.shape
torch.Size([1, 1, 55, 55])Neuron과 Convolution
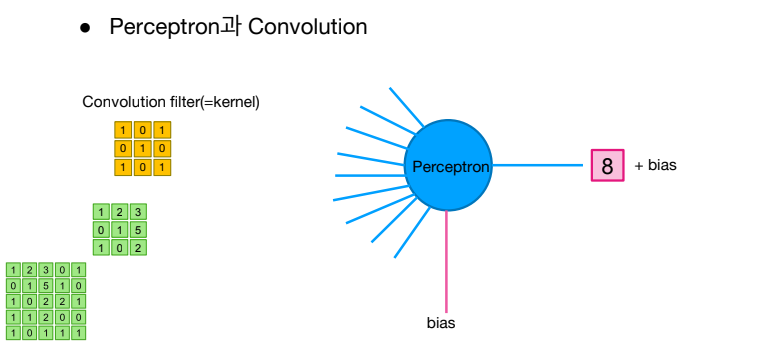
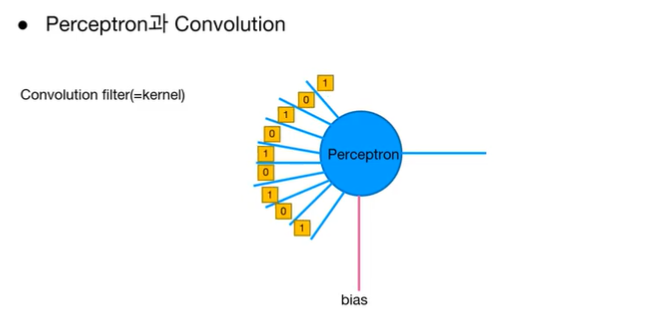 커널에 있는 값들이 perceptron의 weight값으로 처리됨.
커널에 있는 값들이 perceptron의 weight값으로 처리됨.
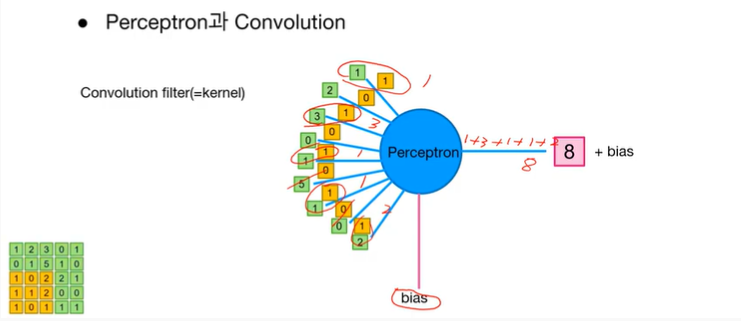 연산은 이와 같이 이루어진다. 마지막에 bias도 합하게 되는거 잊지 말기!
연산은 이와 같이 이루어진다. 마지막에 bias도 합하게 되는거 잊지 말기!
Pooling
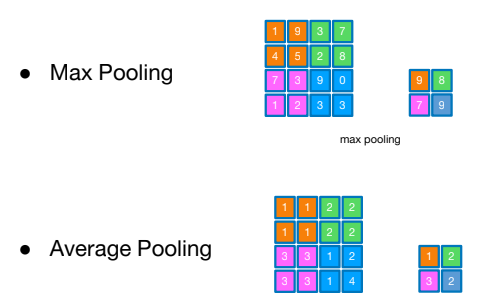
Max Pooling: 가장 큰 값으로 취함
Average Pooling: 평균으로 취함
MaxPool2d
 여기서는 kernel size만 집중해서 보면 될 듯!
여기서는 kernel size만 집중해서 보면 될 듯!
CNN implementation
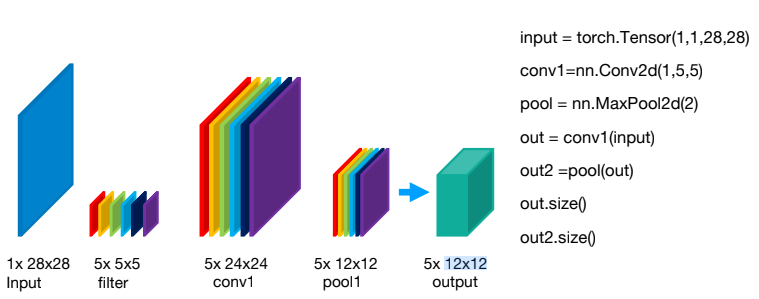
input = torch.Tensor(1,1,28,28)
conv1 = nn.Conv2d(1,5,5) # 필터의 개수 5개, 필터 사이즈 5
pool = nn.MaxPool2d(2) # 커널 사이즈를 2로 하겠다는 뜻
out = conv1(input)
out2 = pool(out)
print(out.size(),out2.size())
torch.Size([1, 5, 24, 24]) torch.Size([1, 5, 12, 12])One More thing!
 convolution연산을 보면 ..! 왜 cross-correlation에 대한 연산으로 계산을 할까?
convolution연산을 보면 ..! 왜 cross-correlation에 대한 연산으로 계산을 할까?
ANS
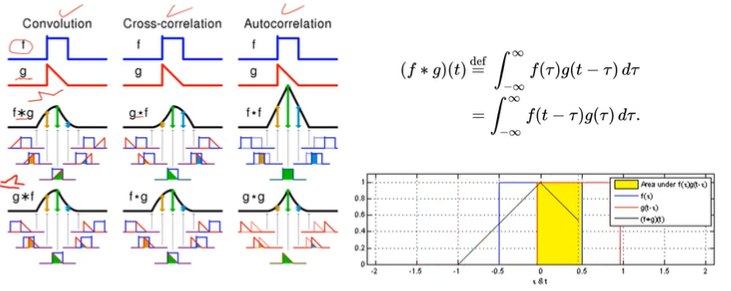
convolution이란 filter가 input image와 얼마나 유사한지를 알아보는 것.
Convolution을 자세히 보며, 를 봤을 때 와 뒤집어서 나타나는 것을 알 수 있음. 그에 반해 Cross correlation은 뒤집어지지 않고 있음
 실제 딥러닝을 사용할 때는 cross-correlation과 convolution을 혼동할 필요가 없기 때문에 그렇다~정도로 넘어가기
실제 딥러닝을 사용할 때는 cross-correlation과 convolution을 혼동할 필요가 없기 때문에 그렇다~정도로 넘어가기
Lab-10-2 mnist cnn
MNIST에 CNN 적용해보기
1. 딥러닝을 학습시키는 단계

2. 우리가 만들 CNN 구조 확인
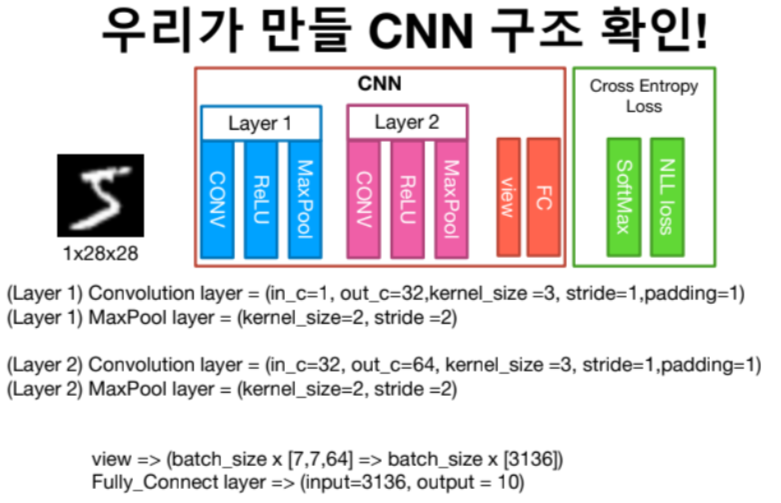
3. MNIST에 CNN 적용 코드를 함께 작성
#1) 라이브러리 가져오기

#2) GPU 사용설정
 코랩 이용해야 할 듯.. 내 주피터에서 cuda 설정 쉽지 않네
코랩 이용해야 할 듯.. 내 주피터에서 cuda 설정 쉽지 않네
#3) Parameter 결정

#4) 데이터셋 가져오고 loader 만들기


#5) 학습모델 만들기 (CNN)

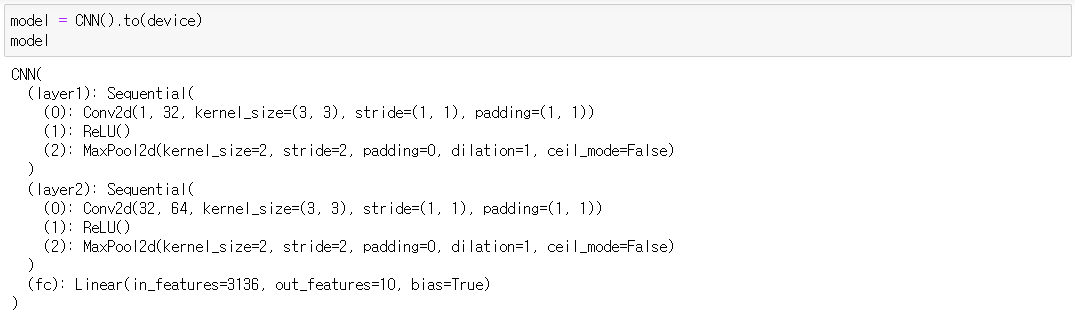
#6) Loss function & Optimizer

#7) Training
 직접 트레이닝 하지 못해서 강의 이용
직접 트레이닝 하지 못해서 강의 이용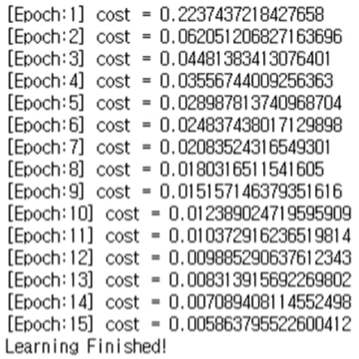
#8) Test model Performance


Q. 더 깊게 레이어를 쌓으면 결과가 더 좋을까?
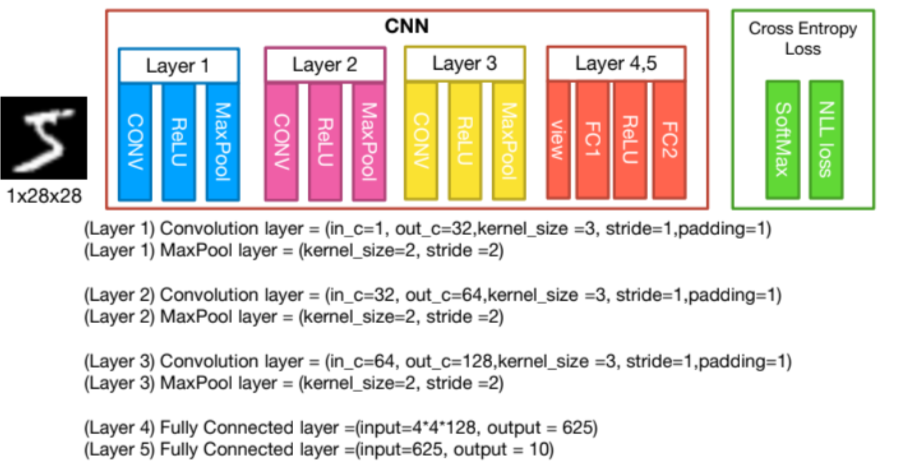
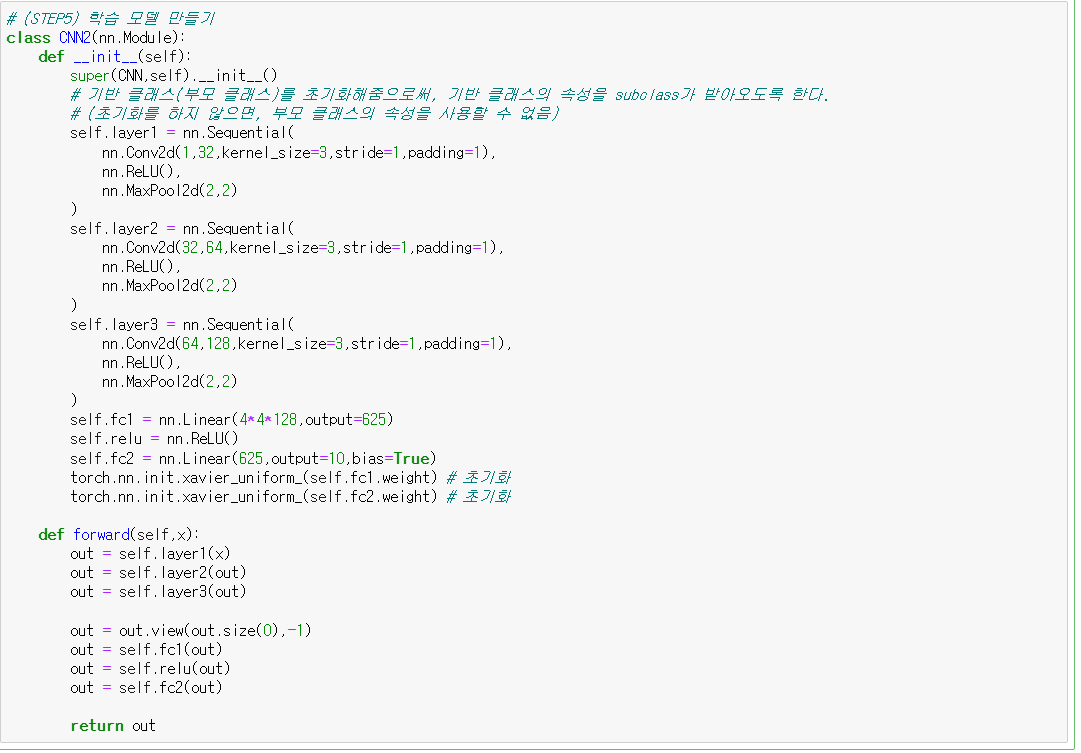 * 코드수정: self.fc1 33*128
* 코드수정: self.fc1 33*128
학습 모델 코드를 다음과 같이 추가하면 된다 :D

결과: accuracy가 더 낮은 것을 확인할 수 있었는데
즉, 단순히 layer를 더 쌓는다고 accuracy가 높아지는 것은 아니라는거!
다른 아키텍처를 더 알아볼 것
Lab-10-3 visdom
Visdom 사용법
실제 학습에 적용해보기
