강의 내용 복습
(01강) Image Classification 1
사람은 오감(특히 시각)을 통해 세상과 소통한다. 시각을 통해 정보를 해석하는 과정을 기계가 하는 방식으로 표현하면 아래 그림과 같다.

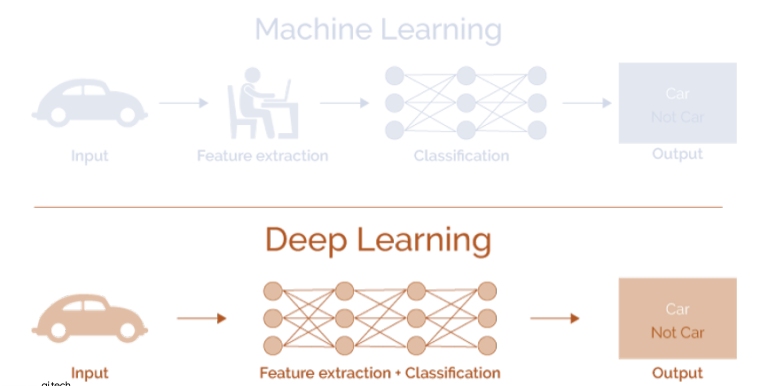
Image Classification
영상안에 어떤 물체가 있는지 분류하는 문제
만약 모든 데이터를 가지고 있다면 분류문제는 단순히 K-nn으로 풀수 있을 것이다.
하지만 이 방법의 단점은 시간,공간 복잡도와 각 데이터의 유사도 측정 방법 선정에 있다.
single fully connected layer로 분류한다면?
단점 : layer가 하나이기 때문에 모델의 표현력이 떨어지며, 일반화 성능도 낮음
CNN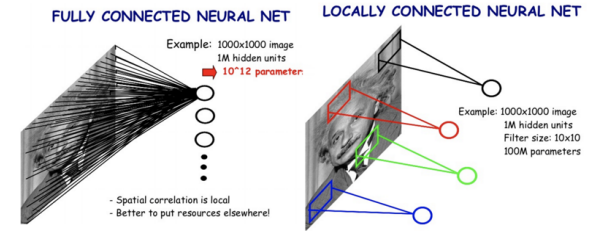
FCN보다 훨씬 작은 weight를 sliding window기법으로 순회하며 이미지의 국부적인 영역에서 특징 추출
-> CV task의 backbone으로 많이 쓰임
CNN architecture for image clf

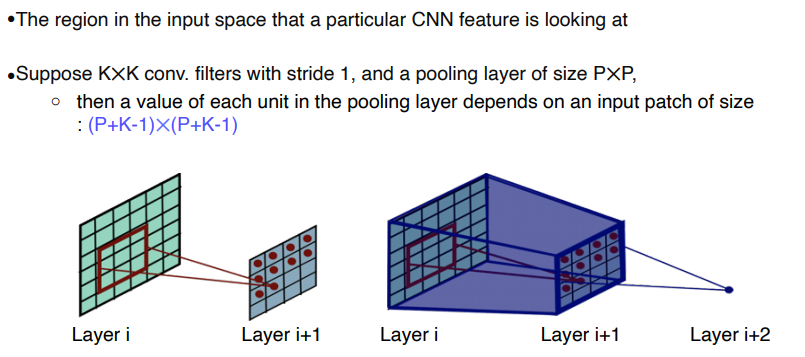
- Receptive field in CNN
특정 feature가 결정되기 까지 거친 input space 의 영역
AlexNet

LeNet과 비슷하지만 차이점은
- bigger (7 hidden layers, 605K neurons, 60 million params)
- trained with ImageNet
- Using better activation Function(ReLU) and regularization technique(drop out)
특징
- 네트워크를 절반씩 나누어 두개의 GPU로 학습
- Local Response Normalization (LRN)
- 11 x 11 conv filter
VGGNet
특징
- Deeper architecture (16 and 19 layers)
- Simple architecture (No LRN, only 3x3 conv filter blocks, 2x2 max pooling) -> 작은 filter를 쌓으면 큰 Receptive field를 보는 것과 같은 효과
- Better performance
- Better generalization
Ref
VGGNet
(02강) Annotation Data Efficient Learning
Data Augmentation, Knowledge Distillation, Transfer learning, Learning without Forgetting, Semi-supervised learning 및 Self-training
Data Augmentation
data set 은 real data 의 분포를 모두 표현할 수 없기 때문에 aat augmentation이 필요하다.
Crop, Rotate, flip, Brightness adjust, Affine transforms 등 transforms
CutMix
데이터를 합성해서 증강하는 것- 라벨도 같은 비율에 따라 합성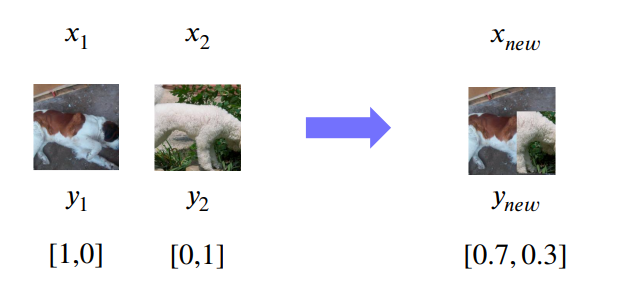
RandAugment
어떤 Augmentation, 얼마나 세게 할지 강도를 파라미터로 받아 Random하게 Augment 적용
Leveraging pre-trained information
Transfer Learning
기존에 미리 학습시켜놓은 모델을 사용하여 적은 학습으로 새로운 task에 적용
-
Transfer knowledge from a pre-trained task to a new task

Backbone은 freeze, FC layer만 새로 붙여 학습시킴 -
Fine-tuning the whole model
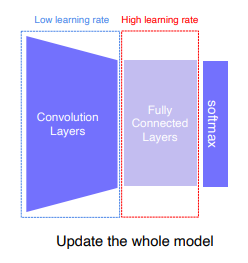
Backbone은 low learning rate, FC layer 는 High learning rate를 주어 학습시킴 데이터 좀 더 많이 필요함
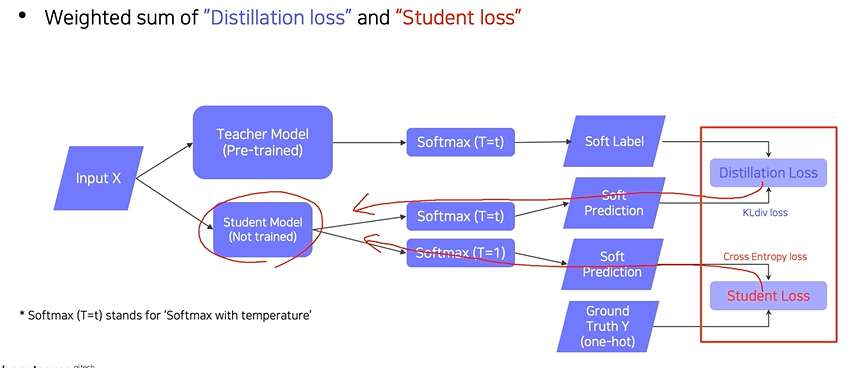
Knowledge distillation
model compression(큰 모델이 알고있는 지식을 작은 모델에 압축), pseudo labeling (unlabeled dataset에 라벨 생성)
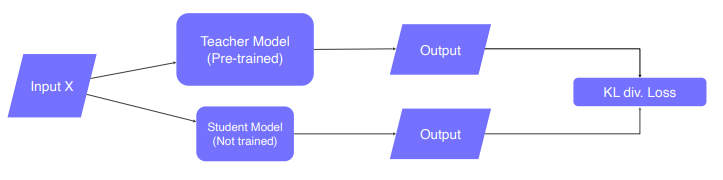
back prop 시 student model만 update
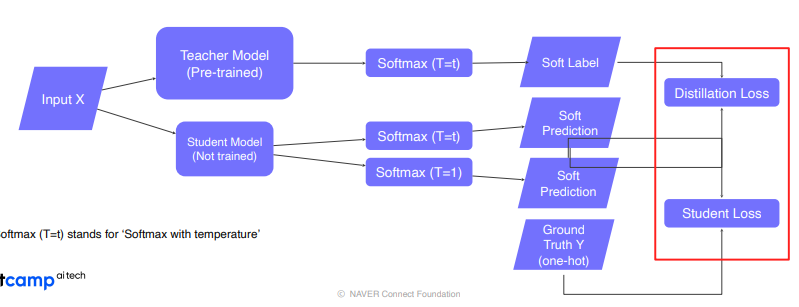
labeled data가 있으면 위와 같이 사용.
Distillation Loss : teacher와 student모델 결과의 유사도 측정하는 KL-Divergence Loss (Soft Label)
Student Loss : Ground Truth와의 Cross Entropy Loss (Hard Label)
Soft Prediction : logit
Softmax with temperature(T) : hard prediction과 같은 극단적인 값보다는 중간 값들도 나오게 만들어 더 많은 정보를 가지게 함으로써 student가 teacher를 더 잘 따라하게 함
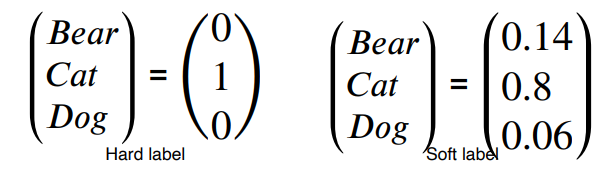

Semantic information is not considered in distillation
Leveraging unlabeled dataset for training
Semi-supervised Learning
매우 큰 Unlabeled data를 활용하는 방법

Self-training
Augmentation + Teacher-Student networks + semi-supervised learning

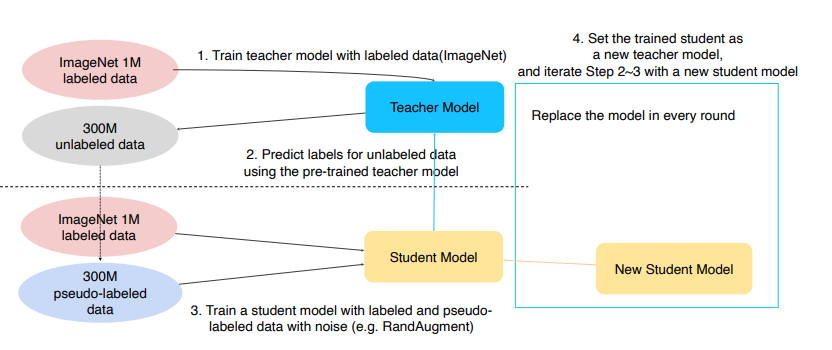
- 라벨이 있는 데이터로 선생모델 학습
- 선생모델이 라벨 없는 데이터에 라벨 부여
- 라벨이 있는 데이터 + 라벨 부여 받은 데이터로 학생 모델 학습 (Rand Augment 적용)
- 그 학생모델을 선생 모델로 만들고 학생모델은 조금 더 큰 모델로 다시 생성
- step 2~4 반복
Ref
CutMix
과제 수행 과정 및 결과
VGG Net 구현
피어 세션
