강의 내용 복습
(03강) Image Classification 2
Problems with deeper layers
Network가 깊어질수록 큰 receptive field관찰이 가능하지만, 계산 복잡도가 커지고 gradient vanishing/exploding 문제가 발생한다.
CNN architectures for image classification 2
GoogLeNet = Inception v1
-
Inception module
 input 에 4가지의 convolution, pooling연산을 한 후 channel 방향으로 concat 하는 것. feature를 효과적으로 추출하기 위해 1X1, 3X3, 5X5 convolutions과 3x3 max pooling 연산을 하는데, 이렇게 하면 계산 복잡도가 너무나 커지게 된다. 이를 해결하기 위해 사용하는 것이 1x1 convolution이다.
input 에 4가지의 convolution, pooling연산을 한 후 channel 방향으로 concat 하는 것. feature를 효과적으로 추출하기 위해 1X1, 3X3, 5X5 convolutions과 3x3 max pooling 연산을 하는데, 이렇게 하면 계산 복잡도가 너무나 커지게 된다. 이를 해결하기 위해 사용하는 것이 1x1 convolution이다. -
1x1 convolution
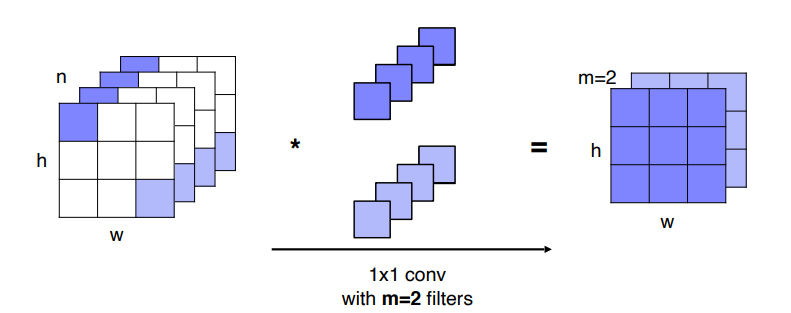 input의 height와 width는 유지하고 channel의 수만 감소시켜 전체 parameter 개수를 줄이는 효과
input의 height와 width는 유지하고 channel의 수만 감소시켜 전체 parameter 개수를 줄이는 효과 -
Auxiliary classifiers
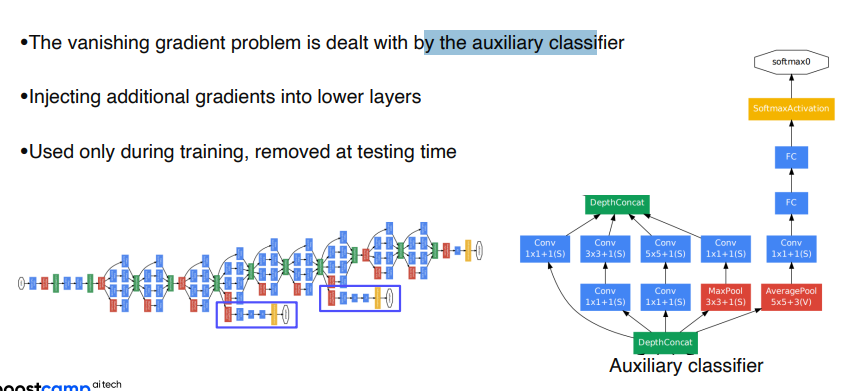
모델이 깊어지면 생기는 gradient vanishing문제를 해결하기 위한 classifier. 모델 중간에 softmax layer를 두어 입력층 앞쪽까지 gradient가 흘러가게 한다. test를 할때는 제거한다.
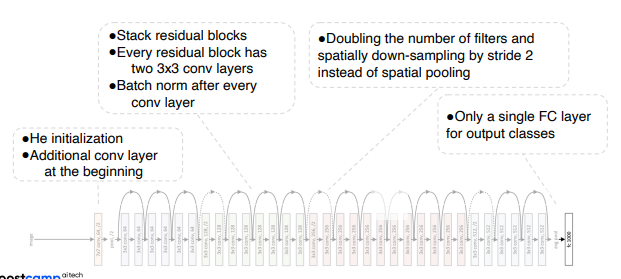
ResNet
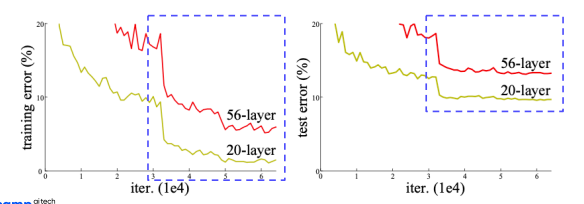 네트워크를 깊게 한다고 무조건 성능이 좋아질까? 라는 의문을 가지고 시작한 논문. 하지만 실제로는 vanishing/exploding gradient 문제때문에 성능이 떨어진다. 이를 degradation problem이라고 하는데, back propagation이 진행될수록 wight의 분포가 불균등해져 역전파시 gradient가 충분히 크지 않아 학습이 제대로 일어나지 않는 현상이다. 이는 overfitting이라고 생각하겠지만 논문에서는 optimiziation 문제라고 말하고 있다.
네트워크를 깊게 한다고 무조건 성능이 좋아질까? 라는 의문을 가지고 시작한 논문. 하지만 실제로는 vanishing/exploding gradient 문제때문에 성능이 떨어진다. 이를 degradation problem이라고 하는데, back propagation이 진행될수록 wight의 분포가 불균등해져 역전파시 gradient가 충분히 크지 않아 학습이 제대로 일어나지 않는 현상이다. 이는 overfitting이라고 생각하겠지만 논문에서는 optimiziation 문제라고 말하고 있다.
-
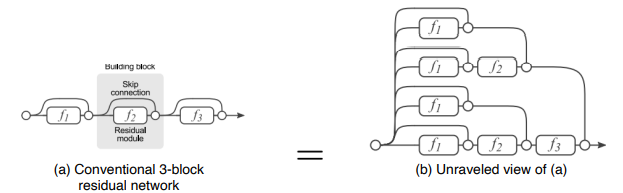
Residual block
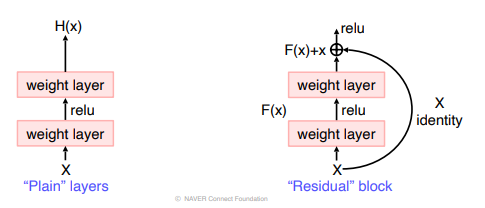 "Plain" layers는 여러 비선형 layer를 거쳐 천천히 복잡한 target function이 에 가까워진다. 이것보다는 로 생각하고 를 H(x)에 근사하게 만드는 것(Residual Mapping)이 더 쉽다고 가정한다.
"Plain" layers는 여러 비선형 layer를 거쳐 천천히 복잡한 target function이 에 가까워진다. 이것보다는 로 생각하고 를 H(x)에 근사하게 만드는 것(Residual Mapping)이 더 쉽다고 가정한다. -
Identity mapping by Shortcut connection
identity X를 전달하여 역전파시 gradient를 적어도 1은 보장하고(X의 미분값 = 1), 이렇게해서 vanishing gradient로 인한 degradation problem을 해결한다. -
Analysis of residual connection

개의 gradient가 지나갈수 있는 input-output path가 생성된다. residual block이 하나 추가될때마다 경로는 2배가 된다. 이를 통해 굉장히 복잡한 mapping을 학습할 수 있다. -
Overall architecture
DenseNet
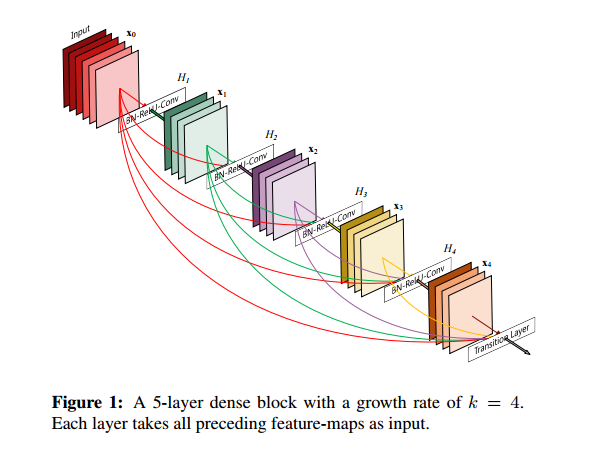
ResNet 보다 적은 파라미터 수로 더 높은 성능을 가진 모델.
모든 레이어의 feature map을 연결한다. 이전의 레이어의 feature map을 이후에 나오는 모든 레이어에 연결하는데, 이때 Resnet과 다르게 더해주는 것이 아닌 channel을 기준으로 concat하기 때문에 feature map의 크기가 같아야한다. 이렇게 연결하면 마지막에는 channel 개수가 굉장히 많아지기 때문에 각 layer의 channel은 작은 값을 이용한다.
-
Strong gradient flow, information flow
입력 단에 있는 feature map을 마지막 레이어까지 전달하면서 정보 소실, 기울기 소실 문제 해결 -
각 layer 의 channel 수가 작기 때문에 파라미터 수가 적음
SENet
channel-wise feature response를 적절하게 조절해주는 “Squeeze-and-Excitation(SE)” 방법론. 채널간의 상호의존도 (interdependency)를 모델링하여 feature recalibration(재조정)한다.
- SE Block

EfficientNet
compound scaling
Beyond ResNets
- Deformable convolution
Summary of image classification
Ref
GoogLENet 논문리뷰1
ResNet 논문리뷰
DenseNet 논문리뷰
과제 수행 과정 및 결과
없음
피어 세션
Q. Knowledge distillation 에서 self-training을 할 때 KL-divergence loss를 사용하는 것인지?
A. No. 둘(model compression, self-training)은 Knowledge distillation이라는 같은 카테고리 아래에 있을 뿐 학습 목적과 방법이 다르다.
추가 설명
공통점
teacher-student model 구조를 가진다.
차이점
model compression
Leveraging pre-trained information, 즉 미리 학습된 정보를 활용하는 방법으로,
student model이 teacher model 을 따라하게(mimic) 한다.
teacher model이 예측한 label 과 student model 이 예측한 logits을 KL-divergence Loss를 사용하여 분포 차이를 줄인다.
student model은 teacher model보다 작은 모델을 사용한다.
self-training
Leveraging unlabeled dataset for training, 즉 labeling되지 않은 data를 활용하는 방법으로,
labeled data 로 teacher model을 지도학습 시킨후, unlabeled data에 label(= pseudo label)을 부여한다.
이후 labeled data + pseudo labeled data를 모두 더해 student model을 지도학습한다.
student model은 teacher model보다 큰 모델을 사용한다.
Q. semi-supervised learning 과 self-training의 차이?
A. semi-supervised learning의 한 종류가 self training 이다
추가 설명
semi-supervised learning의 종류
Semi-supervised learning 방법론 소개
학습 회고
논문 리뷰 및 구현 스터디 시작
