[논문 리뷰] Decision Transformer: Reinforcement Learning via Sequence Modeling (2021)
Paper Review
From NeurIPS, 2021
0. Abstract
- Idea
- RL을 sequence modeling 문제로 추상화해, transformer 아키텍처의 단순성과 확장성을 활용
- 기존 RL 접근법과 달리, 가치 함수(value function)를 학습하거나 정책 경사(policy gradient)를 계산하는 대신, causally masked Transformer를 통해 최적의 행동 생성
- Method
- 모델은 desired return(reward), 과거 상태(state), 행동(action)을 조건으로 한 autoregressive모델로 동작
- 원하는 desired return(목표보상)과 조건을 입력받아, 이를 달성하는 action을 예측
- Result
- Atari, OpenAI Gym, Key-to-Door 벤치마크에서, model-free offline RL 기법과 비슷하거나 더 뛰어난 성능
- Decision transformer는 간단하면서도 기존 알고리즘 한계 극복
1. Introduction
-
Motivation
- Transformer: 언어 모델링과 이미지 생성 등에서 Transformer는 높은 성능과 확장성을 통해 일반화 능력을 증명
- RL
- 대부분의 RL은 특정 행동 분포를 학습하는데 초점, 너무 좁은 범위의 문제 다룸
- Temporal Difference(TD) 학습법은 return의 bootstrapping을 사용하며, 이는 불안정성을 유발할 수 있다(deadly tried).
-
Goal
- Transformer를 RL에 적용해 시퀀스 모델링이 기존 RL을 대체할 수 있는지 탐구
- 기존 RL과 차별화
- Bootstrapping 없이 지도학습으로 데이터를 사용해 policy 학습
- Discounting을 제거해 장기적 목표를 더 잘 학습
-
Proposed Method
- Decision Transformer
- GPT 아키텍처를 활용해 상태, 행동, 목표 보상의 시퀀스를 autoregressive하게 모델링
- 특정 목표보상을 설정하여 다양한 행동을 생성하고, 학습된 데이터를 바탕으로 최적 경로 예측
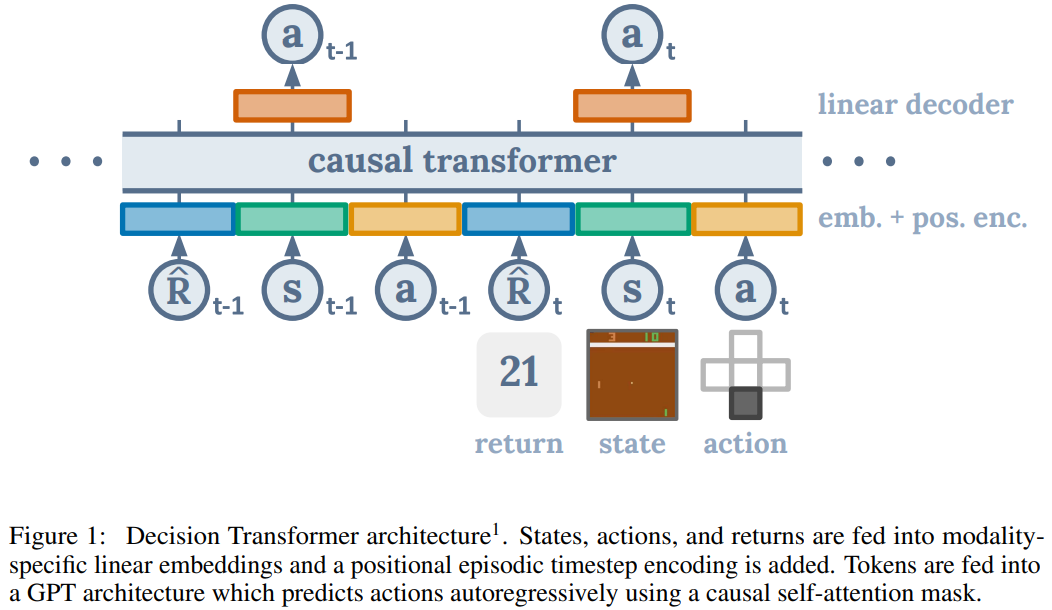
- Decision Transformer
-
Example
- 그래프 최단 경로 (Figure 2)
- 그래프 탐색 문제를 RL로 변환
- Transformer는 과거 데이터 학습해 목표 달성하는 최적 경로 생성
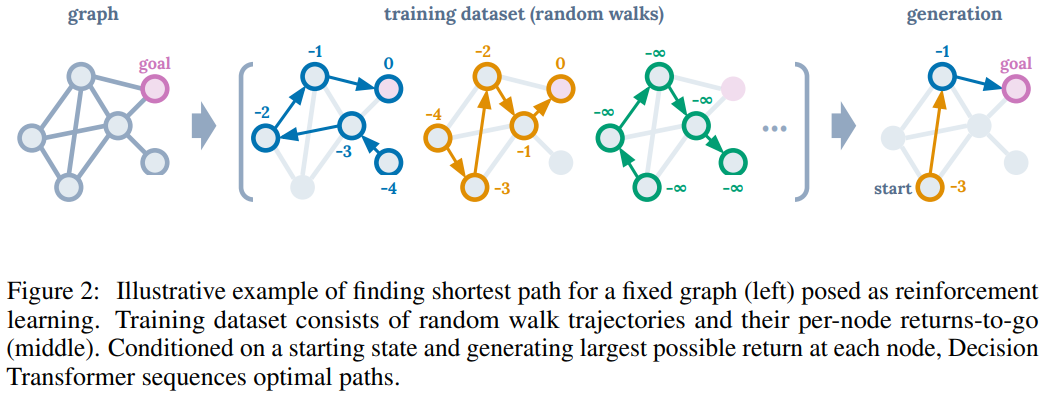
- 그래프 최단 경로 (Figure 2)
2. Preliminaries
2.1 Offline Reinforcement Learning
- 강화학습 목표: Markov Decision Process(MDP)에서 주어진 정책(policy) 하에 기대 보상을 극대화하는 것
- MDP는 상태 S, 행동 A, 전이 확률 P(s′∣s,a), 보상 함수 R(s,a)로 구성
- Offline RL
- 환경과의 상호작용 없이 고정된 데이터셋 내에서 학습 진행
- 고정된 데이터는 trajectory를 포함, 추가적 피드백 받을 수 없는 제약
2.2 Transformers
-
Transformer
- 시퀀스 데이터를 효율적으로 모델링하기 위해 설계
- self-attention layer, residual connection
-
Attention mechanism
- 각 입력은 키, 쿼리, 밸류 벡터로 변환
- 출력은 아래와 같이 계산
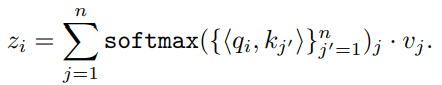
- 쿼리와 키 유사도 기반으로 가중치 적용해 값 합산
-
GPT 아키텍처
- Causal self-attention mask 사용해 시퀀스 생성, 이전 토큰만을 고려
- 이 논문에서는 GPT 구조 활용해 RL을 시퀀스 모델링 문제로 변환
3. Method
Trajectory representation
- Decision Transformer
- RL trajectory를 autoregressive하게 모델링
- Transformer 구조를 최소한으로 수정해, 상태, 행동, 목표 보상을 포함한 trajectory를 학습
- Return-to-go(RtG)
- return-to-go = reward-to-go = 특정 시점부터 미래(에피소드 종료)의 누적 보상
- 과거 보상이 아닌 미래 기대 보상 합계 모델링
- Trajectory representation: τ=(R_1, s_1, a_1, R_2, s_2, a_2, … , R_T, s_T, a_T)
- R_t는 시점 t에서의 Returns-to-go
Architecture
- Input
- 최근의 K 타임스텝의 데이터를 사용해 RtG, 상태, 행동에 대한 총 3K개의 토큰을 생성
- linear embedding을 통해 각 모달리티를 transformer입력으로 변환
- Transformer processing
- 입력 토큰은 GPT 모델에 의해 처리되며, 다음 행동을 예측하기 위해 autoregressive하게 사용
Training
- Loss function
- 행동 예측을 위해 discrete action은 Cross entropy loss, continuous action은 mean-squared error를 사용
- loss는 타임스텝 별로 평균
Evaluation
- 목표 보상(RtG)와 시작 상태를 설정한 후, 모델이 생성한 행동을 환경에 적용하여 다음 상태와 보상을 계산
- 프로세스는 에피소드 종료까지 반복
Pseudocode
- for continuous actions
def DecisionTransformer(R, s, a, t):
pos_embedding = embed_t(t)
s_embedding = embed_s(s) + pos_embedding
a_embedding = embed_a(a) + pos_embedding
R_embedding = embed_R(R) + pos_embedding
input_embeds = stack(R_embedding, s_embedding, a_embedding)
hidden_states = transformer(input_embeds=input_embeds)
a_hidden = unstack(hidden_states).actions
return pred_a(a_hidden)
# R, s, a, t: returns -to -go , states , actions , or timesteps
# K: context length ( length of each input to DecisionTransformer )
# transformer : transformer with causal masking (GPT)
# embed_s , embed_a , embed_R : linear embedding layers
# embed_t : learned episode positional embedding
# pred_a : linear action prediction layer4. Evaluations on offline RL benchmarks
- 개요
- Decision Transformer(DT)가 기존 Temporal Difference(TD) 학습 및 Imitation Learning 방식과 비교해 Offline RL에서 얼마나 잘 학습하는지 평가한다.
- 평가 기준
- TD 학습
- TD 학습은 일반적으로 action-space constraint나 value pessimism을 활용
- 비교 대상: Conservative Q-Learning(CQL), BEAR, BRAC 등
- Imitation Learning
- Bemman update 없이 supervised loss를 사용해 policy를 학습하는 방식
- 비교 대상: Behavior Cloning(BC)
- TD 학습
- Task
- Discrete control task - Atari
- 고차원의 시각적 입력과 action-reward 간 시간 지연으로 인한 credit assignment 문제
- Continuous control task - OpenAI Gym
- 미세한 연속 제어를 요구하는 다양한 task
- Discrete control task - Atari

4.1 Atari
-
벤치마크 설정
- 데이터: Agarwal et al.의 DQN-replay 데이터셋에서 1% 샘플(500,000개의 전이 데이터)
- 기준:
- Hafner et al.의 프로토콜에 따라 점수를 정규화
- 100 = 프로게이머 수준 점수, 0 = 무작위 정책
- 평가 방식: 샘플링된 데이터로 3회 반복 실험 후 평균과 표준 편차 기록
-
결과 요약
-
게임별 성능 비교 (Table 1)
- Breakout: DT(267.5)가 CQL(211.1) 및 모든 baseline 능가
- Qbert: DT는 BC(17.3)에 근접하며 CQL(104.2)보다 낮은 성능
- Pong: DT(106.1)는 CQL(111.9)에 근접하며 다른 baseline 능가
- Seaquest: DT(2.4)는 CQL(1.7) 및 다른 baseline 능가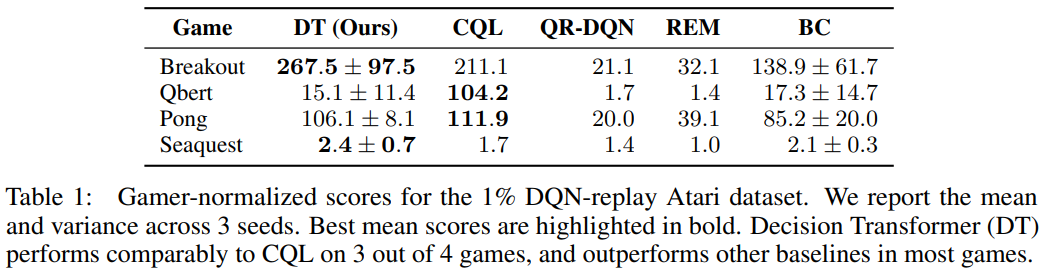
-
결론
- DT는 4개 중 3개 게임에서 CQL과 동등하거나 더 나은 성능을 보이며, 다른 baseline보다 우수
-
4.2 OpenAI Gym
-
벤치마크 설정
- 환경
- D4RL 데이터셋
- Offline RL 표준 데이터셋, 연속적 제어 환경(HalfCheetah, Hopper, Walker) 포함
- 2D Reacher
- 목표 위치에 팔 도달하게 하는 goal-conditioned 작업
- sparse reward 환경 : agent가 목표를 달성했을 때만 보상
- D4RL 데이터셋
- 종류,유형
- Medium: Expert policy의 1/3 수준 성능 갖는 policy
- Medium-Replay: 학습 도중의 replay buffer에서 생성된 데이터. 학습되지 않은 데이터 포함 가능. 다양한 상태-행동 쌍
- Medium-Expert: Medium policy + Expert policy 결합. Expert policy는 environment에서 높은 성능(데이터 품질 다양성 높임)
- 환경
-
결과 요약
-
데이터셋별 성능 비교 (Table 2)
- Medium-Expert
- DT는 HalfCheetah, Walker 등에서 CQL 및 다른 알고리즘보다 우수
- Hopper에서는 CQL과 비슷한 성능
- Medium
- DT는 Hopper에서 CQL을 능가하며, 다른 환경에서도 competitive
- Medium-Replay
- DT는 Hopper에서 CQL을 크게 능가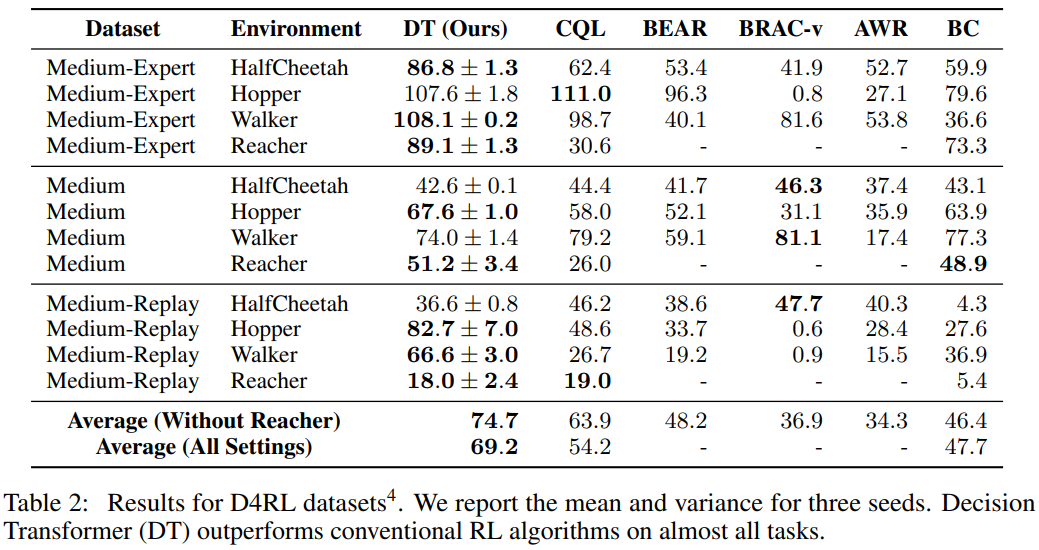
-
결론
- DT는 대부분의 환경에서 기존 Offline RL 알고리즘보다 높은 성능을 보임
-
5. Discussion
5.1 Does Dicision Transformer perform behavior cloning on a subset of the data?
-
Decision Transformer는 데이터의 특정 부분 집합에 대해 Behavior Cloning을 수행하는가?
- DT가 특정 목표 보상(return)에 해당하는 데이터의 일부만 학습하는 모방 학습(Behavior Cloning)과 유사한 방식으로 작동하는지 확인
-
새로운 실험
- Percentile Behavior Cloning (%BC):
- 데이터셋에서 에피소드 보상(return) 기준 상위 X%의 데이터만 선책해 Behavior Cloning 수행
- X%는 전체 데이터를 사용하는 표준 BC(X=100%)와 상위 소수 데이터를 학습하는 특화 모델(X →0%) 간의 tradeoff
- Percentile Behavior Cloning (%BC):
-
결과 요약 (Table 3, 4)
-
D4RL
- %BC는 데이터가 풍부한 환경에서 DT에 근접하거나 성능 능가
- DT는 전체 데이터 분포를 학습하며, 특정 목표 보상에 집중하도록 조정 가능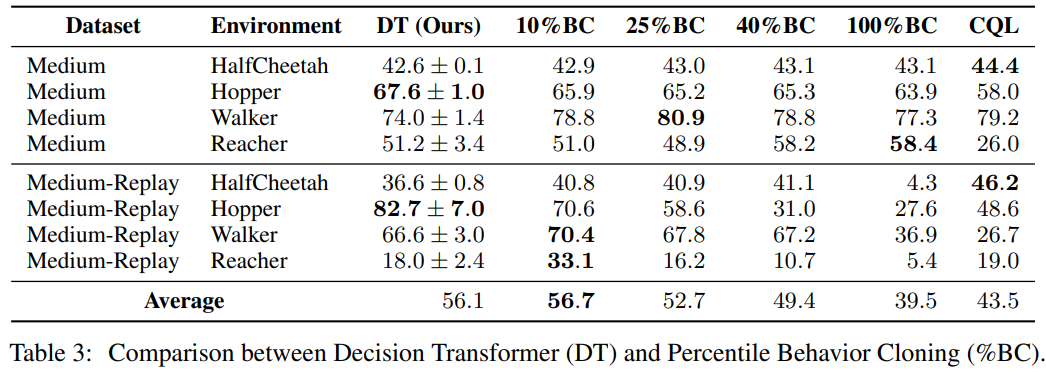
-
Atari
- 제한된 데이터 조건(1%의 DQN-replay 데이터)에서 %BC는 성능 크게 저하
- 반면, DT는 모든 trajectory를 활용해 일반화 개선해 우수한 성능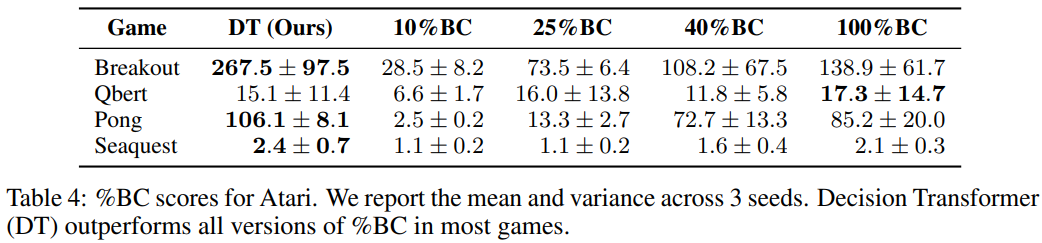
-
-
결론
- DT는 단순히 특정 데이터 하위 집합을 모방하는 것이 아니라, 전체 데이터 학습을 통한 일반화를 통해 성능 향상
5.2 How well does Decision Transformer model the distribution of returns?
- DT는 목표 보상의 분포를 얼마나 잘 모델링 하는가?
- 실험 설정
- 다양한 목표 보상(RtG) 값을 설정하고, 에피소드 동안 누적된 실제 보상과의 상관 관계 평가
- 결과 분석
-
대부분의 작업에서 설정한 목표 보상과 관찰된 실제 보상 간 높은 상관관계 확인됨
-
특정 task에서의 특징
- Pong, HalfCheetah, Walker
- 목표보상(RtG)을 거의 완벽히 충족
- Seaquest
- 데이터셋 내 최대 보상보다 높은 목표보상을 설정하면, DT가 가끔씩 extrapolation 가능
- extrapolation: 데이터 범위 벗어난 영역에서 값을 추정하거나 예측하는 과정 ↔ interpolation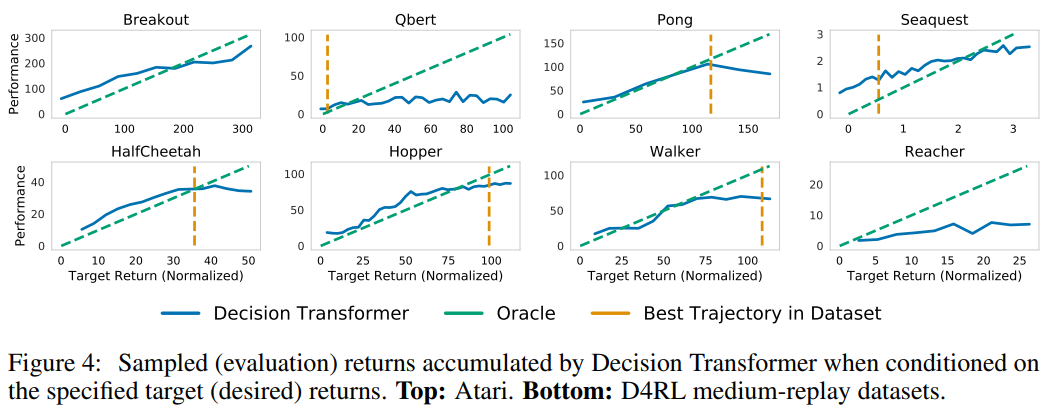
-
- 결론
- DT는 다양한 목표 보상을 학습하고 생성 가능하며, 상황에 따라서는 데이터 범위 이외의 결과도 생성할 수 있다.
5.3 Does Decision Transformer perform effective long-term credit assignment?
- DT는 long term 보상 크레딧 할당을 효과적으로 수행하는가?
- Evaluation 환경
- Key-to-Door 문제
- 3단계로 구성된 grid 환경
- 첫 번째 방에서 키 줍기
- 두 번째 방에서 빈 방 탐색
- 세 번째 방에서 문 열기
- 키를 줍지 않으면 문 열어도 보상 X
- long term 보상 할당이 어려운 문제
- 3단계로 구성된 grid 환경
- Key-to-Door 문제
- 결과 요약 (Table 5)
- DT와 %BC
- 훈련 데이터가 적을 때도 policy를 잘 학습해 최적 경로 생성
- CQL
- Q-value 가 효과적으로 propagate 되지 않아 성능 낮음
- DT와 %BC

- 결론
- DT는 Transformer 특성상 self-attention을 활용해 long term 보상 크레딧을 효과적으로 할당
5.4 Can transformers be accurate critics in sparse reward settings?
- Transformer는 sparse reward 환경에서 정확한 평가자(critic)으로 작동할 수 있는가?
- 추가 실험
- DT를 수정해 action뿐만 아니라 보상(return)도 예측하도록 구성
- Key-to-Door 환경에서 결과
- 보상 예측 확률은 에피소드 동안의 주요 이벤트(키 줍기, 문 열기)에 따라 계속 업데이트(Figure 5 참고)
- Transformer는 주요 이벤트에 높은 attention, state-return 연관성을 효과적으로 학습
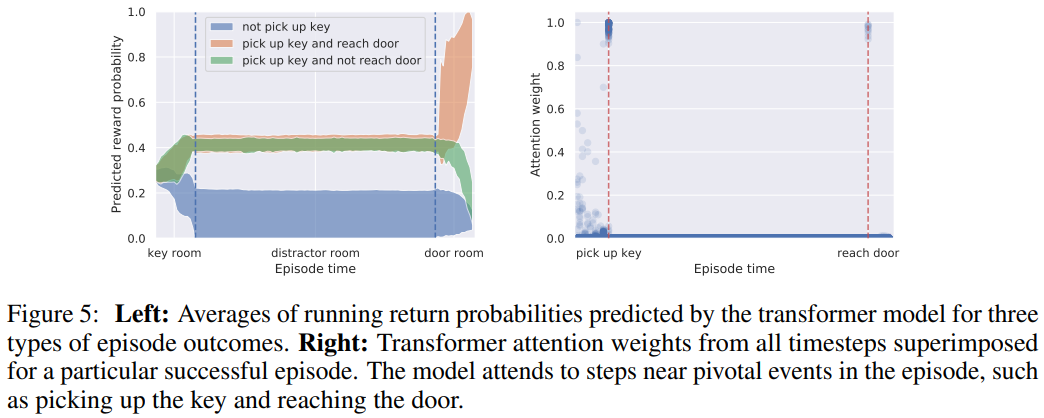
- 결론
- DT는 action 예측 뿐만 아니라 sparse reward 환경에서 정확한 critic으로도 기능 가능
5.5 Does Decision Transformer perform well in sparse reward settings?
- DT는 sparse reward 환경에서도 잘 작동 하는가?
- Evaluation 설정
- D4RL 벤치마크의 보상을 delayed된 형태로 변환
- trajectory 중간에는 보상 미제공, 에피소드 마지막에 누적 보상을 한 번에 제공
- D4RL 벤치마크의 보상을 delayed된 형태로 변환
- 결과 요약 (Table 6)
- DT와 %BC는 reward의 density가 낮아져도 성능의 큰 영향 X
- CQL은 보상 의존적 학습 방식으로 인해 성능 크게 저하

- 결론
- DT는 sparse reward 환경에서도 높은 성능, TD 학습보다 더 강건한 모델
6. Related Work
Offline RL
- Challenge of Offline RL
- Distribution Shift
- Offline data가 환경의 실제 동작 분포와 다를 때 발생하는 문제
- 이를 해결하기 위한 기존 접근법
- 행동 공간 제약(action-space contraint)
- policy가 data distribution에서 벗어나지 않도록 제한
- Ex) BEAR, BRAC
- 가치 비관주의(value pessimism)
- Q-value를 보수적으로 추정해 불확실성 처리
- Ex) CQL
- 동적 모델 기반 학습
- 환경의 동적 모델을 학습해 더 안정적인 학습 보장
- Ex) MOPO, MOREL
- 행동 공간 제약(action-space contraint)
- DT의 차별점
- DT는 동적 모델이나 Bellman 업데이트를 사용하지 않고, sequence modeling을 통해 정책 학습
- 기존 접근법과 달리 transformer의 확장성과 일반화 가능성을 활용
- Distribution Shift
Supervised learning in reinforcement learning settings
- 관련 연구
- 기존 RL 방법 중 일부는 static supervised learning과 유사한 방식으로 동작
- Ex)
- Q-learning: 여전히 Bellman 업데이트를 사용하지만, policy 학습은 supervised learning에 가깝다
- Behavior Cloning: Bellman 업데이트 없이 policy를 직접 학습
- Upside-Down RL (UDRL)
- UDRL은 목표 보상(return)에 조건부로 행동을 예측하는 방식으로, DT와 유사
- 차이점: DT는 sequence modeling을 기반으로 하며, 더 긴 context와 복잡한 행동 분포 모델링 가능
Credit Assignment
- 크레딧 할당 문제
- RL에서 long term reward를 특정 행동에 어떻게 효과적으로 할당할 것인가에 대한 연구
- 기존 접근법
- state와 reward를 연관짓는 구조 학습
- Ex) Hindsight Credit Assignment, Return Decomposition(RUDDER)
- DT 접근법
- Transformer의 self-attention을 활요앻 credit assignment를 명시적 모델링 없이 자연적으로 처리
Conditional Language Generation
- 조건부 생성 연구
- 언어 및 이미지 생성에서 transformer를 사용한 조건부 생성이 연구됨
- controllable text generation 모델에 대한 다양한 연구
- RL에서의 보상 기반 조건부 생성
- 언어 및 이미지 생성에서 transformer를 사용한 조건부 생성이 연구됨
- DT의 차별성
- 기존 text generation 연구에서는 reward가 고정된 class처럼 취급되지만, DT는 시간에 따라 변화하는 보상을 다룸
- RtG를 지속적으로 업데이트하며 trajectory를 생성하는 구조는 DT의 독창적 특징
Attention and Transformer Models
- Transformer 모델의 성공 사례
- NLP 및 비전에서 transformer는 강력한 성능을 보여주며 주류 모델이 됨
- Ex)
- NLP: GPT, BERT
- Vison: ViT
- Ex)
- RL
- RL에서 transformer의 연구는 상대적으로 적음
- 기존 연구
- Transformer를 RL 알고리즘에 보조적으로 활용
- Ex) Relational Reasoning, Episodic Memory Integration
- DT의 기여점
- 기존 연구와 달리 DT는 transformer를 중심으로 RL 문제를 재구성하여 기본 알고리즘의 패러다임 전환을 제시
- NLP 및 비전에서 transformer는 강력한 성능을 보여주며 주류 모델이 됨
7. Conclusion
- 기여
- DT는 RL 문제를 sequence modeling으로 해결할 수 있는 새로운 접근법을 제시
- 기존 RL 알고리즘의 복잡성을 줄이고 transformer의 확장 가능성 활용
- 여러 Offline RL 벤치마크에서 기존 알고리즘을 능가하거나 동등한 성능
- 특히, long term credit assignment가 필요한 문제에서 기존 방법보다 우수
- RL문제를 포함한 다양한 sequence decision making 문제에 잘 적용될 수 있음을 입증
- DT는 RL 문제를 sequence modeling으로 해결할 수 있는 새로운 접근법을 제시
- 한계
- context length나 RtG 설정과 같은 하이퍼파라미터의 중요성
- 복잡한 환경에서의 확장성과 일반화에 대한 추가 실험 부족
- 향후 연구
- 대규모 데이터셋에서의 성능 향상을 위한 self-supervised learning 적용
- state, action, rreturn에 대한 더 정교한 임베딩 설계
- 더 복잡한 RL 및 실제 문제로 확장
