강의 내용 복습
(01강) (1강) 데이터 제작의 중요성 I
모델의 성능 구조, 데이터, 최적화 3가지가 결정
Software 1.0 VS Software 2.0
- Software 1.0 개발과정
딥러닝이 아닌 sw.
- 문제 정의
- 큰 문제를 작은 문제들의 집합으로 분해
- 개별 문제 별로 알고리즘 설계
- 솔루션들을 합쳐 하나의 시스템으로
- Visual Recognition Task
이미지 인식 기술도 처음에는 software 1.0 철학으로 개발됨. 신체부위에 따라 경우의 수를 나누고, 사람에 해당하는 cog 연산을 만들어 적용. 만약 다른 객체를 검출하고 싶으면 해당 객체에 맞는 연산을 다시 만들어야 함.
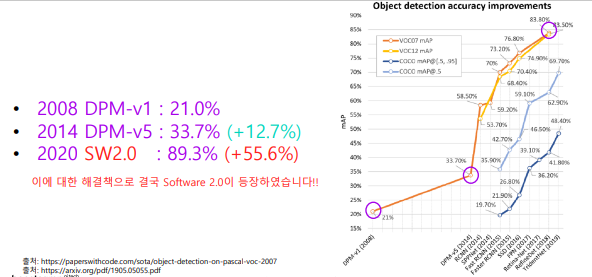 하지만 객체 검출에서 대응하기 어려운 케이스가 많았음.
하지만 객체 검출에서 대응하기 어려운 케이스가 많았음.
sw 2.0 방법으로는 많은 성능향상과 논문이 나옴
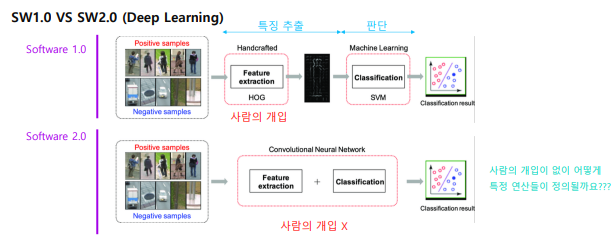
sw 2.0 은 사람의 개입이 없이 객체의 특징을 추출하고 연산을 정함.
- sw 2.0
- Software 2.0은 뉴럴넷의 구조에 의해 검색 영역이 정해집니다.
- 그리고 최적화를 통해 사람이 정한 목적에 제일 부합하는 연산의 집합을 찾습니다
- 이때 경로와 목적지는 데이터와 최적화 방법에 의해서 정해집니다
sw 2.0
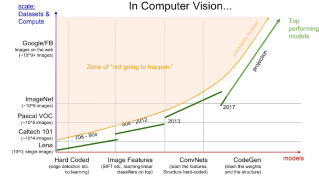
구조를 설계하는데에는 사람의 개입이 필요하지만, 점점 개입을 줄이고 최적화에 더 신경 씁니다
Transformer 시대.
이러한 방법론은 음성인식, 기계번역, 객체검출다양한 분야에서 성과를 내고 있습니다
(2강) 데이터 제작의 중요성 II
1. Lifecycle of an AI Project
1.1 AI Research VS AI Production
학교, 대회와 달리 서비스 개발시에는 데이터셋과 테스트 방법이 준비되어 있지 않고 요구사항만 존재함.
그래서 서비스에 적용되는 AI 개발 업무의 상당 부분이 데이터셋을 준비하는 작업
1.2 Production Process of AI Model
서비스향 AI 모델 개발 과정은 크게 4가지 단계로 구성되어 있음.
1. 모델 요구사항 확정 : 처리시간, 목표정확도, 목표 qps, 서빙 방식, 장비 사양
2. 데이터셋 준비 : 종류, 수량, 정답라벨
3. 모델 학습 및 디버깅 : 데이터 관련 피드백, 요구사항 달성
4. 설치 및 유지보수 : 성능 모니터링, 이슈해결
목표: 요구사항을 충족시키는 모델을 지속적으로 확보하는 것이고 두 가지 방법이 있음
- Data Centric : 데이터만 수정하여 모델 성능 끌어올리기
- Model Centric : 데이터는 고정시키고 모델 성능 끌어올리기
모델 성능 달성에 있어서 서비스 출시 전에는 데이터와 모델에 대한 비중은 5:5지만, 서비스 출시 이후에는 성능개선에 대한 요구가 처리속도보다는 보통 정확도에 대한 것이기 때문에 데이터에 집중하는 비중이 커진다.
이유는 처리 속도같은 것은 이미 모델구조에서 정해지기 때문에 요구사항을 맞추었을 확률이 크며, 정확도를 개선하기 위해 모델구조를 변경하는 것은 처리 속도, qps, 메모리 크기 등에 대한 요구사항 검증을 다시해야하므로 비용이 크다.
2. Data! Data! Data!
2.1 Data-related tasks
데이터와 관련된 업무가 왜이렇게 많을까
- 어떻게 하면 좋을지에 대해 알려져 있지 않음
- 학계에서는 좋은 데이터를 많이 모으기 힘들고, 라벨링 비용이 크고 작업기간이 오래 걸려 데이터를 다루기 힘듬 -> 데이터보다는 모델에 대한 연구와 논문만 많이 나오는 이유
- 데이터 라벨링 작업은 라벨링 노이즈를 상쇄할 정도로 깨끗한 라벨링 데이터가 많아야해서 생각보다 어려움.
- 데이터 불균형을 바로잡기가 어려움.
-> 이 모든 것을 잘 할 수 있는 데이터 annotation tools을 만들어야 한다.
2.2 Data Engine / Flywheel
Data Engine을 위한 IDE
중 sw 2.0 IDE 는 아직 없다. 기능별 ide 제외
데이터 관점에서 필요한 기능들
1. 데이터셋 시각화 : 데이터/레이블 분포 , 레이블 시각화
2. 데이터 라벨링 : 라벨링 UI, 태스크 특화기능, 라벨링 일관성 확인, 자동 라벨링 등
3. 데이터셋 정제 : 반복데이터 제거, 라벨링 오류 수정 등
4. 데이터셋 선별 : 모델 성능 향상을 위해 어떤 데이터를 라벨링 해야하나?
(3강) OCR Technology & Services
1. OCR Technology
1.1 OCR
OCR - Optical Character Recognition
STR - Scene Text Recognition
OCR : 글자 영역 찾기 + 글자 영역별로 글자 인식하기
Offline Handwriting VS Online Handwriting
Offline : 이미지를 입력으로 하여 글자값 출력
Online : 좌표 시퀀스를 입력으로 하여 글자값 출력
1.1 Text Detector
글자 검출기 : 이미지 입력에 글자 영역 위치가 출력인 모델
- 객체 검출 (Object Detection) vs 글자 검출 (Text Detection)
단일 객체 검출 : 입력 이미지가 ‘미리 약속된’ 클래스들 중 어디에 속하고, 해당 객체의 위치는 어디인가?
다수 객체 검출 : 입력 이미지 내에 ‘미리 약속된’ 클래스들에 해당하는 각 객체들의 위치는 어디인가?
글자 영역 다수 객체 검출
글자 영역이냐 아니냐 이기에 단일 클래스 문제 :
클래스 정보가 필요 없고 글자 영역에 해당하는 객체의 위치만 추정

1.2 Text Recognizer
글자 인식기 : 하나의 글자 영역 이미지 입력에 해당 영역 글자열이 출력인 모델

글자 인식기는 Computer Vision과 Natural Language Processing의 교집합 영역
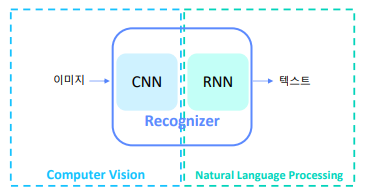
유사한 테스크 : image captioning (이미지를 설명하는 문장 생성)
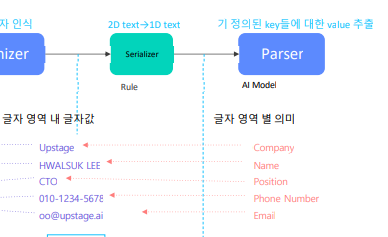
1.3 Serializer
정렬기 : OCR결과값을 자연어 처리하기 편하게 일렬로 정렬하는 모듈

정렬기 결과값을 입력으로 받는 자연어 처리 모듈을 뒤에 붙여서 사용 가능
1.4 Text Parser
자연어 처리 모듈 중 가장 많이 사용되는 것은 기 정의된 key들에 대한 value 추출
BIO 태깅을 활용한 개체명 인식 : 문장에서 기 정의된 개체에 대한 값 추출

Process of Parser : BIO-tagging | BIO tagging 달아주고 학습시키기
2. OCR Services
2.1 Text Extractor
Copy & Paste
2.2 Text Extractor + Natural Language Processing
Search(텍스트로 검색하면 해당 텍스트가 있는 이미지 반환)
Matching
금칙어 처리(광고성/혐오성 이미지 제거)
번역
2.3 Key-value Extractor
신용카드
신분증
수기입력대체 : 사업자 등록증, 영수증 등
과제 수행 과정 및 결과
피어 세션
최종 프로젝트 아이디어 회의
학습 회고
level 3 대회가 시작되었다.
데이터 제작은 프로젝트를 진행하며 해볼 기회가 없었는데(있어도 시간상 안했다..) 이번기회에 해볼 수 있어서 좋다.
