강의 내용 복습
(04강) Semantic Segmentation
사진이 주어졌을 때 사진 내 각 픽셀을 카테고리로 분류하는 task(즉, 하나의 사진이 아닌, 사진에 있는 모든 물체들을 분류한다는 것) 이때 instance를 고려하는 것이 아닌 sementic category 만을 고려한다. (사람 두명이 붙어있으면 묶어서 구분 / instance 기준으로 구분하는 것은 instance segmentation)
Appliications
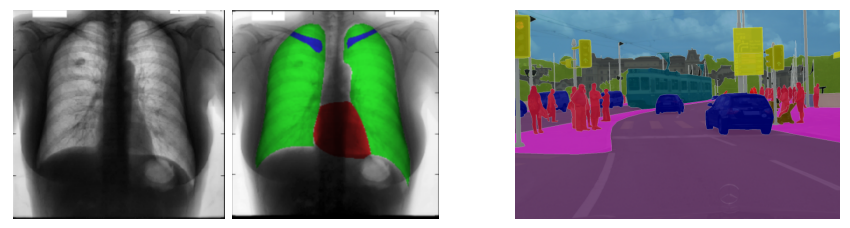
sementic segmentation architecture
Fully Convolutional Networks(FCN)
- end-to-end architecture
중간에 있는 layer가 모두 미분가능한 network로 구성되어 있다. - input size 고정 되어 있지 않다.
Fully Connected vs Fully Convolutional
1x1 convolution
영상의 공간정보 유지하지 못함
-> 채널 축으로 Flattening = 1x1 convolution 과 같은 결과
pooling layer 를 통해 score map(activation map)을 아주 작게 만들어 적은 픽셀로도 큰 receptive field를 볼 수 있게 되지만, 해상도가 떨어지는 문제가 있다. 이를 해결하기위해 upsampling 기법을 사용한다.
score map, activation map
upsampling
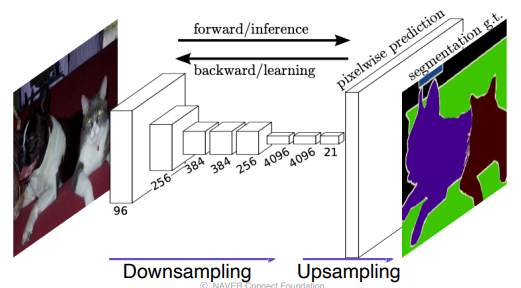
- Unpooling
- Transposed convolution
- Upsample and convolution
Transposed convolution
Upsample and convolution
다시 FCN으로 돌아와서,,
score map을 크게 하기 위해(해상도 측면) 중간에 skip connection 을 넣는다.
Hypercolumns for object segmentation
end-to-end가 아님
U-Net
- FCN
- concatenating feature maps from contracting path(simmilar to skip )
- Yield more precise segmentations
Overall Architecture

-
contracting path
channel 수 두배로 증가 -
Expanding path
2x2 convolution의 반복 적용
channel수 를 절반으로 감소
다른 점 : contracting path의 대칭적인(대응되는) feature map 을 concatenate (lower layer에 있는 activation map을 합쳐서 localized information정보를 뒤쪽 layer에 전달)
점진적으로 해상도가 늘어나는 구조 (through up-conv)
U-Net 사용시 주의할 점
만약 feature map 의 sptial size 값이 홀수라면?
down sampling 時에는 버림으로 계산되어(항상 그런건 아님. U-Net구현에서 그렇다는 것) 결과 feature map spatial size가 홀수가 되는데, 이 상태에서 upsampling을 하면 size가 두배가 되어 처음의 feature map과 size가 달라 concatenating을 하지 못하게 된다.
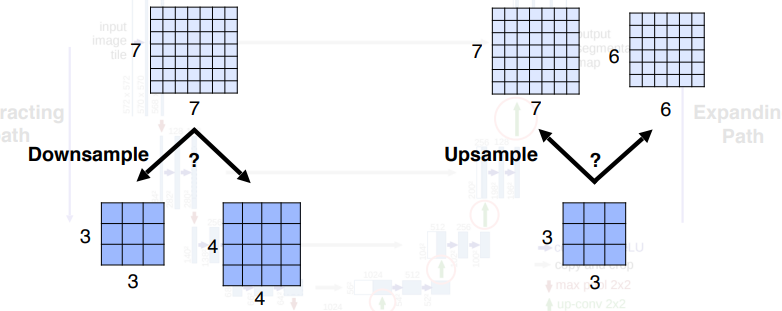
pytorch 구현
Expanding path 에서 ConvTransposed2d 로 Up-conv를 수행하는데, 이때 kernel_size = 2, stride = 2로 설정하여 겹치는 부분을 없애 checker board architecture 가 생기지 않는다.
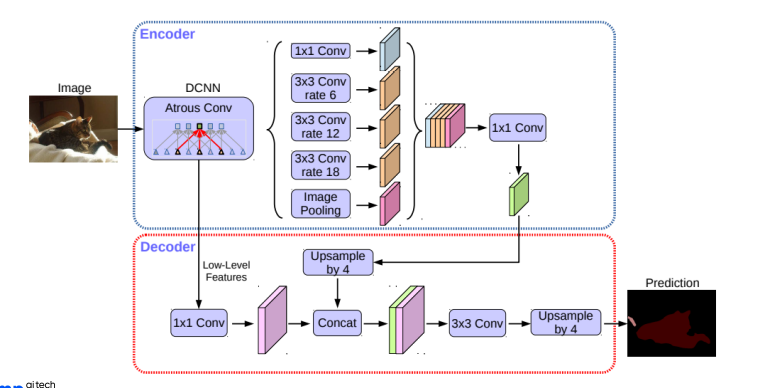
DeepLab

-
DeepLab v1 : Conditional Random Fields (CRFs)
후처리 기법, 최적화를 통해 아미지 안의 경계(edge)를 잘 찾을 수 있도록 한다. -
DeepLab v2,v3 : Dilated convolution(Atrous Convolution)
convolution kernel의 pixel 사이에 빈공간을 넣어 같은 크기의 parameter로 더 큰 receptive field를 볼 수 있도록 한다 -
DeepLab v3+ : Depthwise separable convolution
sementic segmentation 의 입력 해상도가 워낙 크기 때문에 연산이 오래걸리는 것을 줄이려고 했다.
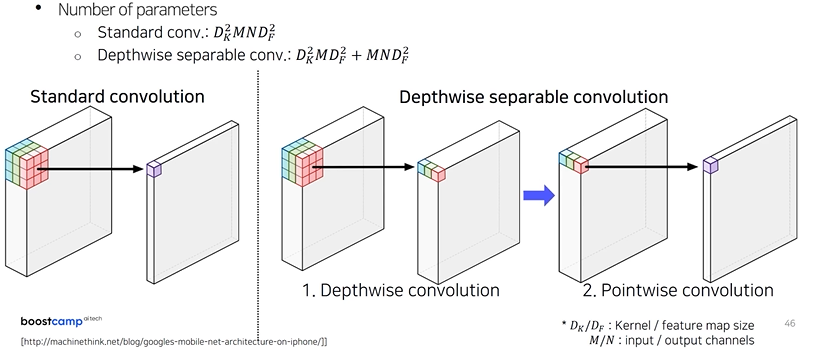
Depthwise convolution : 채널 별로 convoulutoin
Pointwise convolution : 하나의 값에 출력이 되도록 합쳐준다
계산량의 order가 작음
DeepLab v3+ Overall Architecture
Further Reading
Checkerboard artifacts
FCN
UNet
Ref
1. Semantic segmentation
- Chen et al., Rethinking Atrous Convolution for Semantic Image Segmentation, arXiv 2017
- Novikov et al., Fully Convolutional Architectures for Multi-Class Segmentation in Chest Radiographs, T-MI 2016
- Aksoy et al., Semantic Soft Segmentation, SIGGRAPH 2018
- Semantic segmentation architectures
- Long et al., Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
- Hariharan et al., Hypercolumns for Object Segmentation and Fine-Grained localization, CVPR 2015
- Ronneberger et al., U-Net: Convolutional Networks for Biomedical Image Segmentation, MICCAI 2015
- Chen et al., Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs, ICLR 2015
- Howard et al., MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, arXiv 2017
- Chen et al., Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, ECCV 2018
과제 수행 과정 및 결과
- Classification to Segmentation
classification을 풀기 위해 학습한 VGG-11을 다시 학습하지 않고 이미 학습된 weights를 재활용하여 segmentation 문제를 푸는 것이 목표.
이때 image classification에 활용되던 네트워크를 어떻게 하면 segmentation task에 확장할 수 있을 지에 대한 여러가지 노력들이 있었습니다. 대표적인 예시로 FCN으로 불리는 Fully Convolutional Networks for Semantic Segmentation (Long et al., CVPR 2015)이라는 네트워크가 있으며 spatial-information을 담지 못하는 fully-connected layer를 convolution layer로 대체하여 높은 segmentation 성능을 달성하였습니다.
피어 세션
reshaped_fc_out에서 shape가 (7, 512, 1, 1)인 이유? -> convolution에서 b c h w 순으로 입력하는데 b가 꼭 배치 사이즈인 것이 아니라 한 번에 들어가는 필터 개수 이기도 함
Upsampling이란? -> conv를 거치면서 크기가 줄어들고 map안에는 연산을 통한 픽셀들의 레이블이 들어가 있음, 이렇게 작아진 map의 사이즈를 다시 키워주는 것
imagenet 가져다 써도 ground truth를 해야 하는가? -> 그렇다. 경계를 정해주어야 segmentation 학습 가능
학습 회고
segmentation에 대한 더 깊은 이해 필요
