논문Review
1.Attention 모델

https://codingopera.tistory.com/41위의 블로그를 공부하며 정리한 내용입니다Attention: 문맥에 따라 집중할 단어를 결정하는 방식(그림: 한/영 번역에서의 Attention 예시)우리가 글을 읽을 때 모든 단어들을 집중해서 읽지
2.Transformer(Self Attention)
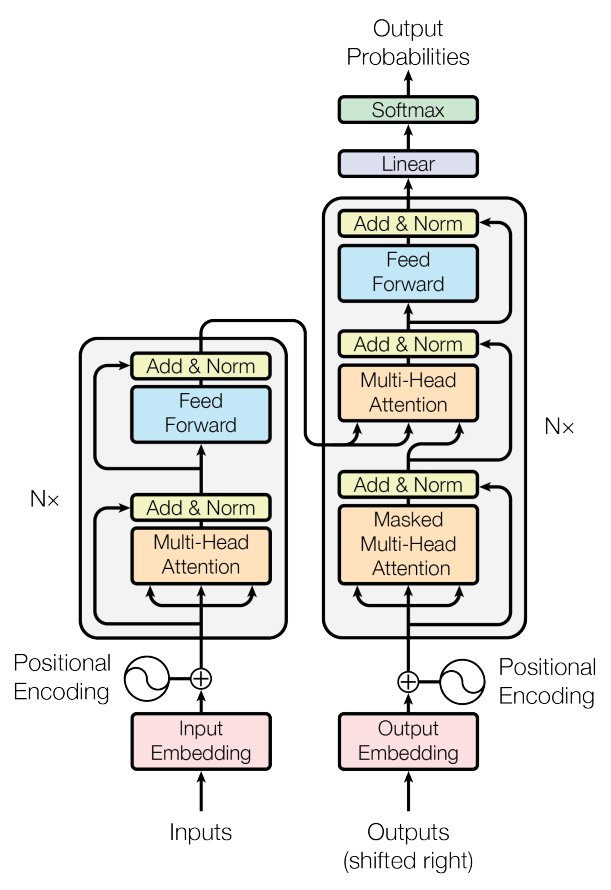
https://codingopera.tistory.com/43출처) 놀랍도록 설명을 너무 잘해주신 블로그Transformer 모델은 RNN없이 Attention만으로 이루어진 encoder-decoder 구조의 seqence to seqence 모델기존의 RN
3.Self-positioning Point-based Transformer for Point Cloud Understanding
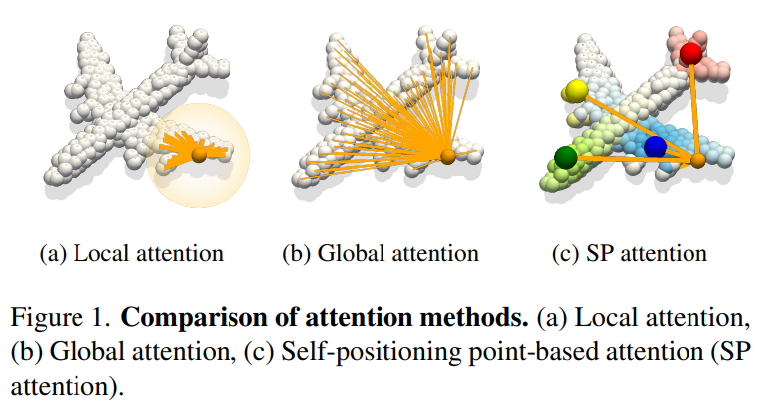
(추가자료)https://www.youtube.com/watch?v=-C6d83rXm1Ihttps://github.com/mlvlab/SPoTrPoint Cloud: 자율주행, 로봇공학, 증강현실 분야에 쓰임지금까지 진행된 연구에는 무엇이 있을까?Po
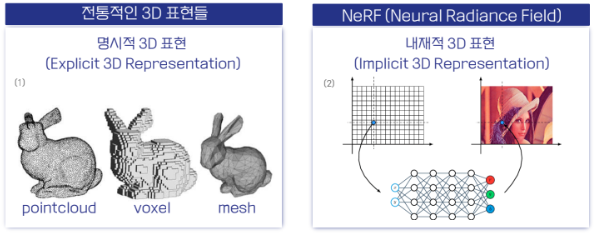
4.Point Cloud에 대해
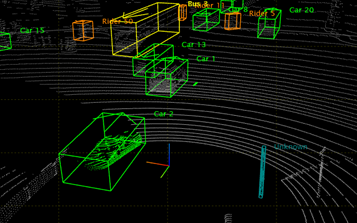
https://blog.testworks.co.kr/3d-ai-data-point-cloud/본문은 위 블로그에서 발췌하였습니다.Point Cloud: 현실에서 3D 공간 정보를 시각적으로 표현해 주는 데이터그렇기 때문에 3D 인공지능 연구 역시 Point C
5.[paper review] Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
Abstract 문제점) FCNN로 파라미터화가 된 Neural graphics primitives은 train하고 evaluate하는데 비용이 많이 듦 해결책) 'versatile new input encoding': 더 작은 네트워크에도 품질 저하 없이 학습됨 작은
6.diffusion model latent vector

Latent Vector의 초기 상태:gpt 결과초기 상태의 latent vector는 랜덤 노이즈로 초기화됩니다.이 노이즈는 정규 분포에서 샘플링된 값으로 채워지며, 이는 의도적으로 "노이즈가 많은" 상태입니다.이 초기 latent vector는 깨끗한 이미지가 아니