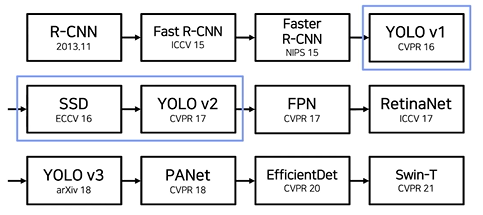
강의 내용 복습
(04강) Neck
1. Neck
1.1 Overview
1.2 Feature Pyramid Network (FPN)
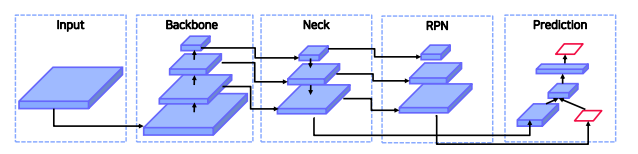
 백본의 마지막 feature map을 이용하여 PRN을 진행. 그럼 왜 마지막 feature map만 가지고 뽑을까? 에서 출발
백본의 마지막 feature map을 이용하여 PRN을 진행. 그럼 왜 마지막 feature map만 가지고 뽑을까? 에서 출발
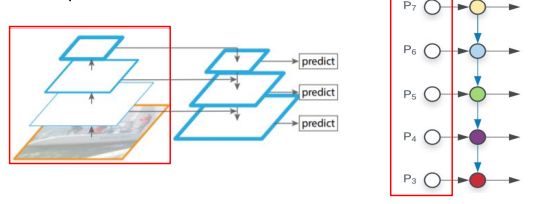
 각 layer에서 나온 모든 feature map을 사용함
각 layer에서 나온 모든 feature map을 사용함
만약 여러 크기의 feature map을 사용하게 된다면 ROI head에서 보는 객체의 크기도 다양해짐
따라서 다양한 크기의 객체를 더 잘 탐지하기 위해 Neck이 필요함
하위 level의 feature는 semantic이 약하므로 상대적으로 semantic이 강한 상위 feature와의 교환이 필요
row level feaure map : 백본 초반의 feature map : 작은 영역을 봄
high level feature map : 백본을 충분히 통과한 작은 feature map : 큰 영역을 봄
// FPN 이전의 작은 object를 탐지하기 위한 시도
- 이미지 자체의 크기를 조절
- 마지막 feature map 사용
- 중간 layer의 feature map 그대로 사용
이렇게 하면 각 크기의 feature map이 섞이지 않음
따라서 top down path way 추가
Pyramid 구조를 통해서 high level 정보를 low level에 순차적으로 전달
- Low level = Early stage = Bottom = 하위
- High level = Late stage = Top = 상위
FPN의 과정
1. Bottom-up
2. Top-down

3. Lateral connections
두 feature map을 섞어주는 과정.

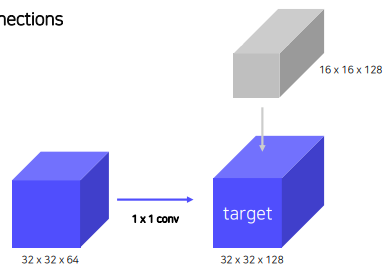
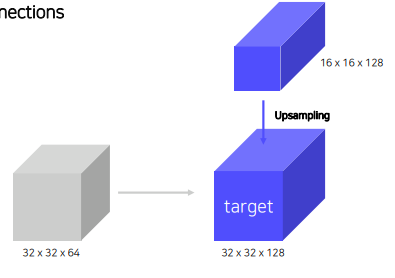
bottom-up의 두번째 layer의 feature map과 top-down의 맨 위 가장 작은 feature map을 섞어야 하는데, 둘의 spatial size와 channel이 맞지 않다. 따라서 top-down 은 up-convolution / bottom-up은 1x1 convoution 과정을 통해 size와 channel을 맞춰줌.
1x1 channel 줄이는거 아니었나? 계산량감소를 위해 channel 수를 작게하는 것뿐 1x1 filter의 channel 수를 크게하면 반대의 역할.
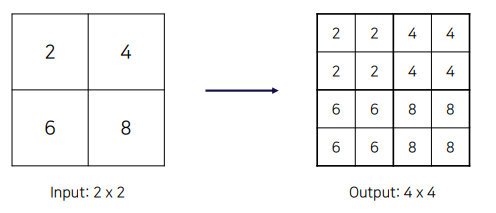
- Nearest Neighbor Upsampling
Pipeline
- backbone
Resnet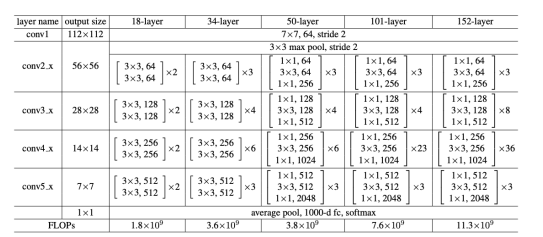 4개의 stage 있음 - pooling을 기준으로 w,h가 절반으로 줄어드는 부분
4개의 stage 있음 - pooling을 기준으로 w,h가 절반으로 줄어드는 부분
 각 stage마다 feature map을 뽑아내고 top-down시 섞어줌.
각 stage마다 feature map을 뽑아내고 top-down시 섞어줌.
각 layer 에서 나온 feature map으로 ROI를 진행하고 전체 ROI에서 NMS를 진행하여 약 1000개의ROI를 select. 그런데 그 ROI가 어느 stage(p5,p4,p3,p2)에서 왔는지 모르기 때문에 mapping과정이 필요하다.
4번째 stage()을 기준으로 w,h가 작으면, 예를 들어 112, 112 라고 하면 log값이 -1이 나와 최종 stage (k)가 3이 된다. 즉 feature map의 크기가 작을 수록 low level의 feature map을 사용하는 것

AR : Average Racall
: small 박스 1000개 기준 AR
Code
Build laterals: 각 feature map 마다 다른 채널을 맞춰주는 단계

Build Top-down: channel을 맞춘 후 top-down 형식으로 feature map 교환

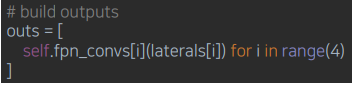
Build outputs: 최종 3x3 convolution을 통과하여 RPN으로 들어갈 feature 완성
Contribution
- 여러 scale의 물체를 탐지하기 위해 설계
- 이를 달성하기 위해서는 여러 크기의 feature를 사용해야할 필요가 있음
Summary - Bottom up (backbone)에서 다양한 크기의 feature map 추출
- 다양한 크기의 feature map의 semantic을 교환하기 위해 top-down 방식 사용
1.3 Path Aggregation Network (PANet)
- FPN의 문제점
실제로 ResNET의 구조를 보면 backbone의 길이가 매우 길기 때문에 low level feature map이 high level feature map으로 제대로 전달될 수 없음
이를 해결한 것이 PANet
Bottom-up Path Augmentation
bottom-up path way 를 하나 더 추가
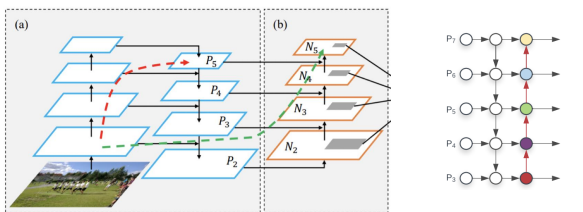 (b)부분 딱 4개의 layer만 지나면되므로 row level 정보가 잘 전달됨
(b)부분 딱 4개의 layer만 지나면되므로 row level 정보가 잘 전달됨
Adaptive Feature Pooling
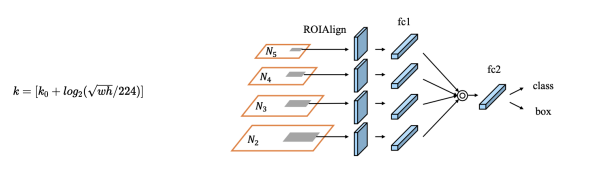
각 layer(N2,N3,N4,N5)에서 나온 feature map에서 ROI pooling진행. 이때 FPN과 같은 stage계산 공식을 쓰면 경계에 있는 feature map의 stage를 제대로 계산 할 수 없음
Projection 단계에서 특정 stage에 있는 feature map을 사용하면 결국 local~sementic정보를 모두 사용할 수 없으니 모든 feature map을 사용해서 ROI Projection을 하고 ROI pooling을 헤서 fc를 만들고, channel wise projection으로 하나의 fc로 출력
Code
- FPN: Top-down에 3 x 3 convolution layer 통과하는 것 까지 동일
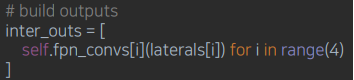
- Add bottom-up: FPN을 통과한 후, bottom-up path 를 더해줌

- Build outputs: 이후 FPN과 마찬가지로 학습을 위해 3 x 3 convolution layer 통과

2. After FPN
2.1 DetectoRS
RPN, Cascade R-CNN 에서 영감을 받아 반복적으로 하면 좋은 성능을 이끌어내는지 실험
주요구성
- Recursive Feature Pyramid (RFP)
- Switchable Atrous Convolution (SAC)
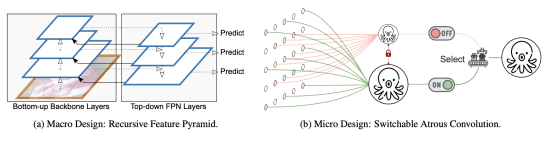
Recursive Feature Pyramid (RFP)

FPN을 recursive하게 수행하는 것 . neck정보를 backbone에 다시 전달하여 backbone을 다시 학습시킴 . 단점은 backbone연산이 많아져 flops늘어남
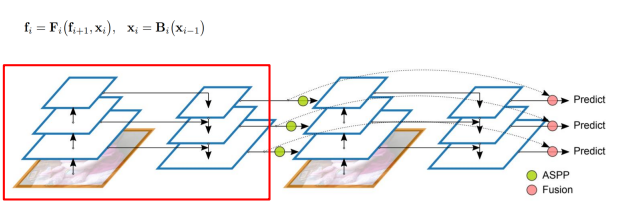
F: neck 연산(backbone layer feature map 와 neck high level feature map 을 통해 feature map 생성)
B: backbone연산(low level feature map 을 통해 feature map생성)

Atrous Spatial Pyramid Pooling 연산을 통해 neck stage의 feature map을 backbone으로 넘겨줌
Atrous Spatial Pyramid Pooling(ASPP)
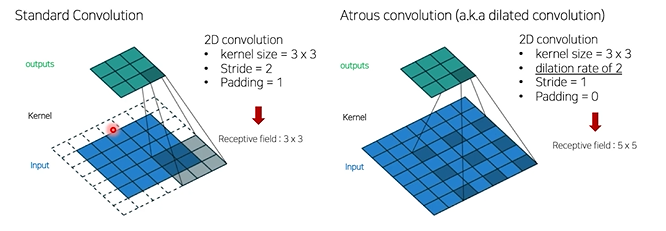 Atrous Convolution : receptive field를 늘릴 수 있는 방법
Atrous Convolution : receptive field를 늘릴 수 있는 방법
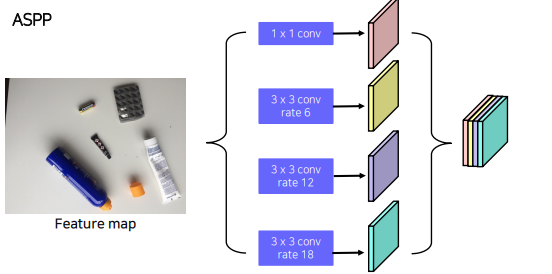 하나의 fm에서 pooling을 진행하는데
하나의 fm에서 pooling을 진행하는데
Atrous Convolution rate를 여러가지를 주어 receptive fiel를 늘리고(다양화하고) concat
2.2 Bi-directional Feature Pyramid (BiFPN)
EfficeintDet에서 제안함
 효율성을 위해 PANet을 다음과 같이 바꾸자.
효율성을 위해 PANet을 다음과 같이 바꾸자.
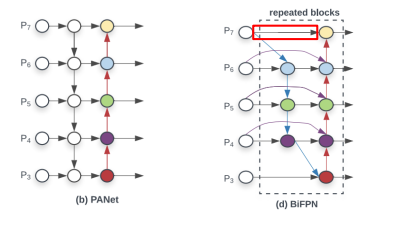 효율성을 위해 feature map이 한곳에서만 오는 node제거
효율성을 위해 feature map이 한곳에서만 오는 node제거
 위의 fpn구조를 반복적으로 사용하여 parameter와 flops를 줄임
위의 fpn구조를 반복적으로 사용하여 parameter와 flops를 줄임
Weighted Feature Fusion
- FPN에서 backbone feature map과 neck feature map을 크기와 패널을 맞추어 더해줌
- FPN과 같이 단순 summation을 하는 것이 아니라 각 feature별로 가중치를 부여한 뒤 summation
- 모델 사이즈의 증가는 거의 없음
- feature별 가중치를 통해 중요한 feature를 강조하여 성능 상승
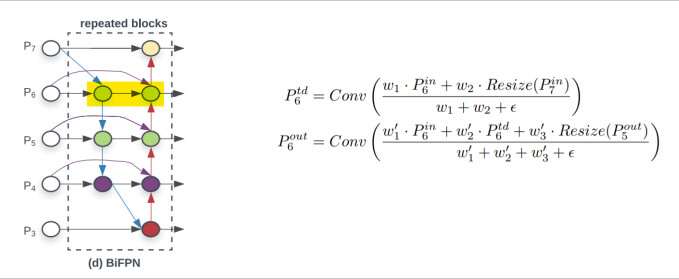 : , P{7}^{i n} 가중합
: , P{7}^{i n} 가중합
$P{6}^{\text {out }}$ : , 과 함께 도 residual 처럼 가중합
이때 weight도 학습가능한 parameter
2.3 NASFPN
기존의 FPN, PANet
- Top-down or bottom up pathway -> 사람이 휴리스틱하게 찾음
- 단순 일방향(top->bottom or bottom ->top) summation 보다 좋은 방법이 있을까?
- 그렇다면 FPN 아키텍처를 NAS (Neural architecture search)를 통해서 찾자!
Architecture

search
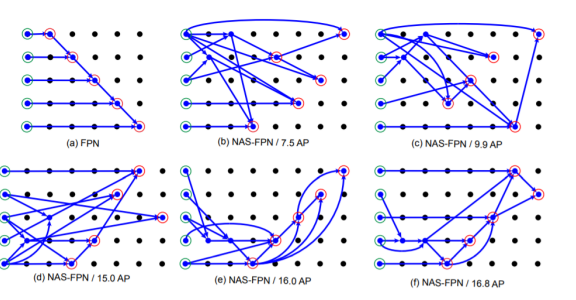
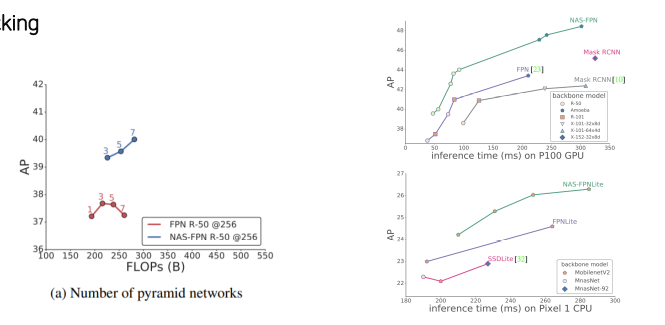
단점
COCO dataset, ResNet기준으로 찾은 architecture, 범용적이지 못함
- Parameter가 많이 소요
High search cost - 다른 Dataset이나 backbone에서 가장 좋은 성능을 내는 architecture를 찾기 위해 새로운 search cost
2.4 AugFPN
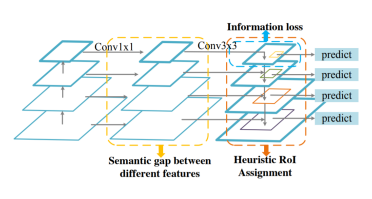
Problems in FPN
- 서로 다른 level의 feature간의 semantic차이
- Highest feature map의 정보 손실
- 1개의 feature map에서 RoI 생성(PANet에서는 해결)
주요 구성
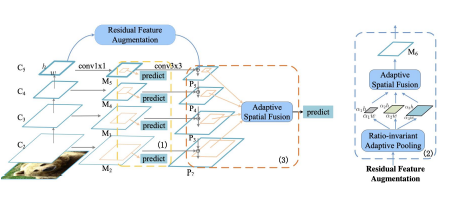
- Consistent Supervision
- Residual Feature Augmentation
- Soft RoI Selection
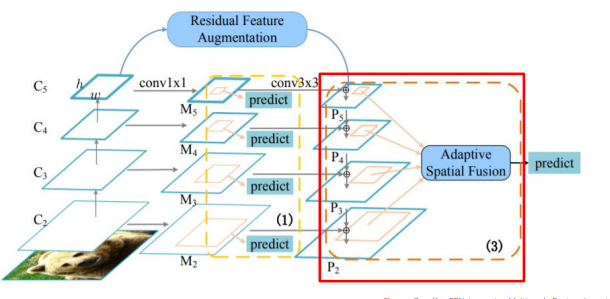
Residual Feature Augmentation
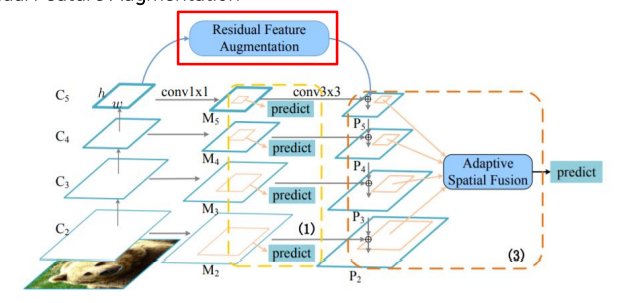 fpn은 row level feature map은 high level sementic정보가 내려오면서 추가됨. 하지만 p5의 경우 1x1,3x3 conv만 진행하기 때문에 channel이 줄어드는 정보손실이 발생함. 따라서 마지막 stage에 더 높은 high level 정보를 보강해줘야 함
fpn은 row level feature map은 high level sementic정보가 내려오면서 추가됨. 하지만 p5의 경우 1x1,3x3 conv만 진행하기 때문에 channel이 줄어드는 정보손실이 발생함. 따라서 마지막 stage에 더 높은 high level 정보를 보강해줘야 함
이것이 Residual Feature Augmentation. C5로부터 m6를 만들어주고 이를 추가해줌
M6 만드는 방법
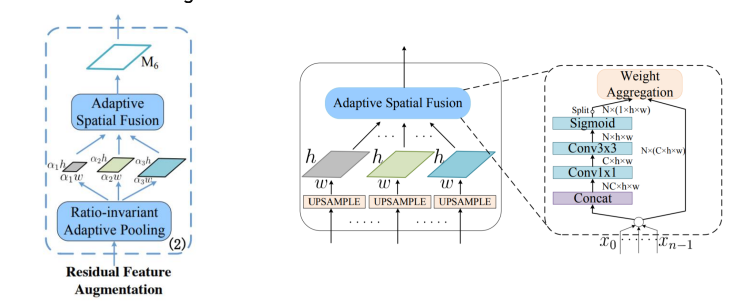
Ratio-invariant Adaptive Pooling
- 다양한 scale의 feature map 생성
- 256 channels로 맞추어 adaptive spatial fusion = 각 feature map 합쳐줌
- 동일한 size로 up sampling
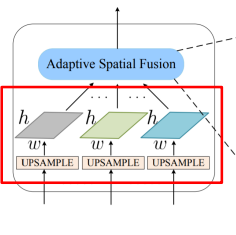
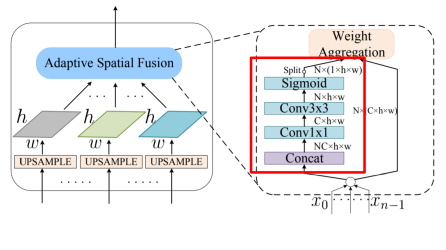
- N 개의 feature에 대해 가중치를 두고 summation

- 3개의 feature map을 Concat하고 N x ( 1 x h x w ) 의 값을 구함
이 때 N x ( 1 x h x w ) 은 spatial weight를 의미
N x ( 1 x h x w ) 를 각 N 개의 feature에 곱해 가중 summation
Soft RoI Selection
- FPN과 같이 하나의 feature map에서 RoI를 계산하는 경우 sub-optimal
- 이를 해결하기 위해 PANet에서 모든 feature map을 이용했지만, PANet은 max pool하여 정보 손실 가능성
- 이를 해결하기 위해 Soft RoI Selection을 설계
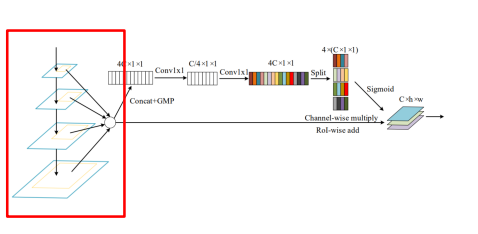 모든 scale의 feature에서 RoI projection 진행 후 RoI pooling
모든 scale의 feature에서 RoI projection 진행 후 RoI pooling
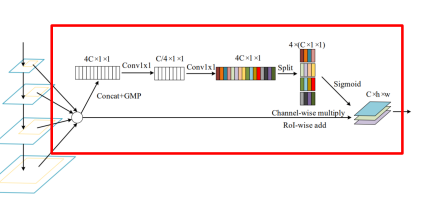 Channel-wise 가중치 계산 후 가중 합을 사용, PANet의 max pooling을 학습 가능한 가중 합으로 대체
Channel-wise 가중치 계산 후 가중 합을 사용, PANet의 max pooling을 학습 가능한 가중 합으로 대체
Further Reading
FPN Paper
PAFPN Paper
DetectoRS Paper
과제 수행 과정 및 결과
피어 세션
회의 내용
- ⭐mmdetection 새로 나온걸로 사용
- mmdetection wandb sweaps 가능한지 방법 알아보기
- github organization 새로 파서 repo 여러개 사용할지 vs. 부캠 제공 repo에서 폴더별로 library 나눌지
- val.json 파일 생성해서 train 해보기
- wandb hook 달기
- wandb interval 조정
- 내일은 수정해볼 파라미터 정하고 각자 역할 나누기
(dataset, runtime은 하이퍼파라미터 거의 고정되어 있으니 나머지에서)
학습 회고
mmdetection 의 config를 직접 만들어 학습 시켜봄
train- valid set을 어떻게 나눌지에 대한 고민 필요
각 모델별 metric 무엇을 의미하는지 분석 필요
object detection 디버깅 방법 여쭤보기
