[논문 리뷰] Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training (2025)
Paper Review
목록 보기
13/15
From arXiv, 2025.01
1. Abstract, Introduction
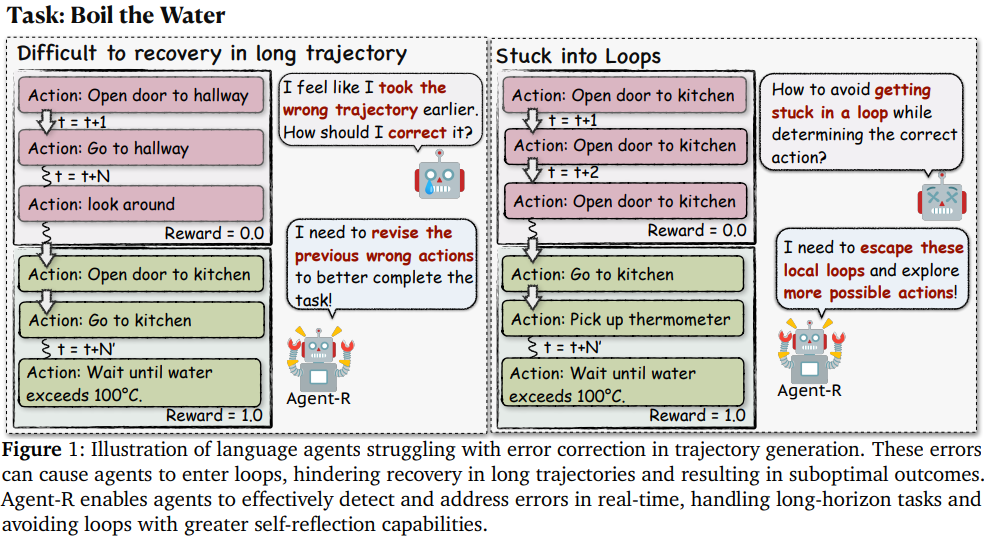
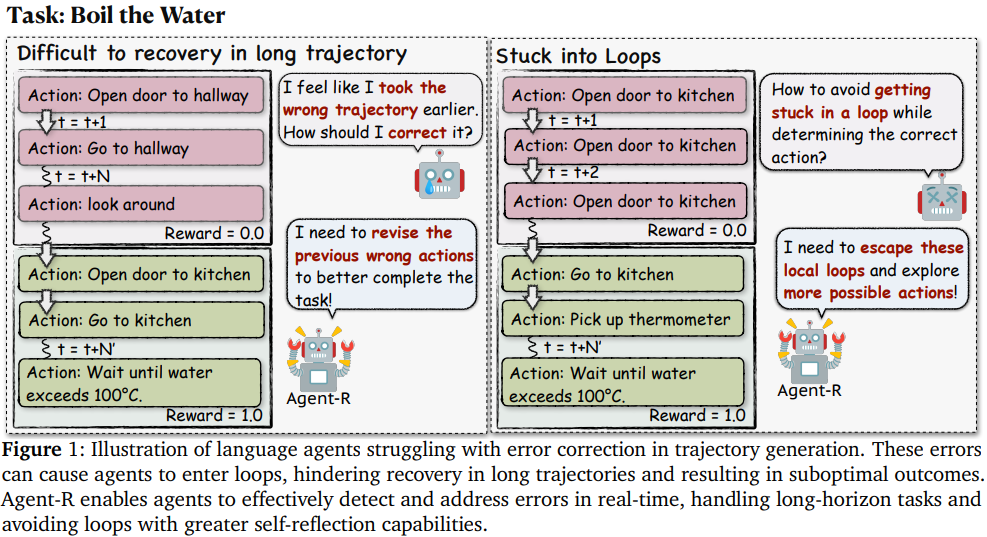
- 제안하는 Agent-R은 LLM agent가 상호작용하는 환경에서 복잡한 작업을 해결하는 과정에서 reflection과 self-improvement를 하게 하는 iterative한 self-training framework
- 기존 방법론들은
- expert를 cloning하거나,
- 보상함수를 기반으로 action의 정확성을 평가하는 방식에 의존
- single-task에서 모델의 self-correction 강화하려 함
- 따라서, 여러 한계
- 오류 탐지 및 수정 능력에 한계
- 작업 종료 후에 수정하므로 실시간 reflection 능력 제한
- multi-turn interaction이 필요한 복잡한 환경에는 적합하지 않음
- Agent-R
- 실시간 오류 감지와 수정 목표
- 주요 요소
- 모델 기반 reflection data 생성: Monte Carlo Tree Search (MCTS)를 활용해 잘못된 경로를 올바른 경로로 수정
- 단계별 수정 능력: 작업 종료를 기다리지 않고 단계별로 오류를 수정함으로써 실시간 reflection 구현
- interative training: 초기 약한 policy에서 점차 강한 policy로 발전 - Agent-R의 기여
- language agent의 상호작용 환경에서 오류 수정 문제를 해결하는 첫번째 접근법
- MCTS와 모델 기반 reflection을 통해 동적 데이터셋 생성 및 self improvement 가능
- 실험을 통한 성능 개선 입증
2. Preliminary
2.1 Task Formulation
- 이 환경은 Partially Observable Markov Decision Process (POMDP)로 모델링되며, 주요 구성 요소는 다음과 같다.
- U: 과제 설명 및 요구 사항을 제공하는 instruction 공간.
- S: 상태 공간(State space).
- A: 행동 공간(Action space).
- O: 관찰 공간(Observation space).
- T: 전이 함수(Transition function), 환경에 의해 결정.
- R: 보상 함수(Reward function), 특정 행동의 보상을 정의
- U,S,A,O는 자연어로 표현되며, 시간 t에서의 histrorical trajectory τ_t는 아래와 같이 표현된다. τt = (a_1, o_1, …, a_t, o_t) ∼ πθ(τ_t ∣ u)
- πθ는 agent의 policy 모델이고, 시간 t+1에서 에이전트는 τ_t와 u를 바탕으로 다음 행동 a(t+1)를 생성해야 한다.
- 최종 보상 r(τ)는 task가 끝나거나 최대 턴 수에 도달하면 주어진다.
2.2 Monte Carlo Tree Search
- MCTS는 Agent-R의 중요 요소로, 잘못된 trajectory를 수정해 새로운 trajectory를 생성한다.
- MCTS는 아래 4단계를 포함한다
- Selection: Upper Confidence bound for Trees (UCT) 전략을 사용해 확장할 노드 선택
- Expansion: 선택된 노드에서 새로운 자식 노드 생성
- Simulation: 새로운 노드에서 터미널 노드까지 rollout 수행
- Backpropagation: 시뮬레이션 결과 바탕으로 노드 값 업데이트
3. Method
- Agent-R은 두 개의 core phase로 구성된다.
- Model-Guided Reflection Trajectory Generation
- MCTS를 사용해 잘못된 trajectory를 수정해 올바른 trajectory로 전환
- Iterative Self-Training with Revision Trajectories
- 생성된 trajectory 기반으로 iterative하게 모델 학습해 성능 개선
3.1. Phase 1: Model-Guided Reflection Trajectory Generation
Reflection Trajectory Definition
- 이 단계에서는 아래 trajectory 유형이 정의된다
- 초기 궤적 (Initial Trajectory) τ^i: 초기 행동 및 관찰의 시퀀스
- τ^i = (a^i_1, o^i_1, …, a^i_t, o^i_t)
- 잘못된 궤적 (Bad Trajectory) τ^b: 초기에 오류를 포함한 행동 및 관찰의 시퀀스.
- τ^b = (τ^i1, a^b(t+1), o^b(t+1), …, a^b(Tb), o^b(T_b))
- 올바른 궤적 (Good Trajectory) τ^g: 초기 궤적에서 시작해 최적화된 행동 시퀀스.
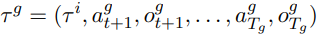
- 수정된 궤적 (Revision Trajectory) τ^r: 잘못된 궤적을 올바른 궤적으로 수정한 결과.
- rs: Revision Signal, agent의 reflection을 돕는 간단한 메시지
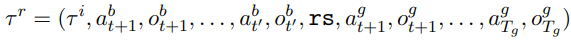
- 초기 궤적 (Initial Trajectory) τ^i: 초기 행동 및 관찰의 시퀀스
- 보상 조건
- 최종 보상 r(τ)에 따라 다음 조건을 만족해야 한다.
- 잘못된 궤적의 보상: r(τ^b)<β
- 올바른 궤적의 보상: β<r(τ^g)≤1
- 수정된 궤적의 품질: r(τ^g)=r(τ^r)≥α
- β: 잘못된 궤적과 올바른 궤적을 구분하는 임계값.
- α: 고품질 궤적의 하한값.
- r(τ^g)=1 은 이 good trajectory가 Optimal Trajectory임을 의미.
- 최종 보상 r(τ)에 따라 다음 조건을 만족해야 한다.
Trajectory Collection with MCTS
- MCTS는 다양한 행동 경로를 탐색하여 수정된 궤적을 생성하는 데 사용되며, 다음 4가지 단계로 구성된다.
- Selection(선택): UCT(Upper Confidence bound for Trees) criterion을 사용해 확장할 노드 선택
-
UCT 공식
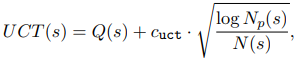
- Q(s): average reward of state s
- N(s): number of visits to state s
- N_p(s): total visit count of the parent node of s
- c_uct: 탐색-활용(exploration-exploitation) trade-off를 조절하는 상수
-
- Expansion(확장): 선택된 노드에서 새로운 자식 노드 생성
- Simulation: 터미널 노드에 도달할 때까지 행동 시퀀스를 샘플링
- Backpropagation: simulation 결과를 바탕으로 노드값을 업데이트
- Selection(선택): UCT(Upper Confidence bound for Trees) criterion을 사용해 확장할 노드 선택
Transition Point Determination
-
agent는 잘못된 trajectory에서 오류를 감지하고, 오류가 발생한 첫번째 지점(t’)을 결정
-
이후 잘못도니 trajectory를 t’에서 잘라내고, t’ 이후부터는 올바른 궤적과 연결
-
이 과정은 agent의 selt reflection 능력을 활용하며, 실시간 수정 능력을 강화
-
요약: MCTS는 다양한 행동 시퀀스를 탐색하며 각 trajectory에 대한 보상을 평가하고, 잘못된 궤적과 올바른 궤적 간의 전환점을 식별한다.
3.2. Phase 2: Iterative Self-Training with Revision Trajectories
Objective
- 수정된 궤적을 사용해 agent를 반복적으로 학습시키고, agent의 정책을 지속적으로 개선하는 것
- 이를 통해 agent는 더 초기의 오류를 감지하고 수정할 수 있는 능력을 개발
Mixed training strategy
- 수정된(revision) trajectory와 올바른(good) trajectory 데이터를 혼합해 학습 진행
- 학습 초기에는 revision trajectory가 중심이 되며, 점진적으로 good trajectory 데이터 비율이 증가합니다.
- 이 접근법은 초기 학습에서 발생하는 cold-start 문제를 완화
Loss function
- 아래의 loss function를 최소화해 학습이 이루어진다:
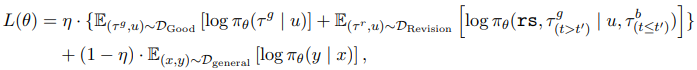
- η: 수정 궤적 데이터와 일반 데이터의 혼합 비율.
- τ_g: 올바른 궤적.
- τ_r: 수정된 궤적.
- (x,y): 일반 데이터셋의 입력-출력 쌍.
Iterative Training
- 매 반복(iteration)마다 agent는 새로운 revision trajectory를 생성하고 학습하며, 정책을 강화
- 이를 통해 약한 초기 정책에서 강력하고 효율적인 정책으로 점진적으로 발전
4. Experiment
- 3개의 interative 환경에서 실험을 통해 평가되었다.
4.1. Interactive and Agentic Environments
- WebShop
- 온라인 쇼핑을 시뮬레이션한 웹 기반 환경
- 보상: 작업 완료 시 보상
- ScienceWorld
- 초등학교 과학 커리큘럼 수준의 30개 과학 작업 유형을 포함한 텍스트 기반 환경
- agent의 과학적 추론 능력 평가ㅏ
- TextCraft
- Minecraft 아이템 제작을 시뮬레이션한 텍스트 기반 환경
- 아이템 제작 트리와 명령을 기반으로 목표 아이템 제작
- 보상: 성공적으로 목표 아이템 제작 시 1점 보상
4.2. Experiment Setting
1. Data Split
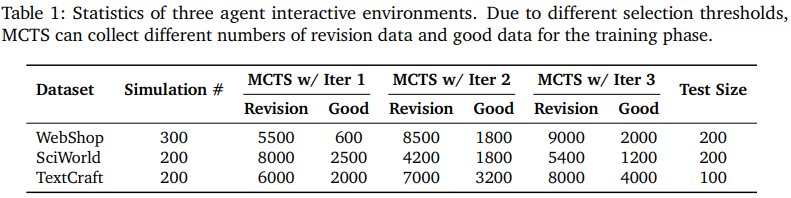
- WebShop 300회, ScienceWorld 200회, TextCraft 200회
- 각 시뮬레이션에서 MCTS를 사용해 trajectory 데이터 생성
- 초기 반복에서는 낮은 기준(α=0.5), 이후 반복에서 점진적으로 증가(α=1.0)
2. MCTS Settings
- 각 시뮬레이션에서 k=8개의 롤아웃을 샘플링
- 탐색 깊이(d)를 20으로 설정
- 각 깊이에서 4개의 행동 후보 생성
- UCT criterion의 탐색-활용 균형 상수 (c_uct)를 0.25로 설정
3. Training Settings
- 3번의 iteration 학습 수행
- 첫 iteration에서 에폭은 3, 이후 iteration에서는 1로 설정해 과적합 방지
- 기본 모델: Llama-3.1-8B-Instruct
4. Baselines
- Closed-source model: GPT-3.5-Turbo, GPT-4-Turbo, GPT-4o, Claude-3, DeepSeek-Chat
- Open-source model: Llama2-Chat, AgentLM, Agent-FLAN
- 기존 기법: ETO, Direct-Revision Trajectory
5. Evaluation Metrics
- WebShop, ScienceWorld: average final reward
- TextCraft: success rate
- 모든 환경에서 최대 라운드 수는 100으로 제한
4.3. Main Results
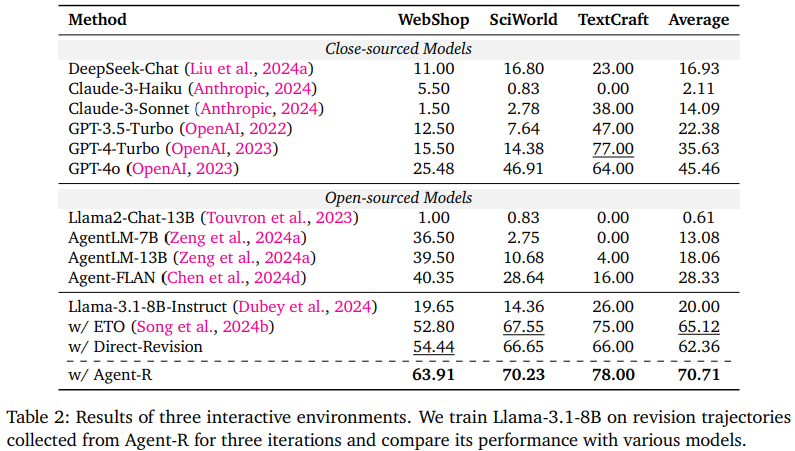
- Performance improvement
- Agent-R은 GPT-4o, AgentLM, Agent-FLAN 등의 기존 모델보다 높은 성능
- 특히 revising erroneous trajectories를 활용한 학습이 기존의 expert data에 의존하는 학습보다 효과적임을 입증
- Early Error detection
- Agent-R은 trajectory 초기에 오류를 감지하고 수정하여 error propagation를 방지
- 수정된 궤적은 더 빠른 회복과 안정적인 학습 유도
- Limitation of Contrastive Learning(Ex: ETO)
- ETO와 같은 contrastive learning은 성능 향상에는 기여했지만, agent의 self reflection 능력을 충분ㄴ히 개선하지 못함
4.4. Findings with Analysis
Finding 1 : Training with trajectories from Agent-R can outperform using optimal trajectories.
- 수정 궤적의 성능 향상 효과

- Revision trajectory를 사용한 학습이 optimal trajectory만을 사용한 학습보다 성능이 우수
- 초기 학습에서 수정 궤적과 최적(optimal) 궤적을 혼합하면 에이전트의 성능과 자기 반성 능력이 크게 향상
Finding 2 : Agent-R can effectively provide language agents with self-reflection capabilities.
- self reflection 능력 강화
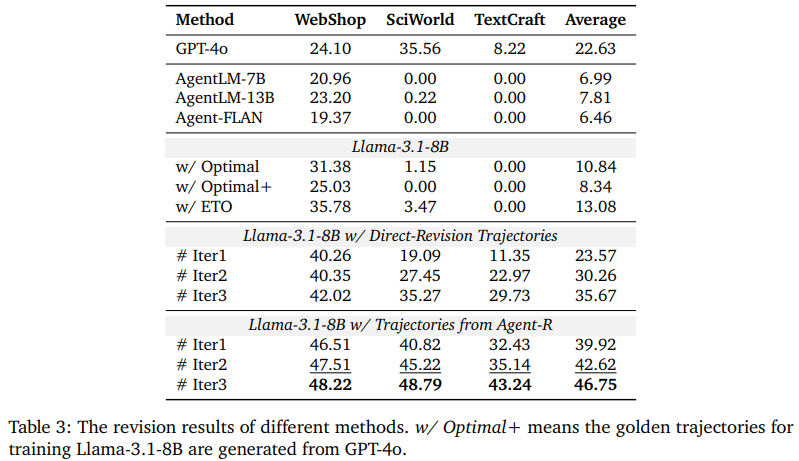
- Agent-R로 학습한 agent는 오류를 감지하고 수정하는 능력이 크게 향상
- 직접 수정(Direct-Revision) 방식보다는 동적 수정 방식이 반복 루프 감지나 오류 수정에 더 효과적
- SFT를 사용한 expert trajectory나 DPO를 사용한 contrastive learning은 성능은 향상시킬 수 있으나 self reflection은 잘 못한다.
Finding 3 : Training with revision trajectories helps agents more easily identify and correct erroneous actions.
- 초기 오류 탐지 능력
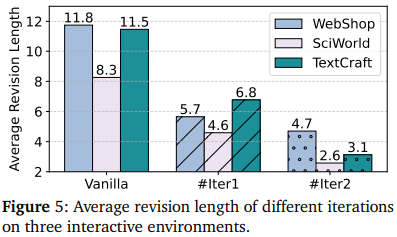
- revision trajectory를 활용한 iterative training은 trajectory의 첫번째 오류를 더 효과적으로 탐지
- 평균 수정 길이(average revision length)가 짧아져서 효율적인 경로 조정 가능
Finding 4 : Training with revision trajectories helps agents avoid getting stuck in loops
- 반복 루프 방지
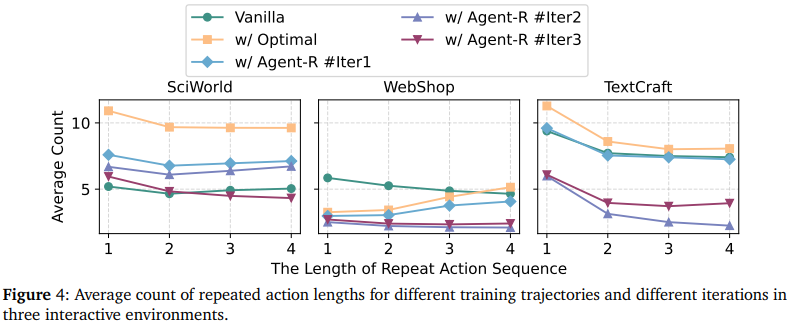
- Agent-R으로 학습한 agent는 동일한 행동을 반복하는 dead loop에 빠질 확률이 매우 감소
- 이는 revision trajectory가 agent의 탐색 능력을 강화했음을 보임
Finding 5 : Multi-task training is a more effective strategy for Agent-R
- multitask 학습
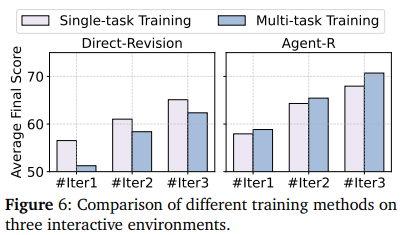
- revision trajectory는 다양한 환경에서 멀티태스크 학습을 통해 Agent-R 성능을 더 향상시킴
- 단일 task 학습보다 다양한 환경에서의 일반화 성능이 높음
5. Related Work
1. Agent Learning in Interactive Environments
- 기존 연구에서 interactive environment에서 agent learning은 크게 3가지 approach로 분류 가능하다: 1) Prompt-based Strategy, 2) Inference-time Search Strategy, 3) Training-based Strategy
- Prompt-based Strategy
- 사람이 작성한 프롬프트를 활용해 LLM이 탐색 과정에서 경험을 요약하도록 유도
- Ex)
- 이전 경험에서 얻은 기술(skill set) 요약 및 전이 가능하도록 구성
- 탐색을 돕는 유용한 힌트 제공
- LLM이 이러한 요약된 경험을 memory에 저장해 성능 향상을 도모하지만, 내재적(self-contained) 학습보다는 외부 지식 의존도가 높음
- Inference-time Search Strategy
- Tree-of-Thought, Monte Carlo Tree Search 등의 탐색 알고리즘을 활용해 최적 경로 찾음
- LLM이 사전에 학습된 지식을 활용해 보다 효율적인 탐색 수행
- 단점: pre-trained된 지식에 의존하여 새로운 문제에 대한 적응력이 떨어질 수 있음
- Training-based Strategy
- Supervised Fine-Tuning(SFT)
- Direct Preference Optimization(DPO)
- 학습 데이터 출처
- expert model에서 수집
- MCTS를 활용한 탐색을 통해 데이터 생성
- 이 strategy는 fine tuning을 통한 성능 향상을 목표로 하지만, agent가 self reflection하는 능력은 부족함
2. Self-Correction for Large Language Models
- LLM의 self-correction 능력은 매우 중요한 기능이지만, LLM은 이를 효과적으로 수행하지 못하는 것으로 나타남
- 기존의 self-correction method
- Prompt Engineering
- 특정한 프롬프트를 입력하여 LLM이 자기 수정을 수행하도록 유도
- 그러나 성능 향상 효과가 미미하거나 오히려 성능이 저하될 수 있음
- Revision Data Collection
- Human annotators, Expert models, Self-generated samples 를 통해 revision data를 생성
- 그러나 대부분의 연구는 code repair, tool use, math 등 특정 작업에 한정
- Prompt Engineering
- 기존 연구의 한계
- 명확한 오류 신호(explicit error signal)가 있는 환경에 초점
- Ex) code error message, tool-use parameters 등의 signal
- 그러나 현실적인 interactive 환경에서는 명확한 오류 신호가 존재하지 않음
- Single-turn 문제 해결에 집중
- 대부분의 연구가 단일 입력과 출력 간의 self correction에 초점을 맞춤
- multi turn interactive 환경에서 LLM이 자율적으로 오류를 수정하는 방법론이 부족
- 명확한 오류 신호(explicit error signal)가 있는 환경에 초점
- Agent-R의 차별점
- Agent-R은 explicit error signal이 없는 interactive environment에서 LLM의 self-correction을 가능하게 함
- 기존 방법들이 prompt engineering, SFT, expert data에 의존하는 반면, Agent-R은 reflection과 self-training을 통해 성능을 점진적으로 개선하는 새로운 방법론 제시
6. Conclusion
- Agent-R의 기여
- Monte Carlo Tree Search (MCTS) 및 모델 기반 반성(Model-Guided Reflection) 활용
- 기존 방법들이 정적인 expert trajectory를 모방하는 것에 의존한 반면, Agent-R은 MCTS를 사용하여 동적으로 수정 궤적(revision trajectories)을 생성
- agent가 자신의 행동을 분석하고, 적절한 수정 지점에서 궤적을 조정하도록 유도
- 실시간 오류 수정 및 궤적 개선
- Agent-R은 잘못된 궤적을 조기에 감지하고 수정할 수 있도록 설계
- 기존 방식 대비 반복 루프(looping) 및 비최적 행동(suboptimal behavior) 방지
- 상호작용 환경에서의 성능 향상
- Agent-R이 기존의 지도 학습(SFT), DPO, Direct-Revision 방식보다 우수한 성능
- Self-correction 기능을 갖춘 agent는 더 높은 보상과 성공률
- 자기 생성 수정 궤적(Self-Generated Revision Trajectories)의 효과
- agent가 생성한 수정 궤적을 학습에 통합하면, 지능적이고 자율적인 agent 발전 가능
- 이를 통해 LLM agent가 단순히 expert data를 학습하는 것이 아니라, 자율적으로 반성(self-reflection)하고 학습(self-improvement)하는 능력 갖춤
- Monte Carlo Tree Search (MCTS) 및 모델 기반 반성(Model-Guided Reflection) 활용
- 향후 연구
- self-correction 능력 고도화
- agent-based system에서의 응용
- Agent-R이 MAS나 자동화된 의사결정 시스템에서도 활용될 가능성 탐색

Anyone can be anything ... with agent!