핵심키워드
- 텐서(Tensor)
- 넘파이(NumPy)
- 텐서 조작(Tensor Manipulation)
- 브로드캐스팅(Broadcasting)
- View, Squeeze, Unsqueeze, Type Casting, Concatenate, Stacking, In-place Operation
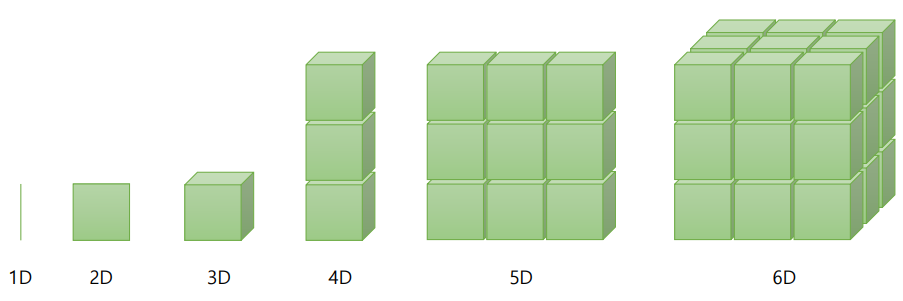
Vector, Matrix, and Tensor
 scalar : 0차원
scalar : 0차원
vector : 1차원
matrix : 2차원
tensor : 3차원 이상
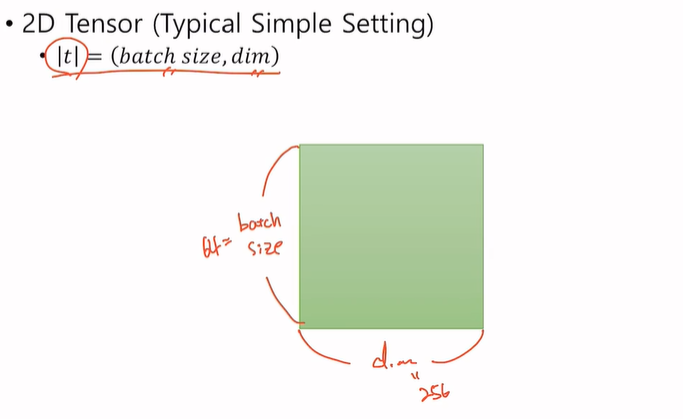
Pytorch Tensor Shape Convention
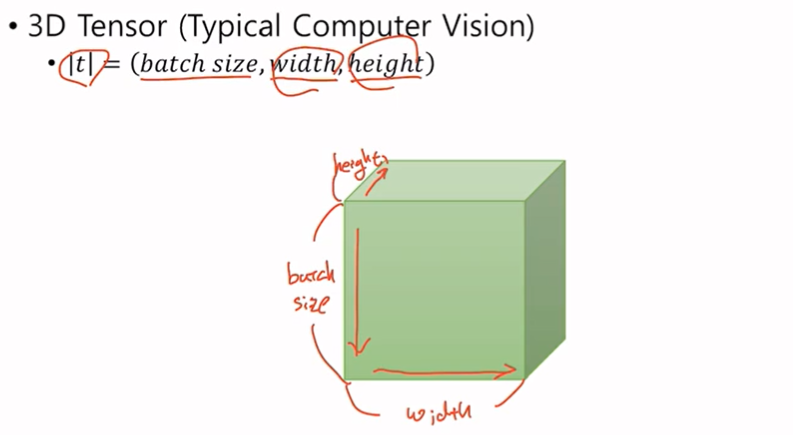
CV에서는 (첫번째 차원의 값 = 세로, 두번째 차원의 값 = 가로, 세번째 차원의 값 = 깊이) 기본적으로 이러한 형태를 따른다. 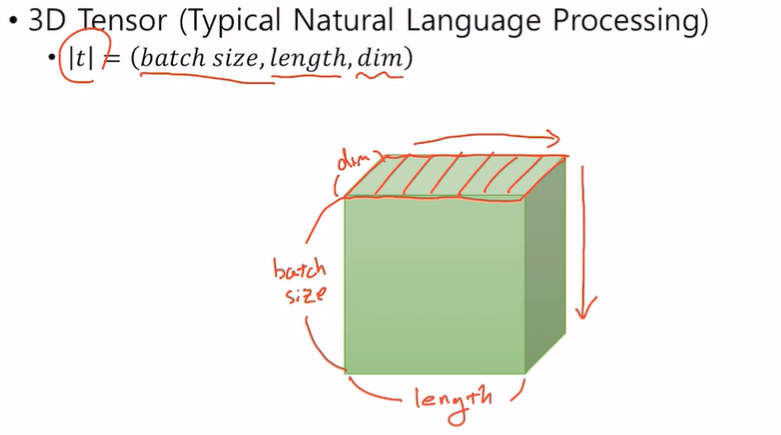
NLP 에서는 색칠된 부분이 하나의 문장을 이루게 되고 batch size만큼 문장이 존재한다. (CV도 마찬가지)
NumPy Review


이제 파이토치로 알아보자
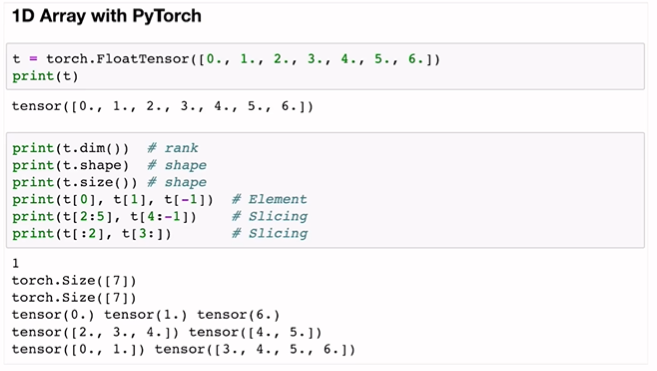
torch.FloatTensor([])
t.dim()
t.shape
t.size()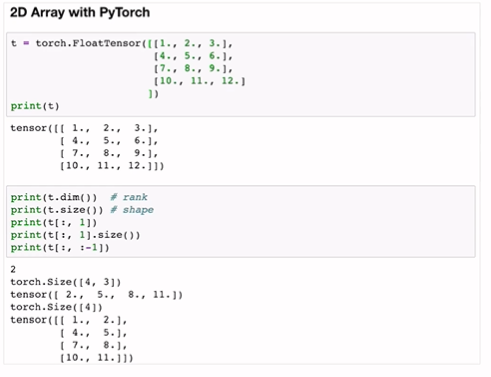
Broadcasting
다른 크기의 tensor를 연산할 때는 주의해야 함
(자동적으로 같은 크기로 변환하여 계산해주기 때문)

내가 의도한 연산이 맞는지 주의해야 함
Multiplication vs Matrix Multiplication

elementwise의 곱인지 행렬곱인지
m1.matmul(m2)
mq.mul(m2)Basic Ops
Mean
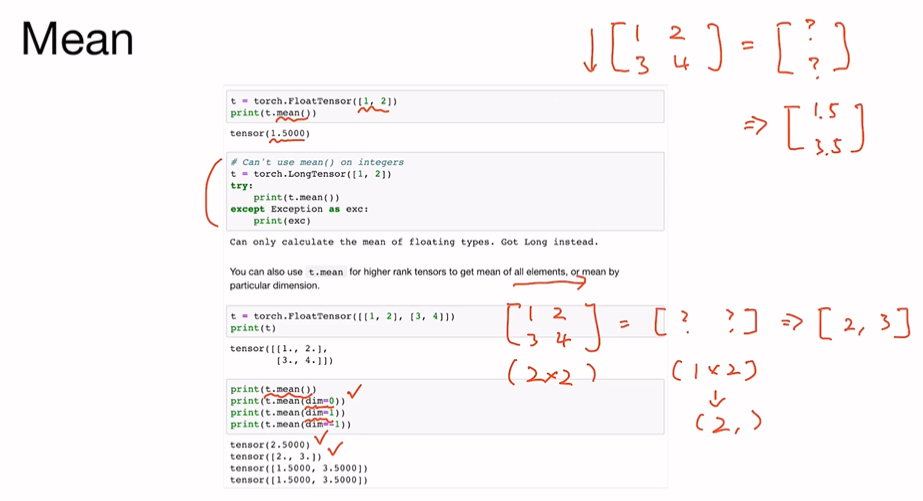
t.mean(dim=?)Sum
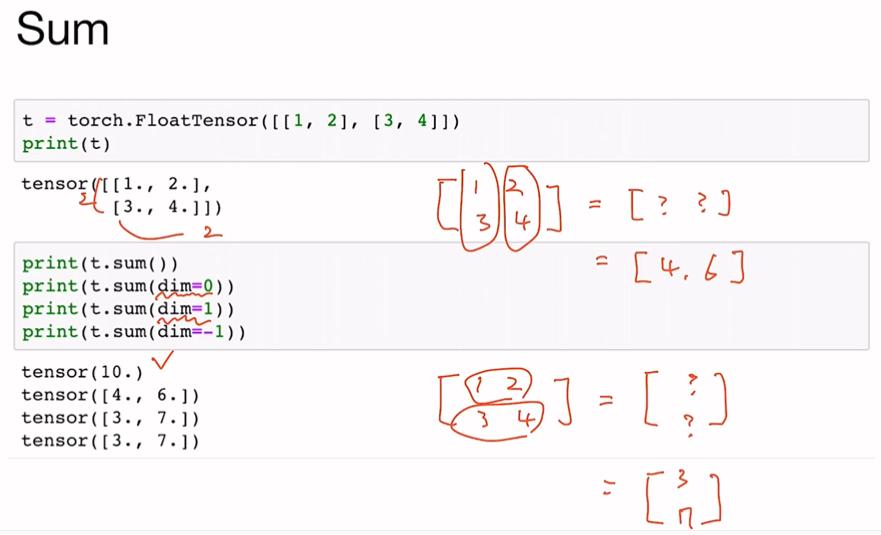
t.sum(dim=?)Max and Argmax

t.max(dim=?)이때는 argmax까지 반환을 해준다는 사실!
View (Reshape)

ft.view([-1,3])위와 같은 코드일 때,
앞에는 모르겠고 두번째 차원은 3개의 element를 갖도록!
-1을 주는 이유?
: 직접 우리가 계산하지 않고, new차원의 행렬을 만들 수 있음 (실수 down)
딥러닝에서 매우 중요한 함수
Squeeze
view함수처럼 차원을 바꿔주는데
squeeze는 특정 dimension의 element가 1이면 => 알아서 삭제해줌

ft.squeeze(dim=?)차원을 지정해줄 수 있는데, element가 1일 때만 squeeze효과가 일어남
Unsqueeze
squeeze를 반대로
원하는 dimension에 차원 1을 넣어줌
반드시 dimension을 지정해줘야함!
- view로도 똑같이 구현 가능

ft.unsqueeze(dim=?)Type Casting

lt.float()
lt.long()
torch.ByteTensor([])long타입의 텐서, float타입의 텐서를 만들 수 있다는거
Concatenate
이어붙인다는 뜻

torch.cat([x,y],dim=?)Stacking
쌓는다는 뜻

torch.stack([x,y,z],dim=?)Ones and Zeros
x와 똑같은 사이즈의
0으로 가득찬 or 1로 가득찬 텐서 만들어짐
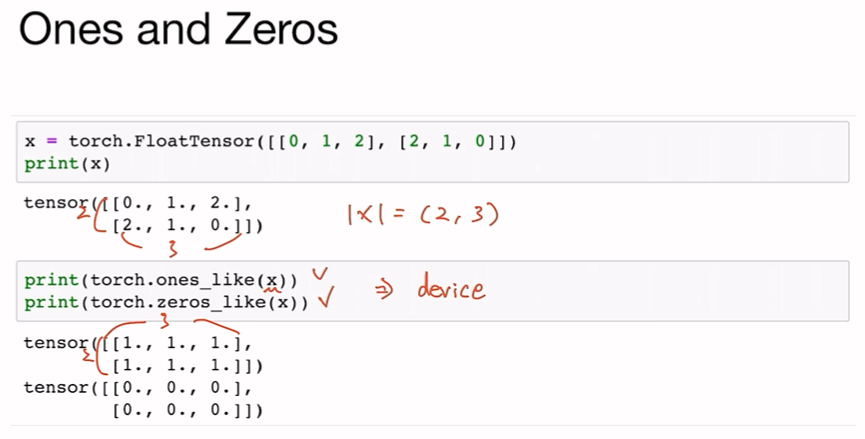
torch.ones_like(x)
torch.zeros_like(x)In-place Operation
덮어쓰기 연산
새로 선언하지 않고 텐서에 바로 적용하라는 뜻
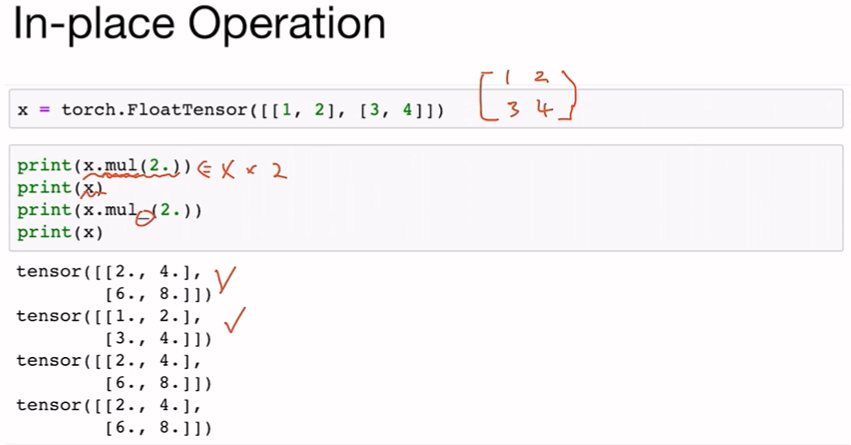
x.mul(2.)
x.mul_(2.)
정리된 글은 https://dusruddl2.tistory.com/로 이동