강의 내용 복습
(5강) 데이터 소개
1. Data Collection
1.1 OCR 학습 및 평가 데이터는 어디에서 오나요?
-
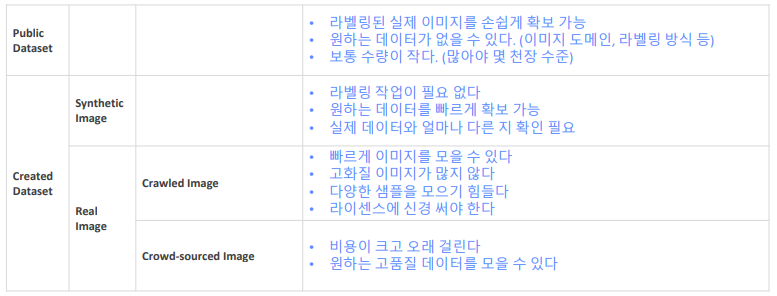
Public dataset
라벨링된 실제 이미지를 손쉽게 확보 가능
원하는 데이터가 없을 수 있다. (이미지 도메인, 라벨링 방식 등)
보통 수량이 작다. (많아야 몇 천장 수준) -
Created dataset
-
Synthetic Image
라벨링 작업이 필요 없다
원하는 데이터를 빠르게 확보 가능
실제 데이터와 얼마나 다른 지 확인 필요 -
Real Image
-
Crawled Image
빠르게 이미지를 모을 수 있다
고화질 이미지가 많지 않다
다양한 샘플을 모으기 힘들다
라이센스에 신경 써야 한다 -
Crowd-sourced Image
비용이 크고 오래 걸린다
원하는 고품질 데이터를 모을 수 있다
-
-
2. Public Dataset
서비스향 AI 모델 개발 시 한시라도 빨리 답을 가지고 있어야 하는 질문들
1. 몇 장을 학습을 시키면 어느 정도 성능이 나오는가?
2. 어떤 경우가 일반적이고 어떤 경우가 희귀 케이스인가?
3. 현재 최신 모델의 한계는 무엇인가?
공개되어 있는 데이터셋으로
공개되어 있는 최신 모델을
학습시켜 성능을 분석한다
데이터 검색 방법

- 언어
- 용도
- 검출기 (Detection)
- 인식기 (Recognition)
- End-to-End
- 데이터 수량
- 라이센스 종류
- 데이터 저장 포맷
- 특이사항
OCR 데이터에 포함되는 것들
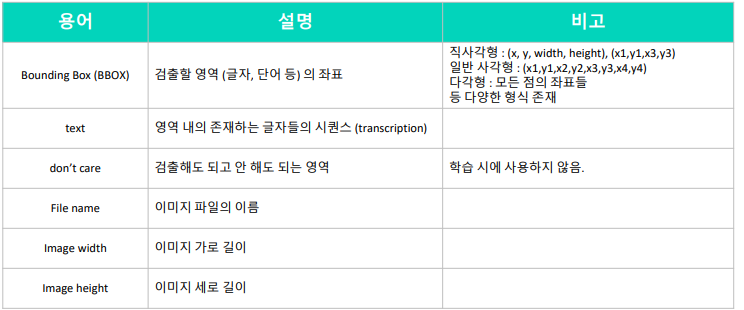
2년에 한번씩 열리는 OCR 대회
ICDAR (International Conference on Document Analysis and Recognition)
2.1 ICDAR 15 : Incidental Scene Text Dataset
Incidental Scene Text: 풍경 이미지 속에 우연히 글자가 잡힌 경우
총 1500장의 이미지와 그에 해당하는 ground truth
(GT) text file
train 1000장, test 500장
care, don’t care로 구분하여 전사
care: 검출할 영역. 라틴문자
don’t care: 검출하지 않을 영역. 육안상 알아보기 힘든 글자, 라틴문자가 아닌 글자 (한자 등)
2.2 ICDAR 17 : Multi-Lingual SceneText Dataset
Multi-lingual Scene Text (MLT)
• Multilingual
• 9가지 언어: Chinese, Japanese, Korean, English, French, Arabic, Italian, German and Indian
• 6가지 문자: "Arabic", "Latin", "Chinese", "Japanese", "Korean", "Bangla" + “symbols”, “mixed”
• 총 18000장
• Train 9000 (각 언어별 1000장), test 9000
• Focused (Intentional) Scene Text
• 우연히 찍힌 글자가 아닌, 글자 영역을 위주로 촬영된 이미지
• 길거리 표지판, 광고판, 가게 간판, 지나가는 자동차 및 웹 microblog에 올라간 유저 사진 등
• gt파일 형식은 ICDAR 2015와 유사
2.3 Recent Datasets
ICDAR 2019 ArT (Arbitrary shaped Text)
• 기존에 존재하던 Total-Text,
SCUT-CTW1500, Baidu Curved
Scene Text 에 추가로 데이터를
수집 (3055장 + 7011장)
• train: 5603장 , test: 4563장
• horizontal, multi-oriented,
curved 등 다양한 형태 포함
2.4 AI Hub 야외 실제 촬영 한글 이미지
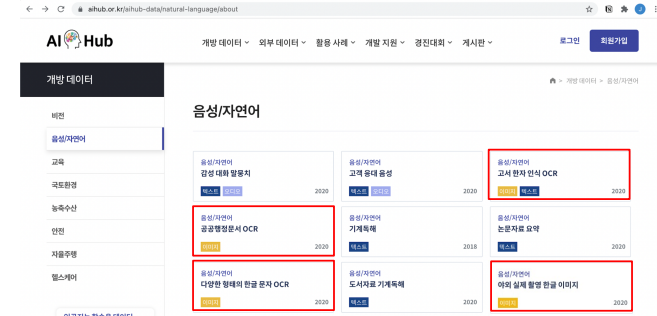
각각의 public data마다 annotation format이 다르기때문에 일관된 방식으로 저장해야함
3. UFO(Upstage Format for OCR)
3.1 UFO가 무엇인가요?
• 각각의 Public Dataset의 파일 형식(json, txt, xml, csv 등)을 하나로 통합함
• Detector, Recognizer, Parser 등 서로 다른 모듈에서 모두 쉽게 사용할 수 있어야 함
• 모델 개선을 위해 필요한 case에 대한 정보를 데이터에 포함 시킬 수 있음
• 예: 이미지 단위의 특징 (손글씨, blur 등), 글자 영역 단위의 특징 (가려짐, 글자 진행 방향 등)
json 파일 안에서 element 탐색이 쉽게 Graph Structure을 기반으로 만들어졌음
• 하나의 이미지 내의 정보는 모두 parallel하게 존재함
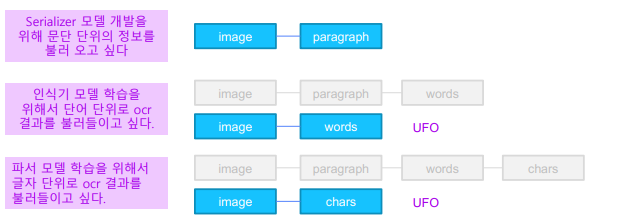
3.2 UFO 포맷 자세히 알아보기
-
Dataset 레벨
한 데이터셋 내의 모든 이미지들에 관해 하나의 ufo 형식의 Json파일을 만든다 -
Image 레벨
이미지 별로 아래와 같은 정보가 담겨있다.
• paragraphs
• words
• characters
• image width
• image height
• image tag
• annotation log
• license tag
각각의 정보는 위계를 가지지 않고, parallel하게 존재한다 -
paragrphs, words, characters의 공통요소
• Ids: paragraph, image, character 레벨 각각에서 모두 id 넘버를 매김 (순서는 의미 없음)
• points: 각 라벨의 위치 좌표. 글자를 읽는 방향의 왼쪽 위에서부터 시계방향으로 x, y좌표를
nested list 형태로 기록함
• 4points의 bbox가 기본적이나, 6, 8 등 2n 개의 points로 이루어진 polygon도 가능하다.
• [[x1, y1], [x2, y2], [x3, y3], [x4, y4]]
• language: 사용된 언어
• “en”, “ko", “others”, [“en”, “ko”] …
• tags: 성능에 영향을 주지만 별도로 기록하기 애매한 요소를 사전에 정의한 태그로 표시
• 이미지 레벨의 image tag, 단어 레벨의 word tag
• confidence: ocr 모델이 예측한 pseudo-label의 경우 confidence score를 함께 표시 -
Annotation log, License Tag
Annotation log: 이슈 추적을 위한 정보 기록
License tag: 라이센스 정보
4. Challenge Dataset!
4.1 챌린지 테스트셋 소개
public 150장 + private 150장
데이터 source:
• 네이버 및 구글에서 크롤링된 데이터 (크롤링 키워드: 간판, 광고판, 손글씨, 화환, 버스노선도 등)
• 상업적 활용 가능한 license
데이터 annotation 방식:
• Ufo포맷 사용
• Image, word 레벨 정보만 태깅되어 있음
데이터 EDA
OCR 관점에서 유용하다고 보는 것들
- 이미지 크기, 이미지 내의 단어 수와 같은 통계
- 이미지 tag 의 분포 -> 특이케이스 알기
- 단어 tag 의 분포 -> 특이케이스 알기
- 언어 분포
- 각 단어의 aspect ratio (가로/세로)
Tips
• detector 학습을 위한 영어 및 한국어 public dataset이 많이 있으니 이를 잘 활용하는 것이 좋다.
• 학습 목적에 맞는 데이터를 잘 선택하여 학습시키면 좋다.
• 다양한 형태의 데이터셋을 통합하기 위해 UFO처럼 하나의 통일된 포맷을 만드는 것이 실험에
편리하다.
(7강) 성능 평가 방식
1. 성능 평가 개요
1.1 성능 평가의 중요성
성능평가 == 새로운 (학습에서 사용되지 않은 ) 데이터가 들어왔을 때 얼마나 잘 동작하는가
validation set을 통해 서비스 출시 전 성능 평가
Confusion Matrix, Recall, Precision 을 통해 추가 분석
- Precision (정밀도) = 1 : 모델의 양성이다고 판단하는 사람은 실제
전부 양성이지만, 양성인 사람 전부를 찾지 못함 - Recall (재현도) = 1 : 실제 양성인 사람은 하나도 빠짐없이 다 찾아
낼 수 있지만, 양성이 아닌 사람도 양성이라고 할 수 있음
1.2 정량평가 & 정성평가
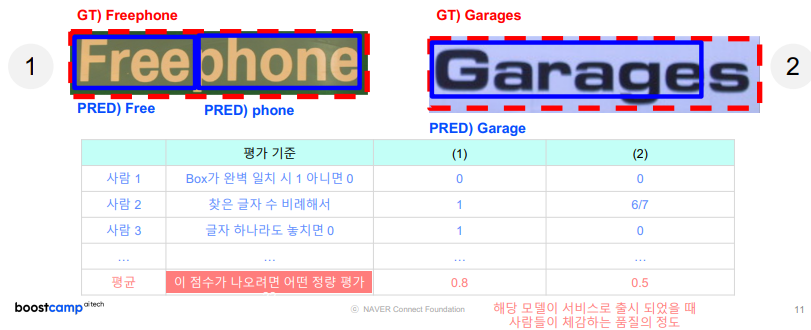
2. 글자 검출 모델 평가 방법
2.1 글자 검출 모델 평가
1단계: 테스트 이미지에 대해, 결과값을 뽑습니다
2단계: 예측 결과와 정답 간 매칭/스코어링 과정을 거쳐 평가합니다
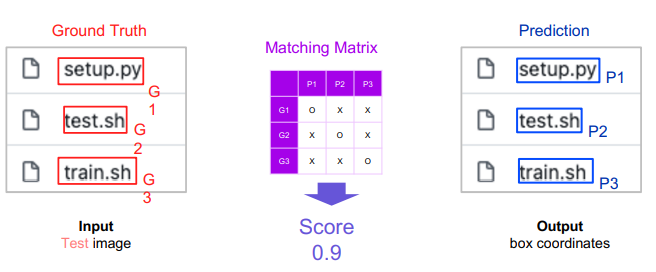

2.2 Glossary
-
IoU (Intersection of Union)
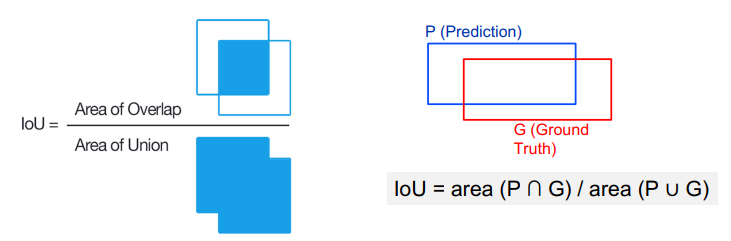
-
Area Recall / Area Precision
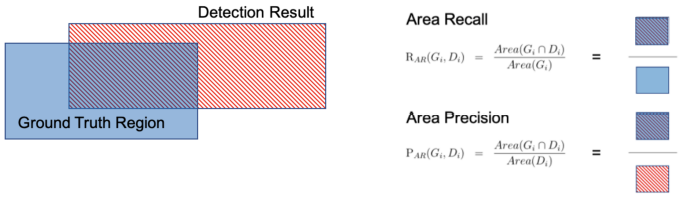
-
One-to-One | One-to-Many | Many-to-One Match
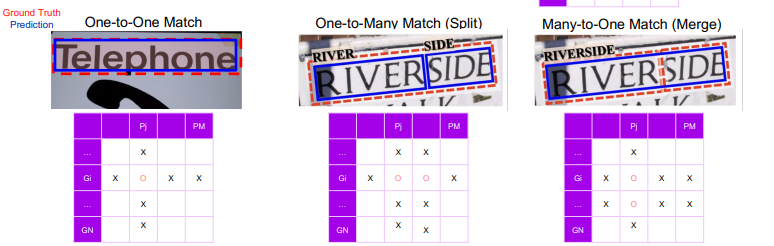
2.3 DetEval


1. 모든 정답 영역, 예측 영역 간의 매칭 정도를
area recall/area precision 둘 다 계산한다.
즉 관계 하나마다 두 개의 수치 확보
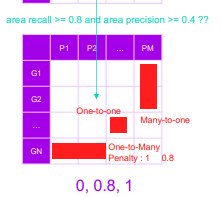
2. 셀 중에 area recall >= 0.8 and area
precision >= 0.4 조건을 충족시키면 1
아니면 0으로 값으로 관계 행렬 값을 바꿈
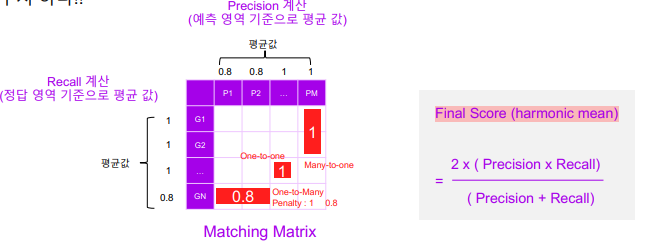
3. 최종 스코어 계산
2.4 IoU

• one-to-one matching 만 허용
• one-to-one matching이 성립 and IoU value > 0.5 일 경우 correct, 그렇지 않은 경우
incorrect
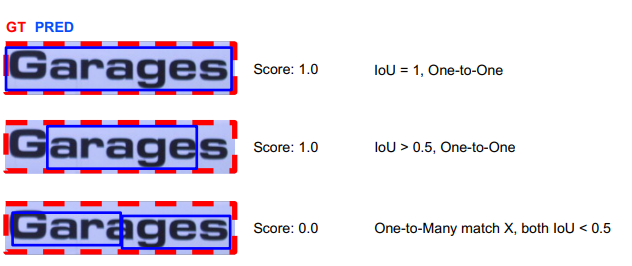
IOU가 0.5보다 크더라도 one-to-many 의 관계이므로 IOU는 0이 됨
2.5 TIoU(Tightness-aware IoU)
• 부족하거나 초과된 영역 크기 에 비례하여 IoU 점수에 대해 penalty를 부여.
• GT의 completeness, 예측 박스의 타이트함을 점수에 반영.
• Ground truth 가 golden answer이라는 가정이 존재
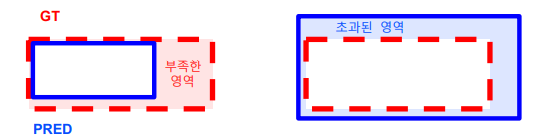
TIOU = IOU X Penalty
예측 영역이 정답보다 부족한 경우 Penalty
부족한 영역 크기 / 정답 크기
정답 영역 기준이므로 TIOU Recall
예측 영역이 정답보다 초과한 경우 Penalty
초과된 영역 크기 / 예측 영역 크기
예측 영역 기준이므로 TIOU Precision

한계점
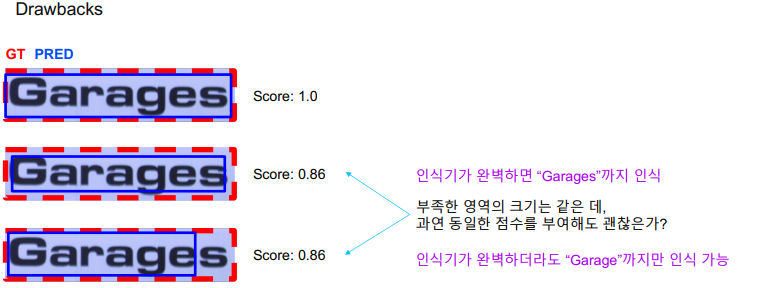
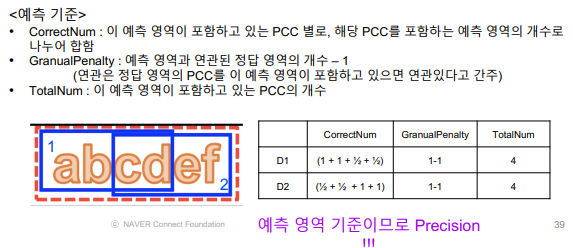
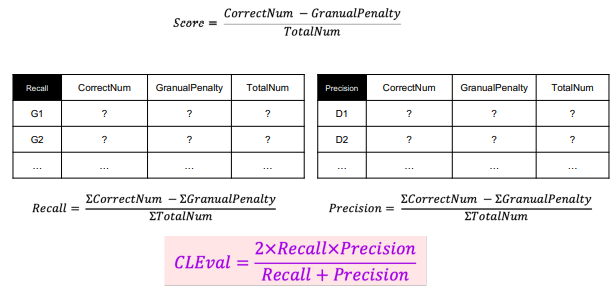
2.6 CLEval(Character-Level Evaluation)
-
얼마나 많은 글자(Character)를 맞추고 틀렸느냐를 가지고 평가.
-
Detection 뿐 아니라 end-to-end, recognition 에 대해서도 평가 가능
-
글자 검출 모델 평가는 글자가 아닌 평가를 기반으로 해야한다는 결론에 이름

-
PCC (Pseudo Character Centers)
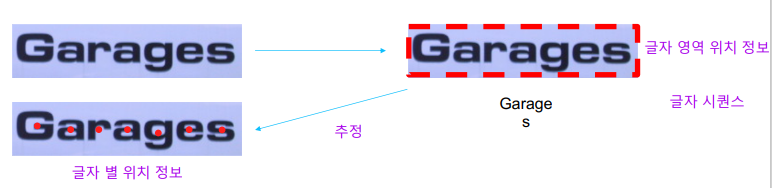 글자 영역을 글자수만큼 나누고 영역을 만들고 각 영역별 center위치를 구함
글자 영역을 글자수만큼 나누고 영역을 만들고 각 영역별 center위치를 구함 -
Matching Matrix
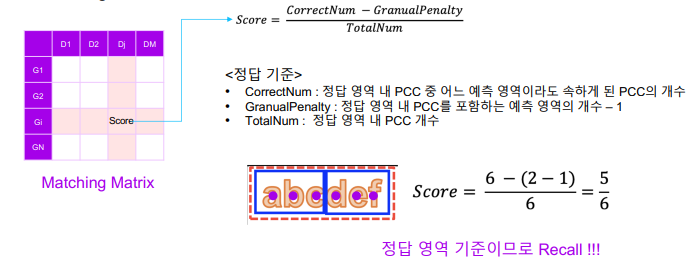


2.7 Summary
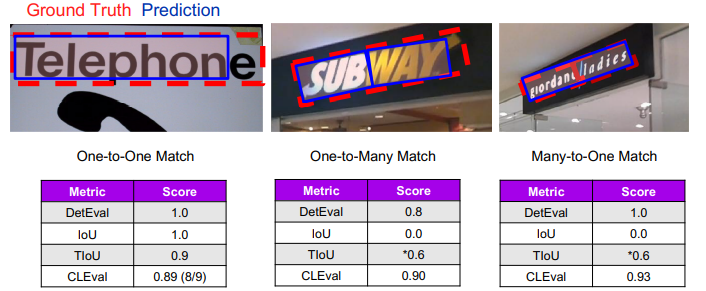
*TIoU 에서 many-to-one, one-to-many match를 허용하기 위해선 별도로 line annotation이 필요
(8강) Annotation Tool 소개
1. 데이터의 중요성
1.1 데이터의 양과 질
연구나 교육 목적으로 다루는 데이터는 굉장히 많은 노력을 거쳐서 나온 결과물
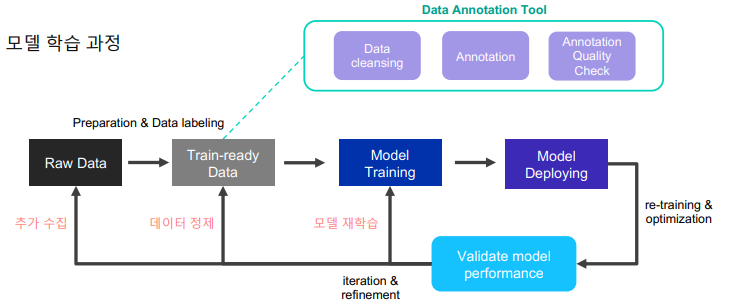 annotation tool은 데이터 정제 단계에서 수행
annotation tool은 데이터 정제 단계에서 수행
1.2 양질의 데이터를 확보하려면?
잘 작성된 아벨링 가이드
일관된, 효율성있는, 숙지된 사람들
프로세스
효율성 좋은 tool(자동화, 부가기능, 게시판을 통한 커뮤니케이션 기능)
2. CV 데이터 제작 서비스들
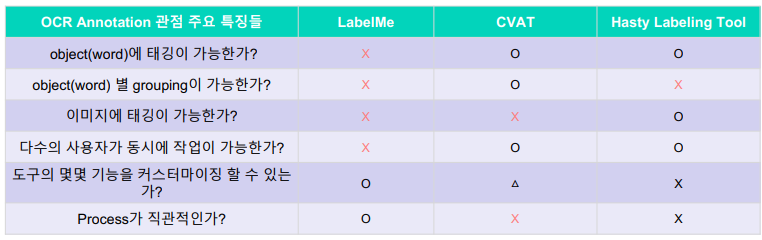
2.1 Labelme
-
MIT CSAIL (Computer Science Artificial
Intelligence Laboratory) 에서 공개한
image data annotation 도구를 참고하여
만든 오픈소스 -
polygon, circle, rectangle, line, point의
annotation 수행 가능 -
장점
설치하기가 용이하다.
python으로 작성되어있어, 추가적인 기능 추가가 가능하다. -
단점
공동작업이 불가능하다. (다수의 사용자가 사용할 수 없다.)
object, image에 대한 속성을 부여할 수 없다
2.2 CVAT
- Intel OpenVINO 팀에서 제작
한 공개 computer vision 데이
터 제작 도구 - image, video 등 일반적인
computer vision task 에서 필
요한 annotation 기능을 모두
포함. - 주로 object detection, image
segmentation, image
classification - Automatic annotation
- Assignee, Reviewer를 특정 인원에게 지정하여, 작업을 나누어 할 수 있습니다.
- 장점
• 다양한 annotation을 지원한다.
• automatic annotation 기능으로, 빠른 annotation이 가능하다.
• 온라인에서 바로 사용하거나, 또는 오픈소스도 제공되어있어 on-premise로 설치하여 이용가능하다.
• multi-user 기반 annotation이 가능하며, Assignee, Reviewer 기능이 제공된다. - 단점
• model inference가 굉장히 느리다.
• object, image에 대한 속성을 부여하기가 까다롭다
2.3 Hasty Labeling Tool
• 앞에서 설명드린 도구와 유사한 CV annotation 도구
• 대신, annotation 도구는 전체 솔루션의 일부이고, 데이
터제작/모델학습/서빙/모니터링까지 전체를 쉽게 할 수
있는 솔루션 제공
• 회원가입을 통해서 사용 가능
• 특정 action을 이용할 때마다 비용 발생
- 장점
• 다양한 annotation을 지원한다.
• semi-automated annotation 기능을 지원한다.
• cloud storage를 활용할 수 있다. (유료)
• multi-user 기반 annotation이 가능하며, Assignee, Reviewer 기능이 제공된다. - 단점
• 서비스 자체가 free credit을 다 소진한 이후에는 과금을 해야한다.
• annotator가 수동으로 이미지마다 review state로 변경해주여야 한다.
• Hasty 플랫폼에 강하게 연결되어 있어, annotation 도구에 대한 커스터마이징이 불가능하다.
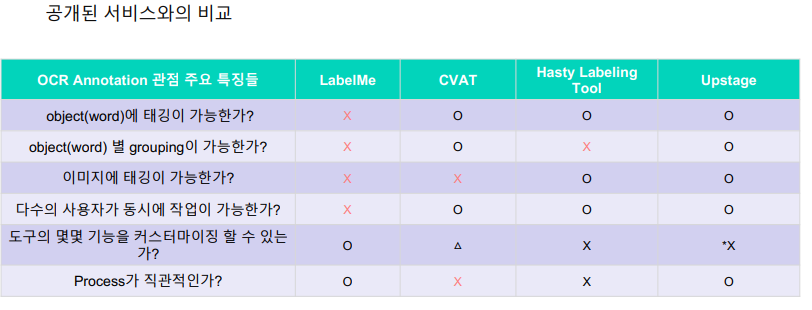
2.4 서비스 비교
OCR Annotation 을 진행한다고 가정함
3. Upstage Annotation Tool
3.1 컨셉
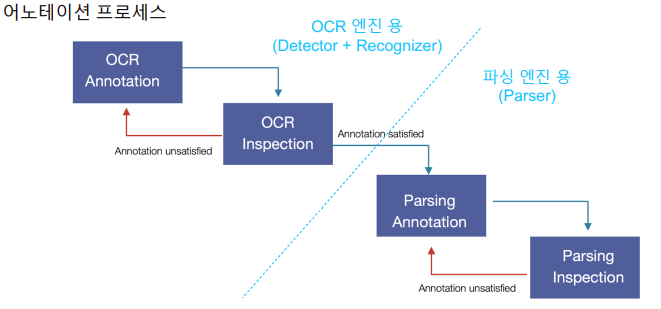
과제 수행 과정 및 결과
피어 세션
학습 회고
