https://blog.testworks.co.kr/3d-ai-data-point-cloud/
본문은 위 블로그에서 발췌하였습니다.
Point Cloud
Point Cloud: 현실에서 3D 공간 정보를 시각적으로 표현해 주는 데이터
그렇기 때문에 3D 인공지능 연구 역시 Point Cloud 데이터 위주로 활발히 이루어졌다.
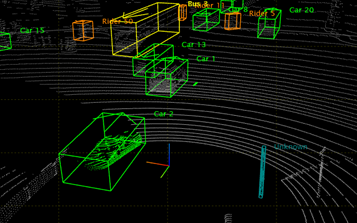
이미지 데이터와 마찬가지로 Point Cloud 데이터를 기반으로 한 Classification, Object Detection, Semantic Segmentation 등의 연구가 이루어졌다.
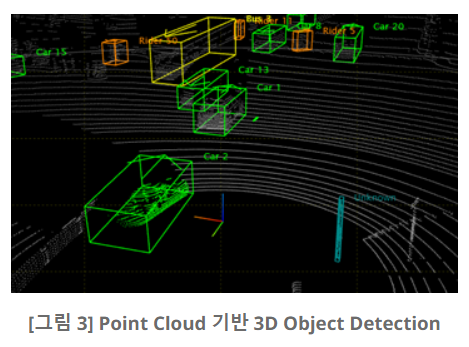
불과 몇 년 전 까지만 해도 Point Cloud 데이터를 다루는 딥 러닝 모델은 거의 찾아볼 수가 없었다. 이는 Point Cloud 데이터가 가진 몇 가지 성질에 의해 딥 러닝을 통한 해석이 매우 어려웠기 때문이다.
한계1) 정렬되지 않고 정형화되어 있지 않은 데이터

Point Cloud 데이터는 2D 이미지 데이터와 달리 정형화 되어있지 않다. 2D 이미지 데이터의 경우 정해진 격자 구조의 형태 안에 정보가 저장되지만, Point Cloud 데이터는 3D 공간상의 수많은 점들을 순서 없이 기록하는 방식으로 데이터가 저장된다.이러한 데이터는 딥 러닝 모델에 있어서는 상당히 치명적이다. 객체의 형상, 점들 간의 상호작용 등 데이터가 가지고 있는 기하학적인 특성을 파악하기가 상당히 어렵기 때문이다.
한계2) Sparse한 성질을 지닌 Point Cloud 데이터

2D 이미지 데이터가 정해진 격자에 pixel 값이 모두 존재하는 dense한 특성을 지녔다면, Point Cloud 데이터는 매우 sparse한 성질을 가지고 있다. 부연 설명을 하자면, 주어진 데이터의 3D 공간 안에는 Point들에 비해 빈공간이 상당이 많다는 것이다. 이러한 데이터는 크기에 비해 얻을 수 있는 유의미한 정보가 거의 없다.
이러한 데이터로 인공지능 모델이 학습 될 경우 유의미한 정보를 거의 얻기 어려우며, 학습 난이도만 올리게 된다. 이로 인해 3D 인공지능 모델은 좋은 성능을 보여주지 못했고, 오랜 시간 이 상태가 지속되면서 Point Cloud 데이터를 다루는 초기 3D 인공지능 모델은 한계를 보였었다.
Point Cloud 데이터를 다루는 3D 인공지능의 발전
단순히 Point Cloud 데이터를 전부 해석하는 것이 아니라, Point Cloud 데이터로부터 유의미한 정보를 추출하는 방식으로 연구가 이루어졌다.
PointNet을 시작으로 Point Cloud 데이터로부터 유의미한 정보를 추출하는 딥러닝 모델들이 좋은 성과를 보였다.
PointNet

PointNet은 데이터 형태의 변환 없이 Point Cloud 데이터를 그대로 입력해 주어 학습하는 모델이다. 초기 PointNet 모델은 Point Cloud 데이터의 Classification, Semantic Segmentation 수행이 가능하다.
VoxelNet
 VoxelNet은 Point Cloud 데이터로부터 Voxel Feature를 추출한 다음 이를 해석해 물체를 검출하는 3D Object Detection 모델이다.
VoxelNet은 Point Cloud 데이터로부터 Voxel Feature를 추출한 다음 이를 해석해 물체를 검출하는 3D Object Detection 모델이다.
Voxel Feature는 데이터의 3차원 공간을 Voxel 단위로 나눈 후 각 Voxel 안의 점들을 Voxel Feature Encoding Layer라는 딥러닝 네트워크를 거쳐 Feature Map을 얻어낸 것이다.
Point Cloud 데이터를 단순히 Voxel 형태로 전처리하는 것이 아니라 딥러닝 네트워크를 통해 Voxel 단위의 Feature Map을 만들어낸 것이 특징이다.
이러한 방법으로 얻은 데이터는 기존 방법보다 딥 러닝 네트워크를 통한 해석이 용이함이 실험을 통해 증명되었다.
SECOND
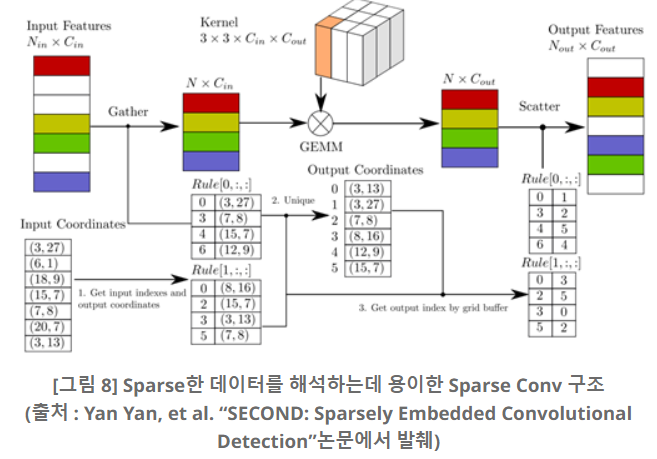
SECOND(Sparsely Embedded Convolutional Detection)는 VoxelNet과 기본적인 구조는 동일하지만 VoxelNet 내에 존재하는 Convolutional Middle Layer를 기존 CNN 대신 Sparse Conv Layer라는 레이어(SPCONV)를 사용하는 것이 특징이다. SPCONV는 반복되는 패턴에 대해 Rule을 설정하는 방식을 사용해 기존의 CNN에서 요구되는 계산 량을 대폭 낮췄다. 따라서 Point Cloud 데이터와 같이 매우 sparse한 데이터를 해석하는데 용이한 구조를 띄고 있으면서도 처리속도가 매우 빠르다.
PointPillars
 PointPillars는 Pillar라는 새로운 형태의 Point Cloud Encoder를 사용해 Point Cloud 데이터로부터 격자 형태의 Feature Map을 얻은 다음, 이를 해석해 물체를 검출하는 3D Object Detection 모델이다. VoxelNet이 3D Voxel 단위의 Feature Map을 얻어냈다면, PointPillar는 Point Cloud 데이터를 특정 시점에서 투영시킨 다음 2D 격자 단위의 Feature Map**을 얻어낸 것이 특징이다. 이렇게 얻어낸 Feature Map은 이미지 데이터와 동일하게 2D CNN을 통한 데이터 해석이 가능해지므로 처리 속도가 상당히 빠르다.
PointPillars는 Pillar라는 새로운 형태의 Point Cloud Encoder를 사용해 Point Cloud 데이터로부터 격자 형태의 Feature Map을 얻은 다음, 이를 해석해 물체를 검출하는 3D Object Detection 모델이다. VoxelNet이 3D Voxel 단위의 Feature Map을 얻어냈다면, PointPillar는 Point Cloud 데이터를 특정 시점에서 투영시킨 다음 2D 격자 단위의 Feature Map**을 얻어낸 것이 특징이다. 이렇게 얻어낸 Feature Map은 이미지 데이터와 동일하게 2D CNN을 통한 데이터 해석이 가능해지므로 처리 속도가 상당히 빠르다.
