강의 내용 복습
(08강) Conditional Generative Model
Conditional Generative Model은 입력 condition (주어진 이미지)에 해당하는 output (변환된 이미지)를 생성하는 모델
1. Conditional generative model
1.1 Conditional generative model

vanilla GAN : 입력으로 들어오는 데이터의 확률분포를 학습함 (랜덤 샘플에서부터 generation)
conditional GAN : 조건(condition)이 주어진 상태에서 입력 X인 이미지가 나올 확률
ex) 가방 그림이 condition으로 주어진 상태에서 X인 realistic한 이미지가 나올 확률 분포를 모델링 함
GAN vs Conditional GAN

vanilla GAN : 랜덤 sample z를 G의 입력으로 넣으면 가짜 이미지를 생성하고, 이를 다시 D의 입력으로 넣어 가짜인지를 판별하는 구조
Conditional GAN : G의 입력으로 z와 함께 c(condition)을 넣어주는 구조, 나머지는 vanilla GAN과 동일
1.2 Conditional GAN and image translation
cGAN을 이용한 image translation 예시
image translatation
super resolution
1.3 Example: Super resolution
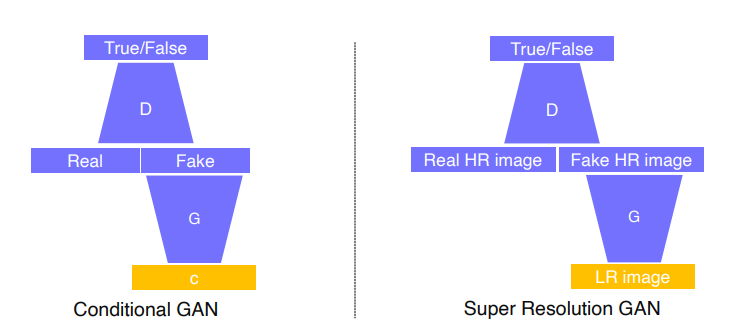
cGAN의 일종으로, input으로 저해상도의 이미지를 넣으면 고해상도의 가짜 이미지를 만드는 모델, real 데이터로 고해상도의 이미지를 주어서 판별기가 현재 주어진 생성 영상이 실제 고해상도 영상과 비슷한 통계적 특성을 갖는지를 따지는 형태
regression vs cGAN for SR
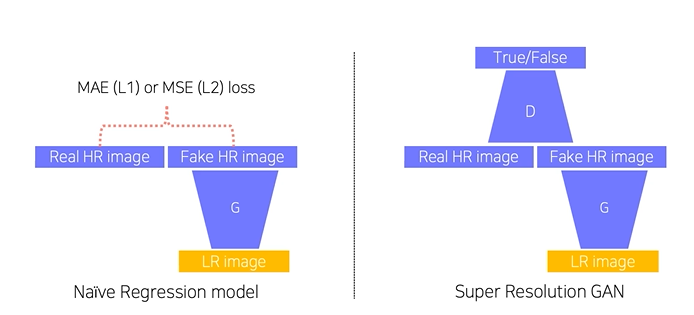
GAN을 사용하지 않고 CNN을 이용해서 SR을 할 때는 MAE(L1 norm), MSE(L2 norm)과 같은 Loss를 이용했는데, 이를 regression model이라고함. MAE, MSE Loss 를 사용하면 "averaging answering"으로 입력과 비슷하지 않은 이미지를 생성하는 문제가 생김.
averaging answering
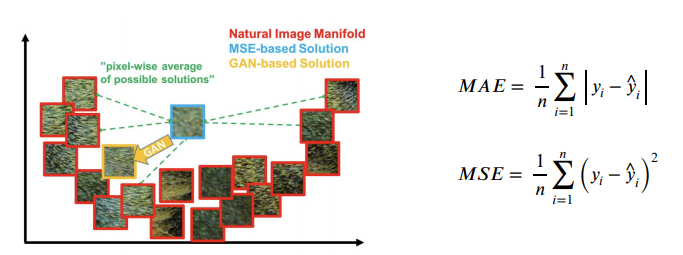
MAE : GT와 생성된 이미지 사이의 오차의 절대값
MSE : GT와 생성된 이미지 간의 오차의 제곱의 평균
regression의 결과는 해상도는 높아지지만 sharp한 영상 대심 blurry한 결과를 얻게됨. 원인은
1. pixel intensity차이를 측정하고, 평균 에러를 구하다 보니 출력 결과와 비슷한 에러를 가지는 많은 패치들이 존재하여 구분성이 떨어짐
2. Generator입장에서는 이미지 패치 공간에서 어느 하나에 가깝지 않고 전반적으로 떨어져있는 패치를 생성하는 것이 다른 패치들과의 거리를 줄여 에러를 줄이기 때문에 적절한 평균영상 을 생성하는 것이 정답이 되어버림
반면에 GAN은 adversarial loss를 사용하므로 Discriminator의 목적이 그동안 봤던 real data와 구분을 못하게 하는 것이다. real data와 가장 비슷한 이미지를 생성하면 되므로 loss도 낮고 blury한 이미지가 아닌 sharp한 이미지를 만들 수 있는것 .
더 자세한 예시
task : 주어진 이미지 Colorizing, real image는 검정, 흰색 두가지 색만을 가짐
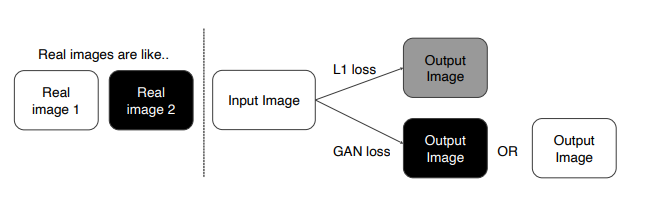
- L1 loss 사용 時
입력된 이미지의 평균 값인 회색을 출력함 - GAN loss 사용 時
검정, 흰색 이미지만 생성함. 회색은 입력 이미지 중 없기 때문에 D가 가짜라고 판별

SRResNET : MSE loss
SRGAN : GAN loss
2. Image translation GANs
한 이미지 스타일을 다른 도메인 또는 다른 스타일로 변환하는 문제
2.1 Pix2Pix
CNN 기반의 image translation
- pix2pix loss : GAN loss + L1 loss
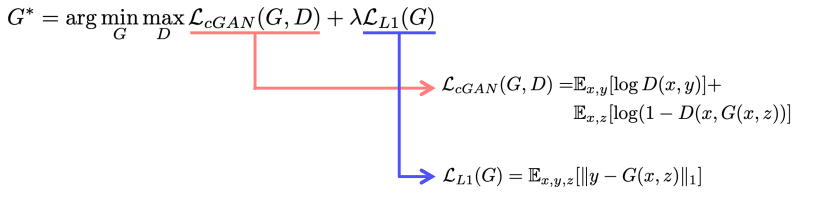
GAN loss만 사용할 경우, 입력된 두개의 pair 를 직접 비교하지 않고 D에서 x(input), y(GT)만 독립적으로 real인지 fake인지만을 판결함. 따라서 입력이 무엇이든 y와 직접 비교를 하지 않아서 y와 비슷한 결과를 만들어 낼 수 없음
이를 해결하기 위해 L1 loss 를 같이 사용해서 우리가 기대하는 결과인 y와 비슷한 영상이 나오게 됨.
GAN loss : realistic + sharp 한 결과 생성, \E_{x,z} \[\log (1-D(x, G(x,z)))\]에서 D의 입력으로 G가 생성한 fake image와 x를 함께 전달하는 것이 기존의 adversarail loss와의 차이점
L1 loss : y와 비슷한 결과 생성, 학습이 안정적으로 이루어 짛 수 있게 보조

2.2 CycleGAN
pix2pix는 x,y (pairwise data)를 함께 입력으로 전달하는 supervised learning. cycleGAN은 non-pairwise dataset으로 도메인간 변환이 가능하게 함
- cycleGAN Loss : GAN loss(in both direction) + Cycle-consistency loss
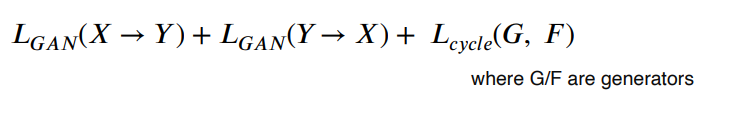
GAN Loss
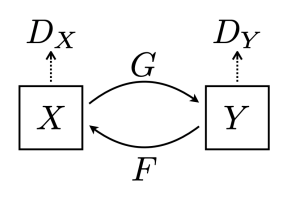
GAN loss는 X->Y, Y->X의 변환을 하는 역할
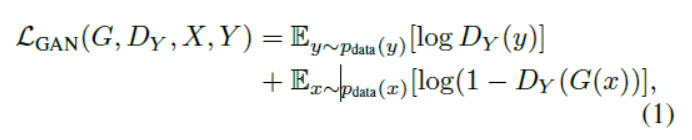

G : X->Y와 에 대한 목적함수 / F : Y->X와 도 이러한 형태의 목적함수를 가짐
GAN loss만 사용했을 때 생기는 문제 : Mode Collapse
input과 관계없이 generator가 항상 같은 output을 생성하는 문제.
D는 이미지가 진짜인지 가짜인지만 판단하기 때문에 realistic한 영상(style)만 보고 G가 잘하고 있다고 판별하여 loss는 낮아지지만 생성은 제대로 되지 않는 문제
해결 : Cycle-consistency Loss
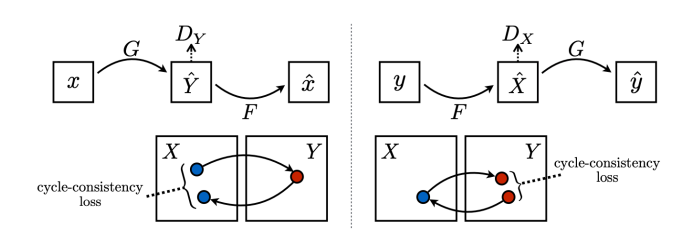
X->Y, Y->X로 변환 된 이미지가 원래의 X와 차이가 나지 않도록 하여(cycle-consistent) 내부의 content 또한 원본과 동일하게끔 유도하는 loss
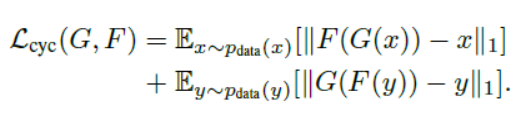
전체 loss
우리가 풀고자 하는 목표
2.3 Perceptual loss
Is there another way to get a high-quality image without GAN?
👉 Perceptual loss
GAN loss (= adversarial loss)
- G와 D를 번갈아가면서 적대적으로 학습해야 하기 때문에(alternating training) 학습하기가 어려움.
- pre-train model이 필요없음.
- pre-train model을 사용하지 않기 때문에 다양항 task에 응용할 수 있음
Perceptual loss
-
학습하기가 쉽고(simple forward & backward computation) 코드가 간단함
-
learned loss측정을 위한 pretrained model 필요
 conv layer의 앞부분 필터가 image를 perceptual space로 변환하는데, 이때 사람이 신경쓰는 부분과 신경쓰지 않는 부분을 구분할 수 있을까에서 시작
conv layer의 앞부분 필터가 image를 perceptual space로 변환하는데, 이때 사람이 신경쓰는 부분과 신경쓰지 않는 부분을 구분할 수 있을까에서 시작

Image transform Net : input 이미지가 주어졌을 때 transform 하여 만듬
Loss Net : ImageNet으로 학습된 VGG-16 모델, style, feature loss로 생성된 이미지와 terget사이 loss측정, Image Transform Net 학습시에는 fix되어 업데이트 되지 않음 -
Feature reconstruction loss
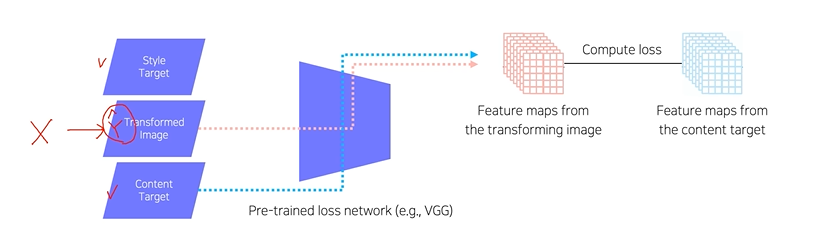
X로부터 를 생성하는 함수 f를 학습시킬때, content 를 유지하게 하는 loss, output과 target image의 L2 loss를 측정하여 back propagation -
Style reconstruction loss
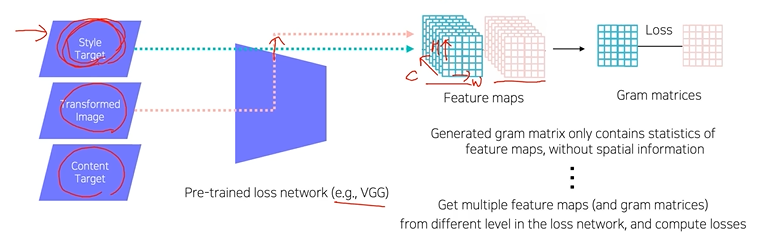
style을 유지하게 하는 loss. 변환하고자 하는 image input과 변화ㄴ목표인 target image를 VGG에 넣어 convolution feature map을 뽑고 두 feature map의 Gram metrices로 L2 loss 측정 -
Gram metrices
feauture map의 공간적 특징을 얻는 통계적 정보를 담은 metrices
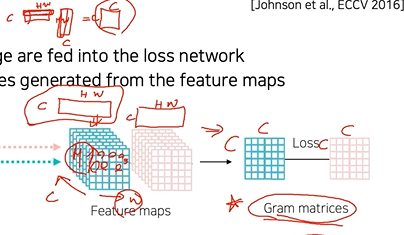
pooling을 통해 feature map을 cx(hxw) 형태오 reshape
해당 행렬을 내적하여 cxc의 행렬 생성. 각 채널에 해당하는 통계치가 내적되어 convoution feature map에서 채널간의 관계를 관찰할 수 있음
convoution 의 각 channel은 특정 feature 를 detection하는 역할을 한다. 강아지를 예로 들면 어떤 채널은 강아지의 동그란 코를 관찰, 어떤 채널은 세로 빗살무늬 , 또 다른 채널은 다로 빗살 무늬를 관찰한다.
만약 stye에서 세로 빗살무늬와 가로 빗살무늬가 동시에 관찰될 경향이 커진다면, 즉 이미지 내에 가로,세로 빗살무늬로 이루어졌다면 gram metrices에서 두 채널의 값이 내적된 원소값이 클것이다.
따라서 gram metrices는 style target의 채널간의 crrelation을 저장하고 있는 것. transformed image의 gram metrices와 target image의 gram metrices간의 차이를 loss로 걸어 gradient를 생성하고, back propagation이 되어 transform image의 gram metrices가 target image의 gram metries를 따라하게 함
3. Various GAN applications
Deepfake

-> Ethical concnerns about Deepfake
Video

Pose transfer
Video-to-Video translation
Video2Game
Further Reading
Generative Adversarial Networks : https://arxiv.org/pdf/1406.2661.pdf
StyleGAN : https://arxiv.org/pdf/1812.04948.pdf
Ref
과제 수행 과정 및 결과
Conditional GAN을 이용한 quick draw 이미지 생성
-> 데이터가 흰바탕에 아주 얇은 선으로 이루어져 있기 때문에 생성이 잘 안되는 문제 발생
피어 세션
학습 회고
