강의 내용 복습
1. Object detection
1.1 What is object detection?

Classification + Box localization
이미지 안의 object 를 분류함과 동사에 object가 위치한 곳에 boundin box까지 찾는다.
1.2 What are the applications of object detection?
Autonomous driving, Optical Character Recognition (OCR)
traditional method
- Gradient-based detector like HOG, SVM

영상의 경계선을 기준으로 물체 탐지 - Selective search

이미지 안 객체의 경계선, 질감, 색 등을 기준으로 over segmentation 한 다음 비슷한 bounding box를 묶는 방식
2. Two-stage detector (R-CNN family)
2.1 R-CNN
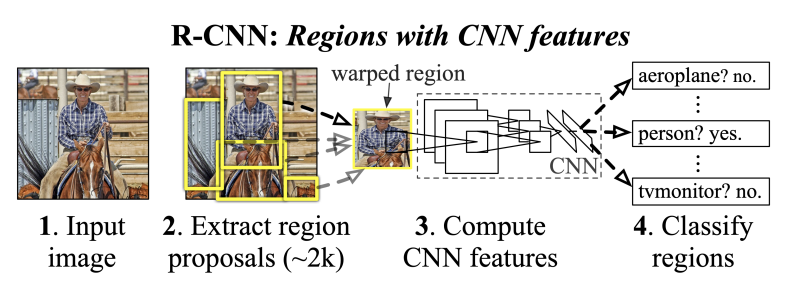
2.2 Fast R-CNN
이미지 안의 여러개의 object detection하기 위해 앞서 계산된 feature map 사용
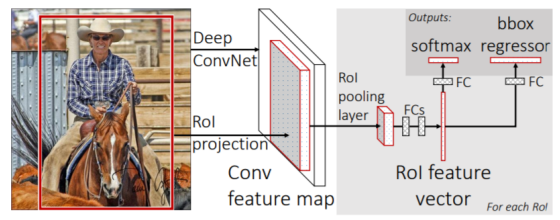
1. conv feature map from original image
2. RoI pooling
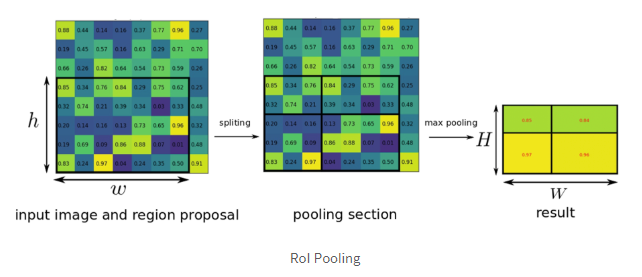
=spatial pyramid pooling : 미리 정해놓은 HxW 크기에 맞게끔 그리드를 정하고 각 영역에서 가장 큰값 추출 -> 고정된 크기의 feature map 나옴
3. class classification and bounding box regression
장점 : R-CNN에 비해 18배 빠른 속도
단점 : region proposal에 selective search 사용
2.3 Faster R-CNN
모든 파트가 neural net기반으로 만들어진 최초의 end-to-end object detection 모델
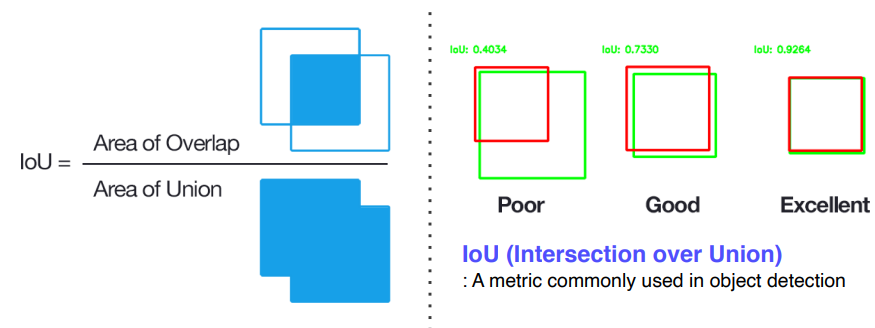
IOU : Intersection Over Union
두 영역의 합집합 중 교집합이 차지하는 비율로, object detection에서 사용되는 metric
Anchor Box
object가 있을 것이라고 예상되는 위치에 rough하게 정해놓은 다른 비율, 스케일을 갖는 bounding box
Anchor Box와 GT의 IOU를 계산하여 0.7이상이면 positive sample, 아니면 negative sample로

Region Proposal Network (RPN)

sliding window 방식으로 메위치마다 k개의 anchor box를 고려
각 위치에서 256 dim의 feature vector를 추출 - object인지 아닌지를 판단하는 2k개의 classification score - bounding box의 정교한 위치를 regression하는 4k개의 coordinates
 > k = 9 = # of anchor box인 경우
> k = 9 = # of anchor box인 경우
더 자세히 보면, classification을 수행하기 위해 1x1 convolution을 2x9 채널 수 만큼 수행하여 HxWx18 feature map을 얻음.H x W 상의 하나의 인덱스는 피쳐맵 상의 좌표를 의미하고, 그 아래 18개의 체널은 각각 해당 좌표를 앵커로 삼아 k개의 앵커 박스들이 object인지 아닌지에 대한 예측 값. 즉, 한번의 1x1 컨볼루션으로 H x W 개의 앵커 좌표들에 대한 예측을 모두 수행한 것. 이제 이 값들을 적절히 reshape 해준 다음 Softmax를 적용하여 해당 앵커가 오브젝트일 확률 값을 얻음.
두 번째로 Bounding Box Regression 예측 값을 얻기 위한 1 x 1 컨볼루션을 (4 x 9) 체널 수 만큼 수행. 리그레션이기 때문에 결과로 얻은 값을 그대로 사용
이제 앞서 얻은 값들로 RoI를 계산. 먼저 Classification을 통해서 얻은 물체일 확률 값들을 정렬한 다음, 높은 순으로 K개의 앵커만 추려냄. 그 다음 K개의 앵커들에 각각 Bounding box regression을 적용. 그 다음 Non-Maximum-Suppression을 적용하여 RoI을 구해줌
Non-Maximum Supperassion (NMS)
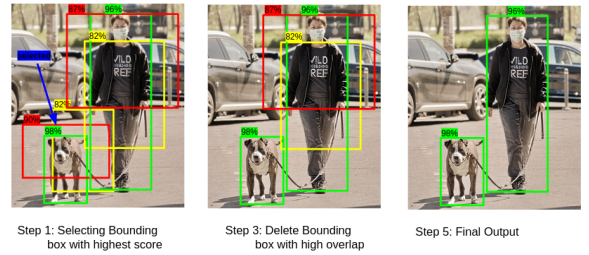
1. 가장 높은 objectiveness score를 가진 bounding box선택
2. 다른 박스와 IOU비교
3. IoU가 50%이상으로 겹치면 그 박스 제거
4. 다음으로 높은 objectiveness score 를 가진 box로 이동
5. 2~4 반복
summary
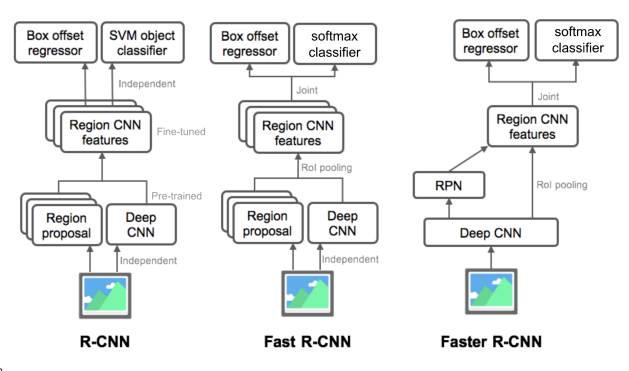
R-CNN : region proposal 별도의 알고리즘 사용 + CNN 이 target task에 학습된게 아닌 미리 학습되어 있음 -> 딥러닝의 장점 다 활용하지 못함
Fast R-CNN : 미분 가능한 ROI region pooling으로 여러개의 object 탐지 + CNN 부분 학습가능하게 만듬 -> region proposal 부분 학습 가능하지 않음
Faster R-CNN :region proposal 부분도 RPN사용으로 전체 프로세스 end-to-end로 학습가능하게 함
3. Single-stage detector

정확도를 조금 포기하더라도 속도를 빠르게 해서 실시간 탐지를 가능하게 한 방법
RoI와 관련된 내용 없음
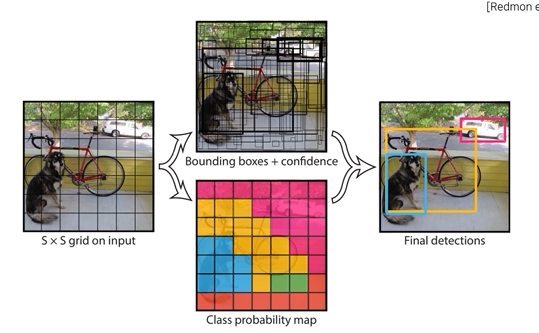
3.1 YOLO (You Look Only Once)
-
input image를 SxS 그리드로 나누고
-
각 그리드 영역에서 물체가 있을만한 영역에 해당하는 B개의 bounding box를 예측. 이는 (x,y,w,h)로 나타내어지는데, (x,y)는 bounding box의 중심점 좌표 / (w,h)는 너비와 높이.
-
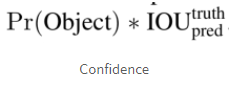 해당 박스의 신뢰도를 나타내는 confidence score 계산 : 해당 그리드에 물체가 있을 확률 Pr(Object)와 예측한 박스와 Ground Truth 박스와의 겹치는 영역의 비율을 나타내는 IoU를 곱해서 계산함.
해당 박스의 신뢰도를 나타내는 confidence score 계산 : 해당 그리드에 물체가 있을 확률 Pr(Object)와 예측한 박스와 Ground Truth 박스와의 겹치는 영역의 비율을 나타내는 IoU를 곱해서 계산함. -
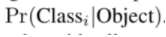 각각의 그리드마다 C개의 클래스에 대해 해당 클래스일 확률을 계산. 이때 특이한 점은 기존의 object detection은 항상 클래스 수 + 1 (배경)을 넣어 분류하는데 yolo는 아님.
각각의 그리드마다 C개의 클래스에 대해 해당 클래스일 확률을 계산. 이때 특이한 점은 기존의 object detection은 항상 클래스 수 + 1 (배경)을 넣어 분류하는데 yolo는 아님.
이렇게 각 그리드 별로 bounding box 와 clf 를 동시에 수행함 -
최종결과는 NMS로 도출
yolo의 구조

224x224 크기의 이미지 넷 클래시피케이션으로 pretrain. 이후엔448x448 크기 이미지를 입력으로 받음. 그리고 앞쪽 20개의 컨볼루션 레이어는 고정한 채, 뒷 단의 4개 레이어만 object detection 테스크에 맞게 학습시킴
최종 출력은 30 channel의 7x7 해상도.
SxS 그리드로 나눌 때 S = 7 , S는 convolution layer의 마지막 출력의 해상도로 결정
왜?
30 channel인 이유는 bounding box의 anchor는 2개 사용(B=2), class는 20개(C=20)
따라서 총 채널의 수는 (x,y,w,h,obj score) 5 X (B times) + (class probability) 20 = 30
-
yolo의 loss function
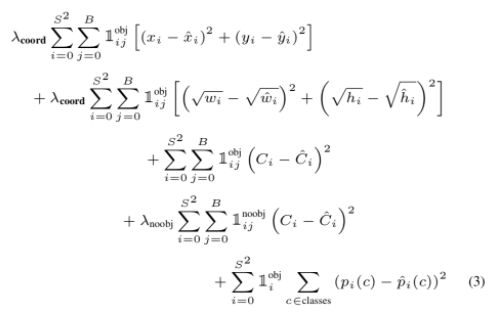
1obj ij
object 가 등장하는 i 인덱스의 j번째 바운딩 박스가 최종 프레딕션을 낸 것을 의미. 앞서 우리는 NMS를 거쳐서 살아남은 일부 바운딩 박스만 최종 프레딕션에 포함시킴. 따라서 Loss Function을 구할 때도 이 박스들을 찾아서 로스를 구하는 것1 noobj ij
물체가 없다고 판단된 i 인덱스의 j번째 바운딩 박스가 사실은 가장 ground truth와 IoU가 가장 높은 인덱스. 즉, 물체로 찾아냈어야 하는데 못찾아낸 인덱스.
loss 1.
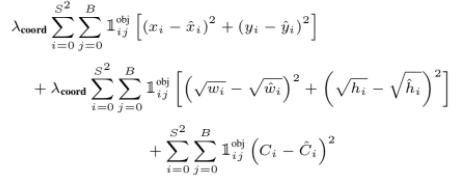
최종 프레딕션에 포함된 바운딩 박스를 찾아내어 x, y 좌표, w, h 값, C 값이 예측 값과 ground truth 값의 차를 구해 모두 더해줌.
이 때, x, y, C 값은 그냥 단순 차를 구했고 w, h는 비율 값이기 때문에 루트를 씌워 차이를 구해줌. 앞에 붙은 람다는 물체가 있을 때의 오차와 없을 때의 오차 간의 비율을 맞춰주기 위한 것인데, 논문에서는 모두 5로 설정.
loss 2.
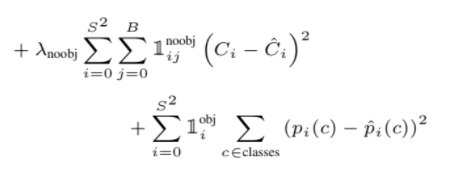
찾아낸 물체들이 얼마나 정확한지 못지 않게 중요한 것이 못 찾아낸 물체들에 대한 페널티를 매기는 것. 1 noobj ij에 대해선 찾아냈어야 하므로 C의 값의 차를 구해 로스에 더해줌.
마지막으로 모든 물체가 있다고 판단된 인덱스 i들에 대해서 모든 클래스들에 대해서 예측 값과 실제 값의 차를 구해 더해줌.
- YOLO의 성능

장점
속도 빠름
단점
그리드보다 작은 object는 탐지 불가
3.2 SSD (Single Shot Multibox Detector)
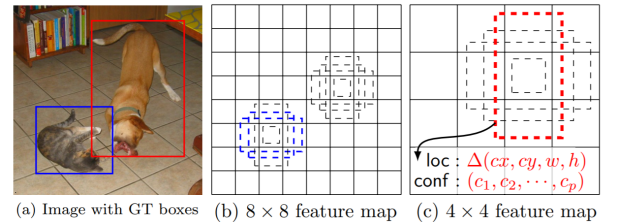
multiscale object 를 더 잘 처리하기 위해 feature map 해상도에 따라 다른 bounding box shape을 고려함 + fully convolutional network처럼 앞단의 feature map을 끌어와 detail 을 잡음

- 성능
Yolo보다 빠르고 좋음
4. Single-stage detector vs. two-stage detector
4.1 Focal loss
single stage detector는 RoI pooling 과정이 없어 class imbalance 문제가 심각함. 이미지 안에서 object가 차지하는 영역은 적고 배경이 차지하는 영역이 크다면 #negative anchor box >> # positive anchor box
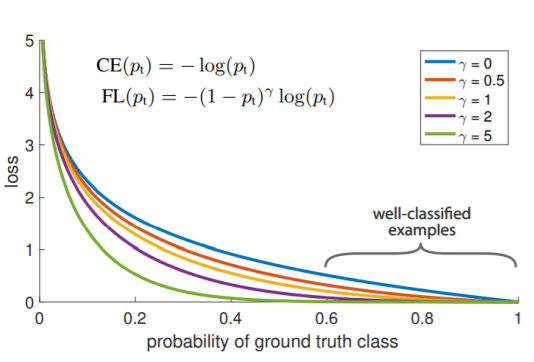
잘못 분류된 예시에 대해 큰 weight를 주는 loss
4.2 RetinaNet
FPN (Reature Pyramid Network) 제시
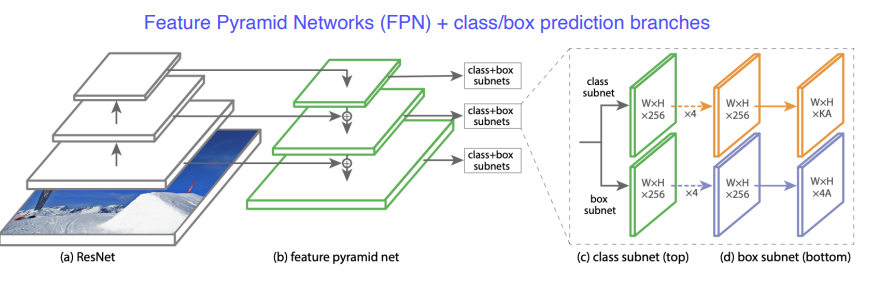
특징
- 각 layer에서 나온 feature map 더함 (not concat)
- class clf 와 box reg 를 따로 dense하게 수행
- SSD보다 더 빠르고 좋은 성능
Ref
object detection
5. Detection with Transformer
DETR
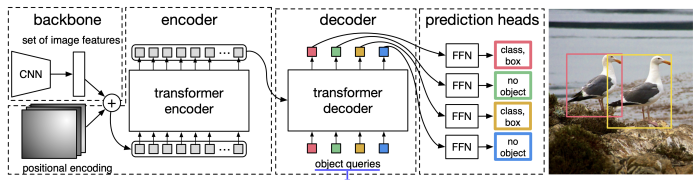
object query : 학습된 posotional encoding
hyper parameter : N object queries = max. N objects exist in a single image
과제 수행 과정 및 결과
피어 세션
Further Question
(1) Focal loss는 object detection에만 사용될 수 있을까요?
(2) CornerNet/CenterNet은 어떤 형식으로 네트워크가 구성되어 있을까요?
학습 회고
이번주는 공채기간과 겹쳐 제대로 학습 및 복습을 하지 못했다.
keep
problem
당일에 강의 다듣고 최대한 이해하기
try
우선순위 작성해서 해나가는 식으로 시간관리하기
