강의 내용 복습
(4강) Text Detection 소개 1
1. Basics
1.1 일반 객체 영역 검출 vs 글자 영역 검출
일반 객체 검출: 클래스와 위치를 예측하는 문제
글자 검출: “Text”라는 단일 클래스 -> 위치만 예측하는 문제
글자 검출 객체의 특징

• 매우 높은 밀도
• 극단적 종횡비
• 특이 모양
• 구겨진 영역
• 휘어진 영역
• 세로 쓰기 영역
• 모호한 객체 영역
• 크기 편차
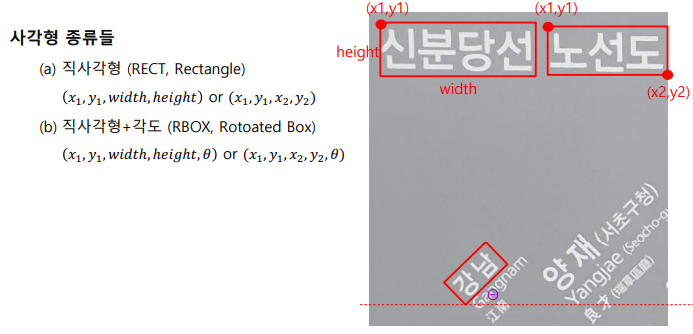
1.2 글자 영역 표현법
사각형 종류들

2. Taxonomy
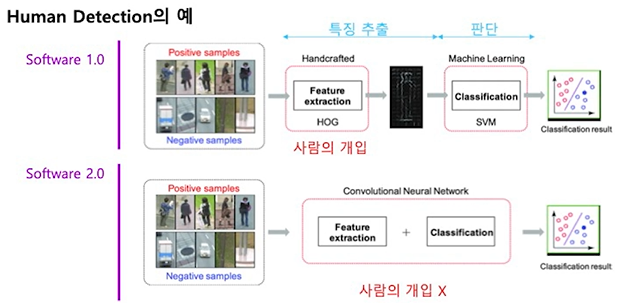
2.0 sw 1.0 vs sw 2.0
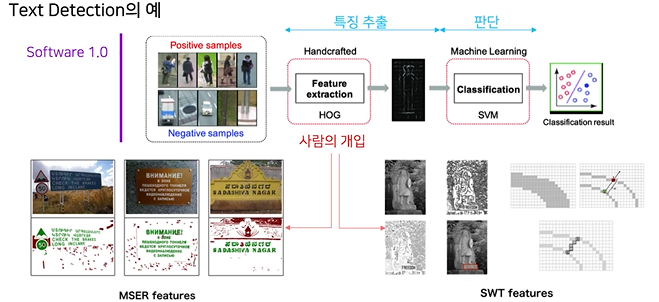
Text detection
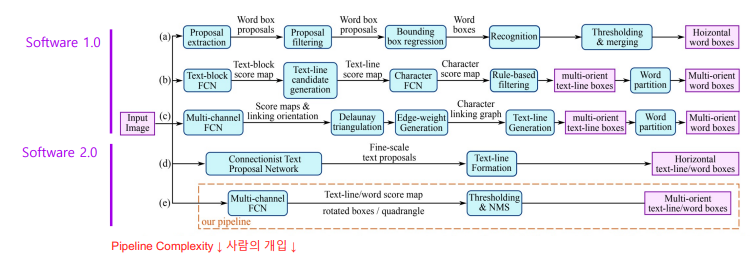 sw1.0은 사람의 개입이 많아 파이프라인이 복잡함.
sw1.0은 사람의 개입이 많아 파이프라인이 복잡함. 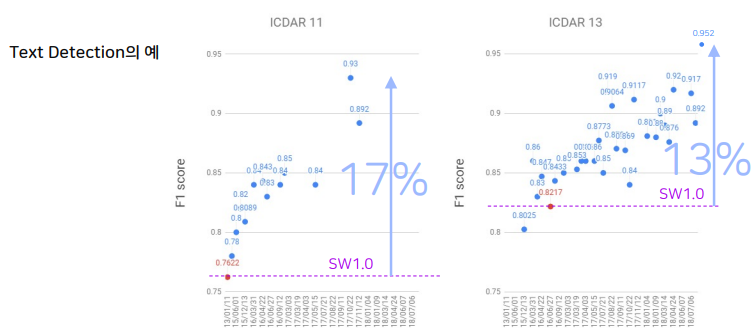 성능도 sw2.0이 더좋음
성능도 sw2.0이 더좋음
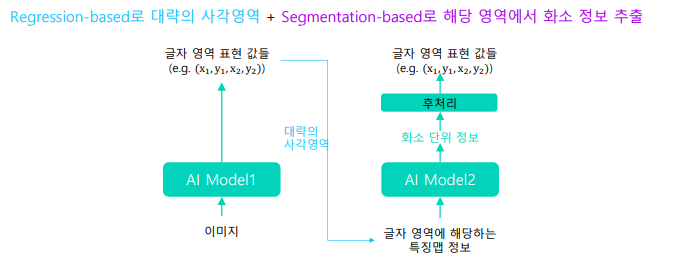
2.1 Regression-based vs Segmentation-based
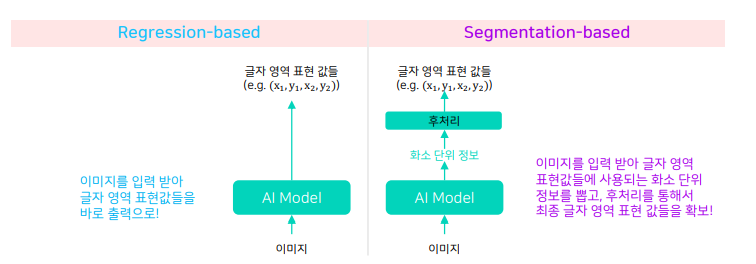
-
regression
ssd 기반 각 앵커박스의 위치와 크기를 GT와 비교하여 박스 위치와 크기를 회귀로 찾음
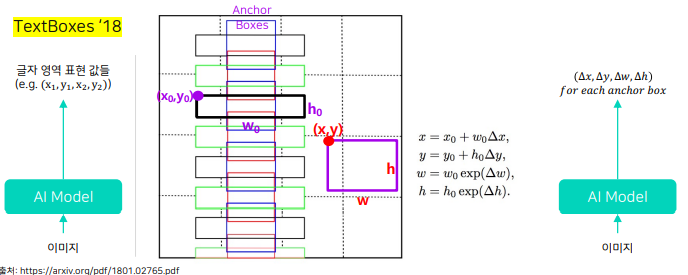
문제점
- Arbitrary-shaped text -> 불필요한 영역을 포함 (Bounding box 표현 방식의 한계)
- Extreme aspect ratio -> 앵커박스보다 훨씬 큰 종횡비를 가지는 경우 Bounding box 정확도 하락 (Receptive field의 한계)
-
segmentation
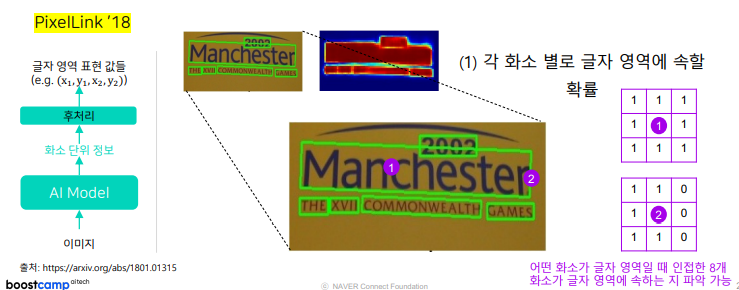
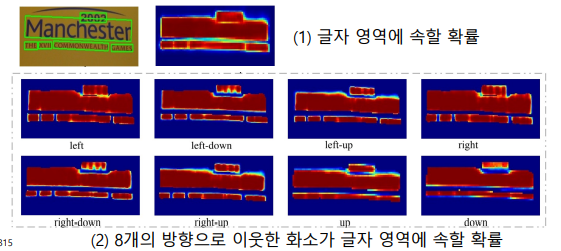 (3) 후처리
(3) 후처리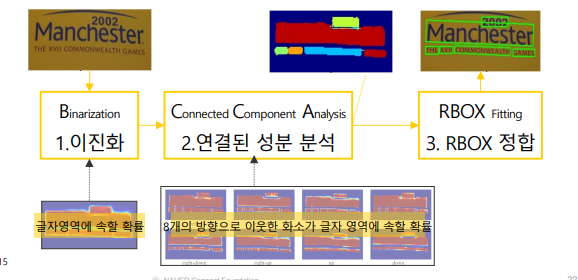
문제점
- 고성능을 위해 복잡하고 시간이 오래 걸리는 post-processing이 필요할 수 있음.
- 기본적으로 글자 영역에 속할 확률값 사용- 인접해있으면 별도 영역이 하나의 영역으로 검출될 수 있음: 서로 간섭이 있거나 인접한 개체 간의 구분이 어려움
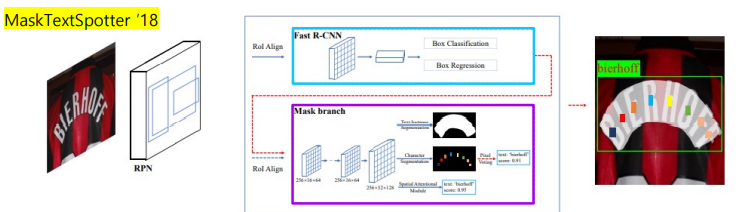
2.2 Character-based vs Word-based

Character-Based Methods
Character 단위로 검출하고 이를 조합해서 word instance를 예측
Character-level GT 필요
Word-Based Methods
Word 단위로 예측
대부분의 모델이 해당
- Character-Based Methods
Weakly-Supervised Learning : 단어단위 라벨링을 가지고 글자단위 라벨링을 추정하는 방법론 제안

3. Baseline Model - EAST
EAST : An Efficient and Accurate Scene Text Detector. CVPR, 2017
sw2.0 방식으로 개발되어 제대로 성능을 냄
Simple 2-Staged System
Fast inference & end-to-end train
-
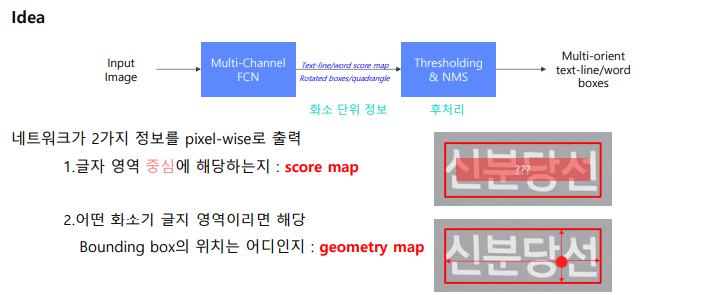
idea
-
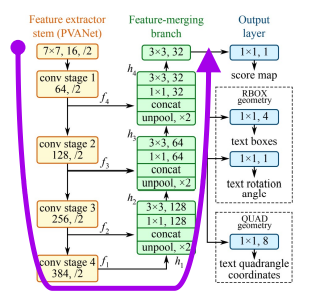
Architecture
fully connected network
크게 보면 UNet 구조: Segmentation의 base가 되는 network 구조
pixel-wise prediction세가지 부분으로 구성
- Feature extractor stem (backbone):
PVANet, VGGNet (Code), ResNet50 (이미지를 입력받아 가장 작은 크기의 피처맵까지 추출) - Feature merging branch:
Unpool로 크기 맞추고 concat
1 x 1, 3 x 3 convolution으로 channel 수 조절 (피처맵을 키워가며 여러 레벨의 피처맵을 합침) - Output: H/4 x W/4 x C maps (최종 출력)
- Feature extractor stem (backbone):
-
Output
-
Score map : 글자영역 중심에 해당하는지 = 1
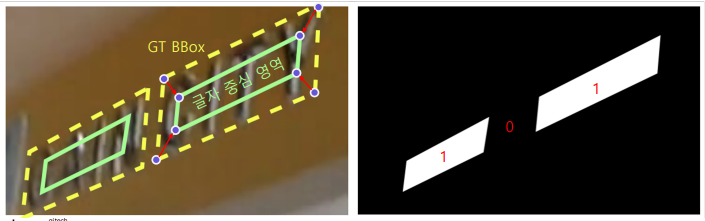 H/4 x W/4 x 1 binary map - 글자 영역의 중심이면 1, 배경이면 0
H/4 x W/4 x 1 binary map - 글자 영역의 중심이면 1, 배경이면 0
GT bounding box를 줄여서 생성 (글자 높이의 30%만큼 end points를 안쪽으로 이동)
추론 할 경우 0,1의 실수값으로 나오게 하며 글자 중심영역에 위치할 확률 값으로 해석 -
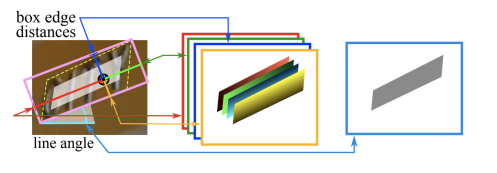
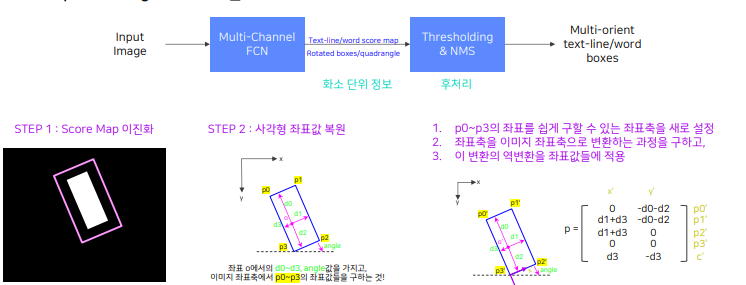
Geometry Map : 어떤 화소가 글자 영역이라면 해당 Bounding box의 위치는 어디인지

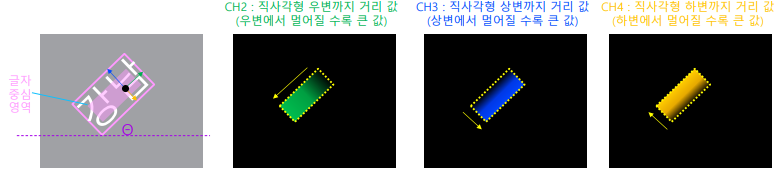
RBOX (rotated box, 직사각형+각도) 형식:
회전 각도 예측 -> 1 channel
Bounding box의 4개 경계선까지의 거리를 예측 -> 4 channels
 즉 중심위치에서 하나는 각도값, 나머지 넷은 변까지의 거리값으로 채운다.
즉 중심위치에서 하나는 각도값, 나머지 넷은 변까지의 거리값으로 채운다. QUAD(quadrilateral, 좌표 4개) 형식:
Bounding box의 4개 점까지의 offset을 예측 -> 8 channles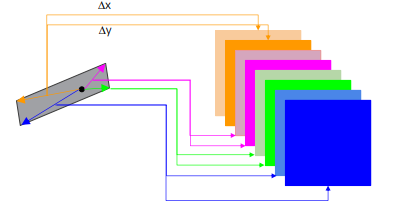
-
-
post processing
- RBOX 기준
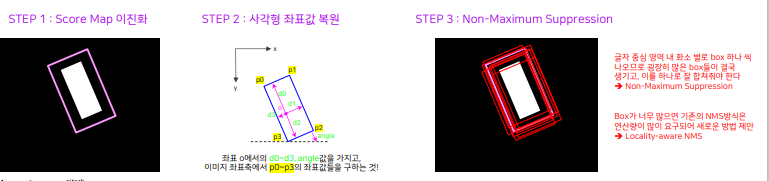
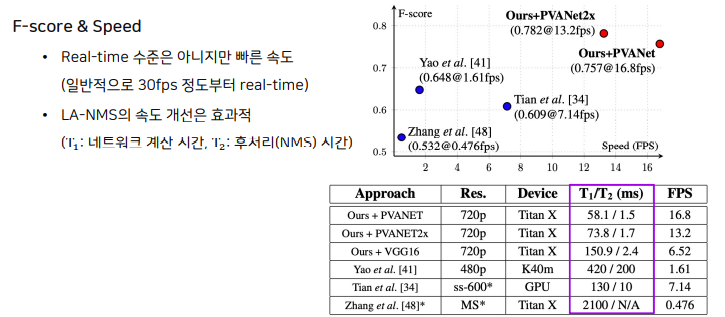
기존의 NMS 사용하면 연산량이 너무 커 새로운 방식 제안 - Locality-Aware NMS

인접한 픽셀에서 예측한 bounding box들은 같은 text instance일 가능성이 높음
위치 순서(행 우선)로 탐색하면서 비슷한 것들을 하나로 통합하자.
- RBOX 기준
-
Training
Loss Term : RBOX 기준
전체 loss : loss for score map + loss for geometry map
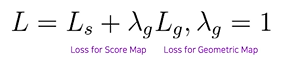

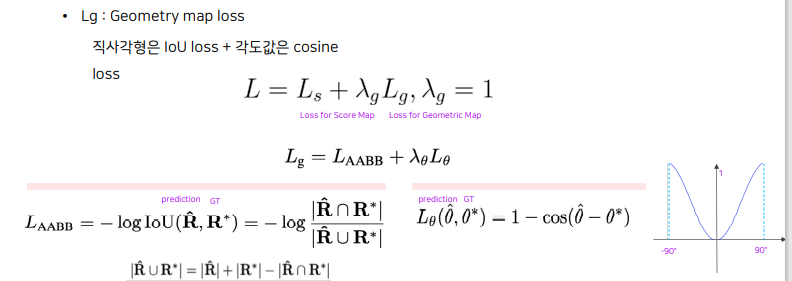
-
Result
(6강) Annotation Guide
1. 좋은 데이터셋의 선결조건, 가이드라인
1.1 가이드라인이란?
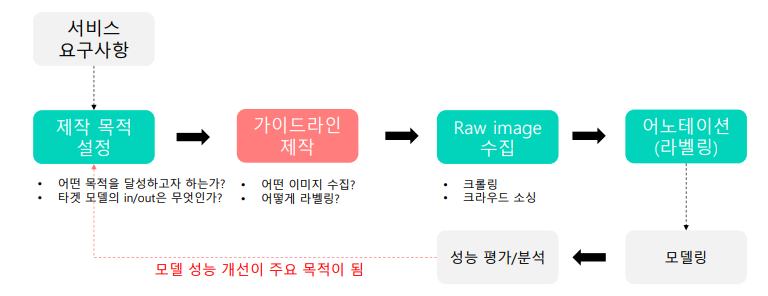
가이드 라인 : 좋은 데이터를 확보하기 위한 과정을 정리해 놓은 문서
좋은 데이터는 되도록
1) 골고루 모여 있고 (raw data)
2) 일정하게 라벨링된 데이터 (GT)
특이 경우를 발견하고 해당 샘플들을 확보하려고 노력해야 하며, 이를 포함한 라벨링 가이드를 만들어야 한다
• 데이터 구축의 목적
• 라벨링 대상 이미지 소개
• 기본적인 용어 정의
• BBOX, “전사”, “태그" 등등
• Annotation 규칙
• 작업불가 이미지 정의
• 작업불가 영역 (illegibility = True) 영역 정의
• BBOX 작업 방식 정의
• 최종 format
가이드 라인은 목적에 맞게 일관되게 작성되어야 함
ex) 단어 별, 줄 별로 구분하여 글자 영역 찾자!
"글자가 잘리지 않는 한도에서 최대한 타이트 하게”
와 같이 원하는 작업을 명확하게 언급해야함
가이드라인 작성시 신경써야할 3가지 요소
특이케이스 - 가능한 모든 케이스
단순함 - 가이드라인 너무 장황하지 않게
명확함 - 동일한 가이드 라인에 대해서 같은 해석이
가능하도록
1.2 학습 데이터셋 제작 파이프라인
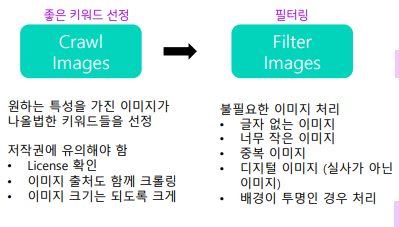
Raw Image 수집 - 크롤링
어떤 결과가 나오는지에 제일 중요한 영향을 주는 것은 “검색어”
검색어의 집합으로 글자가 등장하는 대부분 상황에 대한이미지들을 크롤링 할 수 있어야 한다
이미지 크기는 되도록 큰 것으로!
이미지 크기가 작은 것은 크게 할 수 없지만 (resize해도 노이즈 존재) 큰 것은 작게 할 수 있다.
Augmentation을 효율적으로 하기 위함.
색상도 augmentation 가능하기에 별다른 조건을 걸지 않는다.
• 파일 유형은 이미지 파일이면 되는데 조심해야 하는 것은 배경이 투명한 이미지가 간혹 있어 문제를 일으킨다.
• 시간은 신경 안 써도 됨
사용권 : 상업적으로 사용 시 반드시 조건을 걸어서 해당 라이선스를 갖는 이미지만 모이도록
Raw image 수집 - 크라우드 소싱
• 수집용 가이드라인 제공
• Edge case 수집에 유리
• 원하는 특성 명시
• 좋은 예, 나쁜 예를 직접 사람에게 학습시킬
수 있음
• 시간, 비용이 많이 들어 일반적으로 크롤링된
이미지에 추가하는 방식으로 진행
• 구하기 힘든 이미지
• 개인정보, 저작권 이슈에서 자유로움
2. General OCR Dataset 예제로 알아보는 가이드라인 작성법
2.1 개요
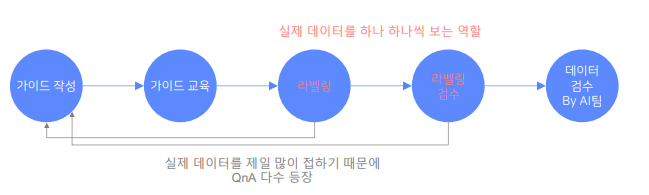
초기에 정말 많은 QnA가 있기 때문에, 처음에 아주 소량의 데이터로 우선 pilot 라벨링 작업을 통해 가이드의 완성도를 빠르게 올리는게 중요!
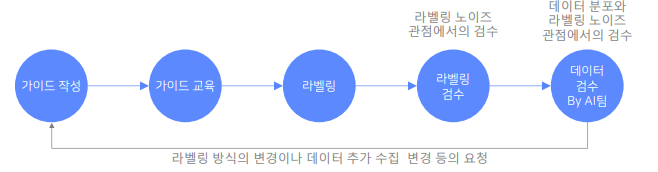
라벨링 방식에 대해서 탐색을 많이 해야 하거나, 일반 사람들에게 익숙하지
않는 데이터에 대해 라벨링을 할 경우에는 가이드 작성의 횟수가 높아
가이드 작성/수정/교육에 대한 비용이 크기 때문에 외주보다 차라리
내부에서 인력을 고용해서 진행하는게 효율적일 수 있음
pilot labeling 및 edge case 대응
기본적인 용어 정리
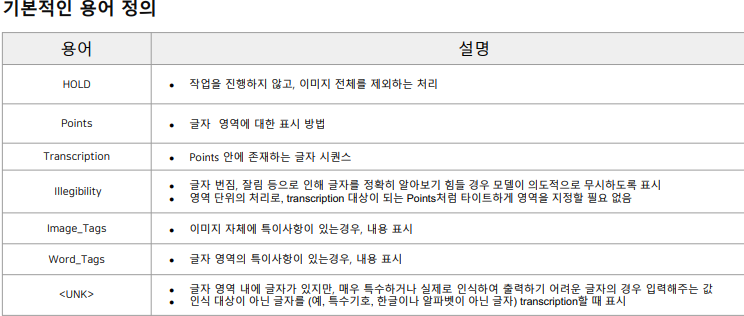
2.2 노하우
Annotation 규칙 : HOLD 이미지 기준
● 이미지 내에 글자영역이 존재하지 않는 이미지
● 이미지의 모든 글자 영역 속 글자를 알아보기 어려운 경우
● 같은 글자 혹은 패턴이 5회 이상 반복되는 이미지
● 영어, 한국어가 아닌 외국어가 ⅓ 이상인 이미지
● 개인정보가 포함된 이미지 (단, 방송 캡쳐는 제외)
● Born-digital 이미지 (화면 캡쳐, 카드뉴스, 작업물 시안 이미지 등 사람이 촬영한 이미지가 아니라,
처음부터 디지털 형태로 생성된 이미지)
Annotation 규칙 : BBOX 작업방식 정의 – Points 영역
1. Points의 크기는 최소한 해당 글자들이 다 포함되는 영역으로 지정합니다.
박스의 타이트함은 상대적이라 Annotation 수행자의 재량에 맡기되, 느슨하게 박스를 표기하는 것은 지양합니다
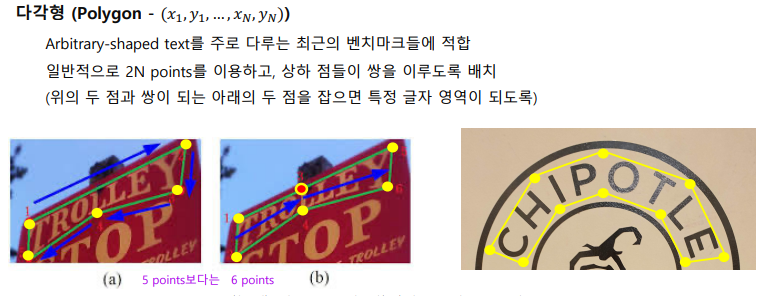
Annotation 규칙 : BBOX 작업방식 정의 – 구부러진 글자 영역
1. 단어가 심하게 곡선으로 배열된 경우 짝수 개의 점들로 이루어진 polygon 형태의 Points를 지정합니다.
글자의 위아래에 점이 쌍을 이루게 하여, 점들을 기준으로 사각형 모양의 박스가 만들어지는 것이 좋습니다
2. 단어가 심하게 곡선으로 배열되어 타이트한 사각형 Points로 라벨링을 못할 경우 짝수 개의 점들로
이루어진 polygon 형태의 Points를 지정합니다. 글자의 위아래에 점이 쌍을 이루게 하여, 점들을 기준으로
사각형 모양의 박스가 만들어지는 것이 좋습니다. 최대 점의 개수는 12개로 제한합니다 (위, 아래 각 6개).
첫 번째 글자로부터 2글자 혹은 4글자에 점을 한 개 찍습니다.
Annotation 규칙 : BBOX 작업방식 정의 – 진행 방향 및 그에 따른 좌표 순서
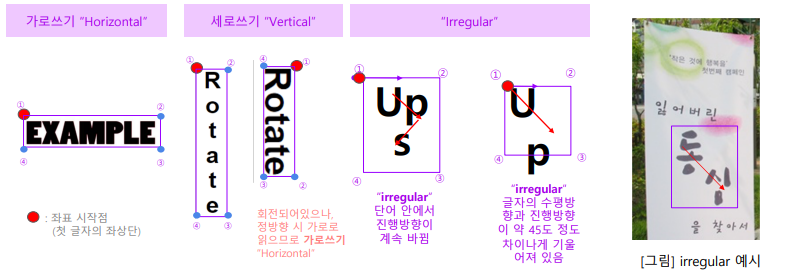
Annotation 규칙 : BBOX 작업방식 정의 – 그 외
어디까지를 하나의 글자 영역으로 정의하여 Points로 표기할 것인지?
● 띄어쓰기 기준으로 분리할 것인지,
● 한 단어 내에서 글자 크기가 급격히 차이나는 경우 분리할 것인지,
● 글자가 변형되어 일반적인 표시 영역을 벗어나는 경우는 어떻게 처리할 것인지
Annotation 규칙 : 작업 불가 영역
“don’t care" 학습 시 마스킹 처리하기 위함
Annotation 규칙 : 최종 포멧
• 데이터 포멧이 변경이 되면, 이전에 작업된 파일들도 최신
포멧으로 변경이 되어야 데이터를 활용할 수가 있음
• 데이터 포맷 고민 시 수정될 때의 이전 데이터 활용 여부도
반드시 염두를 해야 함
가이드라인은 일관성, 우선순위가 있어야 함
2.3 가이드라인으로 데이터 구축하기
데이터 구축 과정시 검수의 역할
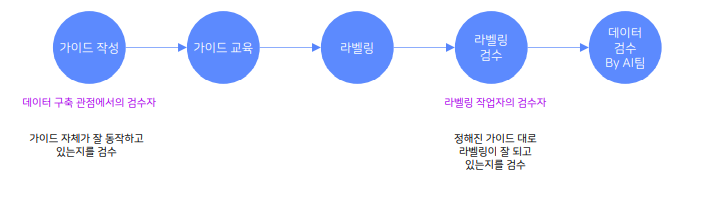
가이드라인 만들기는 끝없는 의사소통과 수정의 연속
1. 충분한 pilot tagging을 바탕으로 가이드 제작
2. 가이드라인 수정 시 versioning 필요, 기존 내용과 충돌 없도록 최소한의 변경만
3. 최대한 명확하고 객관적인 표현을 사용
4. 일관성 있는 데이터가 가장 잘 만들어진 데이터
5. 우선순위를 알고, 필요하다면 포기하는 것도 중요
과제 수행 과정 및 결과
피어 세션
OCR 외부 데이터 수집
프로젝트 주제 설정
학습 회고
