강의 내용 복습
(07강) Semantic Segmentation 대회에서 사용하는 방법들 1
1. Library
Segmentation models
2. baseline 이후 실험해봐야할 것들
2.1 주의사항
-
디버깅 모드
실험 환경이 잘 되어있는지 체크 : 데이터셋 수를 작게, epoch을 작게해서 코드가 잘 돌아가는지 확인 후 train -
시드 고정
모델 성능 비교시 실험마다 성능이 달라지는 것 방지 : torch외 numpy ,os 관련 시드 고정
validation 검증셋의 시드 고정
-
실험 기록
Network 종류, Augmentation 방법, Hyperparameter 등 성능에 영향을 주는 조건을 바꿔가며 실험을 진행한 후, 그 결과를 기록 -
실험은 한번에 하나씩
예를 들어 이전 실험 조건에서 Network 종류와 Augmentation 방법을 모두 변경하여 실험할 경우, 두 조건 중 어떤 조건이 성능 향상/하락에 영향을 주었는지 알기 어려움 -
팀원마다 역할 분배
베이스라인 코드 성능 업데이트->여러사람이 나눠서 실험진행 시 같은 코드에 실험을 서로 중복되지 않게 진행!
솔루션 조사/디스커션 조사 - 한명이 맡아서
2.2 validation
제출없이 모델 성능 평가할 수 있음 / Public 리더보드의 성능에 오버피팅 되지 않도록 도와줌
- Hold Out
전체 데이터를 8:2로 분리해 train/valid data로 분리, 20% 데이터는 학습에 사용되지 못하는 문제 - K-Fold
Hols Out에 split 개념을 도입해 모든 데이터셋이 학습에 참여하도록 함, Ensemble 효과로 대부분 모델 성능 향상, Hold Out 방식에 비해 k배의 시간 - Stratified K-Fold
Fold마다 class distribution을 동일하게 split하여 fold 별 class imbalance 없도록 함 - Group K-Fold
train에서 본 데이터를 valid에 사용하면 일반화 성능 향상에 도움이 되지 않으므로 train, valid에 동일한 그룹이 섞이지 않도록 함 (참여자 별로 데이터1,2,3이 있을 때 학습시 참여자 1의 데이터를 사용했다면 valid에는 참여자 1의 데이터가 없도록 구성)
2.3 Augmentation
- 데이터 수를 증가
- Generalization이 강화
- 성능이 향상
- Class Imbalance 문제를 해결
torchvision, Albumentation 등의 library 사용
무조건 많이 적용한다고 성능 오르지 않음 / 도메인 상황, 데이터 셋에 맞는 augmentation 적용
kaggler 들이 많이 사용하는 기법
- Cutout(Albumentation : CoarseDropout)

이미지 내에 random 하게 box생성하여 이미지 가림 -> 객체의 중요부분 또는 context information 삭제할 수 있다는 단점 - Gridmask(Albumentation : GridDropout)

규칙성있는 박스 생성을 통해 cutout , 기존 cutout 단점 보완 - Mixup

입력이미지 두개를 섞음 (투명도 조절 느낌) - Cutmix


입력 이미지 두개를 섞는데, 박스로 잘라서 섞음 - SnapMix
CAM(Class Activation Map)을 이용해 이미지 및 라벨을 mixing하는 방법
영역 크기만을 고려해 라벨을 생성했던 CutMix와 달리 영역의 의미적 중요도를 고려해 라벨을 생성 - CropNonEmptyMaskIfExists
object가 존재하는 부분을 중심으로 crop 할 수 있다면 model의 학습을 효율적으로 할 수 있음
2.4 SOTA Model
인코더, 디코더 포함 많은 실험 해보기
segmentation 에서는 현재 HRNet이 SOTA
2.5 Scheduler
하이퍼파리미터 찾기 -> learning rate
-
CosineAnnealingLR
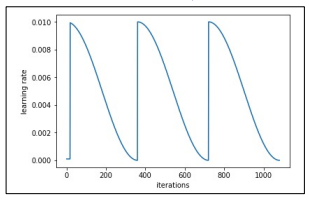
Learning rate의 최대값과 최소값을 정해, 그 범위의 학습율을 Cosine 함수를 이용해 스케줄링하는 방법
• 최대값과 최소값 사이에서 learning rate를 급격히 증가시켰다가, 감소시키기 때문에 saddle point, 정체 구간을 빠르게 벗어나게 함 -
ReduceLROnPlateau
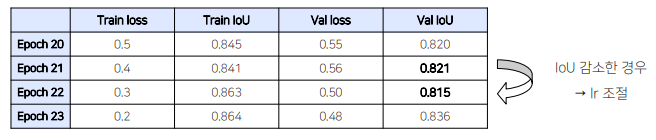
metric의 성능이 향상되지 않을 때 learning rate를 조절하는 방법
• Local minima에 빠졌을 때 learning rate를 조절하여 , 효과적으로 빠져나옴 -
Gradual Warmup
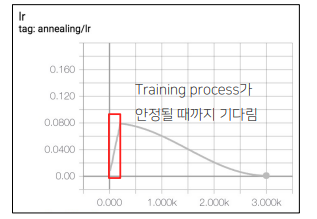
학습을 시작할 때 매우 작은 learning rate로 출발해서 특정 값에 도달할 때까지 learning rate를 서서히
증가시키는 방법
• 이 방식을 사용하면 weight가 불안정한 초반에도 비교적 안정적으로 학습을 수행할 수 있음
• backbone 네트워크 사용시에 weight가 망가지는 것을 방지
Batch Size
모델의 weight를 매 step 마다 업데이트하지 않고, 일정 step 동안 gradient를 누적한 다음 누적된
gradient를 사용해 weight를 업데이트하는 방법
• 배치 사이즈를 키우는 장점이 있음
// 배치사이즈가 크다고 무조건 좋은게 아님
Optimizer
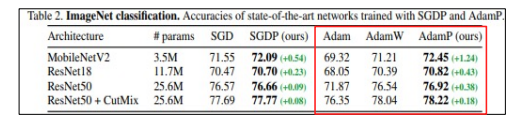
Adam, AdamW, AdamP 등
- Lookahead optimizer
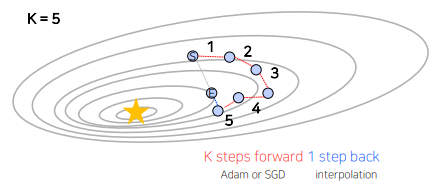
Adam이나 SGD를 통해 k번 업데이트 후, 처음 시작했던 point 방향으로 1 step back 후, 그 지점에서 다시
k번 업데이트를 시작하는 방법
• Adam이나 SGD로는 빠져나오기 힘든 Local minima를 빠져나올 수 있게 한다는 장점
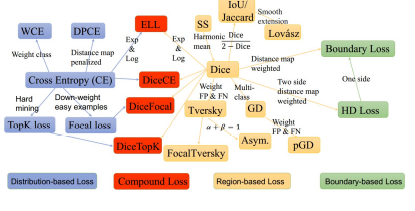
Loss
Compound Loss 계열은 imblanced segmentation task에 강인한 모습
(08강) Semantic Segmentation 대회에서 사용하는 방법들 2
1. baseline 이후에 실험 해봐야할 사항들 II
1.1 Ensemble
-
k-fold ensemble
-
Epoch Ensemble
학습을 완료한 후, 마지막부터 N개의 Weight를 이용해 예측한 후 결과를 Ensemble하는 방법 -
SWA(Stochastic Weight Averaging)
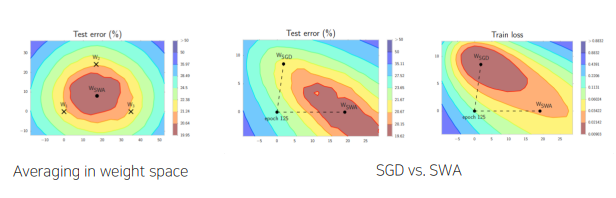

각 step마다 weight를 업데이트 시키는 SGD와 달리 일정 주기마다 weight를 평균 내는 방법
마지막 25%의 epoch에서 SWA진행(비율 사용자 결정) -
Seed Ensemble
Random한 요소를 결정짓는 Seed만 바꿔가며 여러 모델을 학습시킨 후 Ensemble하는 방법 -
Resize Ensemble
input image size를 다르게 해 Ensemble하는 방법 -
TTA(Test Time Augmentation)
Test set으로 모델의 성능을 테스트할 때, augmentation을 수행하는 방법 / 원본 이미지와 함께 augmentation을 거친 N장의 이미지를 모델에 입력하고, 각각의 결과를 평균 / 모델은 같은 모델 / segmentation 같은 경우 좌표가 원본에 맞게 나오기 때문에 transform된 사진 다시 돌려줘야 됨- 학습 때와 다른 input size 이미지를 통해 test하는 방법 - TTA Library - ttach

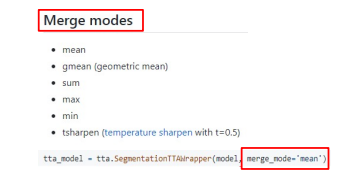 마지막에 원본으로 다시 되돌려주는 것까지 해줌
마지막에 원본으로 다시 되돌려주는 것까지 해줌
- 학습 때와 다른 input size 이미지를 통해 test하는 방법 - TTA Library - ttach
1.2 Pseudo Labeling
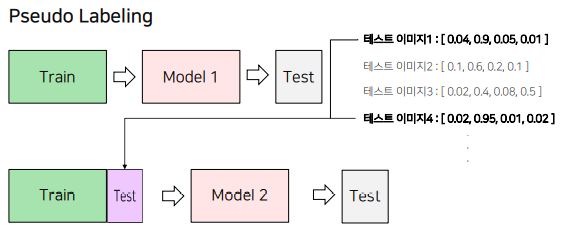
1) 모델 학습을 진행
2) 성능이 가장 좋은 모델에 대해 Test 데이터셋에 대한 예측을 진행
• 이 때 Softmax를 취한 확률값이나 Softmax를 취하기 전의 값, torch.max를 취하기 전의 값을 예측
3) 2단계에서 예측한 Test 데이터셋과 Train 데이터셋을 결합해 새롭게 학습을 진행
4) 3단계에서 학습한 모델로 Test 데이터셋을 예측
1.3 외부 데이터 활용
외부 데이터 활용
1.4 그 외
classification 결과 활용
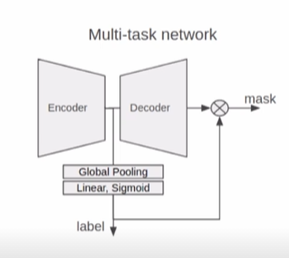
Encoder Head 마지막 단에 Classification Head를 달아서 같이 활용 (UNet3+ 에서 활용)
Classification 결과도 같이 학습해서 모델의 수렴을 도와주는 경우
2. 대회에서 사용하는 기법들 소개
2.1 최근 딥러닝 이미지 대회의 Trend
- problem 1
학습 이미지가 많고 큰경우 네트워크를 한번 학습하는데 시간이 오래 걸려서 충분한 실험 못함 - solutions
-
FP16 : 속도를 높이기 위한 FP16연산과 정확도를 유지하기 위한 FP32 연산을 섞어서 학습하는 방법
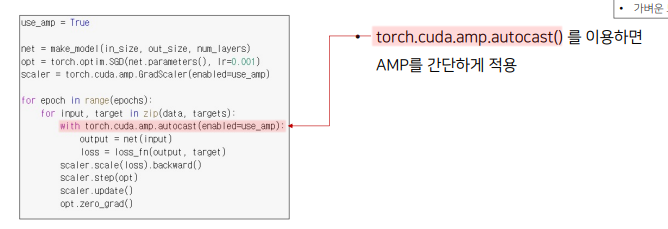
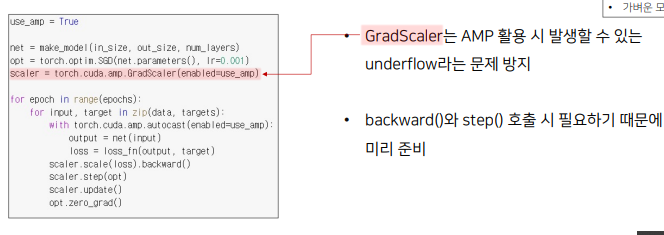
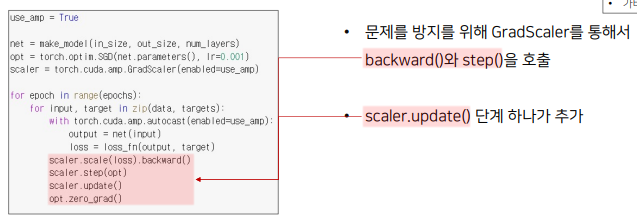
-
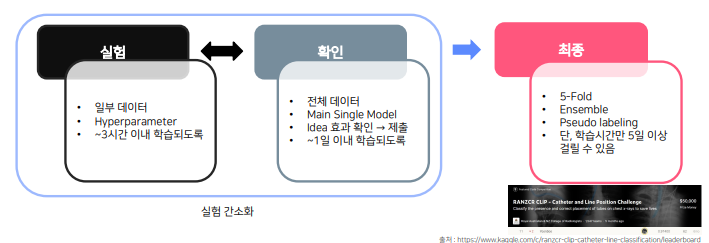
실험 간소화
단, LB 와 Validation Score 간의 어느 정도 상관관계가 있어야함
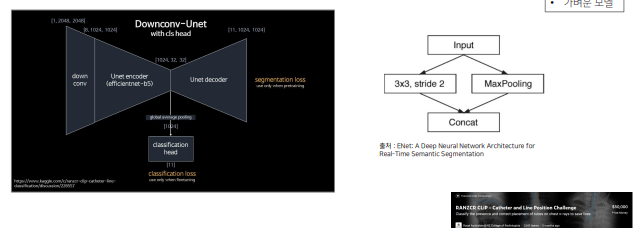 DownConv UNet
DownConv UNet -
가벼운 모델로 실험
efficient b0 과 같이 파라미터가 적고 가벼운 모델로 실험
- problem 2 : 주어진 data인 Image의 크기가 매우 큰 경우 model이 학습하는 시간이 매우 오래 걸림
solutions
1. 주어진 data모두 resize시켜 학습 - test set에 대해 예측된 mask는 interplation으로 원본 size로 복원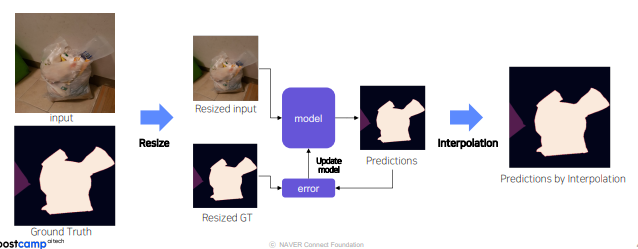 image가 너무 큰 경우 resolution 감소 문제
image가 너무 큰 경우 resolution 감소 문제
- Silding window(Overlapping / Non-overlapping) window size 및 stride 중요
stride와 window 작게 하면 이미지를 겹치게 잘라 학습데이터의 양이 늘어나고 다양한 정보를 얻을 수 있지만 / 중복되는 정보가 많아 늘어나는 양에 비래 성능의 차이는 적고 학습 속도가 오래 걸리는 문제 발생 - 그외의 팁
일반적으로 train에 사용된 sliding window와 inference시 sliding window 크기가 동일해야 한다고 생각하지만, inference시 sliding sindow를 더 크게 하면 더 많은 주변 정보로 prediction 할 수 있어서 성능에 향상을 보임
Sliding window 적용하면 아래와 같이 유의미하지 않은 영역들이 잡히는 경우가 많음
• 해결 방안 : “background” 만 수집된 영역은 조금만 샘플링
- Task 가 Binary Classification인 경우
threshold인 probability를 오직 0.5로 끊지 않고 하이퍼파리미터로 탐색해도 됨
2.2 model 의 개선하기 위한 Tips
- output image 확인하여 object잘 예측하는지 확인
2.3 Label Noise가 있는 경우 Tips
- label noise있는 경우 : mask boundary가 불명확한 경우 , label이 올바르지 않은 경우 등
- Label smoothing : Hard target -> Soft target ---> soft cross entropy loss
- Pseudo-labeling을 이용한 label processing
fold별 학습시 noised label 이미지 학습 후 validation하면 잘 예측을 해도 GT와 다르기 때문에 mIoU가 낮게 나옴. 모든 이미지의 mIoU를 계산한 후 낮은 순서대로 비교를 해보면 이는 실제 이미지가 잘 못맞춘 이미지일 수도 있지만 GT자체에 noise가 있을 수도 있음.
이 경우 예측한 결과를 GT로 삼아서 다시 학습을 시키는 방법.
2.4 최근 딥러닝 이미지 대회의 평가 Trend
기존 평가 방식인 Accuracy, mIoU 이외에 다양한 평가 방식을 추가
-
학습 시간의 제한이 있는 경우
epoch ensemble 과 SWA같은 경우 사용하는 모델이 같기 때문에 학습 시간에는 영향을 끼치지 않고 추론 시간에만 영향이 있음 -
추론 시간의 제한이 있는 경우
-
속도 평가를 하는 경우
tensor RT 등 의 사용
3. Monitoring Tool
3.1 Weights \& Biases
- 실험을 돌려 놓고 다른 작업을 진행하기 편리
- Web을 통해 결과를 실시간으로 확인가능
- model에 대한 실험 결과를 비교 가능
- step, learning rate 에 따른 score 등을 비교가능
- 학습된 model로 부터 inference결과를 web에서 확인 가능
과제 수행 과정 및 결과
피어 세션
지난 일주일간 각자 한 feature 공유
학습 회고
아침에 일찍 일어나서 공부를 해야겠다.
자소서 코테 면접과 겹치니 잠을 줄여서 공부하는 수 밖에 없겠다. 체력관리를 하자!
