강의 내용 복습
(05강) 1 Stage Detectors
2 Stage Detector(R-CNN family)은 Selective Search와 RPN과 같은 후보 영역을 찾는 모듈이 존재하여 객체를 더 정확하게 찾을 수 있다는 장점이 있습니다. 하지만 학습 시간이 오래 걸린다는 단점이 있어 아직 real-time으로 활용하기에 부족합니다.
이러한 문제를 해결하기 위해서 1 Stage Detector가 등장했습니다.
1 Stage Detector에서는 후보영역을 찾는 Localization 과정을 따로 수행하지 않고, 어떻게 Localization과 Classification을 동시에 할 수 있는지 주목
1. 1 stage Detectors
1.1 Background
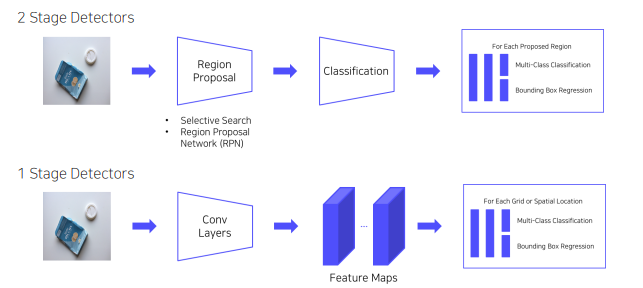
1- stage detectors
- Localization, Classification이 동시에 진행
- 전체 이미지에 대해 특징 추출, 객체 검출이 이루어짐 → 간단하고 쉬운 디자인
- 속도가 매우 빠름 (Real-time detection)
- 영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높음
- Background error가 낮음
- YOLO, SSD, RetinaNet, …
1.2 History
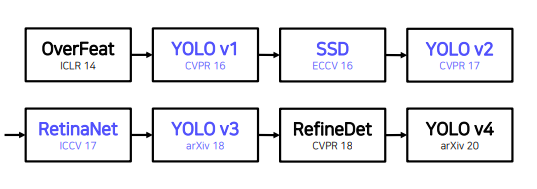
2. YOLO v1
2.1 Overview
- YOLO v1 : 하나의 이미지의 Bbox와 classification 동시에 예측하는 1 stage detector 등장
- YOLO v2 : 빠르고 강력하고 더 좋게
- 3가지 측면에서 model 향상 - YOLO v3 : multi-scale feature maps 사용
- YOLO v4 : 최신 딥러닝 기술 사용
- BOF : Bag of Freebies, BOS: Bag of Specials - YOLO v5: 크기별로 모델 구성
- Small, Medium, Large, Xlarge
특징
Region proposal 단계 X
- 전체 이미지에서 bounding box예측과 클래스를 예측하는 일을 동시에 진행
- 이미지, 물체를 전체적으로 관찰하여 추론 (맥락적 이해 높아짐)
2.2 Pipeline
Network
GoogLeNet 변형
-
24개의 convolution layer : 특징 추출
-
2개의 fully connected layer : box의 좌표값 및 확률 계산
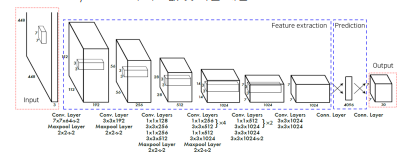
-
입력 이미지를 SxS 그리드 영역으로 나누기 (S=7)
-
각 그리드 영역마다 B개의 Bounding box와 Confidence score 계산 (B=2)
-
신뢰도(confidence) =
-
각 그리드 영역마다 C개의 class에 대한 해당 클래스일 확률 계산 (C=20)
-
conditional class probability = Pr(𝐶𝑙𝑎𝑠𝑠_𝑖|𝑂𝑏𝑗𝑒𝑐𝑡)
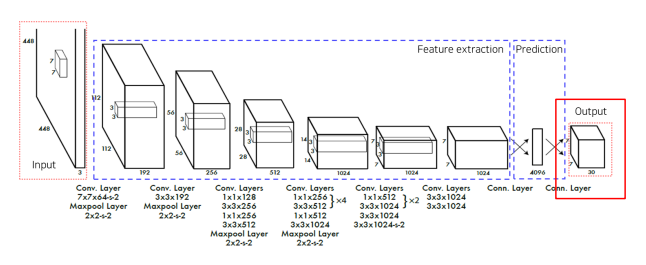 최종 output 7x7x30 이기 때문에 input을 grid를 7x7로 나눔
최종 output 7x7x30 이기 때문에 input을 grid를 7x7로 나눔
결과에 대한 분석
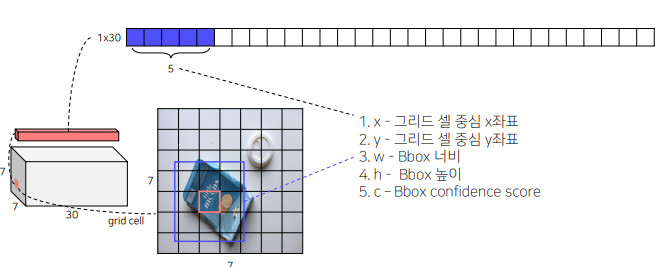
30 channel인 이유
Bbox 갯수인 2만큼 중심좌표,너비,confidence score 를 가짐 = 10개
나머지 20개는 각 class의 class score Pr(𝐶𝑙𝑎𝑠𝑠_𝑖|𝑂𝑏𝑗𝑒𝑐𝑡) = 20개
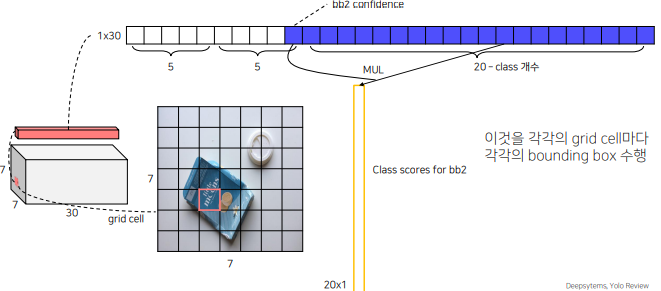
각 bbox의 confidence score를 20개 class score와 곱하면 해당 bbox가 어느 class를 뜻하는지 확률이 나옴
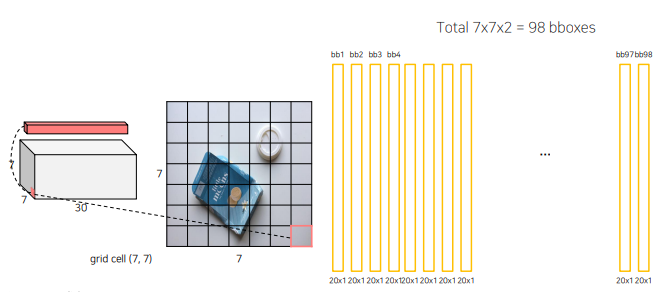
이과정을 모든 grid cell마다 수행하면 7x7x2=98 bbox가 나옴
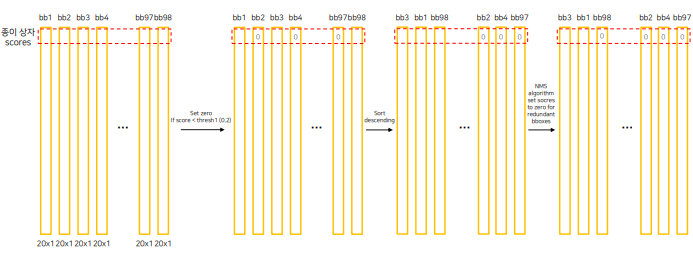 각 class에 해당하는 모든 확률을 일정 threshold이하인 애는 삭제 - 내림차순 정렬- NMS 진행하여 최종 inference box 찾음
각 class에 해당하는 모든 확률을 일정 threshold이하인 애는 삭제 - 내림차순 정렬- NMS 진행하여 최종 inference box 찾음
Loss

-
Localization loss
: 각 grid cell의 각 box별로
: object 가 있을 때
: 중심점의 위치를 구함
: width와 height의 regression loss 계산함
: Localization loss 조절하는 parmameter -
Confidence loss
: 각 grid cell의 각 box별로
: object 가 있을 때
: object 가 없을 때
: confidence loss 계산
: balance 조절 term -
Classification loss
: 각 grid cell별로 (class는 grid cell별로 모든 class 에 대한 score가 나오므로)
\mathbb{1}{i}^{\text {obj }} : object가 있을 때
$\sum{c \in \text { classes }}\left(p{i}(c)-\hat{p}{i}(c)\right)^{2}$ : class 확률에 대한 mse 계산
2.3 Results
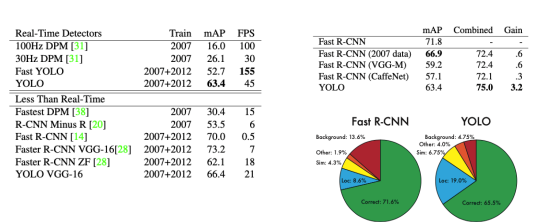
- Fast R-CNN, Yolo 두개를 앙상블 했을 때 결과가 좋다
- Faster R-CNN에 비해 6배 빠른 속도
- 다른 real-time detector에 비해 2배 높은 정확도
- 이미지 전체를 보기 때문에 클래스와 사진에 대한 맥락적 정보를 가지고 있음 = background error 낮음
- 물체의 일반화된 표현을 학습
- 사용된 dataset외 새로운 도메인에 대한 이미지에 대한 좋은 성능을 보임
3. SSD
3.1 Overview
YOLO의 단점
- 7x7 그리드 영역으로 나눠 Bounding box prediction 진행 → 그리드보다 작은 크기의 물체 검출 불가능
- 신경망을 통과하며 마지막 feature만 사용 → 정확도 하락
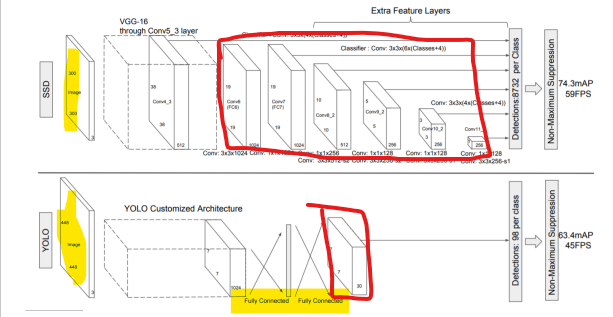
이미지 크기 차이
yolo : fcn, ssd : 1x1 conv
yolo : 마지막 fm에서 prediction , ssd : 모든 fm으로 prediction
SSD 특징
- Extra convolution layers에 나온 feature map들 모두 detection 수행
- 6개의 서로 다른 scale의 feature map 사용
- 큰 feature map (early stage feature map)에서는 작은 물체 탐지
- 작은 feature map (late stage feature map)에서는 큰 물체 탐지 - Fully connected layer 대신 convolution layer 사용하여 속도 향상
- Default box 사용 (anchor box)
- 서로 다른 scale과 비율을 가진 미리 계산된 box 사용
3.2 Pipeline
Network
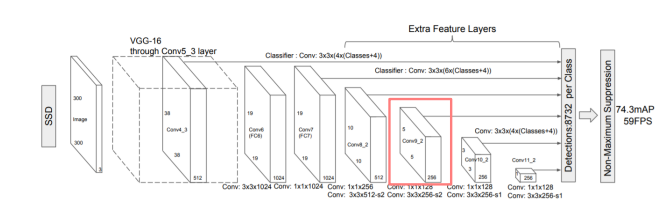 VGG-16(Backbone) + Extra Convolution Layers
VGG-16(Backbone) + Extra Convolution Layers
, 입력 이미지 사이즈 300 x 300
Multi-scale feature maps
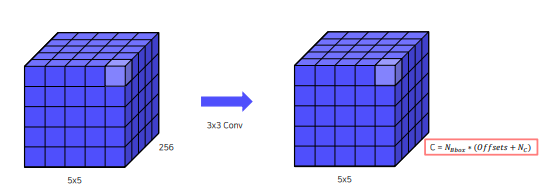
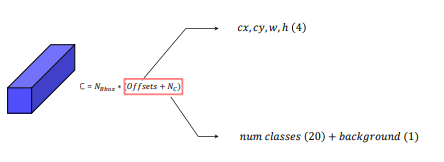 channel = 박스 갯수 x (각 box의 offset + 각 box별로 예측될 class)
channel = 박스 갯수 x (각 box의 offset + 각 box별로 예측될 class)
Default box

각 박스 별로 scale을 선형적으로 증가시키고, 그에 따라 anchor box의 aspect ratio (모양)도 미리 결정함, 마지막에 부분은 s1, s2 사이의 크기의 정사각형 box를 뜻함
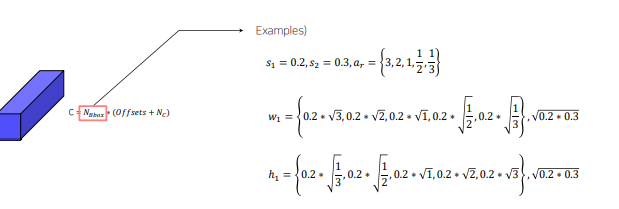
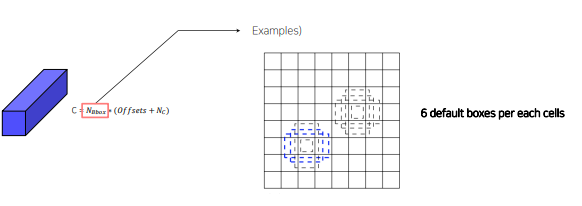 따라서 예시를 보면 s1, s2, a 에 따라 총 6개의 anchor box가 나옴
따라서 예시를 보면 s1, s2, a 에 따라 총 6개의 anchor box가 나옴
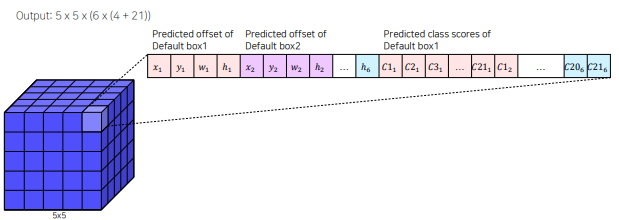 최종 output은 각 채널 별로 5x5x(6x(4+21)) bounding box
최종 output은 각 채널 별로 5x5x(6x(4+21)) bounding box
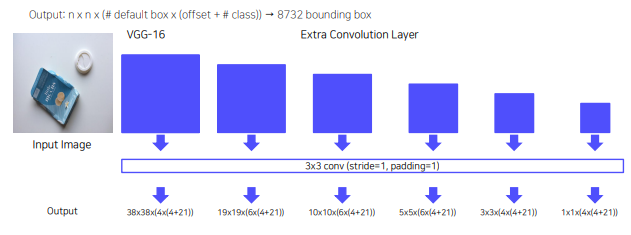 6개의 모든 fm에 대해서 output을 계산 = 8732 bounding box
6개의 모든 fm에 대해서 output을 계산 = 8732 bounding box

Training
- Hard negative mining 수행
- Non maximum suppression 수행
loss
 Localization loss에서 anchor box에서 GT로 가는 차이 = delta를 계산
Localization loss에서 anchor box에서 GT로 가는 차이 = delta를 계산
3.3 Results
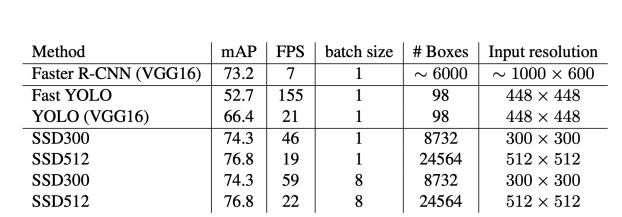
4. YOLO Follow-up
4.1 YOLO v2
3가지 파트에서 model 향상
- Better : 정확도 향상
- Faster : 속도 향상
- Stronger : 더 많은 class 예측 (80 -> 9000)
Better
- Batch normalization
- High resolution classifier
- YOLO v1: 224x224 이미지로 사전 학습된 VGG를 448x448 Detection 태스크에 적용
- YOLO v2 : 448x448 이미지로 새롭게 finetuning
- Convolution with anchor boxes
- Fully connected layer 제거
- YOLO v1 : grid cell의 bounding box의 좌표 값 랜덤으로 초기화 후 학습
- YOLO v2 : anchor box 도입
- K means clusters on COCO datasets
- 5개의 anchor box
- 좌표 값 대신 offset 예측하는 문제가 단순하고 학습하기 쉬움
- Fine-grained features
- Early feature map을 late feature map에 합쳐주는 passthrough layer 도입
- 26x26 feature map을 분할 후 결합
Faster
- Backbone model
- GoogLeNet → Darknet-19
- Darknet-19 for detection
- 마지막 fully conected layer 제거
- 대신 3x3 convolution layer로 대체
- 1x1 convolution layer 추가
- channel 수 125 (=5 x (5+20))
Stronger
- Classification 데이터셋(ImageNet), detection 데이터셋(Coco) 함께 사용
- WordTree 구성 (계층적인 트리)
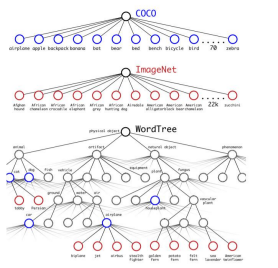
- Ex. “요크셔테리어” = 물리적객체(최상위 노드) – 동물 – 포유류 – 사냥개 – 테리어(최하위 노드)
- ImageNet 데이터셋과 CoCo 데이터셋 합쳐서 구성 : 9418 범주
- ImageNet 데이터셋 : Coco 데이터셋 = 4: 1
4.2 YOLO v3
Darknet-53
- Skip connection 적용
- Max pooling x, convolution stride 2사용
- ResNet-101, ResNet-152와 비슷한 성능, FPS 높음
Multi-scale Feature maps
- 서로 다른 3개의 scale을 사용 (52x52, 26x26, 13x13)
- Feature pyramid network 사용 = neck
- High-level의 fine-grained 정보와 low-level의 semantic 정보를 얻음
5. RetinaNet
5.1 Overview
1 Stage Detector Problems
Class imbalance
2 stage detector는 region proposal에서 background sample을 제거하여 posotive / negative sample수를 적절하게 유지 (hard negative mining)
1 stage detector의 경우 rpn이 없기 때문에 이미지를 grid로 나누어 gird별로 무조건 bounding box를 예측하게 함 -> Positive sample(객체 영역) < negative sample(배경영역) == Class imbalance
Concept
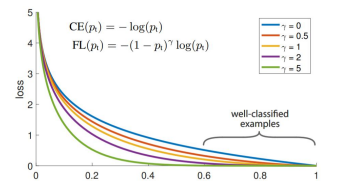
새로운 loss function 제시 : cross entropy loss + scaling factor
쉬운 예제에 작은 가중치, 어려운 예제에 큰 가중치
결과적으로 어려운 예제에 집중
result
이후 One-stage methods의 단점이였던 성능면에서 큰 향상을 이룸.
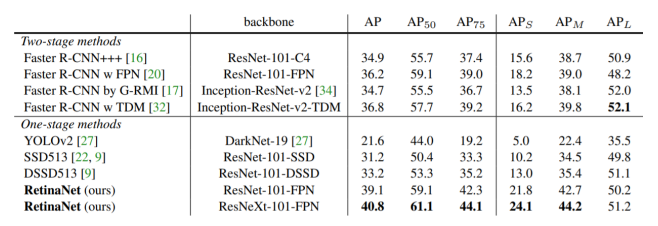
5.2 Focal Loss
1) Object Detection에서 background와의 class imbalance 조정
2) Object Detection 뿐만 아니라 Class imbalance가 심한 Dataset을 학습할 때 이를 활용
- Classification, Segmentation, Kaggle, etc
Summary
1 stage detector 연구 동향 및 paper
- Anchor
[DAFS] Dynamic Anchor Feature Selection for Single-Shot Object Detection [ICCV' 19][FSAF] Feature Selective Anchor-Free Module for Single-Shot Object Detection [CVPR' 19] - Multi-scale feature map
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network [AAAI' 19]
Learning Rich Features at High-Speed for Single-Shot Object Detection [ICCV' 19] - 경량화
YOLOv4: Optimal Speed and Accuracy of Object Detection [arXiv' 20]
Scaled-YOLOv4: Scaling Cross Stage Partial Network [CVPR’ 21]
Further Reading
YOLO v1, YOLO v2, YOLO v3
SSD: Single Shot MultiBox Detector
Focal Loss for Dense Object Detection
과제 수행 과정 및 결과
피어 세션
학습 회고
