강의 내용 복습
(06강) High Performance를 자랑하는 Unet 계열의 모델들
1. U- Net
1.1 Intro
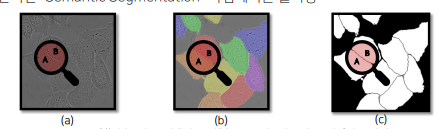
의료계열에서 문제 상황
1. 기본적인 Deep Learning은 파라미터 수가 많고 네트워크가 깊어서 train 데이터가 많이 필요 -> 의료계열은 데이터 많이 부족
2. 같은 클래스가 인접한 셀 구분이 어려움
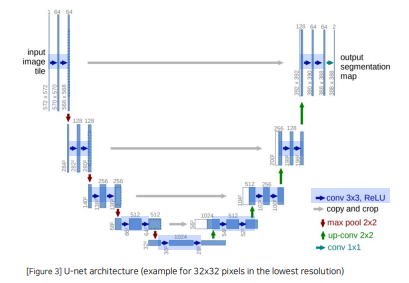
1.2 Architecture
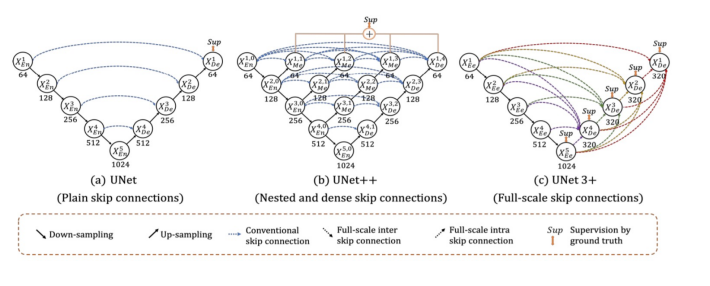
Contracting Path 와 Expanding path 가 대칭일 U자 형을 이룸


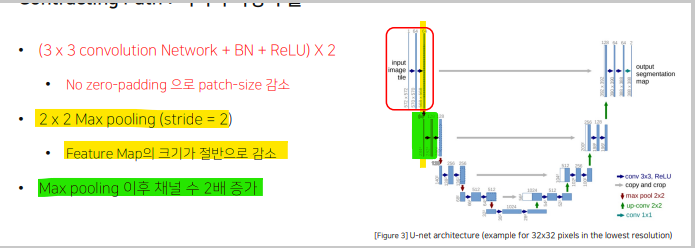
3x3 conv - bn = relu 반복되는 구조
Zero-Padding을 적용하지 않아서 특징맵의 크기가 감소
Contracting Path에서는 채널의 수가 2배로 증가하고 Expanding Path에서는 채널의 수가 2배로 감소
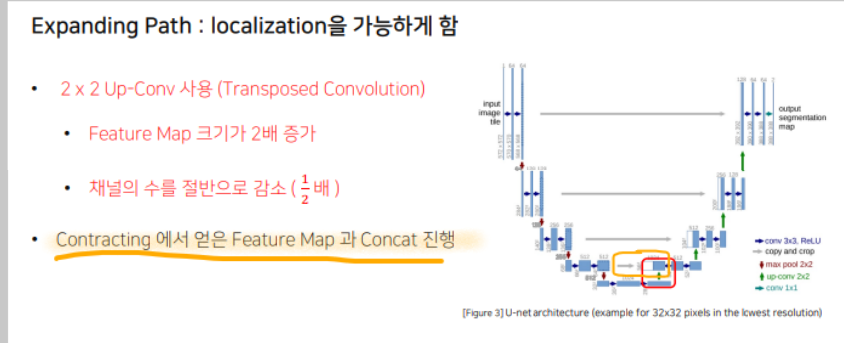
같은 계층(Level)의 Encoder 출력물과 Up-Conv의 결과를 Concatenate하는 형태
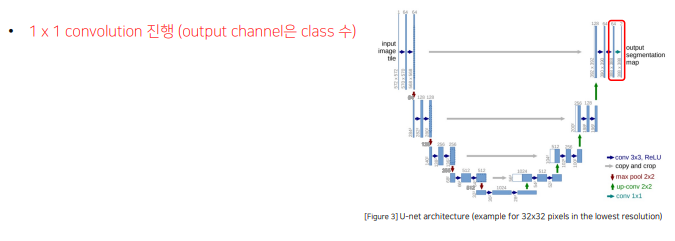
- Contribution
- Encoder가 확장함에 따라 채널의 수를 1024까지 증가시켜 좀 더 고차원에서 정보를 매핑
- 각기 다른 계층의 Encoder의 출력을 Decoder와 결합시켜서 이전 레이어의 정보를 효율적으로
활용
1.3 Techniques
-
Data Augmentation
Randoom Elastic defomations -> model이 invarience , robustness 를 학습하게 함 -
Pixel-wise loss weight 를 계산하기 위한 Weight map을 생성

1.4 한계
- 깊이가 4로 고정 -> 데이터셋마다 최적의 깊이를 찾는 탐색 비용이 듬
- 단순한 skip connection
동일한 깊이를 가지는 인코더와 디코더만 연결되는 제한적인 구조
2. U-Net ++
유넷의 두가지 한계점을 극복하기 위한 새로운 형태의 아키텍쳐
2.1 Intro
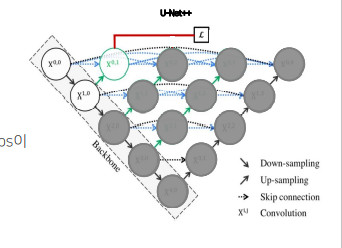
- 인코더를 공유하는 다양한 깊이의 U Net 생성
- skip connection을 동일한 깊이에서의 feature map이 모두 결합되도록 유연한 feature map 생성
2.2 Dense skip connections / ensemble/ deep supervision
-
Dense skip connections
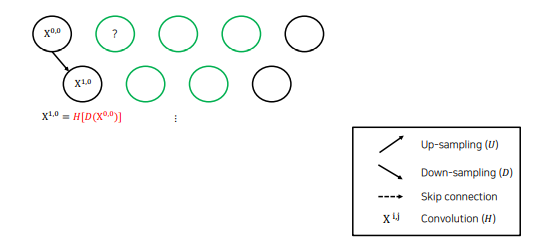
다음 층의 결과는 downsampling 후 conv 연산을 한 결과
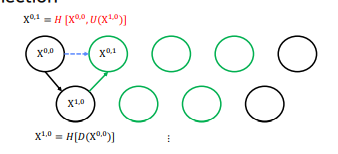
이전 층의 다음 결과()는 을 upsampling하고 해당 층의 이전 결과 () 와 concat한 후 conv연산을 한 결과
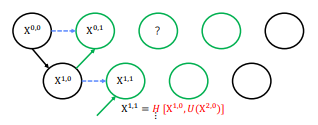 도 같은 연산으로 만듬
도 같은 연산으로 만듬
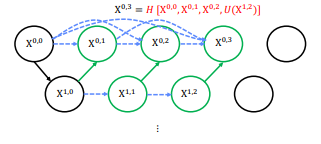 을 만들때는 0 번째 층에 있는 모든 결과와 up()을 다같이 concat한 후 conv연산을 취해줌
을 만들때는 0 번째 층에 있는 모든 결과와 up()을 다같이 concat한 후 conv연산을 취해줌
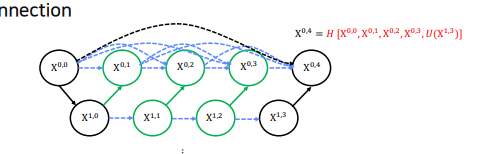 이렇게 하면 기존의 U-Net skip connection(검정 점선) 보다 훨씬 다양한 feature map을 전달할 수 잇음
이렇게 하면 기존의 U-Net skip connection(검정 점선) 보다 훨씬 다양한 feature map을 전달할 수 잇음 -
ensemble
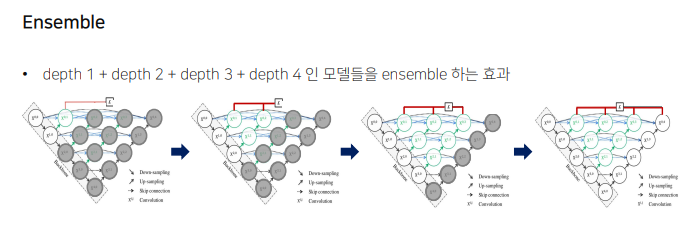
-
Hybrid Loss
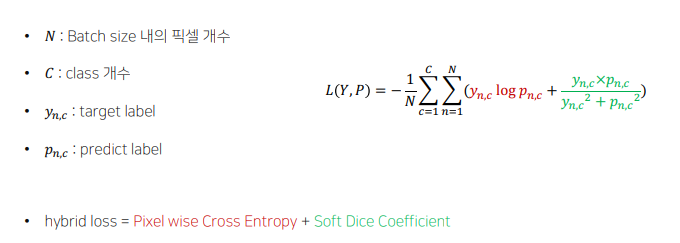
-
Deep supervision
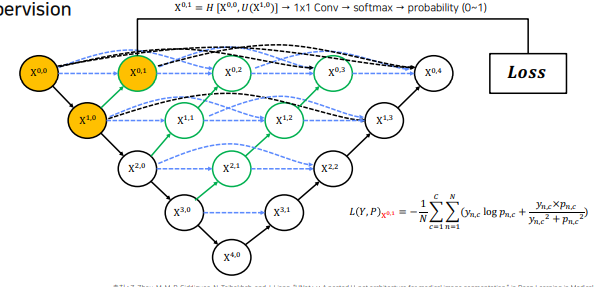
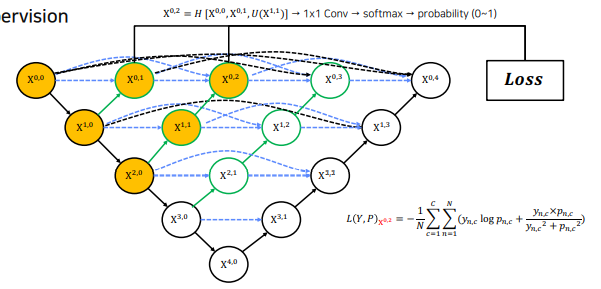
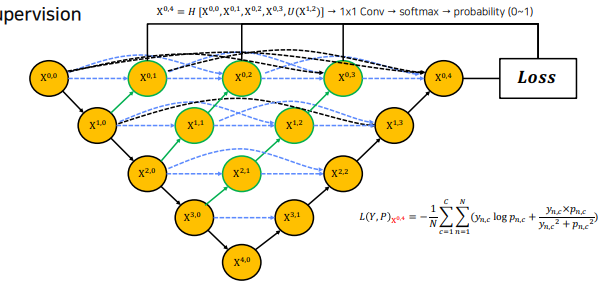
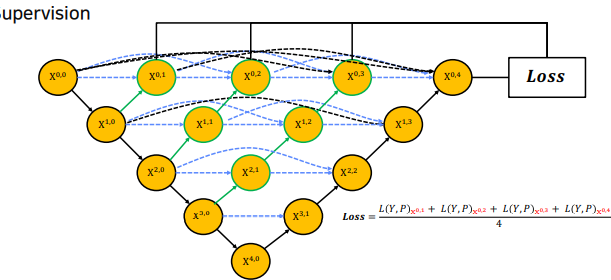
각 깊이의 loss 의 평균을 내어 최종 loss로 활용
2.3 한계
- 복잡한 connection으로 파라미터, 메모리 증가
- 인코더-디코더 사이의 connection이 동일한 크기를 갖는 feature map(동일한 층의 feature map 만 concat함 )에서만 진행됨 -> 즉 full scale 에서 충분한 정보를 탐색하지 못해 위치와 경계르르 명시적으로 학습하지 못함
3. U-Net 3+
3.1 U-Net, U-Net ++ 의 한계
U-Net : 같은 level의 encoder layer 로부터만 feature map을 받는 simple skip connection이용
U-Net ++ : nested and dense skip connection으로 인코더 - 디코더 사이의 semantic gap을 줄였지만 파라미터, 메모리 증가 / 성능이 좋아졌음에도 불구하고 full scale에서 충분한 정보를 탐색하지 못해 예측하려는 위치의 경계를 면시적으로 학습하지 못함
3.2 U-Net 3+ 에 적용된 techniques
small-scale : 하나의 픽셀이 담고있는 원본 이미지의 정보가 작다는 것으로 해석 (lager-scale도 마찬가지)
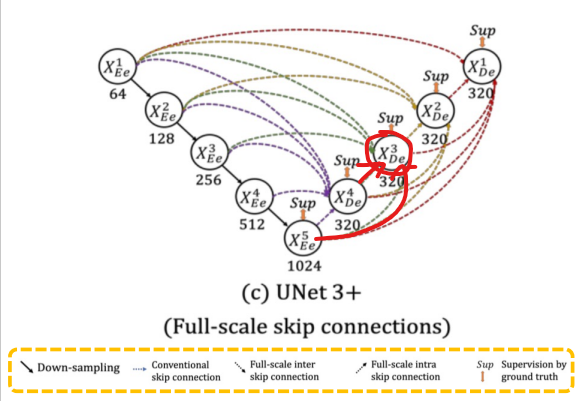
- Full-scale skip connections(Conventional + inter + intra) skip connection
= decoder의 feature map구성 방법
-
conventional
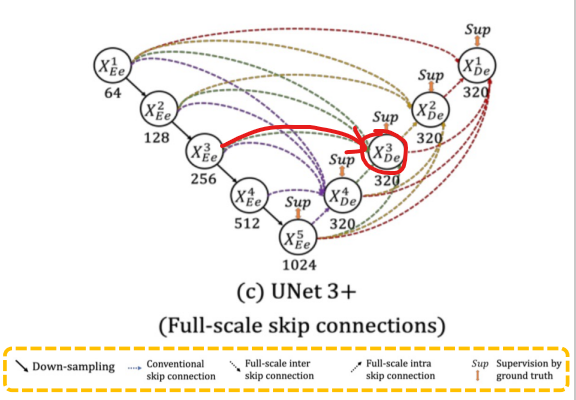
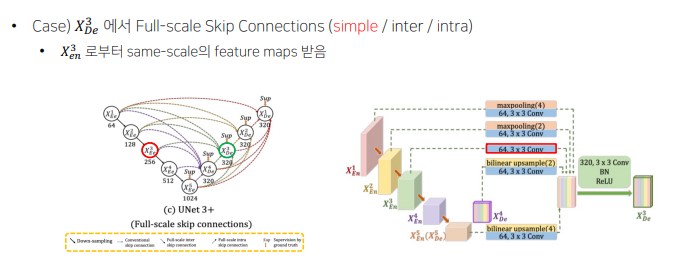
encoder layer 로부터 small-scale(이미지 크기가 작다는 것이 아닌, 하나의 픽셀이 담고있는 원본 이미지의 정보가 작다는 것으로 해석)의 low-level feature maps를 받음 -
inter
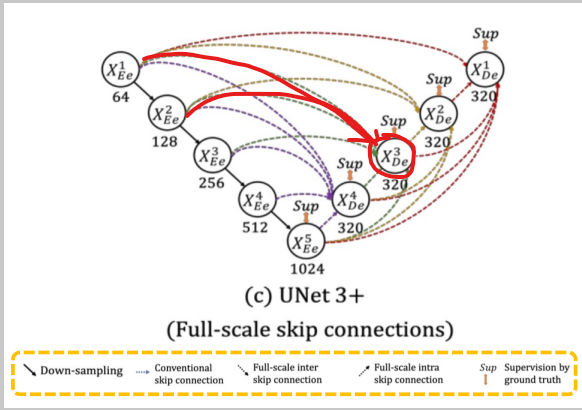
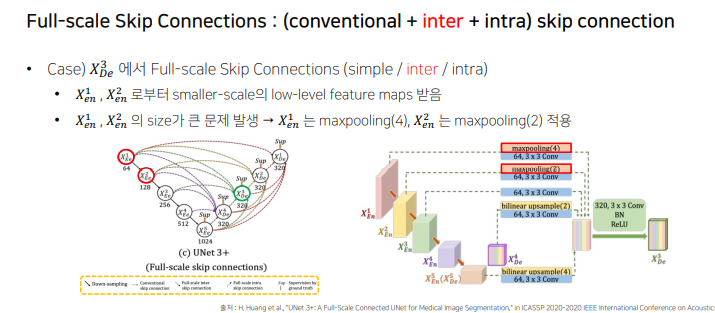
encoder layer 로부터 smaller-scale의 low-level feature maps를 받음 - 풍부한 공간 정보를 통해 경계 강조 -
intra
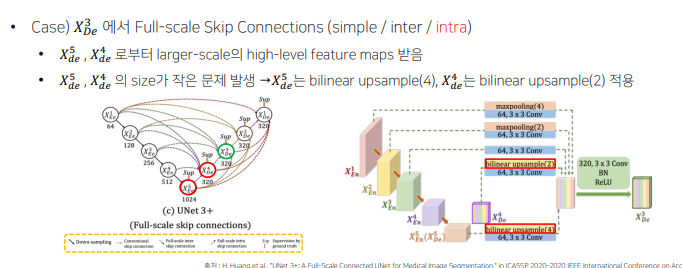
decoder layer 로부터 larger-scale(이미지 크기가 크다는 것이 아닌, 하나의 픽셀이 담고있는 원본 이미지의 정보가 크다는 것으로 해석)의 high-level feature maps를 받음 - 어디에 위치하는지 위치정보 구현
-
Full-scale skip connections with 64 channels, 3x3 convolutions
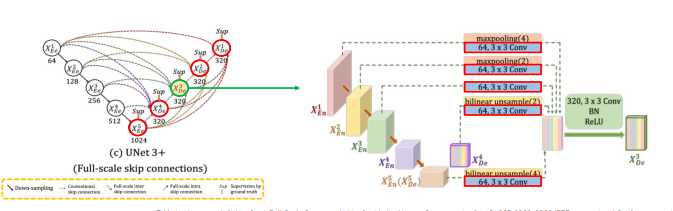
parameter 줄이기 위해 모든 decoder layer 의 channel 수 320 통일, 모든 인코더 레이어에서 skip connection 과정에서 64 channel, 3x3 conv 동일하게 적용(64 x 5 = 320) -
각 모델의 parameter 비교
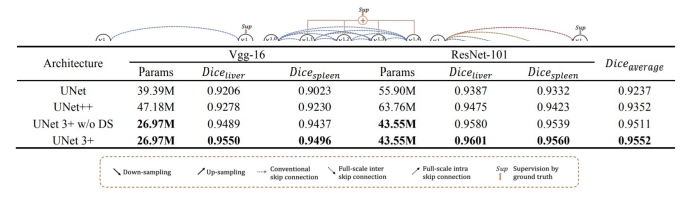
-
Classification-guided Module(CGM)
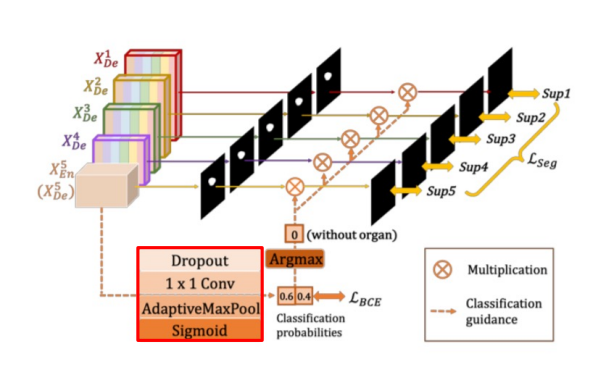
노이즈로 인한 false - positive문제 해결 / fp 문제 : 실제로는 배경인데 노이즈때문에 객체로 예측하는 문제
정확도를 높이고자 extra classification task 진행
high-level feature map인 인코더5의 feature map을 사용하여 dropour-1x1 conv-pool-sigmoid 통과
argmaw를 통해 organ이 없으면 0, 있으면 1
이 결과를 인코더 각 low-layer의 아웃풋에 곱
-> low-layer의 feature map에 노이즈가 있더라도 extra classfication 결과인 0을 곱하면 0이 되어 노이즈 제거 가능
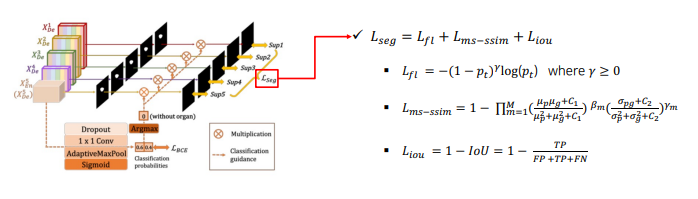 경계부분 잘 학습하기 위해 focal loss(클래스 불균형 해소) + ms-ssim loss(boundary 인식 강화) + IoU loss(픽셀의 분류 정확도 상상) 를 결합하여 사용
경계부분 잘 학습하기 위해 focal loss(클래스 불균형 해소) + ms-ssim loss(boundary 인식 강화) + IoU loss(픽셀의 분류 정확도 상상) 를 결합하여 사용
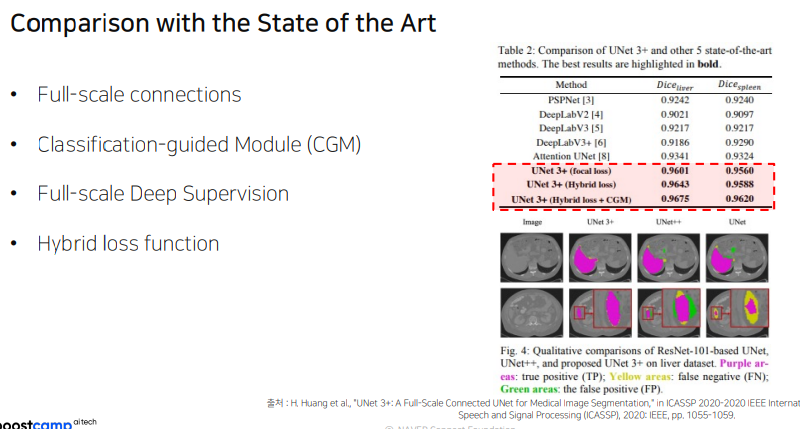
3.3 결론
Further Reading
Unet
Unet++
Unet3+
EfficientUnet
DenseUnet
ResidualUnet
과제 수행 과정 및 결과
피어 세션
일요일까지 naive template 에 모델 추가해서 돌아가게 해놓기
학습 회고
U-Net receptive field를 다양화하기 위한 techique이 흥미롭고 재미있다.
수업을 듣는데 시간이 너무 오래걸린다. 한번에 빡 집중하고 끝내버리자
