강의 내용 복습
5. 딥러닝 학습 방법 이해
신경망의 구조
-
신경망 : 선형모델 + 비선형 함수의 결합한 비선형 모델
대표적으로 regression 선형 모델에 softmax함수를 결합하여 분류문제로 바꾸는 방식 -
신경망을 수식으로 분해해보면
O = XW + B
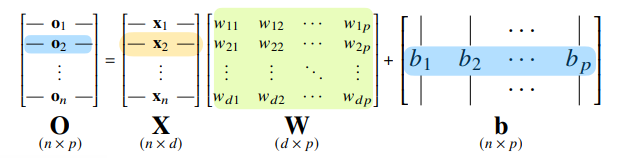
각 행벡터 는 데이터 와 가중치 행렬 W 의 행렬곱에
절편 b벡터의 합
출력 벡터의 차원은 W의 차원인 p 차원
softmax
-
softmax
모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
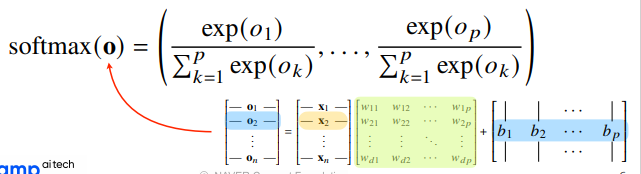
신경망의 출력벡터 O에 softmax함수를 합성하면 각 데이터가 특정 클래스에 속할 확률을 계산해줌
- 학습할 때는 사용하지만
추론을 할 때에는 원-핫 벡터로 최대값을 가진 주소만 1로 출력하면 되므로 사용하지 않음
- 학습할 때는 사용하지만
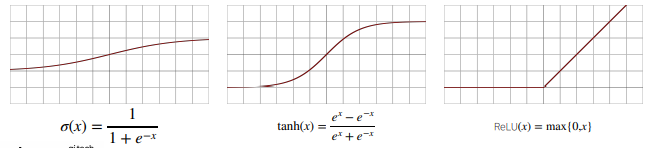
활성함수 (activation function)
-
위에 정의된 비선형 (nonlinear) 함수로, 딥러닝에서 아주 중요한 개념
-
신경망 : 선형모델 + 활성함수, 활성함수를 쓰지 않으면 딥러닝은 선형모형과 똑같음
-
sigmoid, tanh, ReLU
-
input - func(input) - sigmoid(func(input)) -> func(sigmoid(func(input))) -> output
중간에 활성함수 하나 있고 가중치를 곱하는 것을 두번 반복하면 2층 신경망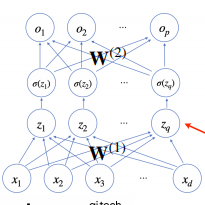
신경망이 여러츨 합성되면 다층 퍼셉트론(MLP, multi layer perceptron)
L층 MLP 파라미터는 L개의 가중치 행렬 로 이루어져 있음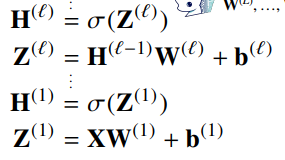
layer 1부터 L 까지 순차적인 신경망 계산은 순전파(forward propagation)이라고 부름 -
여러층을 쌓는 이유
층이 깊어질수록 목적함수를 근사하는데 필요한 뉴런(노드)의 수가 훨씬 빨리 줄어들어 효율적인 학습 가능만약 층이 얇으면 필요한 뉴런의 수가 늘어나 넓은 신경망이 되어야 함
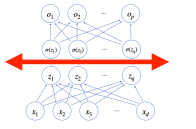
역전파 알고리즘
각 층에 사용된 파라미터 W, b를 학습하는데 사용되는 알고리즘
손실함수 L을 각 층의 가중치에 대해 미분한 값을 구함 ->
합성함수 미분법인 연쇄법칙(chain-rule)기반 자동미분(auto-differentiation)을 사용하여 맨 마지막에 쌓은 층부터 앞의 층까지 역순으로 그래디언트 벡터를 전달함.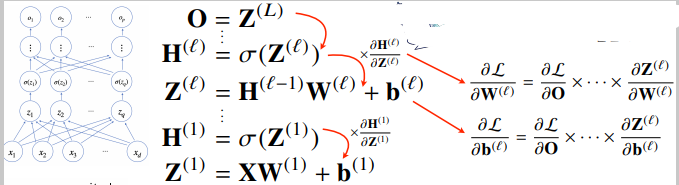
-
연쇄법칙
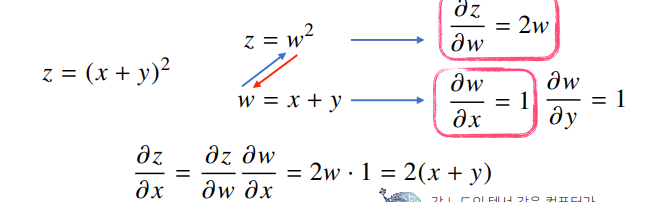
-
2층 신경망의 역전파 예시
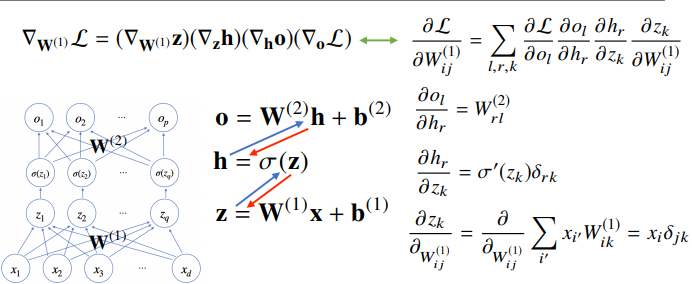
//참고
는 크로네커 델타라고 하며, r == k면 1, 다르면 0을 내놓는 함수
이므로 인데 뒤의 dl r=k이면 1, r!=k 이면 0 이기에 크로네커 델타로 표현한 것.
i = j = k로 대입하여 정리하면 됨
6. 확률론 맛보기
딥러닝에서 확률론이 필요한 이유
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 둠
- 기계학습에서 손실함수 (loss function)의 작동원리는 데이터 공간을 통계적으로 해석해서 유도함
- 회귀분석에서 손실함수로 사용되는 L2 norm은 예측오차의 분산을 가장 최소화하는 방향으로 학습
- 분류문제에서 사용되는 교차엔트로피(cross Entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습
- 분산 및 불확실성을 최소화하기 위해 측정방법을 알아야 함
확률분포
- 확률분포란?
데이터가 존재하는 데이터 공간(XxY)에서 데이터를 추출하는 분포 D
주어진 데이터만 가지고 확률분로 D를 아는 것은 불가능하기 때문에 기계학습으로 D를 추론함
확률변수는 확률분포 D에 따라 이산형(discrete)과 연속형(continuous)확률변수로 구분함
이때, 확률변수의 유형을 구분짓는 것은 데이터 공간이 아닌 확률 분포 D
즉, 실수공간에 정의된 데이터가 무조건 연속형 확률변수가 아니다.
- 이산확률변수와 확률질량함수
확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링 -> 확률질량함수
- 연속확률변수와 확률밀도함수
데이터 공간에 정의된 확률변수의 밀도 (density)위에서 적분을 통해 모델링 // 이때 확률민도함수의 값을 그대로 확률로 해석하면 안됨
확률분포를 이용한 모델링
-
데이터는 확률변수로 라고 표기
-
결합분포 P(x,y)는 D를 모델링함
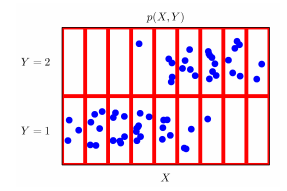
칸을 나누어 각 칸에 있는 데이터의 수로 모델링하면 결합분포를 이산확률분포처럼 만들 수 있음. 이처럼 결합분포 P의 확률분포는 어떻게 모델링하냐에 따라 정해짐
-
입력 x에 대한 주변확률분포 P(x) (y에 대한 정보 주지 않음)
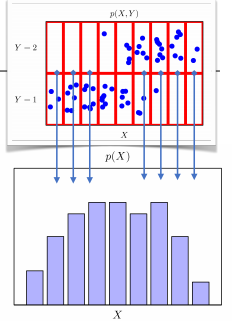
y값에 상관없이 각 칸의 X의 빈도 계산 => marginal distribution
-
조건부확률분포 P(x|y)
데이터 공간에서 입력 x와 출력 y 사이의 관계를 모델링
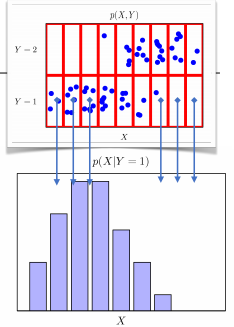
특정 클래스가 주어진 조건에서 데이터의 확률분포 보여줌
조건부 확률과 기계학습
-
사용
-
조건부확률 P(y|x) : 입력변수 x에 대해 정답이 y일 확률을 의미
-
로지스틱 회귀에서 사용한 선형모델과 소프트맥수 함수의 결합을 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용됨
-
분류문제에서 은 데이터 x로부터 추출된 특징패턴 과 가중치행렬 W를 통해 조건부 확률 P(y|x)계산
-
회귀문제의 경우 조건부 기댓값 를 추정
-
딥러닝은 다층신경망을 사용하여 데이터로부터 특징패던 을 추출
-
-
회귀문제에서 추정에 기댓값을 사용하는 이유
-
먼저 기댓값(expextation)은 데이터를 대표하는 통계량으로, 확률분포가 주어졌을 때 데이터 분석에 사용 가능한 여러 종류의 통계적 범함수 (statistical functional)를 계산하는데에 쓰임
-
기댓값을 이용해 분산, 첨도, 공분산 등 여러 통계량 계산 가능
-
조건부 기댓값 사용 이유는 조건부 기댓값 가 예측의 오차의 분산을 최소화하는 estimator이기 때문에, 또한 해당 estimator를 사용하여 얻어진 오차는 해당 조건부 기댓값에 대응되는 조건부 분산이 되기 때문.
<증명>
비교적 간단한 예로, 연속적인 랜덤 변수 Y 에 관심이 있어서 그 값을 Y 에 대한 확률 밀도 함수만으로 추정한다고 합니다. 이 때 우리는
를 최소화하는 를 선택하게 됩니다.
위 수식을 에 대해 미분하면,
이 되고, 이는
가 됩니다.따라서,
즉, 가 됩니다.
또한 (1) 식을 에 대해 두 번 미분하면 양수가 나오기 때문에 는 (1) 식의 minimizer 입니다. (1) 식에 minimizer 를 대입하여 다시 표현하면,
이는 YY 의 분산입니다.비슷한 방식으로 랜덤 변수 XX 를 추가하고, conditional density 를 소개하여 조건부 기댓값 이 MSE 를 최소화한다는 것을 보일 수 있습니다.
(1) 수식에 대해 유도한 것과 마찬가지로, 다음의 MSE minimizer를 얻게 됩니다.따라서,
을 얻게 됩니다.이는 YY 의 X=xX=x 에 대한 조건부 분산입니다.
원래의 질문으로 돌아가서, "조건부기댓값(E[y|x])을 사용하는 이유가 예측의 오차의 분산을 최소화하기 때문" 이라는 언급을 더 풀어서 설명하면 "조건부기댓값(E[y|x])을 사용하는 이유는 해당 조건부 기댓값이 예측의 오차를 최소화하는 minimizer 이기 때문이고, 해당 조건부 기댓값이 사용되어 얻어진 오차는 조건부 분산" 이라고 볼 수 있습니다.
-
-
몬테카를로 샘플링
기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분인데, 이 때 데이터를 이용하여 기댓값을 계산하려면 몬테카를로 (Monte Carlo) 샘플링 방법을 사용해야 함 (이산형 / 연속형 상관없이 성립함)독립추출만 보장되면 대수의 법칙에 의해 수렴성을 보장, 샘플링한 데이터의 산술평균이 기댓값에 근사함
- 함수 의 [-1,1] 상에서 적분값을 구하는 방법
직접 구하는것은 불가능, 몬테카를로 사용하여[-1,1] 에서의 적분값 = 넓이를 구한 뒤 구간의 길이인 2로 나누면 기댓값을 계산하는 것과 같으므로 몬테카를로 방법 사용 가능
- 함수 의 [-1,1] 상에서 적분값을 구하는 방법
7. 통계학 맛보기
모수?
모수란 모집단의 특성을 나타내는 값(평균, 분산 등)
통계적 모델링은 적절한 가정 위에서 확률분포를 추정(infereance)하는 것이 목표지만 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아내는 것은 불가능 하므로 근사적으로 확률분포를 추정함
확률분포 가정

기계적으로 확률분포를 가정하지말고 데이터 생성원리 고려가 선행되어야 하먀, 각 분포마다 모수를 추정한 후 반드시 검정을 해야 함
데이터로 모수 추정

- 중심극한 정리 (Central Limit Theorm)은 모집단의 분포가 정규분포를 따르지 않아도, 표본 집단의 크기인 N이 커지면 표집분포(통계량의 확률분포)는 정규분포 를 따름
최대가능도 추정법 (Maximim likelihood estimation, MLE)
이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나
가능도 함수 L은 데이터 x가 주어진 상황에서 모수 에 따라 값이 바뀌는 함수
- 로그가능도
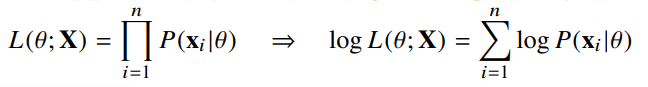
데이터가 독립적으로 추출되었을 경우는 로그가능도 최적화
로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀수 있기 때문에 데이터가 아주 커도 연산이 가능함 ()
대게 손실함수는 경사하강법을 사용하므로 음의 로그가능도 (negative log-likelihood) 최적화
-
최대 가능도 추정법 예제1 : 정규분포
정규분포를 따르는 확률변수 X로부터 독립적인 표본 을 얻었을 때 최대가능도 추정법을 이용하여 모수를 추정하면?
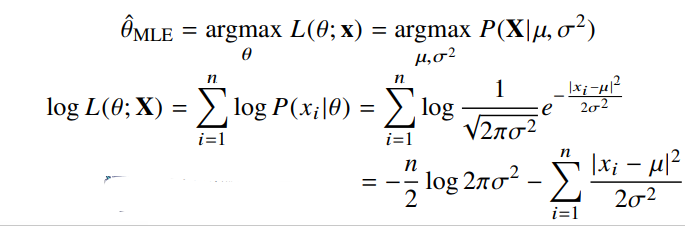
식을 전개하면 마지막에 만 있는 항과 둘다 있는 항 두개가 남음.
가능도 함수 L을 두 모수에 대해 편미분하여 두 미분이 모두 0이 되는 를 찾으면 가능도를 최대화하게 됨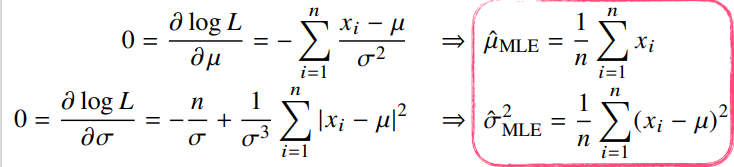
-
최대 가능도 추정법 예제2 : 카테고리 분포
카테고리 분포 Multinoulli(x; p1, …, pd) 를 따르는 확률변수 X로부터 독립적인 표본 을 얻었을 때 최대가능도 추정법을 이용하여 모수를 추정하면?
//제약 : 카테고리 분포의 모수는 을 만족해야함
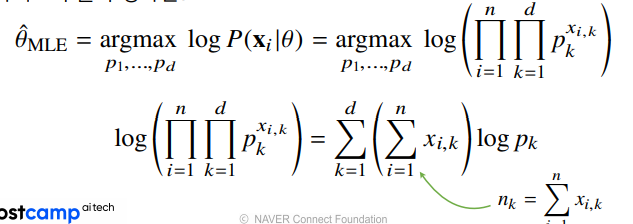
사진에서 초록 화살표 는 0또는 1이기 때문에 주어진 데이터들에 대해 k=1인 데이터를 count하는 와 같음
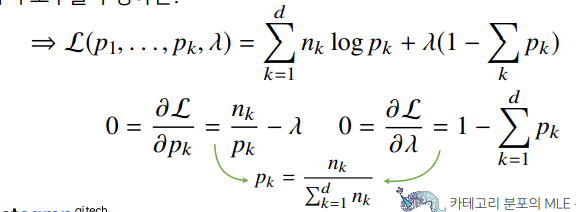
제약을 만족하면서 식의 로그가능도가 최대가 되는 모수를 구하기 위해 라그랑주 승수법 사용
1) 각 모수 에 대해 미분, 2) 에 대해 미분하면 결국 카테고리 분포의 MLE는 경우의 수를 세어서 비율을 나타내는 것
-
딥러닝에서 최대 가능도 추정

-
확률분포의 거리
기계학습에서 손실함수는 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도함
데이터 공간에 두 개의 확률분포 P, Q가 있을 경우 두 확률분포 사이의 거리(distance)를 계산할 때 사용하는 함수 중 쿨백-라이블러 발산(KL)

과제 수행 과정 및 결과
선택과제 1
- 선택과제 1 - gradient descent 시 error를 L2 norm으로 정의하고 미분했을 때 식의 깔끔함을 위해 제곱해도 된다.
error = np.sum((train_y - _y)**2) / n_data #train_y : 정답 / _y : 예측값
# gradient
gradient_w = -2 * np.sum(train_x.T @ (train_y - _y)) / n_data
gradient_b = -2 * np.sum((train_y - _y)) / n_data피어 세션
-
back propagation
각 레이어에서 체인룰로 편미분하면서 앞으로 오는 과정 -
선택과제 1 - gradient descent 시 error를 L2 norm으로 정의하고 미분했을 때 식의 깔끔함을 위해 제곱해도 된다.
error = np.sum((train_y - _y)**2) / n_data #train_y : 정답 / _y : 예측값
# gradient
gradient_w = -2 * np.sum(train_x.T @ (train_y - _y)) / n_data
gradient_b = -2 * np.sum((train_y - _y)) / n_data학습 회고
오늘 강의를 들으며 통계학을 비롯한 수학적 기초가 많이 부족함을 느꼈다.
unist 임성빈 교수님의 마스터 클래스에서 AI ENgineer가 수학을 공부하는 방법에 대해 알려주셔서 공부의 방향을 잡을 수 있었다.
마지막 MLE와 KL은 이해를 완벽하게 하지는 못해서 어디에 사용되는지 예시를 더 찾아봐야겠다.
