강의 내용 복습
(09-1강) Multi-modal Learning
1. Overview of multi-modal learning

multi-modal learning이란 서로 다른 type을 갖는 데이터를 함께 학습에 활용하는 기법
문제
1. 데이터의 표현방법이 모두 다름(Image : 3d, Text : word하나에 해당하는 embedding 벡터가 sequence만큼)
2. heterogeneous feature space간의 unbalance
아보카도 모양의 의자(Text) - 이미지(image) = 1:N 매칭
3. 여러 modality를 사용할 경우 학습의 한계
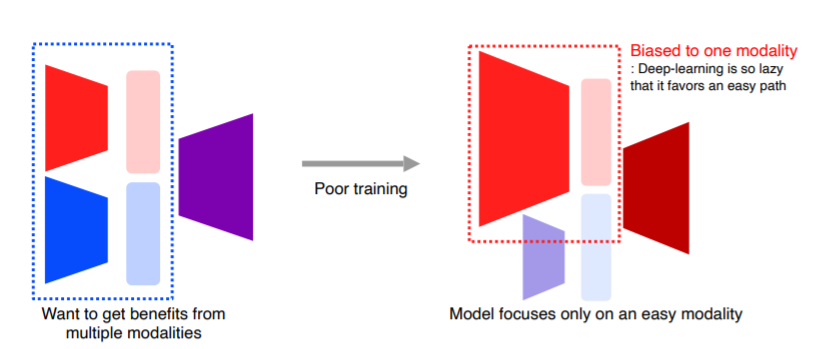 너무 많은 정보를 받기 때문에 오히려 학습이 잘 안됨(하나의 modality만 편파적으로 학습하는 등의 문제)
너무 많은 정보를 받기 때문에 오히려 학습이 잘 안됨(하나의 modality만 편파적으로 학습하는 등의 문제)
이러한 문제에도 불구하고 multi-modal learning은 중요, 종류는 아래와 같음
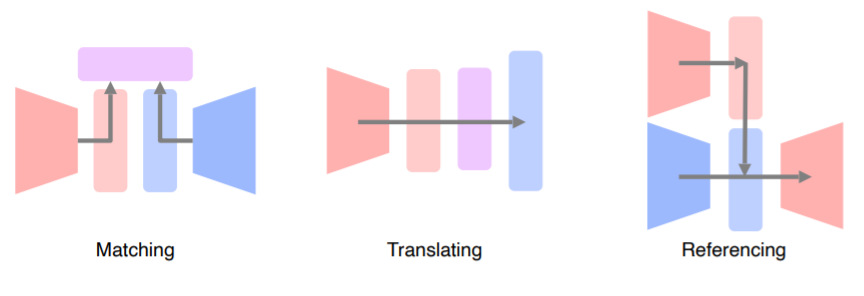
2. Multi-modal tasks (1) - Visual data & Text
2.1 test embedding
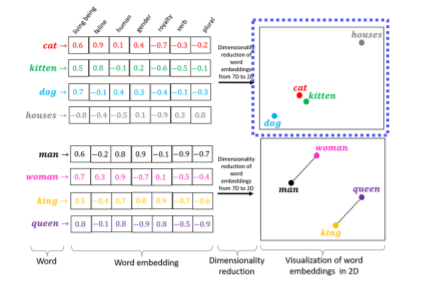
word level text embedding vector를 생성 후 각 벡터를 low dimensional projection해서 각 벡터의 거리를 측정 -> 다른 단어 관계에 일반화 가능(man~woman : king~queen)
- word2vec : Skip-gram model
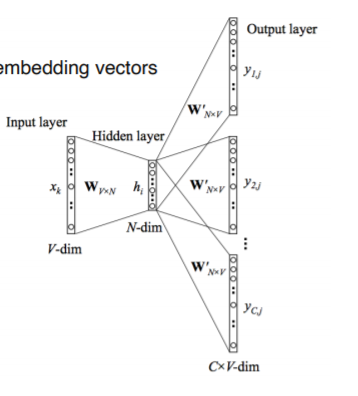
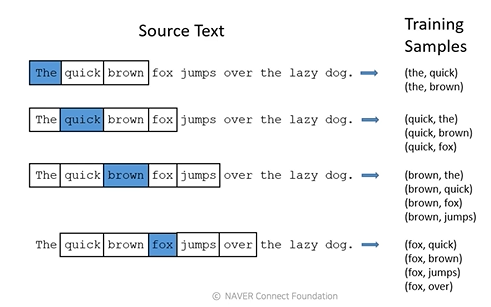 중심 단어와 주변 단어의 관계를 학습
중심 단어와 주변 단어의 관계를 학습
2.2 Joint embedding
- Image tagging

이미지 -> 태그 / 태그 -> 이미지 생성
 pretrain 된 unimodal model을 combine하여 구현
pretrain 된 unimodal model을 combine하여 구현
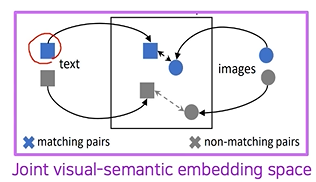 Metric Learning in visual-sementic space : 두 벡터를 같은 임베딩 공간에 매핑하여 distance를 줄이는 방향으로 학습(매칭되지 않은 데이터의 경우 distance가 커지도록 penalty를 주어 학습)
Metric Learning in visual-sementic space : 두 벡터를 같은 임베딩 공간에 매핑하여 distance를 줄이는 방향으로 학습(매칭되지 않은 데이터의 경우 distance가 커지도록 penalty를 주어 학습)
 만들어진 joint embedding space를 통해 multi-modal analgy 가능
만들어진 joint embedding space를 통해 multi-modal analgy 가능
응용
[Image & food recipr retrival]([Marin et al., TPAMI 2019])
Cross modal translation
1. Image captioning : image to sentance - CNN 4 image + RNN 4 sentence

-
show and tell

cnn과 rnn 을 합치는 방법, Encoder : CNN model pre-trained on ImageNet / Decorder : LSTM module -
show, attend, and tell - Attention
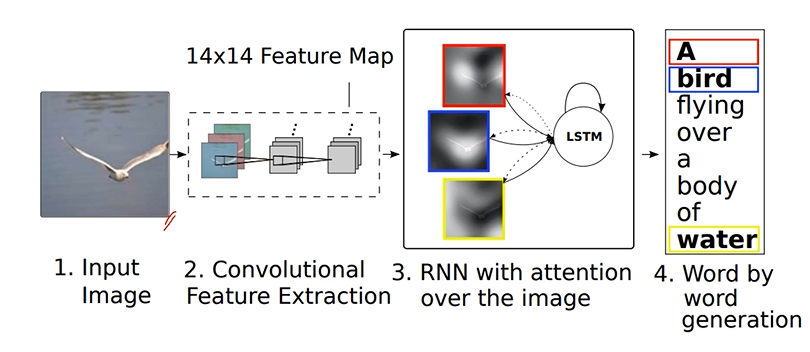
영상 전체에 tag를 생성하기 위해 집중해야하는 국지적인 부분까지 보게하는 방법. fixed dimensinal vector를 공간정보를 유지하는 feature map생성하여 RNN에 넣어줌 -
Soft Attention embedding
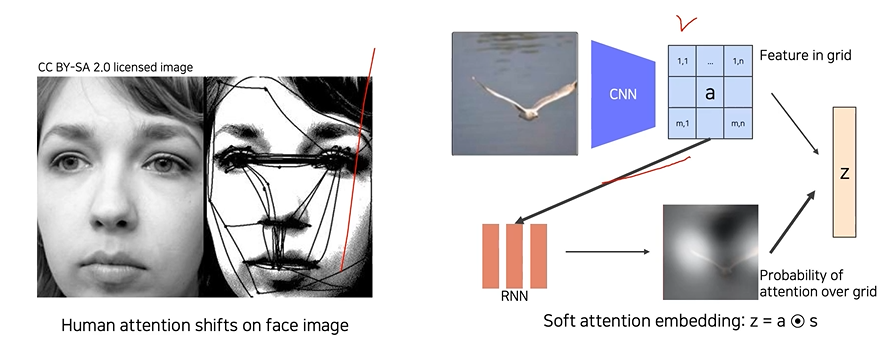
사람이 시각적으로 물체를 판단할 때 집중하는 특징이 있는 것처럼, 모델도 feature 와 attetion weight을 내적하여 z를 만들어냄
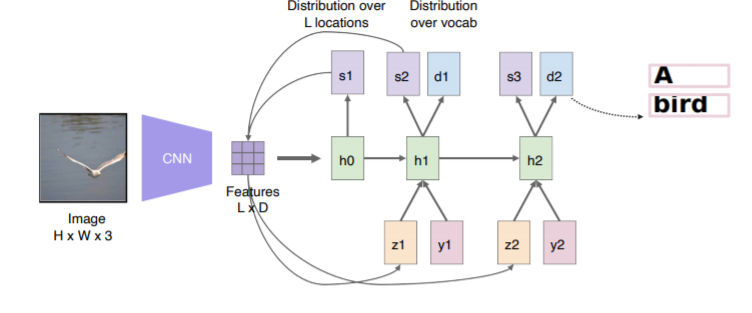
: 이미지에서 어느 부분을 집중하여 볼지를 말하는 spartial soft attention map
: feature map과 soft attention map을 내적하여 얻어낸 attention weight
: 이전에 출력했던 단어
: 디코더의 hidden state
- Text-to-image by Generative model
 텍스트-이미지처럼 1:n은 generative model 필요
텍스트-이미지처럼 1:n은 generative model 필요
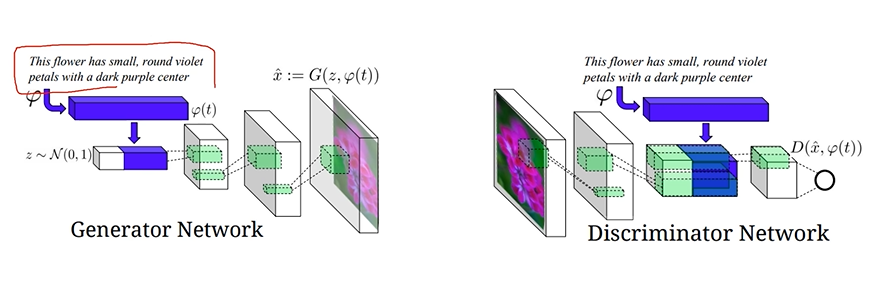
Generator Network
text 전체를 fixed dimensional vector로 만들어줌
가우시안 분포를 붙여주어 output이 항상 다르게 나오도록 함
codnitinal Generator를 거쳐 이미지 생성
Discriminator Network
생성된 이미지를 입력으로 받아 low-dimensional feature map을 뽑음
G에서 사용한 sentence condition을 함께 주어 해당 condition하에 생성된 image가 true or false를 판단하게 함
Crodd model reasoning (Referencing)
1. Visual question answering
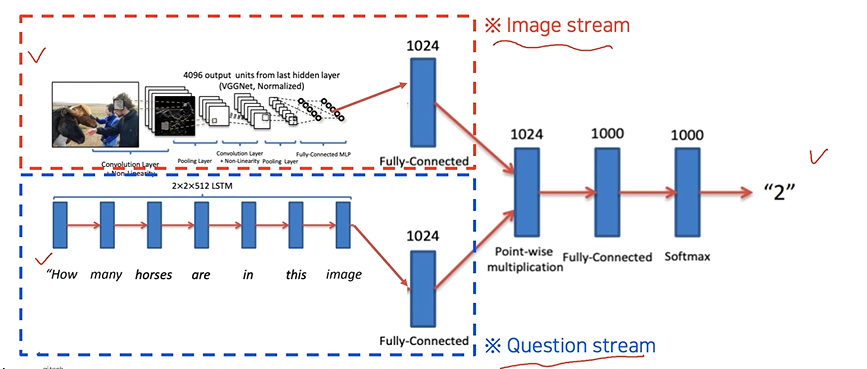
- multi streams
- joint embedding
- end-to-end training
3. Multi-modal tasks (2) - Visual data & Audio
3.1 Sound representation

시간축에 대한 wave form 형태의 1d signal, 모델 학습시에는 power spectrum 이나 Spectogram으로 만듬
- Fourier transform : Short-time Fourier transform (STFT)
짧은 윈도우 구간 내에서만 Fourier transform 적용하여 spectogram으로 만듬/ Hammming window로 윈도우 내에서도 가운데 부분에 가중치 적용
Further Question
(1) Multi-modal learning에서 feature 사이의 semantic을 유지하기 위해 어떤 학습 방법을 사용했나요?
(2) Captioning task를 풀 때, attention이 어떻게 사용될 수 있었나요?
(3) Sound source localization task를 풀 때, audio 정보는 어떻게 활용되었나요?
(09-2강) Image captioning
Image captioning은 이미지를 입력하여, 이미지를 가장 잘 설명하는 문장을 출력하는 task 실습 / 논문 : Show, Attend, and Tell

author's original implementation : https://github.com/kelvinxu/arctic-captions
Show, Attend and Tell Concepts
- Image captioning
- Encoder-Decoder architecture
- Attention
- Transfer Learning
- Beam Search

environment :Pytorch 0.4 Python 3.6
- Encoder

class Encoder(nn.Module):
"""
Encoder.
"""
def __init__(self, encoded_image_size=14):
super(Encoder, self).__init__()
self.enc_image_size = encoded_image_size
resnet = torchvision.models.resnet101(pretrained=True) # pretrained ImageNet ResNet-101
# Remove linear and pool layers (since we're not doing classification)
modules = list(resnet.children())[:-2]
self.resnet = nn.Sequential(*modules)
# Resize image to fixed size to allow input images of variable size
self.adaptive_pool = nn.AdaptiveAvgPool2d((encoded_image_size, encoded_image_size))
self.fine_tune()
def forward(self, images):
"""
Forward propagation.
:param images: images, a tensor of dimensions (batch_size, 3, image_size, image_size)
:return: encoded images
"""
out = self.resnet(images) # (batch_size, 2048, image_size/32, image_size/32)
out = self.adaptive_pool(out) # (batch_size, 2048, encoded_image_size, encoded_image_size)
out = out.permute(0, 2, 3, 1) # (batch_size, encoded_image_size, encoded_image_size, 2048)
return out
def fine_tune(self, fine_tune=True):
"""
Allow or prevent the computation of gradients for convolutional blocks 2 through 4 of the encoder.
:param fine_tune: Allow?
"""
for p in self.resnet.parameters():
p.requires_grad = False
# If fine-tuning, only fine-tune convolutional blocks 2 through 4
for c in list(self.resnet.children())[5:]:
for p in c.parameters():
p.requires_grad = fine_tune- Decoder(with attention)

class Attention(nn.Module):
"""
Attention Network.
"""
def __init__(self, encoder_dim, decoder_dim, attention_dim):
"""
:param encoder_dim: feature size of encoded images
:param decoder_dim: size of decoder's RNN
:param attention_dim: size of the attention network
"""
super(Attention, self).__init__()
self.encoder_att = nn.Linear(encoder_dim, attention_dim) # linear layer to transform encoded image
self.decoder_att = nn.Linear(decoder_dim, attention_dim) # linear layer to transform decoder's output
self.full_att = nn.Linear(attention_dim, 1) # linear layer to calculate values to be softmax-ed
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1) # softmax layer to calculate weights
def forward(self, encoder_out, decoder_hidden):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:param decoder_hidden: previous decoder output, a tensor of dimension (batch_size, decoder_dim)
:return: attention weighted encoding, weights
"""
att1 = self.encoder_att(encoder_out) # (batch_size, num_pixels, attention_dim)
att2 = self.decoder_att(decoder_hidden) # (batch_size, attention_dim)
att = self.full_att(self.relu(att1 + att2.unsqueeze(1))).squeeze(2) # (batch_size, num_pixels)
alpha = self.softmax(att) # (batch_size, num_pixels)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(dim=1) # (batch_size, encoder_dim)
return attention_weighted_encoding, alpha
class DecoderWithAttention(nn.Module):
"""
Decoder.
"""
def __init__(self, attention_dim, embed_dim, decoder_dim, vocab_size, encoder_dim=2048, dropout=0.5):
"""
:param attention_dim: size of attention network
:param embed_dim: embedding size
:param decoder_dim: size of decoder's RNN
:param vocab_size: size of vocabulary
:param encoder_dim: feature size of encoded images
:param dropout: dropout
"""
super(DecoderWithAttention, self).__init__()
self.encoder_dim = encoder_dim
self.attention_dim = attention_dim
self.embed_dim = embed_dim
self.decoder_dim = decoder_dim
self.vocab_size = vocab_size
self.dropout = dropout
self.attention = Attention(encoder_dim, decoder_dim, attention_dim) # attention network
self.embedding = nn.Embedding(vocab_size, embed_dim) # embedding layer
self.dropout = nn.Dropout(p=self.dropout)
self.decode_step = nn.LSTMCell(embed_dim + encoder_dim, decoder_dim, bias=True) # decoding LSTMCell
self.init_h = nn.Linear(encoder_dim, decoder_dim) # linear layer to find initial hidden state of LSTMCell
self.init_c = nn.Linear(encoder_dim, decoder_dim) # linear layer to find initial cell state of LSTMCell
self.f_beta = nn.Linear(decoder_dim, encoder_dim) # linear layer to create a sigmoid-activated gate
self.sigmoid = nn.Sigmoid()
self.fc = nn.Linear(decoder_dim, vocab_size) # linear layer to find scores over vocabulary
self.init_weights() # initialize some layers with the uniform distribution
def init_weights(self):
"""
Initializes some parameters with values from the uniform distribution, for easier convergence.
"""
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
self.fc.weight.data.uniform_(-0.1, 0.1)
def load_pretrained_embeddings(self, embeddings):
"""
Loads embedding layer with pre-trained embeddings.
:param embeddings: pre-trained embeddings
"""
self.embedding.weight = nn.Parameter(embeddings)
def fine_tune_embeddings(self, fine_tune=True):
"""
Allow fine-tuning of embedding layer? (Only makes sense to not-allow if using pre-trained embeddings).
:param fine_tune: Allow?
"""
for p in self.embedding.parameters():
p.requires_grad = fine_tune
def init_hidden_state(self, encoder_out):
"""
Creates the initial hidden and cell states for the decoder's LSTM based on the encoded images.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:return: hidden state, cell state
"""
mean_encoder_out = encoder_out.mean(dim=1)
h = self.init_h(mean_encoder_out) # (batch_size, decoder_dim)
c = self.init_c(mean_encoder_out)
return h, c
def forward(self, encoder_out, encoded_captions, caption_lengths):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, enc_image_size, enc_image_size, encoder_dim)
:param encoded_captions: encoded captions, a tensor of dimension (batch_size, max_caption_length)
:param caption_lengths: caption lengths, a tensor of dimension (batch_size, 1)
:return: scores for vocabulary, sorted encoded captions, decode lengths, weights, sort indices
"""
batch_size = encoder_out.size(0)
encoder_dim = encoder_out.size(-1)
vocab_size = self.vocab_size
# Flatten image
encoder_out = encoder_out.view(batch_size, -1, encoder_dim) # (batch_size, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# Sort input data by decreasing lengths; why? apparent below
caption_lengths, sort_ind = caption_lengths.squeeze(1).sort(dim=0, descending=True)
encoder_out = encoder_out[sort_ind]
encoded_captions = encoded_captions[sort_ind]
# Embedding
embeddings = self.embedding(encoded_captions) # (batch_size, max_caption_length, embed_dim)
# Initialize LSTM state
h, c = self.init_hidden_state(encoder_out) # (batch_size, decoder_dim)
# We won't decode at the <end> position, since we've finished generating as soon as we generate <end>
# So, decoding lengths are actual lengths - 1
decode_lengths = (caption_lengths - 1).tolist()
# Create tensors to hold word predicion scores and alphas
predictions = torch.zeros(batch_size, max(decode_lengths), vocab_size).to(device)
alphas = torch.zeros(batch_size, max(decode_lengths), num_pixels).to(device)
# At each time-step, decode by
# attention-weighing the encoder's output based on the decoder's previous hidden state output
# then generate a new word in the decoder with the previous word and the attention weighted encoding
for t in range(max(decode_lengths)):
batch_size_t = sum([l > t for l in decode_lengths])
attention_weighted_encoding, alpha = self.attention(encoder_out[:batch_size_t],
h[:batch_size_t])
gate = self.sigmoid(self.f_beta(h[:batch_size_t])) # gating scalar, (batch_size_t, encoder_dim)
attention_weighted_encoding = gate * attention_weighted_encoding
h, c = self.decode_step(
torch.cat([embeddings[:batch_size_t, t, :], attention_weighted_encoding], dim=1),
(h[:batch_size_t], c[:batch_size_t])) # (batch_size_t, decoder_dim)
preds = self.fc(self.dropout(h)) # (batch_size_t, vocab_size)
predictions[:batch_size_t, t, :] = preds
alphas[:batch_size_t, t, :] = alpha
return predictions, encoded_captions, decode_lengths, alphas, sort_indFurther Reading
a-PyTorch-Tutorial-to-Image-Captioning
과제 수행 과정 및 결과
피어 세션
학습 회고
