강의 내용 복습
(08강) Advanced Object Detection 2
1. YOLO v4
yolo v4는 굉장히 많은 실험을 했는데, 그 실험 방법과 결과를 소개함
1.1 Overview
등장배경
정확도는 올라갔지만 많은 양의 GPU가 필요하고 실시간으로 적용하기 힘듬
contribution
- 하나의 GPU에서 훈련할 수 있는 빠르고 정확한 Object detector
- BOF, BOS 방법들을 실험을 통해서 증명하고 조합을 찾음
- BOF (Bag of Freebies) : inference 비용을 늘리지 않고 정확도 향상시키는 방법
- BOS (Bag of Specials) : inference 비용을 조금 높이지만 정확도가 크게 향상하는 방법
- GPU 학습에 더 효율적이고 적합하도록 방법들을 변형
1.2 Related work
- input : images, patches,Image Pyramid, ..
- Backbone
- GPU platform : VGG, ResNet, ResNext, DenseNet, …
- CPU platform : SqueezeNet, MobileNet, ShuffleNet, …
- Neck
- Additional blocks: SPP, ASPP, …
- Path-aggregation blocks: FPN, PAN, NAS-FPN, BiFPN ...
- Head
- Dense Prediction(one-stage) : RPN(not 1 stage detector), YOLO, SSD, RetinaNet, CornerNet, FCOS, …
- Sparse Prediction(two-stage) : Faster-RCNN, R-FCN, Mask R-CNN, …
BOF (Bag of Freebies)

-
Data Augmentation
입력 이미지의 변화시켜 과적합(overfitting)을 막고, 다양한 환경에서도 강력해지는 방법
 여러 이미지를 함께 사용하여 data augmentation 수행. cutmix : 학습 이미지의 패치영역만큼 잘라내서 다른 학습 이미지에 붙여 넣고 ground truth 라벨도 패치 영역만큼 비율로 섞는 방법
여러 이미지를 함께 사용하여 data augmentation 수행. cutmix : 학습 이미지의 패치영역만큼 잘라내서 다른 학습 이미지에 붙여 넣고 ground truth 라벨도 패치 영역만큼 비율로 섞는 방법 -
Semantic Distribution Bias
데이터셋에 특정 라벨(배경)이 많은 경우 불균형을 해결하기 위한 방법
hard negetive mining , focal loss 등- Label smoothing
라벨에 0 또는 1로 설정하는 것이 아니라 smooth하게 부여
Ex) 원래 0이었던 라벨을 0.1로 부여, 1이었던 라벨을 0.9로 부여
모델의 overfitting 막아주고 regularization의 효과
- Label smoothing
-
Bounding Box Regression

Bounding box 좌표값들을 예측하는 방법(MSE)은 거리가 일정하더라도 IoU가 다를 수 있음
IoU 기반 loss 제안 (IoU는 1에 가까울수록 잘 예측한 것이므로 loss처럼 사용 가능)- GIoU
IoU 기반 loss
IoU가 0인 경우에 대해서 차별화하여 loss 부여CIou 등도 있음
- GIoU
BOS (Bag of Specials)
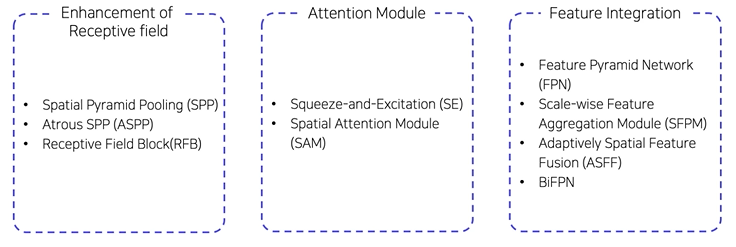

-
Enhance receptive field
Feature map의 receptive field를 키워서 검출 성능을 높이는 방법- SPP (Spatial Pyramid Pooling)
conv layer의 마지막 feature map을 고정된 크기의 grid로 분할해 pooling하여 고정된 크기의 벡터 출력
- SPP (Spatial Pyramid Pooling)
-
Attention Module
feature map의 글로벌 정보 추가
SE, CBAM

-
Feature Integration
Feature map 통합하기 위한 방법 = neck
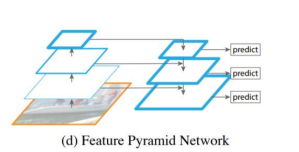
-
Activation Function
좋은 activation 함수는 gradient가 더 효율적으로 전파 -
ReLU
-Gradient vanishing 문제 해결하기 위한 활성 함수로 등장 -
음수 값이 나오면 훈련이 되지 않는 현상 발생
-
Swish / Mish
- 약간의 음수 허용하기 때문에 ReLU의 zero bound보다 gradient 흐름에 좋은 영향
- 모든 구간에서 미분 가능
-
Post-processing Method
불필요한 Bbox 제거하는 방
BoF and BoS for YOLOv4 backbone
• Activations : ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
• Bounding box regression loss : MSE, IoU, GIoU, CIoU, DIoU
• Data augmentation : CutOut, MixUp, CutMix
• Regularization method : DropOut, DropPath, Spatial DropOut, DropBlock
• Normalization : Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter
Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN)
• Skip-connections : Residual connections, Weighted residual connections, Multi-input weighted
residual connections, Cross stage partial connections (CSP)
• Others : label smoothing
1.3 Selection of Architecture
Detector의 디자인 고려사항
- 작은 물체 검출하기 위해서 큰 네트워크 입력 사이즈 필요
- 네트워크 입력 사이즈가 증가함으로써 큰 receptive field 필요 → 많은 layer를 필요
- 하나의 이미지로 다양한 사이즈의 물체 검출하기 위해 모델의 용량이 더 커야 함 → 많은 파라미터 필요
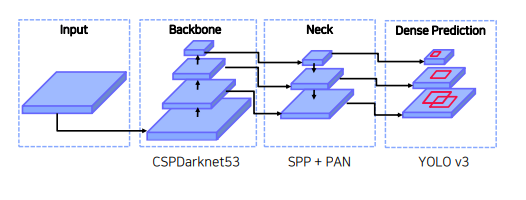
Cross Stage Partial Network (CSPNet)
정확도 유지하면서 경량화
메모리 cost 감소
다양한 backbone에서 사용가능
연산 bottleneck 제거
기존의 Dense Net
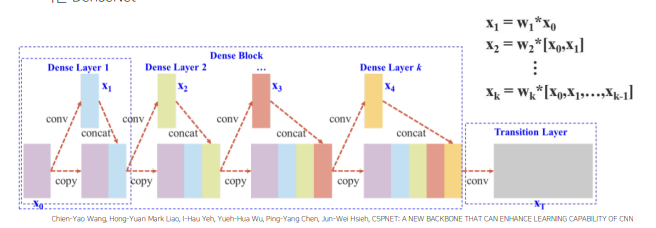 문제점 : 가중치 업데이트 할 때 gradient 정보가 재사용
문제점 : 가중치 업데이트 할 때 gradient 정보가 재사용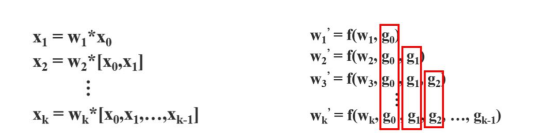
CSPDenseNet
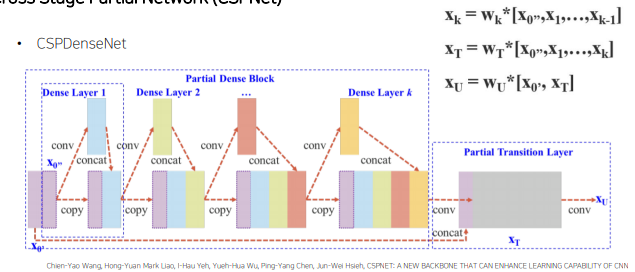
 conv-concat 연산시 input image전체를 사용하지 않고 반만 사용하고 이후 만들어진 x_t에 input image 절반을 concat하여 최종적인 feature map 만듬 -> 나중에 합쳐주는 feature map에 대한 cost를 줄일 수 있고, gradient information이 많아지는 것을 방지하여 학습에 좋은 영향
conv-concat 연산시 input image전체를 사용하지 않고 반만 사용하고 이후 만들어진 x_t에 input image 절반을 concat하여 최종적인 feature map 만듬 -> 나중에 합쳐주는 feature map에 대한 cost를 줄일 수 있고, gradient information이 많아지는 것을 방지하여 학습에 좋은 영향
새로운 data augmentation 방법
- Mosaic

train image 4장을 하나로 합쳐서 하나의 input으로 4개의 사진을 학습하는 효과 - 배치 사이즈 커지는 효과 - Self-Adversarial Training (SAT)
첫번째 stage : 원본이미지를 변형시켜 이미지안에 객체가 없어보이게 함
두번째 stage : 변형된 이미지를 사용하여 학습
눈에 보이지 않는 augmentation을 추가하여 robust한 모델을 만듬
기존 방법 변형
- modified SAM(Spatial Attention Module)
spatial wise attention을 point wise attention으로 - modified PAN(Path Aggregation Network)
add 연산을 concat으로 - Cross mini-Batch Normalization (CmBN)
각 미니배치마다 norm을 계산하지 않고 batch norm을 accumulate하여 batch사이즈가 큰것과 같은 효과
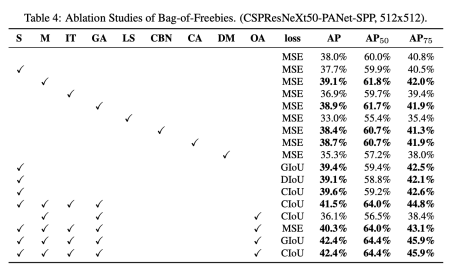
실험결과
2. M2Det
2.1 Overview
물체에 대한 스케일 변화는 object detection의 과제
-> FPN
Feature pyramid 한계점
Backbone으로부터 feature pyramid 구성
Classification task를 위해 설계된 backbone은 object detection task를 수행하기에 충분하지 않음
Backbone network는 single-level layer로, single-level 정보만 나타냄
일반적으로, low-level feature는 간단한 외형을, high-level feature는 복잡한 외형을 나타내는데 적합합니다
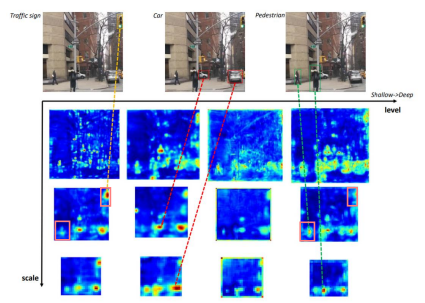
low-level에서는 간단한 신호등에 집중 , high-level에서는 사람에 집중
Multi-level, multi-scale feature pyramid 제안(MLFPN)
SSD에 합쳐서 M2Det라는 one stage detector 제안
2.2 Architecture
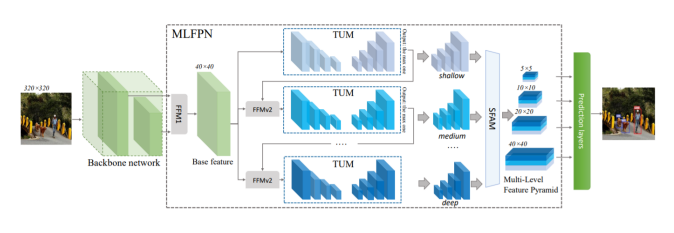
FFMv1 : backbone에서 두개의 stage로부터 feature map을 골라 이를 concat하여 하나의 base feature map을 만듬
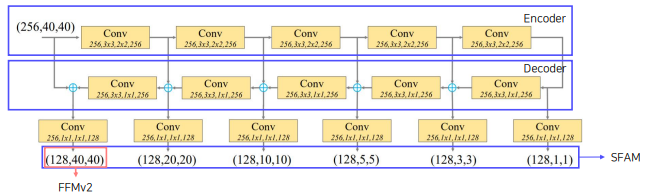
TUM : U-net encoder, decoder 로 구성
첫번째 level 결과 : U-net decoder를 통과한 다양한 scale을 갖는 feture map. 이중 가장 큰 feature map을 level 2로 보냄
FFMv2 : base feature map 과 level 1 decoder output을 concat
SFAM : feature map concat + attention
FFM : Feature Fusion Module
FFMv1 : base feature 생성
Base feature : 서로 다른 scale의 2 feature map을 합쳐(channel dim concat) semantic 정보가 풍부함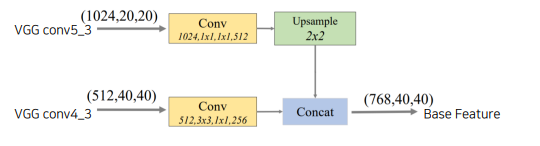
TUM : Thinned U-shape Module
Encode-decoder 구조
Decoder의 출력 : 현재 level에서의 multi-scale features
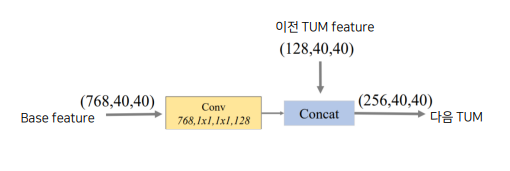
FFMv2 : base feature와 이전 TUM 출력 중에서 가장 큰 feature concat
다음 TUM의 입력으로 들어감
multi level , multi scale feature map
SFAM : Scale-wise Feature Aggregation Module
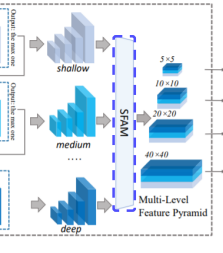
TUMs에서 생성된 multi-level multi-scale을 합치는 과정

동일한 크기를 가진 feature들끼리 연결 (scale-wise concatenation)
각각의 scale의 feature들은 multi-level 정보를 포함
Channel-wise attention 도입 (SE block)
채널별 가중치를 계산하여 각각의 feature를 강화시키거나 약화시킴
SSD
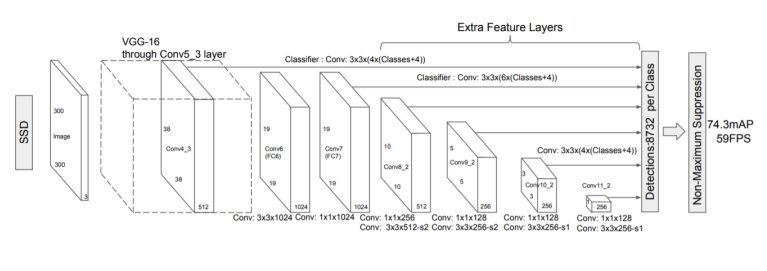
M2Det
8개의 TUM 사용
- 출력 : 6개의 scale features
Detection Stage - 6개의 feature마다 2개의 convolution layer 추가해서 regression, classification 수행
- 6개의 anchor box 사용
- Soft-NMS사용
Results

3. CornerNet
3.1 Overview
Anchor Box의 단점
• Anchor Box의 수가 엄청나게 많음
• Positive sample(객체)가 적고, 대부분이 negative sample(배경) → class imbalance
• Anchor Box 사용할 때 하이퍼파라미터를 고려해야함
• Anchor box 개수, 사이즈, 비율
CornerNet
• Anchor Box가 없는 1 stage detector
• 좌측 상단(top-left), 우측 하단(bottom-right)점을 이용하여 객체 검출
• Center(중심점)이 아니라 Corner(모서리) 사용하는 이유
• 중심점을 잡게 되면 4개의 면을 모두 고려해야하는 반면, corner을 사용하면 2개만 고려
3.2 Architecture
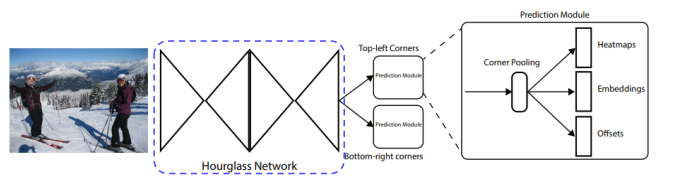
3.3 Follow-up
Further Reading
YOLOv4: Optimal Speed and Accuracy of Object Detection
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
CornerNet: Detecting Objects as Paired Keypoints
과제 수행 과정 및 결과
피어 세션
학습 회고
