[paper review] Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
논문Review
https://www.youtube.com/watch?v=EYWHjrW-Xoo
다음 영상을 보고 기록하였습니다.
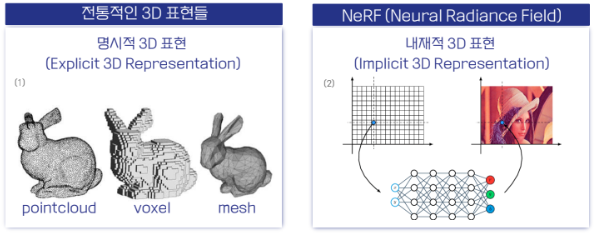
전통적인 3D 표현 vs NeRF


NeRF는 해당 물체를 모든 방향에서 봐도 이미지를 생성해서 볼 수 있다면 3D 렌더링했다고 간주함.
(기존에 3D 공간 자체가 정의되었던 방식과 차이가 있음!)
[장점]
- 매우 작은 값으로 방향을 바꾸어도 해당 Scene을 생성할 수 있기 때문에 부드러운 표현 가능
- 3D 지도 같은 경우, 이를 NeRF가 아닌 3D Point나 Mesh로 표현하면 엄청난 메모리가 필요함.
그러나 NeRF는 View Synthesis이기 때문에 사용되는 메모리는 매우 작고 생성하는데 매우 빠름
NeRF (ECCV 2020)

Structure from Motion을 위해 COLMAP을 많이 사용.
본래 COLMAP은 이미지로 3D Point를 생성하기 위해 사용하지만, 3D Reconstruction할 때 카메라 포즈를 뽑는데도 사용 가능
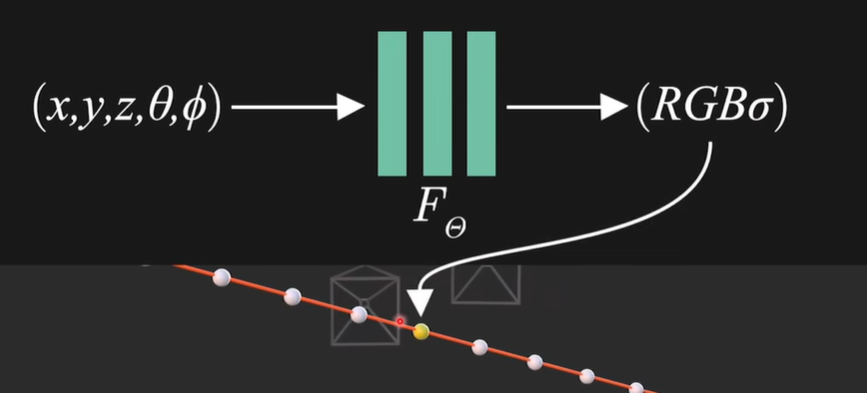
네트워크 구조 | Positional Encoding

MLP에 입력되는 위치와 방향값은 그냥 입력되는 것이 아니라
Positional Encoding을 통해 고차원으로 매핑하여 입력됨! (like Data augmentation)
 이와 같이 Positional Encoding을 하지 않으면, 고주파를 학습하지 못해서 화질이 낮음
이와 같이 Positional Encoding을 하지 않으면, 고주파를 학습하지 못해서 화질이 낮음
- (x,y,z) 3차원 -> 60차원 (L=10)
- () 2차원 -> 24차원 (L=6)
=> 고주파 부분도 학습 가능
Instant NeRF

Positional Encoding 대신에
Multi-resolution Hash Encoding
- 기존 9개의 Layer -> 3개의 Layer
- 각 Layer의 차원 수 256 - > 64
(Simple MLP)
=> 학습 속도 빠르게 향상
해당 샘플 포인트를 기준으로 정사각형이 감싸게 됨
(그림은 정사각형이지만, 실제 3D에서는 정육면체 voxel)
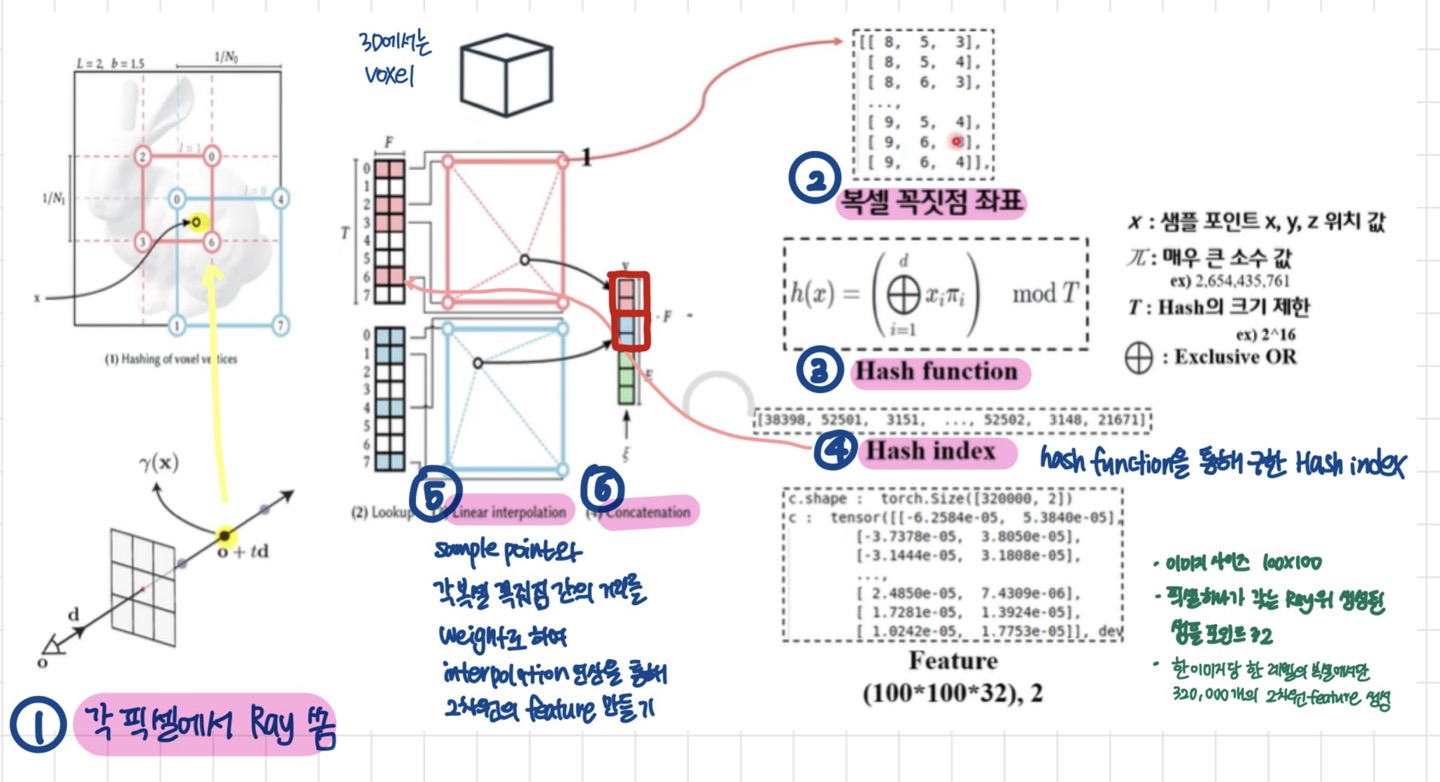
Multiresolution Hash Encoding의 내용은 다음과 같다.
1. ray를 쏘는 pixel 기준으로 샘플 포인트를 고른다
2. pixel 위에는 다양한 정사각형(2D), 혹은 voxel(3D)가 생길 것인데 (#levels에 따라 개수는 다르겠지만) -> 이들의 꼭짓점 좌표를 저장한다
3&4. 그리고 hash function을 통과시켜 hash index값을 구한다
5. hash table을 참고하여 hash index에 해당하는 feature vector을 각 꼭짓점마다 구하고 이들을 interpolation을 통해 2차원의 feature vector 만들기
6. 다른 정사각형(2D) or voxel(3D)과도 concatenation하여 하나의 최종 vector을 만들기
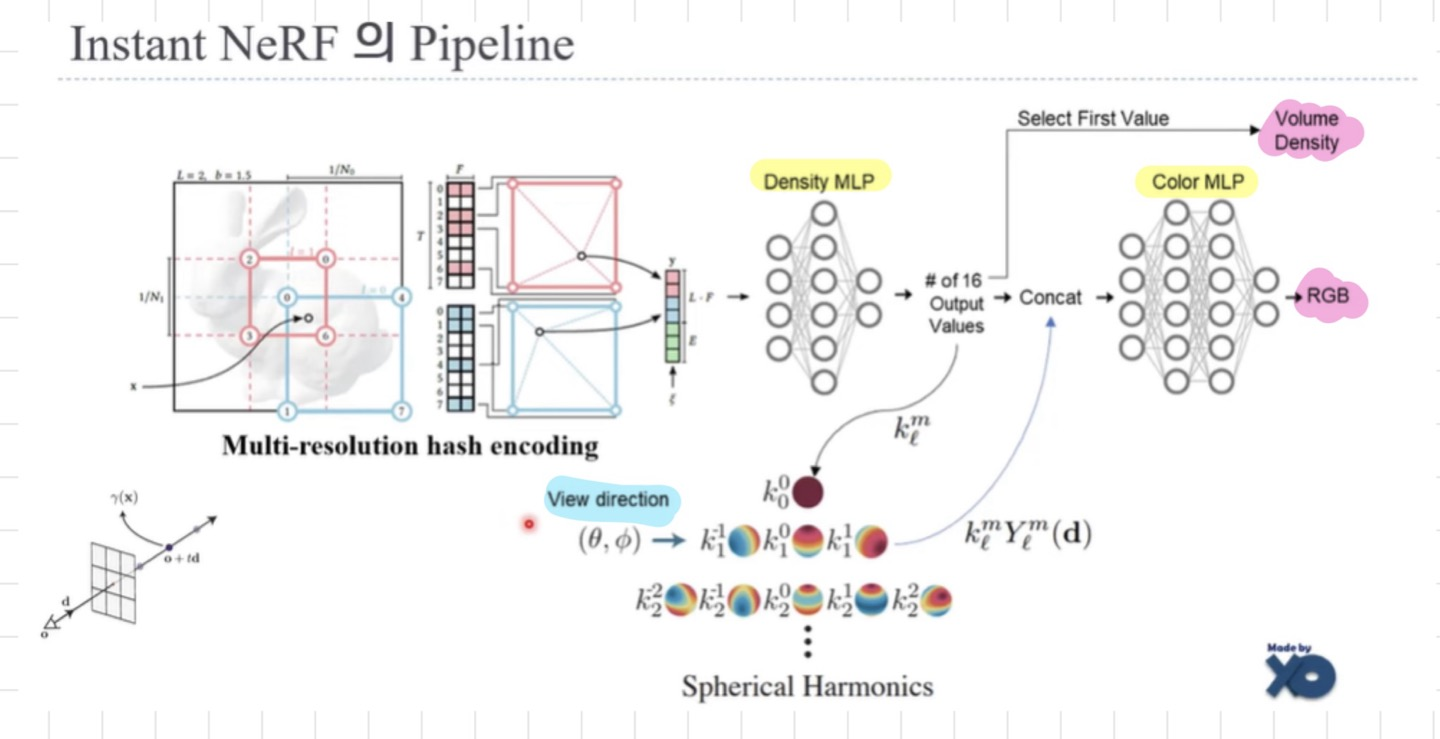
최종 파이프라인은 다음과 같다
- 먼저 위치 정보를 Density MLP에 통과시켜 Volume Density를 구하고
- 결과값을 View direction과 concat한다
- 이후 concat된 벡터를 Color MLP를 통과시켜 RGB값을 구함
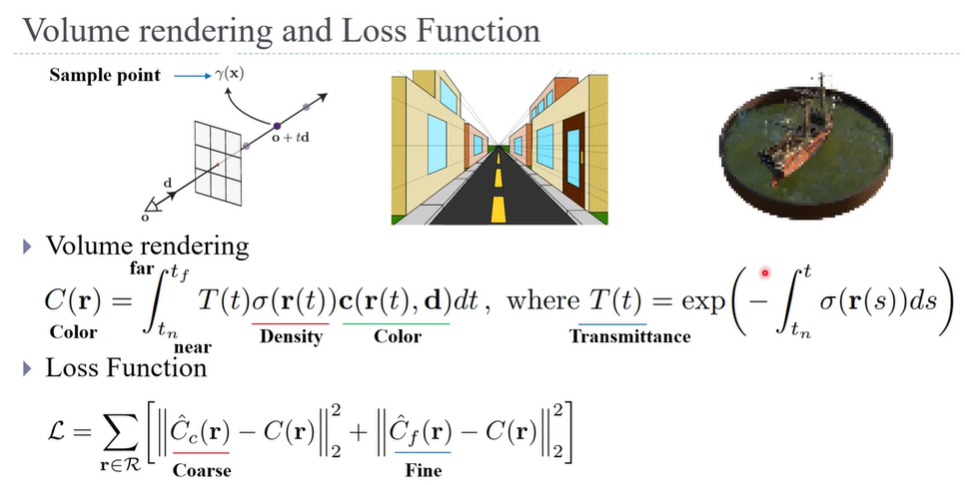 Volume rendering과 Loss function은 기존과 동일함
Volume rendering과 Loss function은 기존과 동일함
Volume Rendering
: Ray위에 있는 모든 샘플포인트를 합쳐 하나의 최종 Pixel color값을 만들어줌
Loss function
: 실제 Ground truth color값과 예측된 pixel color 값을 L2 Loss에 입력하여 학습
NeRF의 한계

각 pixel은 가까운 곳과 먼 곳을 촬영할 때 포함하는 범위가 다름
(ex. 바로 앞에 있는 픽셀과 저 도로 끝에 있는 한 픽셀과는 실제 포함하는 범위가 다름)
그러나 NeRF에서는 이러한 점을 고려하지 않고 직선형태의 Ray로 sampling했기 때문에 이미지가 깨지는 Aliasing 문제 발생
- 에일리어싱은 샘플링 또는 시그널처리에서 발생하는 현상으로, 고주파 구성 요소가 샘플링 또는 재구성 과정에서 잘못된 낮은 주파수로 해석되어 발생합니다. 이를테면, 렌더링된 이미지에서 세부적인 구조나 선명한 경계가 모호하게 나타나는 현상
이를 해결하기 위해
Mip-NeRF, sample point를 가우시안 분포를 따르는 원뿔대 상의 점으로 가정함으로써 해결
- 멀리 있는 곳에서는 더 큰 범위를 커버
그리고 Mip-NeRF와 Instant NGP를 결합한 Zip-NeRF기법이 SOTA 기록
